 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
CG-GAN: An Interactive Evolutionary GAN-based Approach for Facial Composite Generation)
Nov 28, 2019


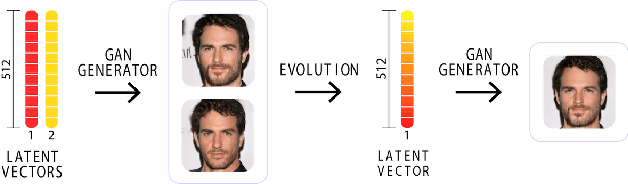
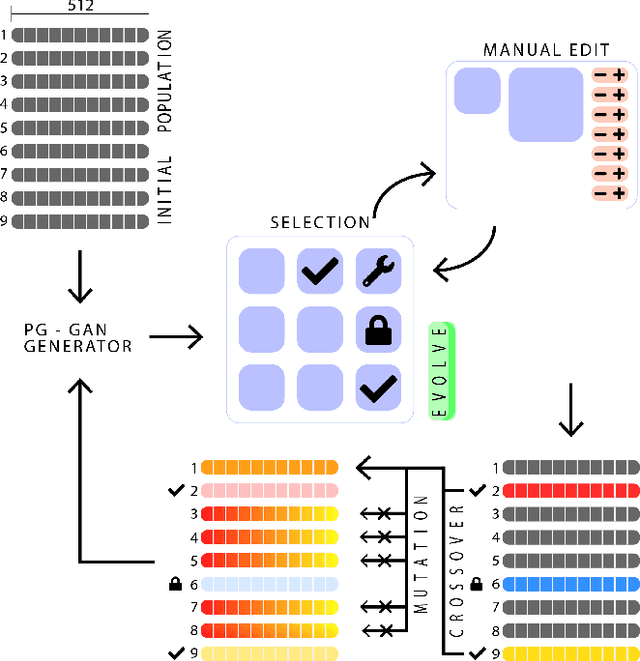
Facial composites are graphical representations of an eyewitness's memory of a face. Many digital systems are available for the creation of such composites but are either unable to reproduce features unless previously designed or do not allow holistic changes to the image. In this paper, we improve the efficiency of composite creation by removing the reliance on expert knowledge and letting the system learn to represent faces from examples. The novel approach, Composite Generating GAN (CG-GAN), applies generative and evolutionary computation to allow casual users to easily create facial composites. Specifically, CG-GAN utilizes the generator network of a pg-GAN to create high-resolution human faces. Users are provided with several functions to interactively breed and edit faces. CG-GAN offers a novel way of generating and handling static and animated photo-realistic facial composites, with the possibility of combining multiple representations of the same perpetrator, generated by different eyewitnesses.
AutoRemover: Automatic Object Removal for Autonomous Driving Videos
Nov 28, 2019
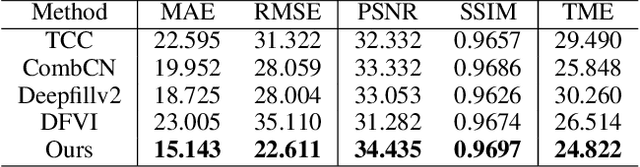
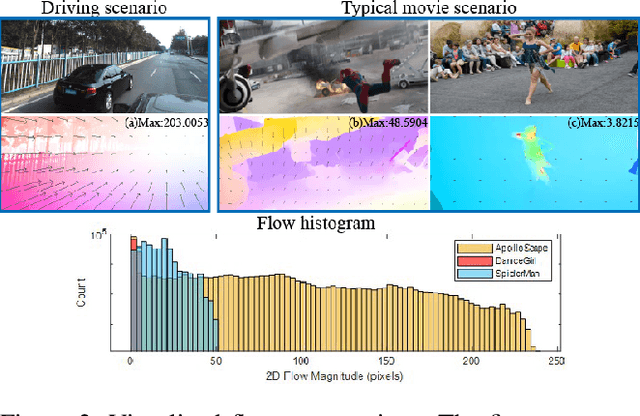
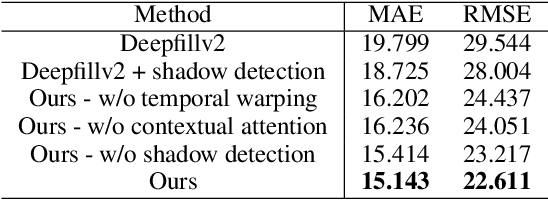
Motivated by the need for photo-realistic simulation in autonomous driving, in this paper we present a video inpainting algorithm \emph{AutoRemover}, designed specifically for generating street-view videos without any moving objects. In our setup we have two challenges: the first is the shadow, shadows are usually unlabeled but tightly coupled with the moving objects. The second is the large ego-motion in the videos. To deal with shadows, we build up an autonomous driving shadow dataset and design a deep neural network to detect shadows automatically. To deal with large ego-motion, we take advantage of the multi-source data, in particular the 3D data, in autonomous driving. More specifically, the geometric relationship between frames is incorporated into an inpainting deep neural network to produce high-quality structurally consistent video output. Experiments show that our method outperforms other state-of-the-art (SOTA) object removal algorithms, reducing the RMSE by over $19\%$.
