 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Facial Keypoint Sequence Generation from Audio
Nov 02, 2020
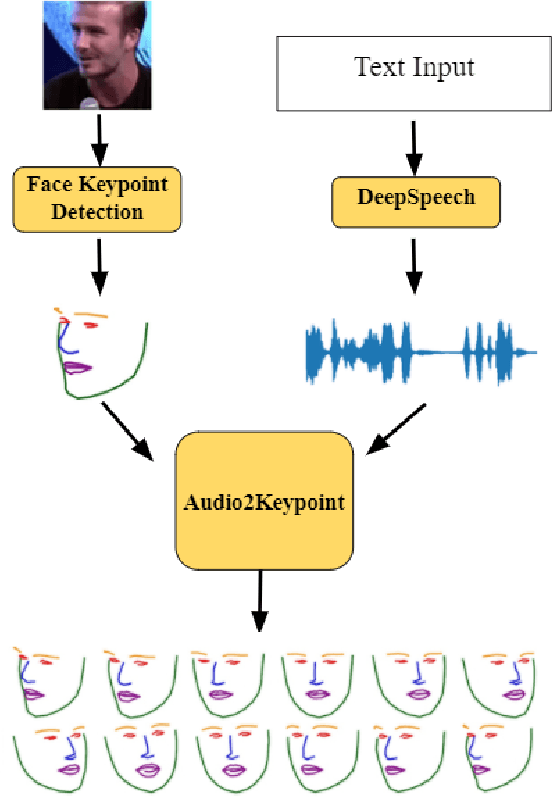
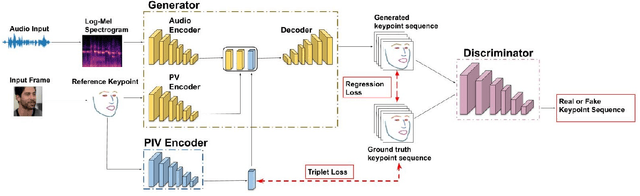
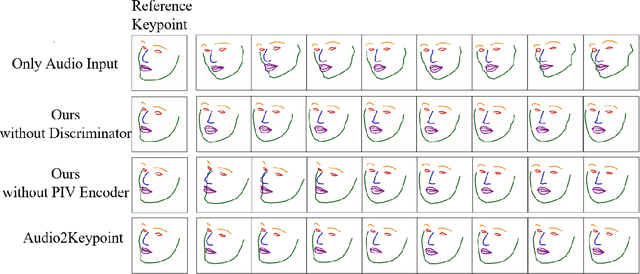
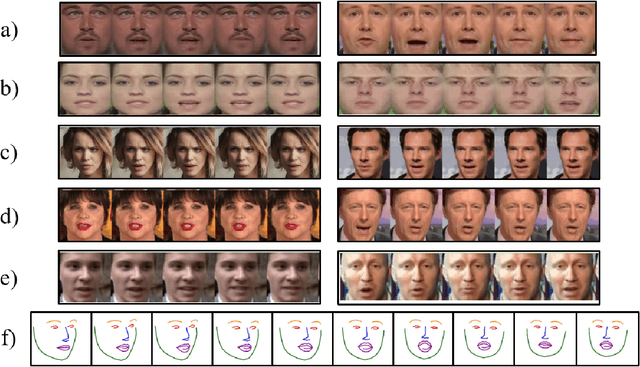
Whenever we speak, our voice is accompanied by facial movements and expressions. Several recent works have shown the synthesis of highly photo-realistic videos of talking faces, but they either require a source video to drive the target face or only generate videos with a fixed head pose. This lack of facial movement is because most of these works focus on the lip movement in sync with the audio while assuming the remaining facial keypoints' fixed nature. To address this, a unique audio-keypoint dataset of over 150,000 videos at 224p and 25fps is introduced that relates the facial keypoint movement for the given audio. This dataset is then further used to train the model, Audio2Keypoint, a novel approach for synthesizing facial keypoint movement to go with the audio. Given a single image of the target person and an audio sequence (in any language), Audio2Keypoint generates a plausible keypoint movement sequence in sync with the input audio, conditioned on the input image to preserve the target person's facial characteristics. To the best of our knowledge, this is the first work that proposes an audio-keypoint dataset and learns a model to output the plausible keypoint sequence to go with audio of any arbitrary length. Audio2Keypoint generalizes across unseen people with a different facial structure allowing us to generate the sequence with the voice from any source or even synthetic voices. Instead of learning a direct mapping from audio to video domain, this work aims to learn the audio-keypoint mapping that allows for in-plane and out-of-plane head rotations, while preserving the person's identity using a Pose Invariant (PIV) Encoder.
