 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Multi-modal Datasets for Super-resolution
Apr 13, 2020

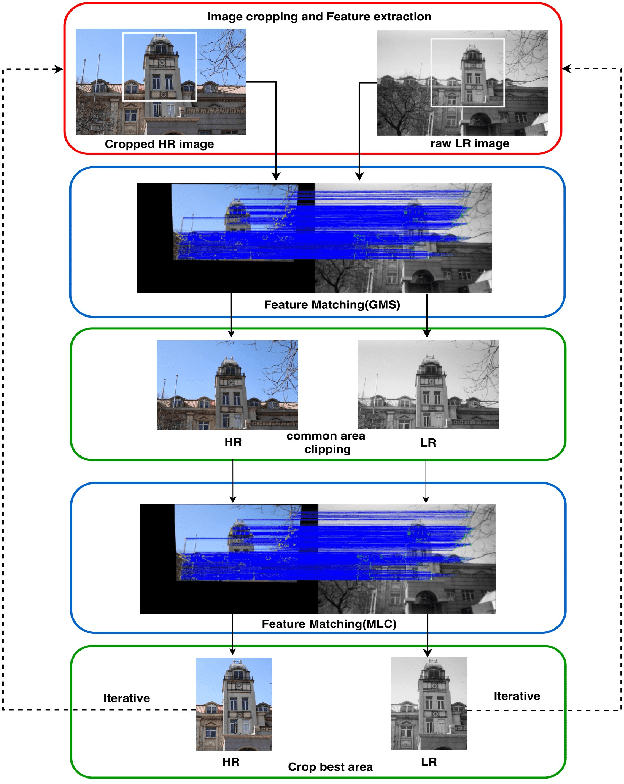
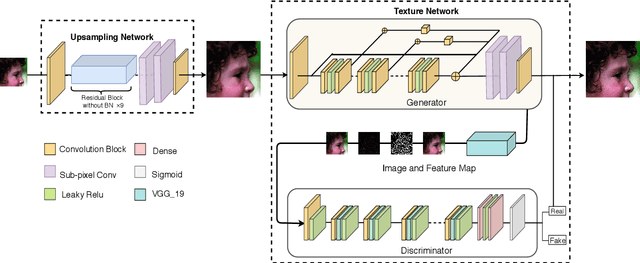

Nowdays, most datasets used to train and evaluate super-resolution models are single-modal simulation datasets. However, due to the variety of image degradation types in the real world, models trained on single-modal simulation datasets do not always have good robustness and generalization ability in different degradation scenarios. Previous work tended to focus only on true-color images. In contrast, we first proposed real-world black-and-white old photo datasets for super-resolution (OID-RW), which is constructed using two methods of manually filling pixels and shooting with different cameras. The dataset contains 82 groups of images, including 22 groups of character type and 60 groups of landscape and architecture. At the same time, we also propose a multi-modal degradation dataset (MDD400) to solve the super-resolution reconstruction in real-life image degradation scenarios. We managed to simulate the process of generating degraded images by the following four methods: interpolation algorithm, CNN network, GAN network and capturing videos with different bit rates. Our experiments demonstrate that not only the models trained on our dataset have better generalization capability and robustness, but also the trained images can maintain better edge contours and texture features.