Source Camera Attribution from Strongly Stabilized Videos
Nov 26, 2019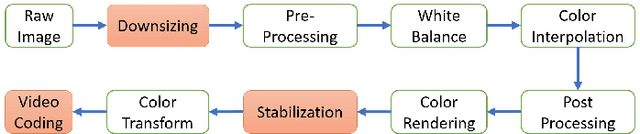
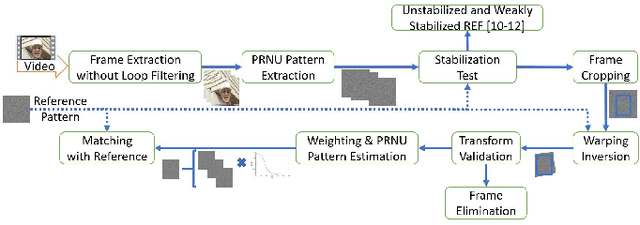
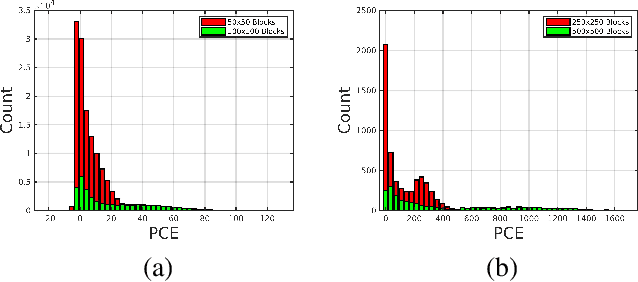
The in-camera image stabilization technology deployed by most cameras today poses one of the most significant challenges to photo-response non-uniformity based source camera attribution from videos. When performed digitally, stabilization involves cropping, warping, and inpainting of video frames to eliminate unwanted camera motion. Hence, successful attribution requires the inversion of these transformations in a blind manner. To address this challenge, we introduce a source camera verification method for videos that takes into account the spatially variant nature of stabilization transformations. Our method identifies transformations at a sub-frame level and incorporates a number of constraints to validate their correctness. The method also adopts a holistic approach in countering disruptive effects of other video generation steps, such as video coding and downsizing, for more reliable attribution. Tests performed on a public dataset of stabilized videos show that the proposed method improves attribution rate over existing methods by 17-19\% without a significant impact on false attribution rate.
