 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Help, Anna! Visual Navigation with Natural Multimodal Assistance via Retrospective Curiosity-Encouraging Imitation Learning
Oct 08, 2019
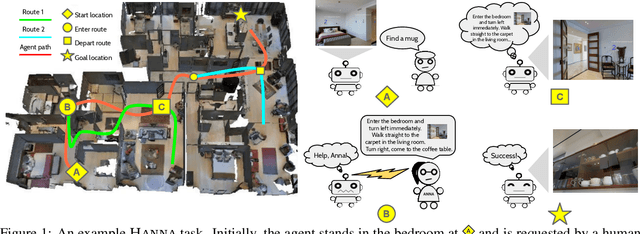
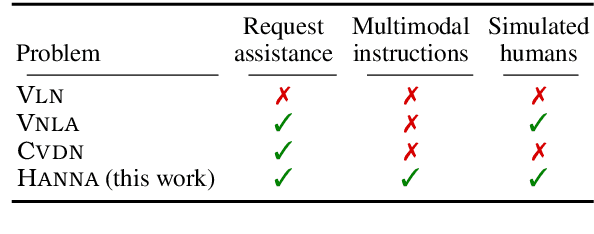
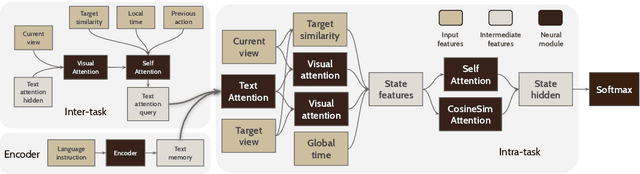
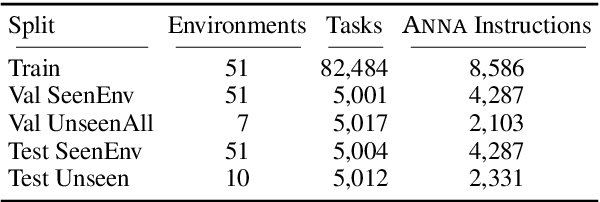
Mobile agents that can leverage help from humans can potentially accomplish more complex tasks than they could entirely on their own. We develop "Help, Anna!" (HANNA), an interactive photo-realistic simulator in which an agent fulfills object-finding tasks by requesting and interpreting natural language-and-vision assistance. An agent solving tasks in a HANNA environment can leverage simulated human assistants, called ANNA (Automatic Natural Navigation Assistants), which, upon request, provide natural language and visual instructions to direct the agent towards the goals. To address the HANNA problem, we develop a memory-augmented neural agent that hierarchically models multiple levels of decision-making, and an imitation learning algorithm that teaches the agent to avoid repeating past mistakes while simultaneously predicting its own chances of making future progress. Empirically, our approach is able to ask for help more effectively than competitive baselines and, thus, attains higher task success rate on both previously seen and previously unseen environments. We publicly release code and data at https://github.com/khanhptnk/hanna .
Social Relation Recognition in Egocentric Photostreams
May 12, 2019
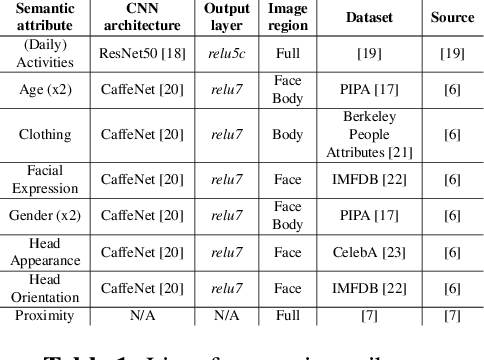

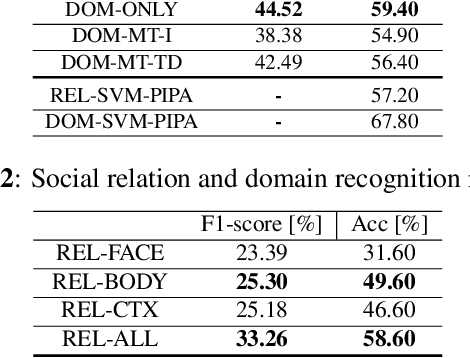
This paper proposes an approach to automatically categorize the social interactions of a user wearing a photo-camera 2fpm, by relying solely on what the camera is seeing. The problem is challenging due to the overwhelming complexity of social life and the extreme intra-class variability of social interactions captured under unconstrained conditions. We adopt the formalization proposed in Bugental's social theory, that groups human relations into five social domains with related categories. Our method is a new deep learning architecture that exploits the hierarchical structure of the label space and relies on a set of social attributes estimated at frame level to provide a semantic representation of social interactions. Experimental results on the new EgoSocialRelation dataset demonstrate the effectiveness of our proposal.