Close-Proximity Underwater Terrain Mapping Using Learning-based Coarse Range Estimation
Jan 02, 2020
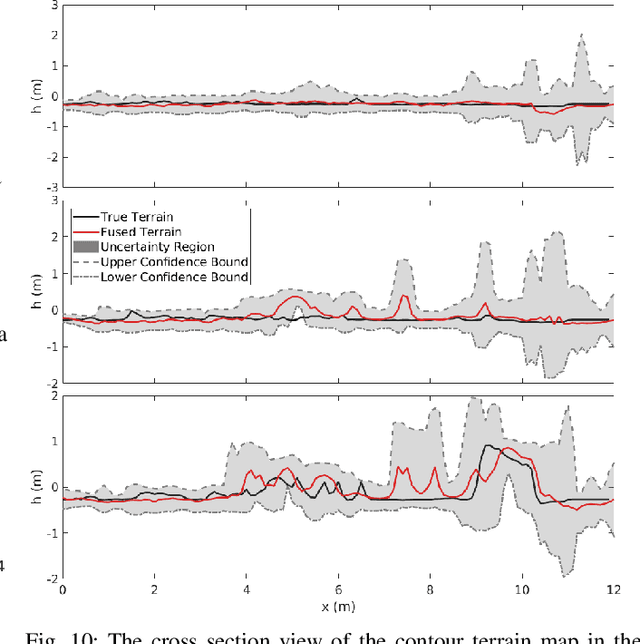
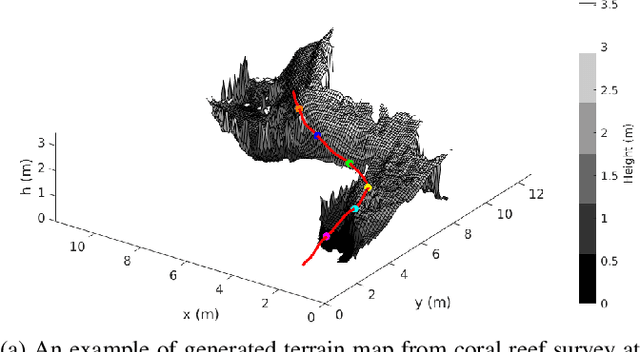
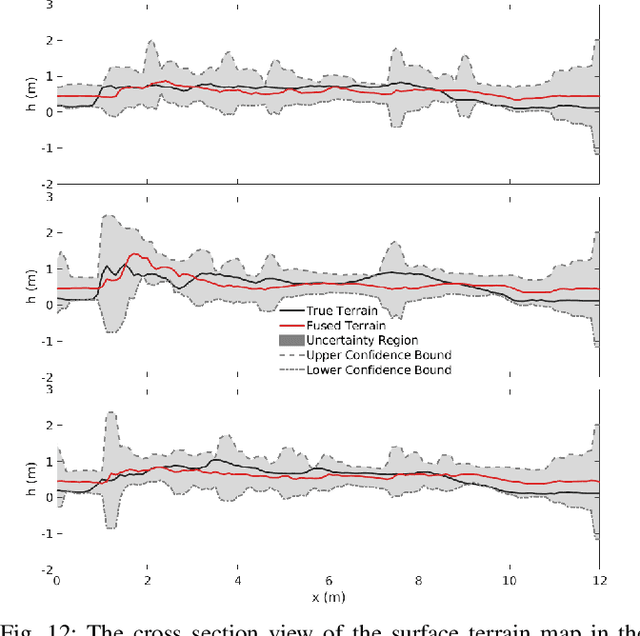
This paper presents a novel approach to underwater terrain mapping for Autonomous Underwater Vehicles (AUVs) operating in close proximity to complex 3D environments. The approach leverages a coarse learning-based scene range estimator from monocular images, which can filter transient objects such as fish and lighting aberrations. The proposed methodology then creates a probabilistic elevation map of the terrain using a learning-based scene range estimator as a sensor. The approach considers uncertainty in estimated scene range and robot pose as the AUV moves through the environment. The resulting elevation map can be used for reactive path planning and obstacle avoidance to allow robotic systems to follow the underwater terrain as closely as possible. The performance of our approach is evaluated in simulation by comparing the reconstructed terrain to ground truth reference maps in an photo-realistic underwater environment. The method is also demonstrated using field data collected within a coral reef environment by an AUV.