One Shot 3D Photography
Sep 01, 2020
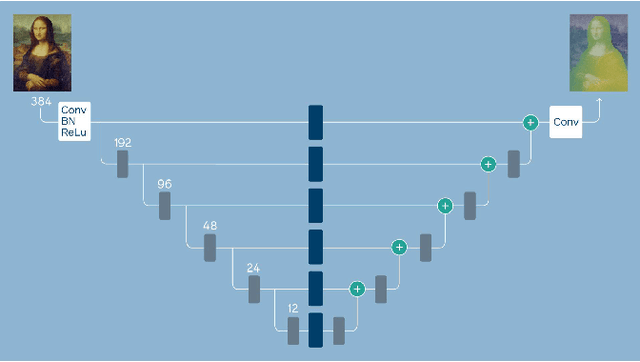

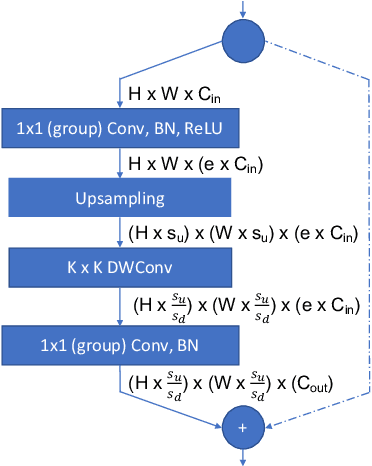
3D photography is a new medium that allows viewers to more fully experience a captured moment. In this work, we refer to a 3D photo as one that displays parallax induced by moving the viewpoint (as opposed to a stereo pair with a fixed viewpoint). 3D photos are static in time, like traditional photos, but are displayed with interactive parallax on mobile or desktop screens, as well as on Virtual Reality devices, where viewing it also includes stereo. We present an end-to-end system for creating and viewing 3D photos, and the algorithmic and design choices therein. Our 3D photos are captured in a single shot and processed directly on a mobile device. The method starts by estimating depth from the 2D input image using a new monocular depth estimation network that is optimized for mobile devices. It performs competitively to the state-of-the-art, but has lower latency and peak memory consumption and uses an order of magnitude fewer parameters. The resulting depth is lifted to a layered depth image, and new geometry is synthesized in parallax regions. We synthesize color texture and structures in the parallax regions as well, using an inpainting network, also optimized for mobile devices, on the LDI directly. Finally, we convert the result into a mesh-based representation that can be efficiently transmitted and rendered even on low-end devices and over poor network connections. Altogether, the processing takes just a few seconds on a mobile device, and the result can be instantly viewed and shared. We perform extensive quantitative evaluation to validate our system and compare its new components against the current state-of-the-art.
* Project page: https://facebookresearch.github.io/one_shot_3d_photography/ Code: https://github.com/facebookresearch/one_shot_3d_photography
TailorGAN: Making User-Defined Fashion Designs
Jan 20, 2020

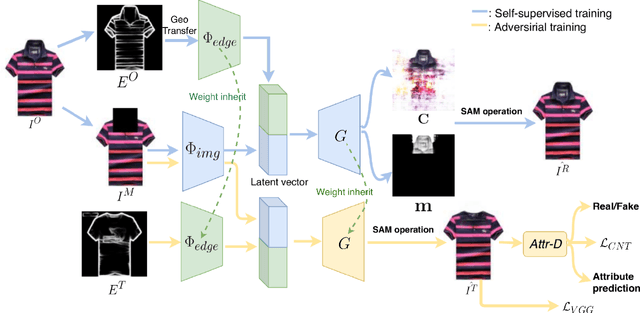

Attribute editing has become an important and emerging topic of computer vision. In this paper, we consider a task: given a reference garment image A and another image B with target attribute (collar/sleeve), generate a photo-realistic image which combines the texture from reference A and the new attribute from reference B. The highly convoluted attributes and the lack of paired data are the main challenges to the task. To overcome those limitations, we propose a novel self-supervised model to synthesize garment images with disentangled attributes (e.g., collar and sleeves) without paired data. Our method consists of a reconstruction learning step and an adversarial learning step. The model learns texture and location information through reconstruction learning. And, the model's capability is generalized to achieve single-attribute manipulation by adversarial learning. Meanwhile, we compose a new dataset, named GarmentSet, with annotation of landmarks of collars and sleeves on clean garment images. Extensive experiments on this dataset and real-world samples demonstrate that our method can synthesize much better results than the state-of-the-art methods in both quantitative and qualitative comparisons.