VITAL: A Visual Interpretation on Text with Adversarial Learning for Image Labeling
Jul 26, 2019
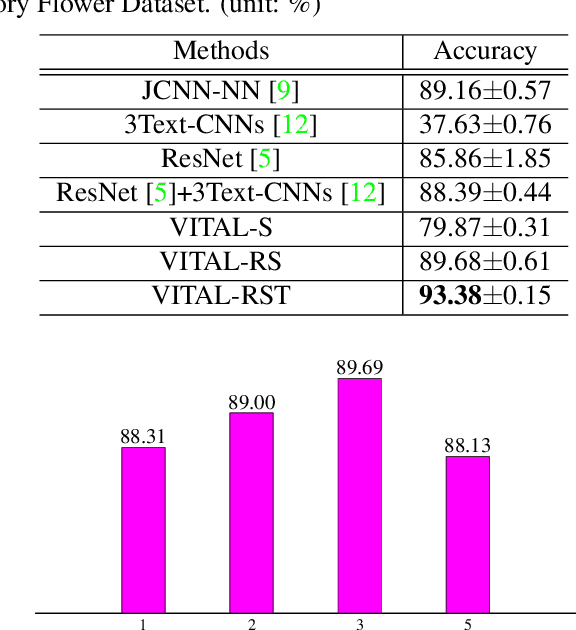
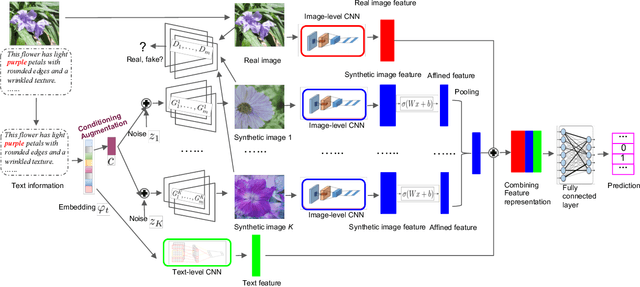
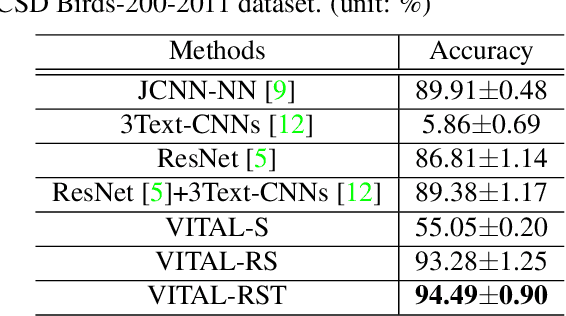
In this paper, we propose a novel way to interpret text information by extracting visual feature presentation from multiple high-resolution and photo-realistic synthetic images generated by Text-to-image Generative Adversarial Network (GAN) to improve the performance of image labeling. Firstly, we design a stacked Generative Multi-Adversarial Network (GMAN), StackGMAN++, a modified version of the current state-of-the-art Text-to-image GAN, StackGAN++, to generate multiple synthetic images with various prior noises conditioned on a text. And then we extract deep visual features from the generated synthetic images to explore the underlying visual concepts for text. Finally, we combine image-level visual feature, text-level feature and visual features based on synthetic images together to predict labels for images. We conduct experiments on two benchmark datasets and the experimental results clearly demonstrate the efficacy of our proposed approach.