CookGAN: Meal Image Synthesis from Ingredients
Feb 25, 2020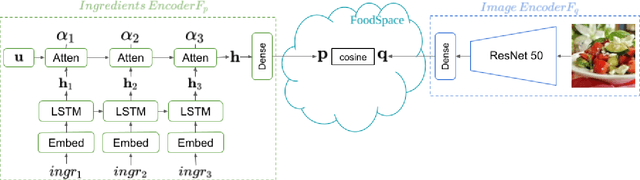
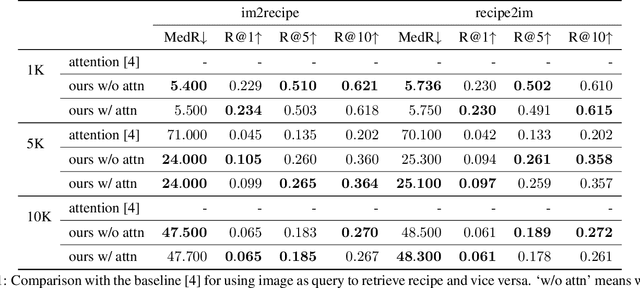
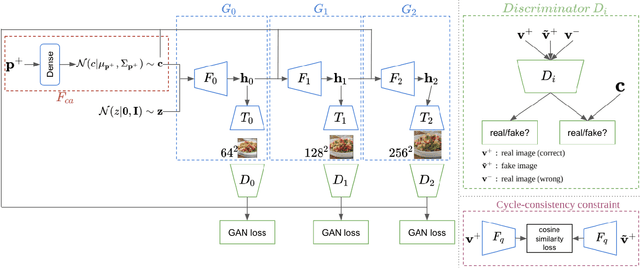
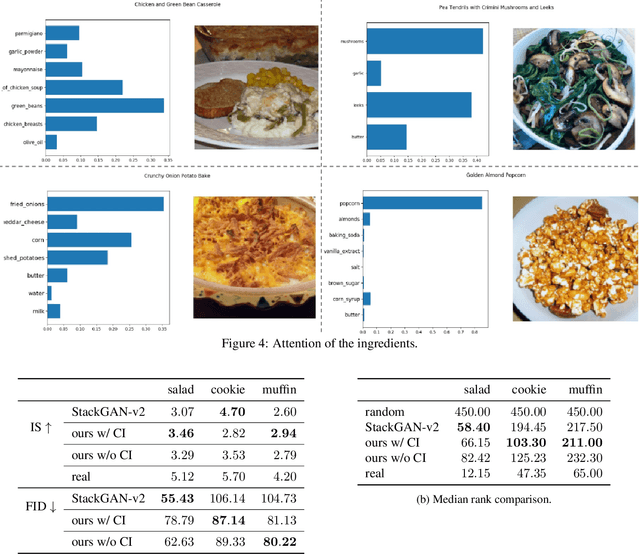
In this work we propose a new computational framework, based on generative deep models, for synthesis of photo-realistic food meal images from textual list of its ingredients. Previous works on synthesis of images from text typically rely on pre-trained text models to extract text features, followed by generative neural networks (GAN) aimed to generate realistic images conditioned on the text features. These works mainly focus on generating spatially compact and well-defined categories of objects, such as birds or flowers, but meal images are significantly more complex, consisting of multiple ingredients whose appearance and spatial qualities are further modified by cooking methods. To generate real-like meal images from ingredients, we propose Cook Generative Adversarial Networks (CookGAN), CookGAN first builds an attention-based ingredients-image association model, which is then used to condition a generative neural network tasked with synthesizing meal images. Furthermore, a cycle-consistent constraint is added to further improve image quality and control appearance. Experiments show our model is able to generate meal images corresponding to the ingredients.