* fashion
Deep Semantic Face Deblurring
Jan 19, 2020
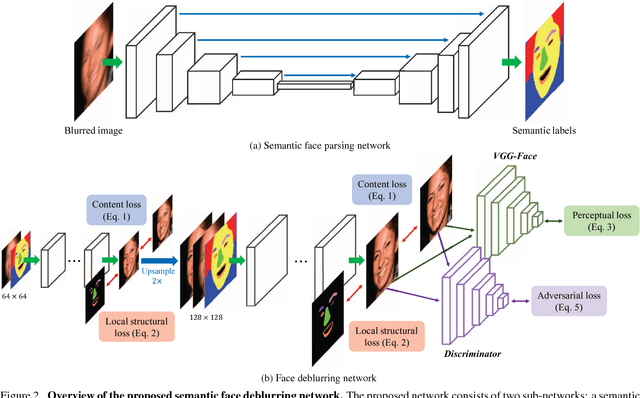
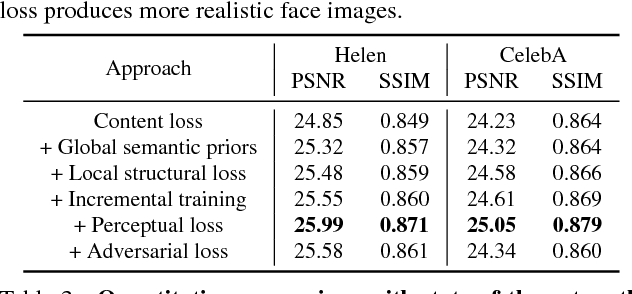

In this paper, we propose an effective and efficient face deblurring algorithm by exploiting semantic cues via deep convolutional neural networks. As the human faces are highly structured and share unified facial components (e.g., eyes and mouths), such semantic information provides a strong prior for restoration. We incorporate face semantic labels as input priors and propose an adaptive structural loss to regularize facial local structures within an end-to-end deep convolutional neural network. Specifically, we first use a coarse deblurring network to reduce the motion blur on the input face image. We then adopt a parsing network to extract the semantic features from the coarse deblurred image. Finally, the fine deblurring network utilizes the semantic information to restore a clear face image. We train the network with perceptual and adversarial losses to generate photo-realistic results. The proposed method restores sharp images with more accurate facial features and details. Quantitative and qualitative evaluations demonstrate that the proposed face deblurring algorithm performs favorably against the state-of-the-art methods in terms of restoration quality, face recognition and execution speed.
Pixel-wise Crowd Understanding via Synthetic Data
Aug 03, 2020
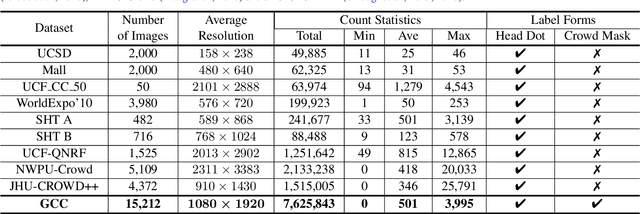
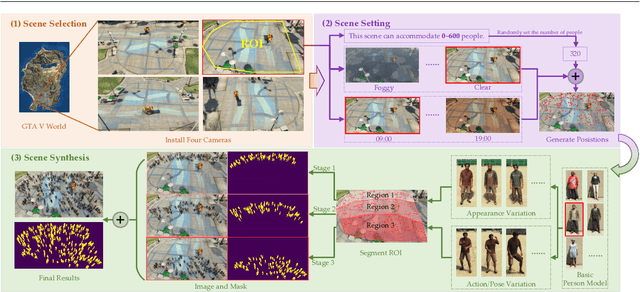

Crowd analysis via computer vision techniques is an important topic in the field of video surveillance, which has wide-spread applications including crowd monitoring, public safety, space design and so on. Pixel-wise crowd understanding is the most fundamental task in crowd analysis because of its finer results for video sequences or still images than other analysis tasks. Unfortunately, pixel-level understanding needs a large amount of labeled training data. Annotating them is an expensive work, which causes that current crowd datasets are small. As a result, most algorithms suffer from over-fitting to varying degrees. In this paper, take crowd counting and segmentation as examples from the pixel-wise crowd understanding, we attempt to remedy these problems from two aspects, namely data and methodology. Firstly, we develop a free data collector and labeler to generate synthetic and labeled crowd scenes in a computer game, Grand Theft Auto V. Then we use it to construct a large-scale, diverse synthetic crowd dataset, which is named as "GCC Dataset". Secondly, we propose two simple methods to improve the performance of crowd understanding via exploiting the synthetic data. To be specific, 1) supervised crowd understanding: pre-train a crowd analysis model on the synthetic data, then fine-tune it using the real data and labels, which makes the model perform better on the real world; 2) crowd understanding via domain adaptation: translate the synthetic data to photo-realistic images, then train the model on translated data and labels. As a result, the trained model works well in real crowd scenes.