Real-time Burst Photo Selection Using a Light-Head Adversarial Network
Mar 20, 2018
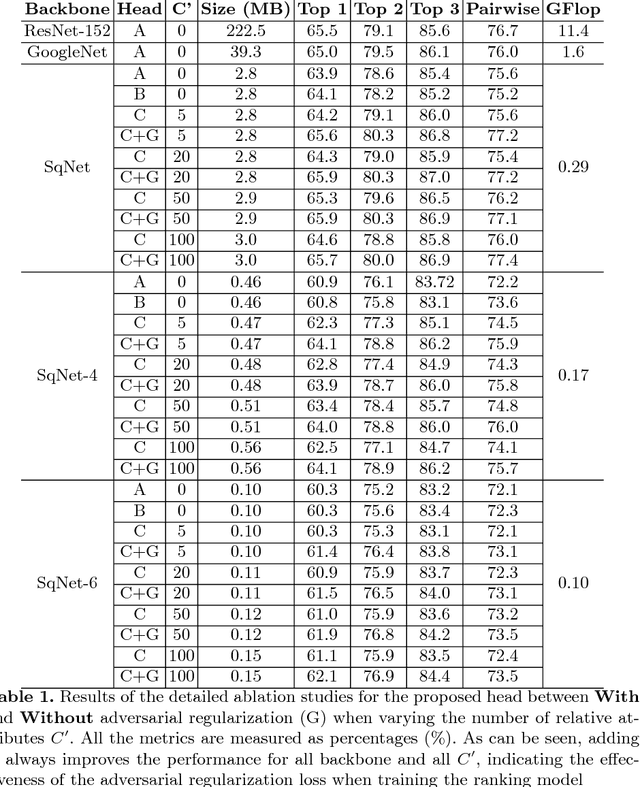
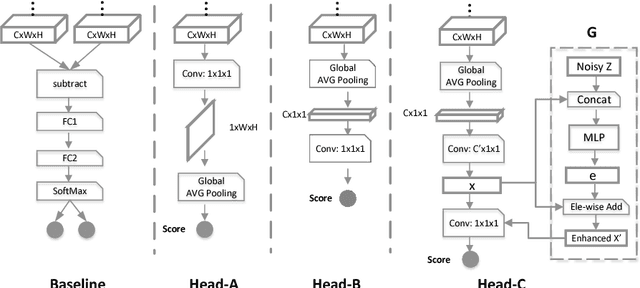
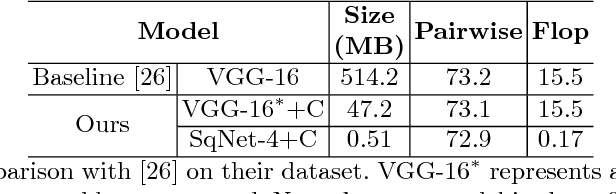
We present an automatic moment capture system that runs in real-time on mobile cameras. The system is designed to run in the viewfinder mode and capture a burst sequence of frames before and after the shutter is pressed. For each frame, the system predicts in real-time a "goodness" score, based on which the best moment in the burst can be selected immediately after the shutter is released, without any user interference. To solve the problem, we develop a highly efficient deep neural network ranking model, which implicitly learns a "latent relative attribute" space to capture subtle visual differences within a sequence of burst images. Then the overall goodness is computed as a linear aggregation of the goodnesses of all the latent attributes. The latent relative attributes and the aggregation function can be seamlessly integrated in one fully convolutional network and trained in an end-to-end fashion. To obtain a compact model which can run on mobile devices in real-time, we have explored and evaluated a wide range of network design choices, taking into account the constraints of model size, computational cost, and accuracy. Extensive studies show that the best frame predicted by our model hit users' top-1 (out of 11 on average) choice for $64.1\%$ cases and top-3 choices for $86.2\%$ cases. Moreover, the model(only 0.47M Bytes) can run in real time on mobile devices, e.g. only 13ms on iPhone 7 for one frame prediction.