Background Matting: The World is Your Green Screen
Apr 10, 2020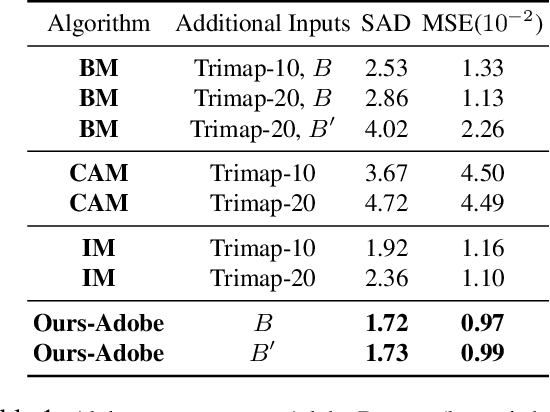
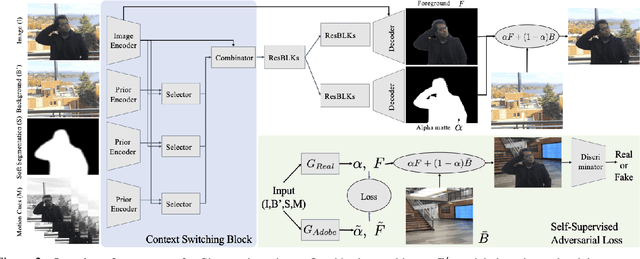
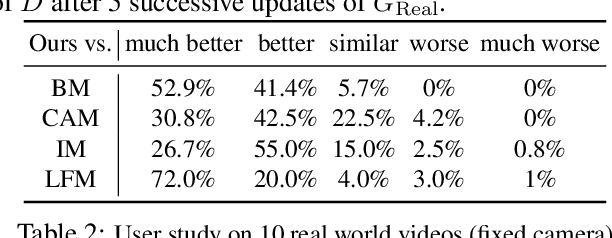

We propose a method for creating a matte -- the per-pixel foreground color and alpha -- of a person by taking photos or videos in an everyday setting with a handheld camera. Most existing matting methods require a green screen background or a manually created trimap to produce a good matte. Automatic, trimap-free methods are appearing, but are not of comparable quality. In our trimap free approach, we ask the user to take an additional photo of the background without the subject at the time of capture. This step requires a small amount of foresight but is far less time-consuming than creating a trimap. We train a deep network with an adversarial loss to predict the matte. We first train a matting network with supervised loss on ground truth data with synthetic composites. To bridge the domain gap to real imagery with no labeling, we train another matting network guided by the first network and by a discriminator that judges the quality of composites. We demonstrate results on a wide variety of photos and videos and show significant improvement over the state of the art.
Instance Selection for GANs
Jul 30, 2020
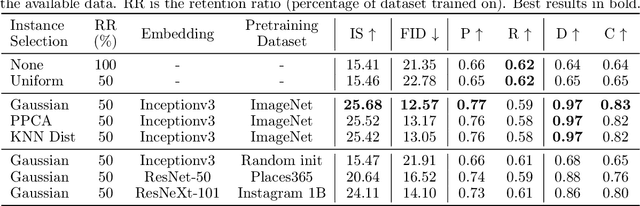
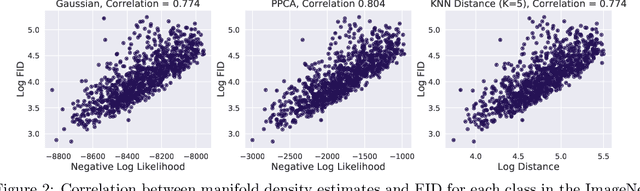
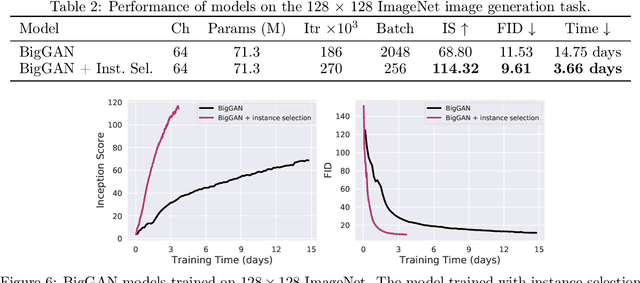
Recent advances in Generative Adversarial Networks (GANs) have led to their widespread adoption for the purposes of generating high quality synthetic imagery. While capable of generating photo-realistic images, these models often produce unrealistic samples which fall outside of the data manifold. Several recently proposed techniques attempt to avoid spurious samples, either by rejecting them after generation, or by truncating the model's latent space. While effective, these methods are inefficient, as large portions of model capacity are dedicated towards representing samples that will ultimately go unused. In this work we propose a novel approach to improve sample quality: altering the training dataset via instance selection before model training has taken place. To this end, we embed data points into a perceptual feature space and use a simple density model to remove low density regions from the data manifold. By refining the empirical data distribution before training we redirect model capacity towards high-density regions, which ultimately improves sample fidelity. We evaluate our method by training a Self-Attention GAN on ImageNet at 64x64 resolution, where we outperform the current state-of-the-art models on this task while using 1/2 of the parameters. We also highlight training time savings by training a BigGAN on ImageNet at 128x128 resolution, achieving a 66% increase in Inception Score and a 16% improvement in FID over the baseline model with less than 1/4 the training time.