Learning Synthetic to Real Transfer for Localization and Navigational Tasks
Nov 23, 2020



Autonomous navigation consists in an agent being able to navigate without human intervention or supervision, it affects both high level planning and low level control. Navigation is at the crossroad of multiple disciplines, it combines notions of computer vision, robotics and control. This work aimed at creating, in a simulation, a navigation pipeline whose transfer to the real world could be done with as few efforts as possible. Given the limited time and the wide range of problematic to be tackled, absolute navigation performances while important was not the main objective. The emphasis was rather put on studying the sim2real gap which is one the major bottlenecks of modern robotics and autonomous navigation. To design the navigation pipeline four main challenges arise; environment, localization, navigation and planning. The iGibson simulator is picked for its photo-realistic textures and physics engine. A topological approach to tackle space representation was picked over metric approaches because they generalize better to new environments and are less sensitive to change of conditions. The navigation pipeline is decomposed as a localization module, a planning module and a local navigation module. These modules utilize three different networks, an image representation extractor, a passage detector and a local policy. The laters are trained on specifically tailored tasks with some associated datasets created for those specific tasks. Localization is the ability for the agent to localize itself against a specific space representation. It must be reliable, repeatable and robust to a wide variety of transformations. Localization is tackled as an image retrieval task using a deep neural network trained on an auxiliary task as a feature descriptor extractor. The local policy is trained with behavioral cloning from expert trajectories gathered with ROS navigation stack.
Photo-unrealistic Image Enhancement for Subject Placement in Outdoor Photography
Jul 17, 2018
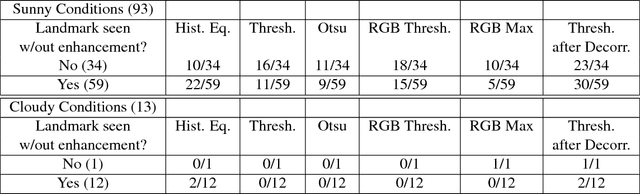
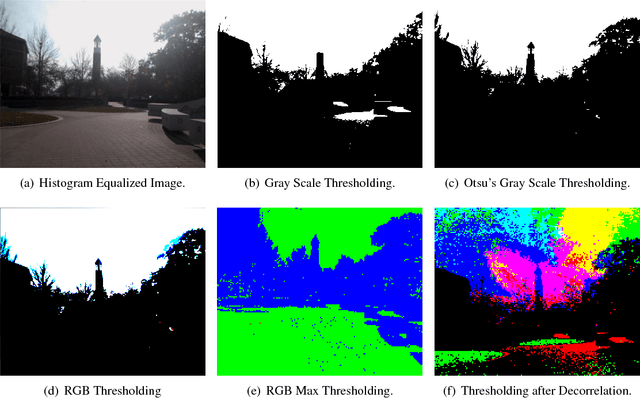
Camera display reflections are an issue in bright light situations, as they may prevent users from correctly positioning the subject in the picture. We propose a software solution to this problem, which consists in modifying the image in the viewer, in real time. In our solution, the user is seeing a posterized image which roughly represents the contour of the objects. Five enhancement methods are compared in a user study. Our results indicate that the problem considered is a valid one, as users had problems locating landmarks nearly 37% of the time under sunny conditions, and that our proposed enhancement method using contrasting colors is a practical solution to that problem.