Netizen-Style Commenting on Fashion Photos: Dataset and Diversity Measures
Jan 31, 2018
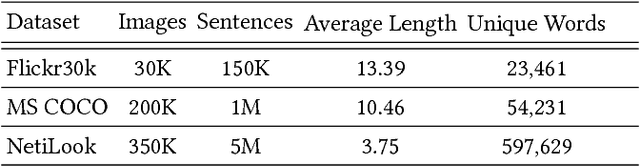

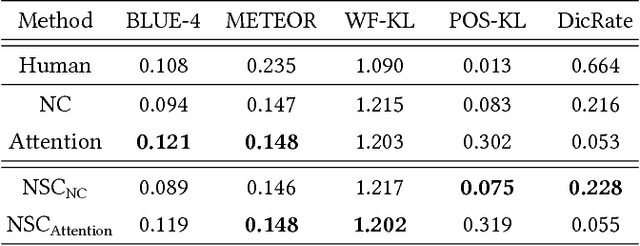
Recently, deep neural network models have achieved promising results in image captioning task. Yet, "vanilla" sentences, only describing shallow appearances (e.g., types, colors), generated by current works are not satisfied netizen style resulting in lacking engagements, contexts, and user intentions. To tackle this problem, we propose Netizen Style Commenting (NSC), to automatically generate characteristic comments to a user-contributed fashion photo. We are devoted to modulating the comments in a vivid "netizen" style which reflects the culture in a designated social community and hopes to facilitate more engagement with users. In this work, we design a novel framework that consists of three major components: (1) We construct a large-scale clothing dataset named NetiLook, which contains 300K posts (photos) with 5M comments to discover netizen-style comments. (2) We propose three unique measures to estimate the diversity of comments. (3) We bring diversity by marrying topic models with neural networks to make up the insufficiency of conventional image captioning works. Experimenting over Flickr30k and our NetiLook datasets, we demonstrate our proposed approaches benefit fashion photo commenting and improve image captioning tasks both in accuracy and diversity.
Beyond Frontal Faces: Improving Person Recognition Using Multiple Cues
Jan 30, 2015
We explore the task of recognizing peoples' identities in photo albums in an unconstrained setting. To facilitate this, we introduce the new People In Photo Albums (PIPA) dataset, consisting of over 60000 instances of 2000 individuals collected from public Flickr photo albums. With only about half of the person images containing a frontal face, the recognition task is very challenging due to the large variations in pose, clothing, camera viewpoint, image resolution and illumination. We propose the Pose Invariant PErson Recognition (PIPER) method, which accumulates the cues of poselet-level person recognizers trained by deep convolutional networks to discount for the pose variations, combined with a face recognizer and a global recognizer. Experiments on three different settings confirm that in our unconstrained setup PIPER significantly improves on the performance of DeepFace, which is one of the best face recognizers as measured on the LFW dataset.
Semantic Bottleneck Scene Generation
Nov 26, 2019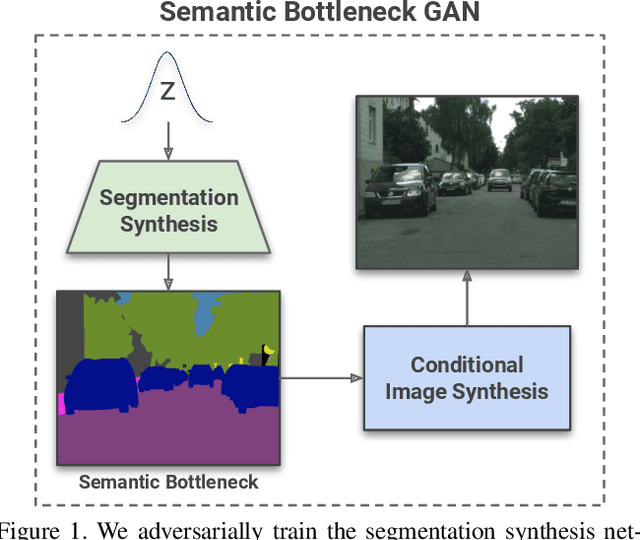
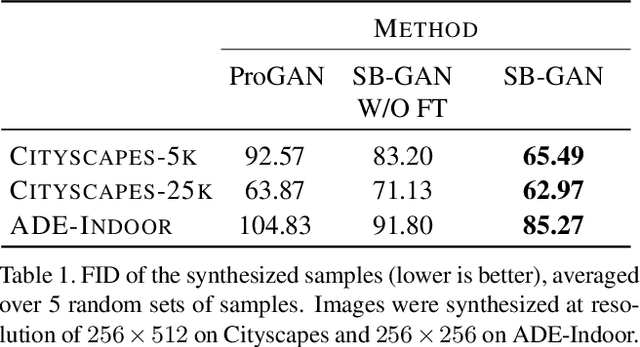
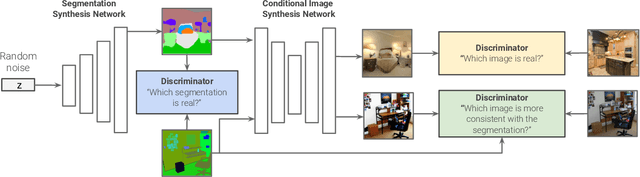
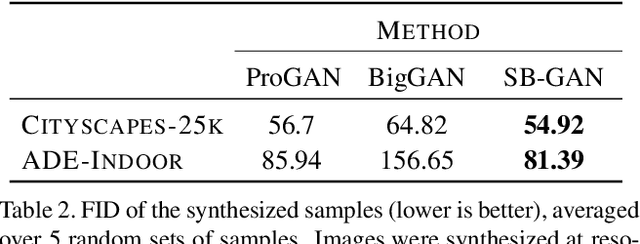