Bringing Old Photos Back to Life
Apr 20, 2020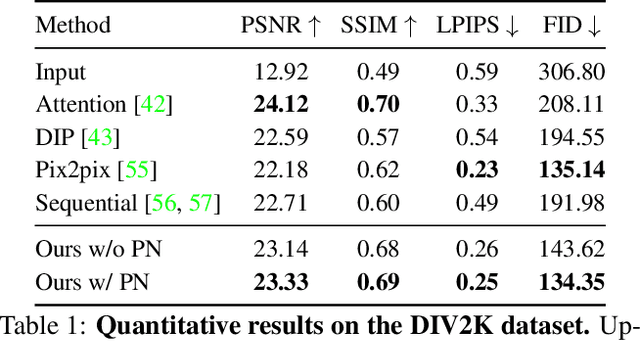
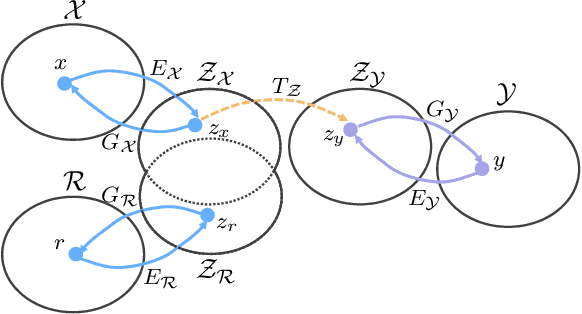
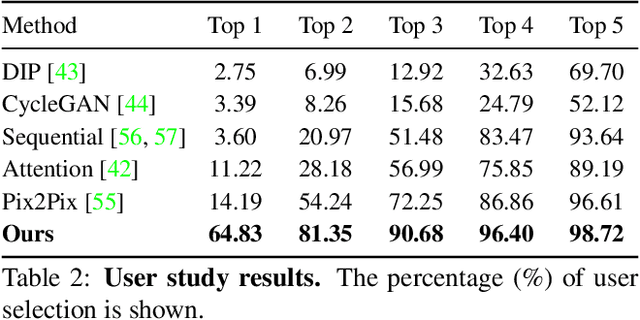
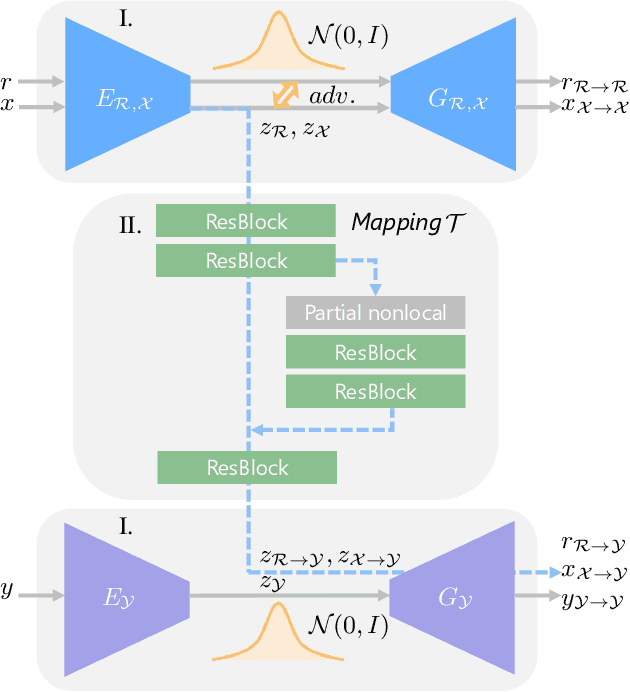
We propose to restore old photos that suffer from severe degradation through a deep learning approach. Unlike conventional restoration tasks that can be solved through supervised learning, the degradation in real photos is complex and the domain gap between synthetic images and real old photos makes the network fail to generalize. Therefore, we propose a novel triplet domain translation network by leveraging real photos along with massive synthetic image pairs. Specifically, we train two variational autoencoders (VAEs) to respectively transform old photos and clean photos into two latent spaces. And the translation between these two latent spaces is learned with synthetic paired data. This translation generalizes well to real photos because the domain gap is closed in the compact latent space. Besides, to address multiple degradations mixed in one old photo, we design a global branch with a partial nonlocal block targeting to the structured defects, such as scratches and dust spots, and a local branch targeting to the unstructured defects, such as noises and blurriness. Two branches are fused in the latent space, leading to improved capability to restore old photos from multiple defects. The proposed method outperforms state-of-the-art methods in terms of visual quality for old photos restoration.