Sketch-BERT: Learning Sketch Bidirectional Encoder Representation from Transformers by Self-supervised Learning of Sketch Gestalt
May 19, 2020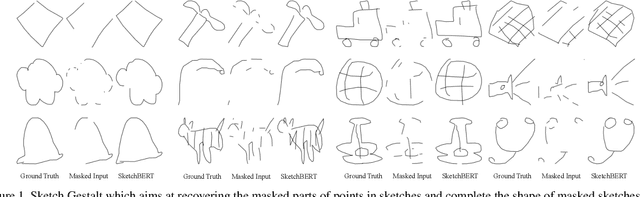
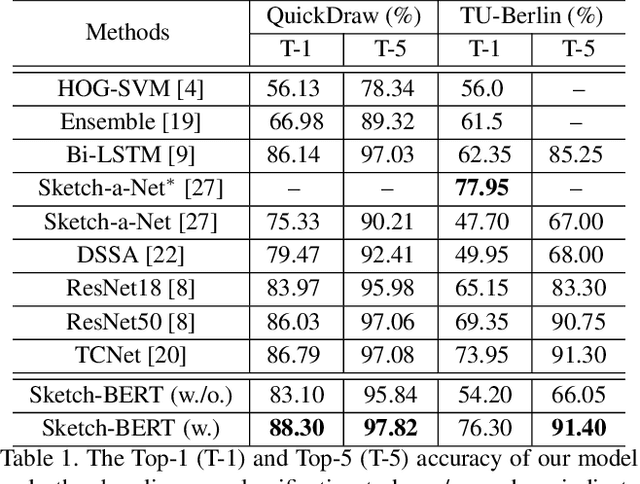
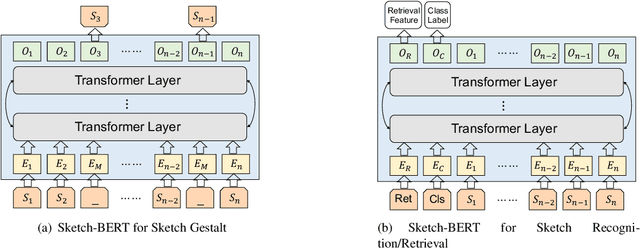
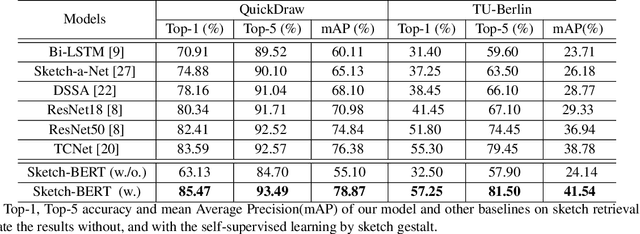
Previous researches of sketches often considered sketches in pixel format and leveraged CNN based models in the sketch understanding. Fundamentally, a sketch is stored as a sequence of data points, a vector format representation, rather than the photo-realistic image of pixels. SketchRNN studied a generative neural representation for sketches of vector format by Long Short Term Memory networks (LSTM). Unfortunately, the representation learned by SketchRNN is primarily for the generation tasks, rather than the other tasks of recognition and retrieval of sketches. To this end and inspired by the recent BERT model, we present a model of learning Sketch Bidirectional Encoder Representation from Transformer (Sketch-BERT). We generalize BERT to sketch domain, with the novel proposed components and pre-training algorithms, including the newly designed sketch embedding networks, and the self-supervised learning of sketch gestalt. Particularly, towards the pre-training task, we present a novel Sketch Gestalt Model (SGM) to help train the Sketch-BERT. Experimentally, we show that the learned representation of Sketch-BERT can help and improve the performance of the downstream tasks of sketch recognition, sketch retrieval, and sketch gestalt.
ActGAN: Flexible and Efficient One-shot Face Reenactment
Mar 30, 2020
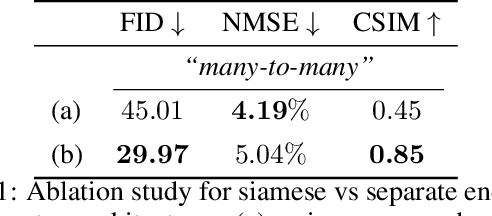
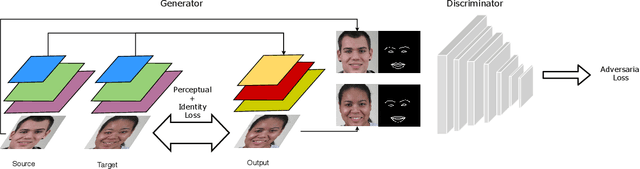

This paper introduces ActGAN - a novel end-to-end generative adversarial network (GAN) for one-shot face reenactment. Given two images, the goal is to transfer the facial expression of the source actor onto a target person in a photo-realistic fashion. While existing methods require target identity to be predefined, we address this problem by introducing a "many-to-many" approach, which allows arbitrary persons both for source and target without additional retraining. To this end, we employ the Feature Pyramid Network (FPN) as a core generator building block - the first application of FPN in face reenactment, producing finer results. We also introduce a solution to preserve a person's identity between synthesized and target person by adopting the state-of-the-art approach in deep face recognition domain. The architecture readily supports reenactment in different scenarios: "many-to-many", "one-to-one", "one-to-another" in terms of expression accuracy, identity preservation, and overall image quality. We demonstrate that ActGAN achieves competitive performance against recent works concerning visual quality.