Coupling the high-fidelity generation capabilities of label-conditional image synthesis methods with the flexibility of unconditional generative models, we propose a semantic bottleneck GAN model for unconditional synthesis of complex scenes. We assume pixel-wise segmentation labels are available during training and use them to learn the scene structure. During inference, our model first synthesizes a realistic segmentation layout from scratch, then synthesizes a realistic scene conditioned on that layout. For the former, we use an unconditional progressive segmentation generation network that captures the distribution of realistic semantic scene layouts. For the latter, we use a conditional segmentation-to-image synthesis network that captures the distribution of photo-realistic images conditioned on the semantic layout. When trained end-to-end, the resulting model outperforms state-of-the-art generative models in unsupervised image synthesis on two challenging domains in terms of the Frechet Inception Distance and user-study evaluations. Moreover, we demonstrate the generated segmentation maps can be used as additional training data to strongly improve recent segmentation-to-image synthesis networks.
Rethinking Fully Convolutional Networks for the Analysis of Photoluminescence Wafer Images
Mar 01, 2020
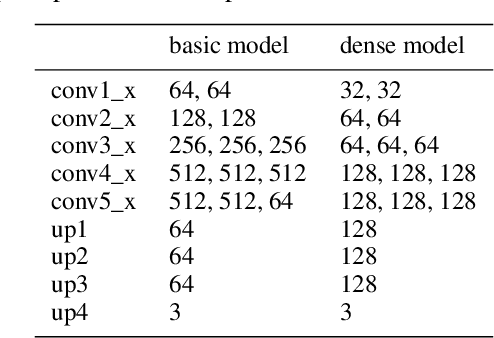
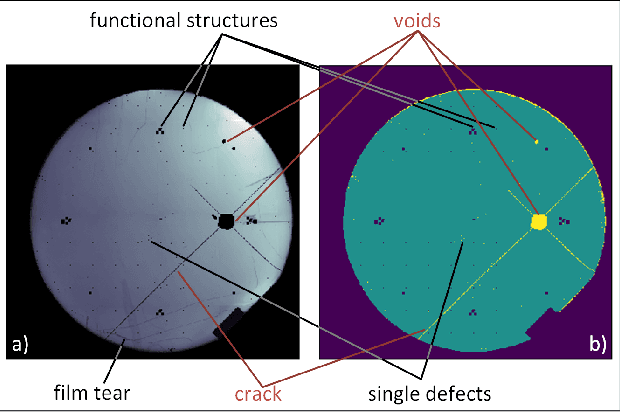
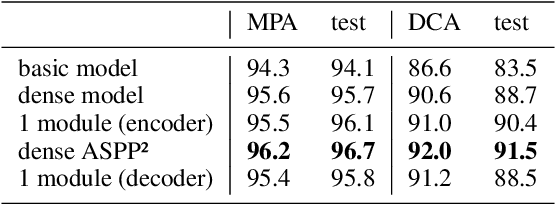
The manufacturing of light-emitting diodes is a complex semiconductor-manufacturing process, interspersed with different measurements. Among the employed measurements, photoluminescence imaging has several advantages, namely being a non-destructive, fast and thus cost-effective measurement. On a photoluminescence measurement image of an LED wafer, every pixel corresponds to an LED chip's brightness after photo-excitation, revealing chip performance information. However, generating a chip-fine defect map of the LED wafer, based on photoluminescence images, proves challenging for multiple reasons: on the one hand, the measured brightness values vary from image to image, in addition to local spots of differing brightness. On the other hand, certain defect structures may assume multiple shapes, sizes and brightness gradients, where salient brightness values may correspond to defective LED chips, measurement artefacts or non-defective structures. In this work, we revisit the creation of chip-fine defect maps using fully convolutional networks and show that the problem of segmenting objects at multiple scales can be improved by the incorporation of densely connected convolutional blocks and atrous spatial pyramid pooling modules. We also share implementation details and our experiences with training networks with small datasets of measurement images. The proposed architecture significantly improves the segmentation accuracy of highly variable defect structures over our previous version.