SurfaceNet+: An End-to-end 3D Neural Network for Very Sparse Multi-view Stereopsis
May 26, 2020
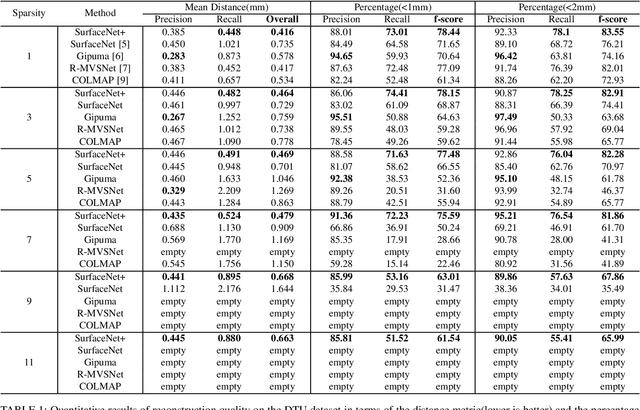
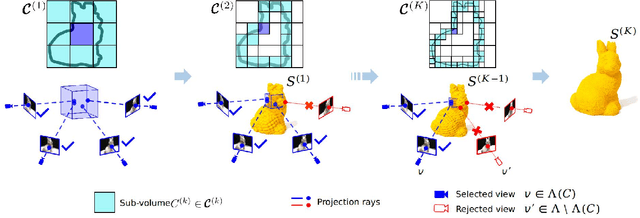
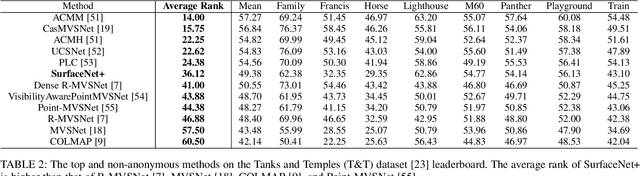
Multi-view stereopsis (MVS) tries to recover the 3D model from 2D images. As the observations become sparser, the significant 3D information loss makes the MVS problem more challenging. Instead of only focusing on densely sampled conditions, we investigate sparse-MVS with large baseline angles since the sparser sensation is more practical and more cost-efficient. By investigating various observation sparsities, we show that the classical depth-fusion pipeline becomes powerless for the case with a larger baseline angle that worsens the photo-consistency check. As another line of the solution, we present SurfaceNet+, a volumetric method to handle the 'incompleteness' and the 'inaccuracy' problems induced by a very sparse MVS setup. Specifically, the former problem is handled by a novel volume-wise view selection approach. It owns superiority in selecting valid views while discarding invalid occluded views by considering the geometric prior. Furthermore, the latter problem is handled via a multi-scale strategy that consequently refines the recovered geometry around the region with the repeating pattern. The experiments demonstrate the tremendous performance gap between SurfaceNet+ and state-of-the-art methods in terms of precision and recall. Under the extreme sparse-MVS settings in two datasets, where existing methods can only return very few points, SurfaceNet+ still works as well as in the dense MVS setting. The benchmark and the implementation are publicly available at https://github.com/mjiUST/SurfaceNet-plus.
* Accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), May 2020