Deep Cropping via Attention Box Prediction and Aesthetics Assessment
Oct 22, 2017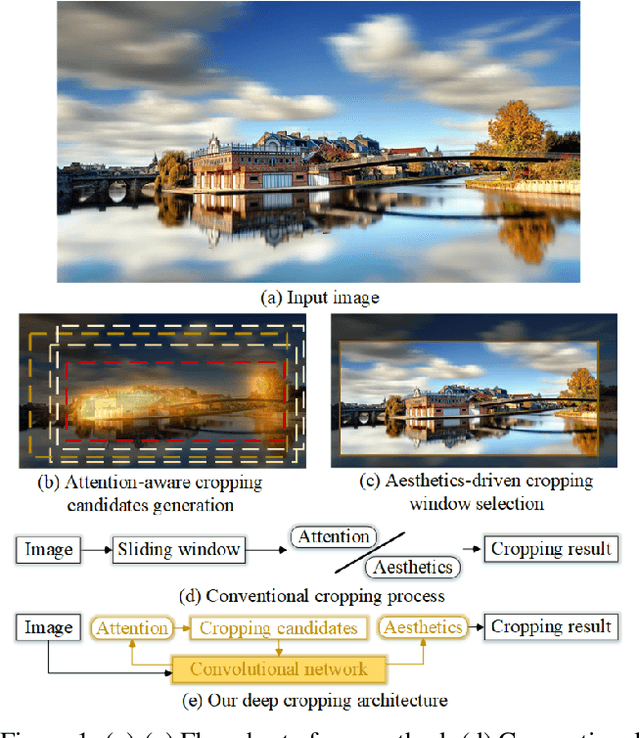
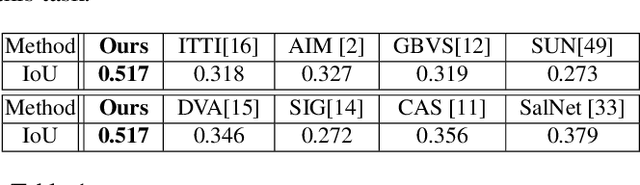

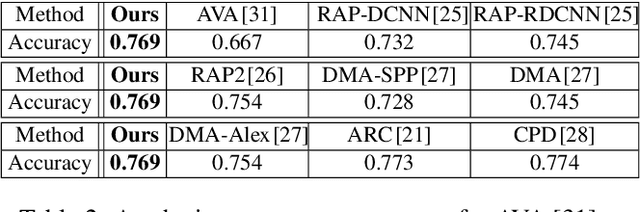
We model the photo cropping problem as a cascade of attention box regression and aesthetic quality classification, based on deep learning. A neural network is designed that has two branches for predicting attention bounding box and analyzing aesthetics, respectively. The predicted attention box is treated as an initial crop window where a set of cropping candidates are generated around it, without missing important information. Then, aesthetics assessment is employed to select the final crop as the one with the best aesthetic quality. With our network, cropping candidates share features within full-image convolutional feature maps, thus avoiding repeated feature computation and leading to higher computation efficiency. Via leveraging rich data for attention prediction and aesthetics assessment, the proposed method produces high-quality cropping results, even with the limited availability of training data for photo cropping. The experimental results demonstrate the competitive results and fast processing speed (5 fps with all steps).