ReadNet:Towards Accurate ReID with Limited and Noisy Samples
May 12, 2020

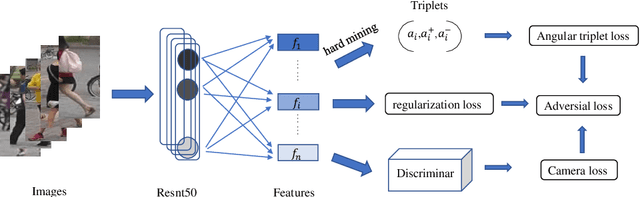
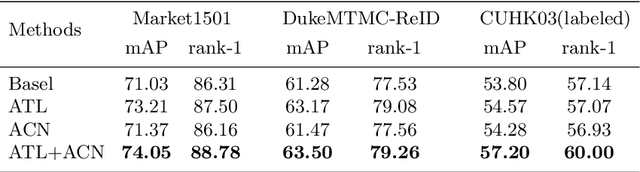
Person re-identification (ReID) is an essential cross-camera retrieval task to identify pedestrians. However, the photo number of each pedestrian usually differs drastically, and thus the data limitation and imbalance problem hinders the prediction accuracy greatly. Additionally, in real-world applications, pedestrian images are captured by different surveillance cameras, so the noisy camera related information, such as the lights, perspectives and resolutions, result in inevitable domain gaps for ReID algorithms. These challenges bring difficulties to current deep learning methods with triplet loss for coping with such problems. To address these challenges, this paper proposes ReadNet, an adversarial camera network (ACN) with an angular triplet loss (ATL). In detail, ATL focuses on learning the angular distance among different identities to mitigate the effect of data imbalance, and guarantees a linear decision boundary as well, while ACN takes the camera discriminator as a game opponent of feature extractor to filter camera related information to bridge the multi-camera gaps. ReadNet is designed to be flexible so that either ATL or ACN can be deployed independently or simultaneously. The experiment results on various benchmark datasets have shown that ReadNet can deliver better prediction performance than current state-of-the-art methods.
Domain Adaptation with Morphologic Segmentation
Jun 16, 2020


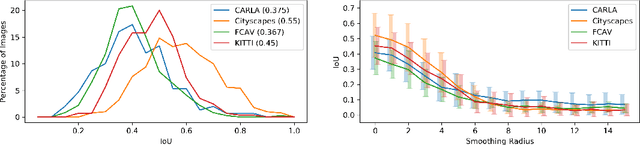
We present a novel domain adaptation framework that uses morphologic segmentation to translate images from arbitrary input domains (real and synthetic) into a uniform output domain. Our framework is based on an established image-to-image translation pipeline that allows us to first transform the input image into a generalized representation that encodes morphology and semantics - the edge-plus-segmentation map (EPS) - which is then transformed into an output domain. Images transformed into the output domain are photo-realistic and free of artifacts that are commonly present across different real (e.g. lens flare, motion blur, etc.) and synthetic (e.g. unrealistic textures, simplified geometry, etc.) data sets. Our goal is to establish a preprocessing step that unifies data from multiple sources into a common representation that facilitates training downstream tasks in computer vision. This way, neural networks for existing tasks can be trained on a larger variety of training data, while they are also less affected by overfitting to specific data sets. We showcase the effectiveness of our approach by qualitatively and quantitatively evaluating our method on four data sets of simulated and real data of urban scenes. Additional results can be found on the project website available at http://jonathank.de/research/eps/ .