Environment-agnostic Multitask Learning for Natural Language Grounded Navigation
Mar 01, 2020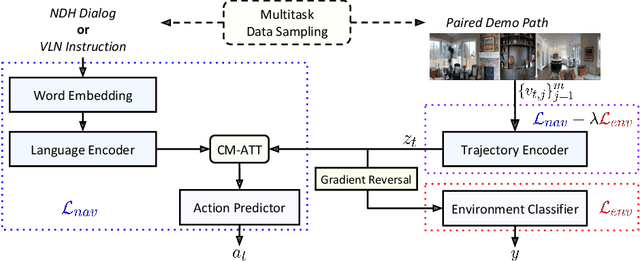
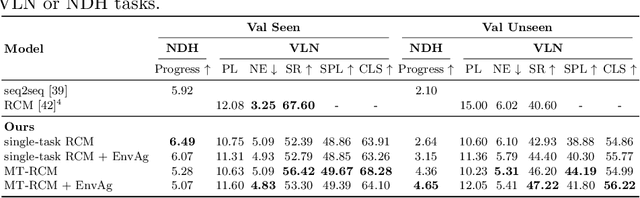
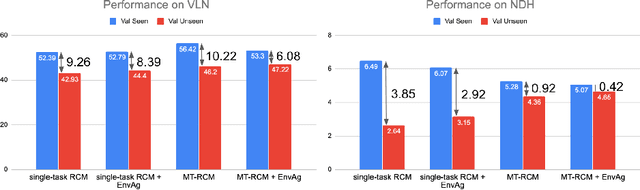
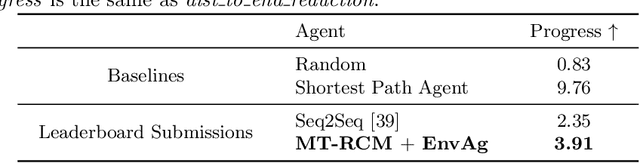
Recent research efforts enable study for natural language grounded navigation in photo-realistic environments, e.g., following natural language instructions or dialog. However, existing methods tend to overfit training data in seen environments and fail to generalize well in previously unseen environments. In order to close the gap between seen and unseen environments, we aim at learning a generalized navigation model from two novel perspectives: (1) we introduce a multitask navigation model that can be seamlessly trained on both Vision-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks, which benefits from richer natural language guidance and effectively transfers knowledge across tasks; (2) we propose to learn environment-agnostic representations for the navigation policy that are invariant among the environments seen during training, thus generalizing better on unseen environments. Extensive experiments show that our navigation model trained using environment-agnostic multitask learning significantly reduces the performance gap between seen and unseen environments and outperforms the baselines on unseen environments by 16% (relative measure on success rate) on VLN and 120% (goal progress) on NDH, establishing a new state-of-the-art for the NDH task. The code for training the navigation model using environment-agnostic multitask learning is available at https://github.com/google-research/valan.
Visual Attribute Transfer through Deep Image Analogy
Jun 06, 2017

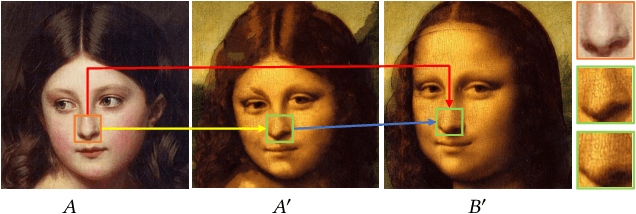

We propose a new technique for visual attribute transfer across images that may have very different appearance but have perceptually similar semantic structure. By visual attribute transfer, we mean transfer of visual information (such as color, tone, texture, and style) from one image to another. For example, one image could be that of a painting or a sketch while the other is a photo of a real scene, and both depict the same type of scene. Our technique finds semantically-meaningful dense correspondences between two input images. To accomplish this, it adapts the notion of "image analogy" with features extracted from a Deep Convolutional Neutral Network for matching; we call our technique Deep Image Analogy. A coarse-to-fine strategy is used to compute the nearest-neighbor field for generating the results. We validate the effectiveness of our proposed method in a variety of cases, including style/texture transfer, color/style swap, sketch/painting to photo, and time lapse.