Text Classification for Azerbaijani Language Using Machine Learning and Embedding
Dec 26, 2019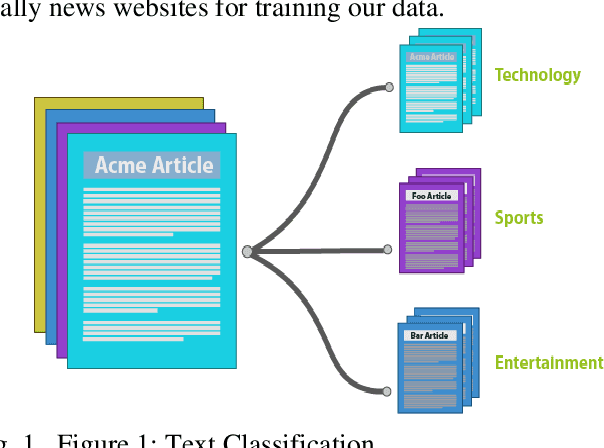
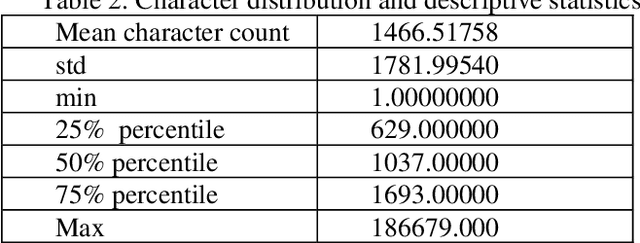
Text classification systems will help to solve the text clustering problem in the Azerbaijani language. There are some text-classification applications for foreign languages, but we tried to build a newly developed system to solve this problem for the Azerbaijani language. Firstly, we tried to find out potential practice areas. The system will be useful in a lot of areas. It will be mostly used in news feed categorization. News websites can automatically categorize news into classes such as sports, business, education, science, etc. The system is also used in sentiment analysis for product reviews. For example, the company shares a photo of a new product on Facebook and the company receives a thousand comments for new products. The systems classify the comments into categories like positive or negative. The system can also be applied in recommended systems, spam filtering, etc. Various machine learning techniques such as Naive Bayes, SVM, Decision Trees have been devised to solve the text classification problem in Azerbaijani language.
FaceVR: Real-Time Facial Reenactment and Eye Gaze Control in Virtual Reality
Mar 21, 2018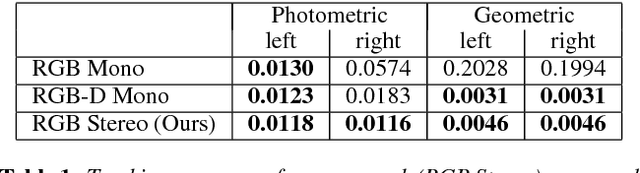

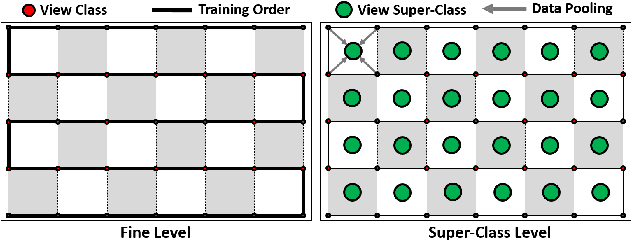
We propose FaceVR, a novel image-based method that enables video teleconferencing in VR based on self-reenactment. State-of-the-art face tracking methods in the VR context are focused on the animation of rigged 3d avatars. While they achieve good tracking performance the results look cartoonish and not real. In contrast to these model-based approaches, FaceVR enables VR teleconferencing using an image-based technique that results in nearly photo-realistic outputs. The key component of FaceVR is a robust algorithm to perform real-time facial motion capture of an actor who is wearing a head-mounted display (HMD), as well as a new data-driven approach for eye tracking from monocular videos. Based on reenactment of a prerecorded stereo video of the person without the HMD, FaceVR incorporates photo-realistic re-rendering in real time, thus allowing artificial modifications of face and eye appearances. For instance, we can alter facial expressions or change gaze directions in the prerecorded target video. In a live setup, we apply these newly-introduced algorithmic components.
Enhancing Perceptual Loss with Adversarial Feature Matching for Super-Resolution
May 15, 2020
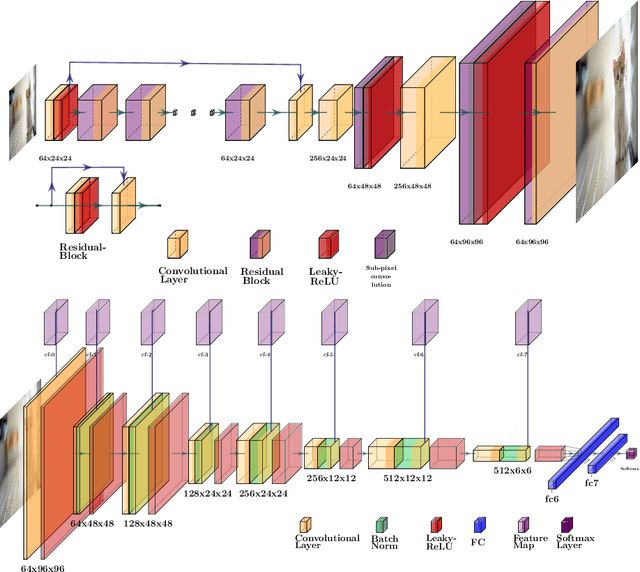
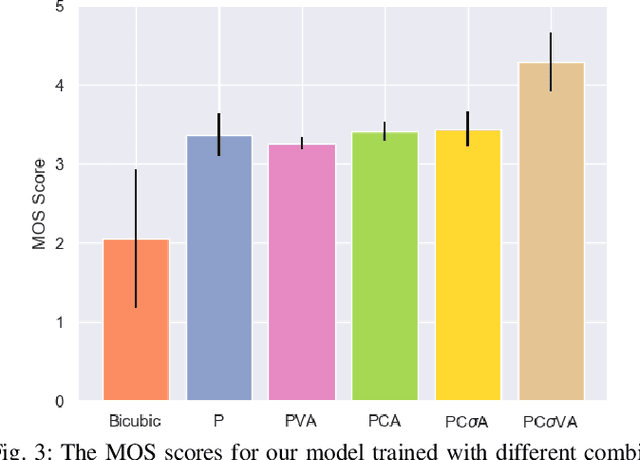

Single image super-resolution (SISR) is an ill-posed problem with an indeterminate number of valid solutions. Solving this problem with neural networks would require access to extensive experience, either presented as a large training set over natural images or a condensed representation from another pre-trained network. Perceptual loss functions, which belong to the latter category, have achieved breakthrough success in SISR and several other computer vision tasks. While perceptual loss plays a central role in the generation of photo-realistic images, it also produces undesired pattern artifacts in the super-resolved outputs. In this paper, we show that the root cause of these pattern artifacts can be traced back to a mismatch between the pre-training objective of perceptual loss and the super-resolution objective. To address this issue, we propose to augment the existing perceptual loss formulation with a novel content loss function that uses the latent features of a discriminator network to filter the unwanted artifacts across several levels of adversarial similarity. Further, our modification has a stabilizing effect on non-convex optimization in adversarial training. The proposed approach offers notable gains in perceptual quality based on an extensive human evaluation study and a competent reconstruction fidelity when tested on objective evaluation metrics.