Effective Multi-Query Expansions: Collaborative Deep Networks for Robust Landmark Retrieval
Jan 18, 2017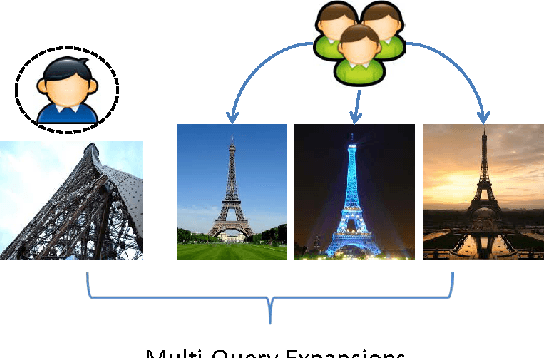
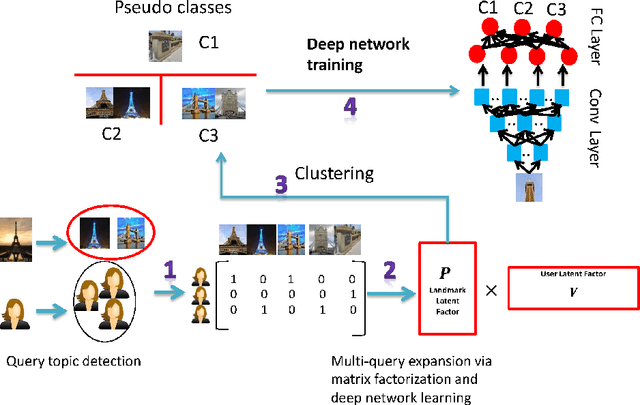
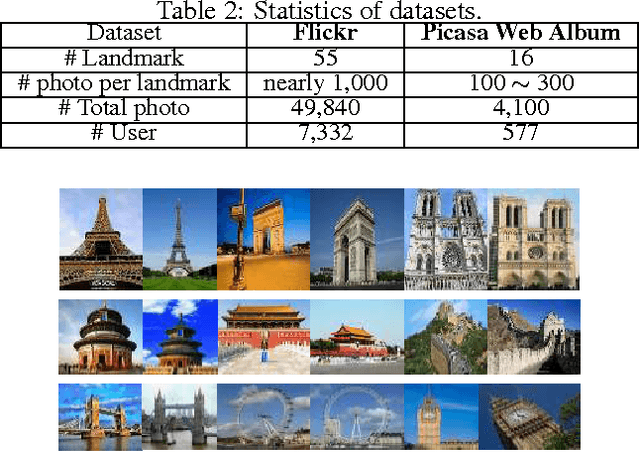
Given a query photo issued by a user (q-user), the landmark retrieval is to return a set of photos with their landmarks similar to those of the query, while the existing studies on the landmark retrieval focus on exploiting geometries of landmarks for similarity matches between candidate photos and a query photo. We observe that the same landmarks provided by different users over social media community may convey different geometry information depending on the viewpoints and/or angles, and may subsequently yield very different results. In fact, dealing with the landmarks with \illshapes caused by the photography of q-users is often nontrivial and has seldom been studied. In this paper we propose a novel framework, namely multi-query expansions, to retrieve semantically robust landmarks by two steps. Firstly, we identify the top-$k$ photos regarding the latent topics of a query landmark to construct multi-query set so as to remedy its possible \illshape. For this purpose, we significantly extend the techniques of Latent Dirichlet Allocation. Then, motivated by the typical \emph{collaborative filtering} methods, we propose to learn a \emph{collaborative} deep networks based semantically, nonlinear and high-level features over the latent factor for landmark photo as the training set, which is formed by matrix factorization over \emph{collaborative} user-photo matrix regarding the multi-query set. The learned deep network is further applied to generate the features for all the other photos, meanwhile resulting into a compact multi-query set within such space. Extensive experiments are conducted on real-world social media data with both landmark photos together with their user information to show the superior performance over the existing methods.
On the Role of Receptive Field in Unsupervised Sim-to-Real Image Translation
Jan 25, 2020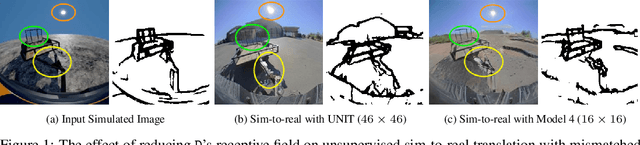
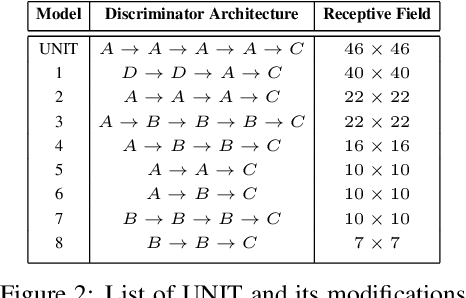
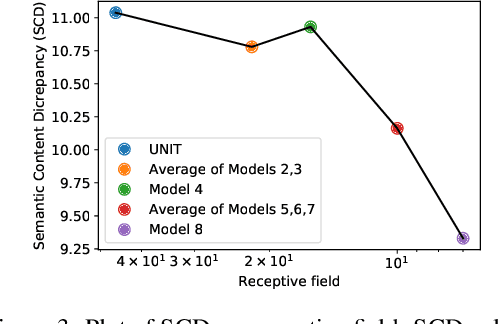

Generative Adversarial Networks (GANs) are now widely used for photo-realistic image synthesis. In applications where a simulated image needs to be translated into a realistic image (sim-to-real), GANs trained on unpaired data from the two domains are susceptible to failure in semantic content retention as the image is translated from one domain to the other. This failure mode is more pronounced in cases where the real data lacks content diversity, resulting in a content \emph{mismatch} between the two domains - a situation often encountered in real-world deployment. In this paper, we investigate the role of the discriminator's receptive field in GANs for unsupervised image-to-image translation with mismatched data, and study its effect on semantic content retention. Experiments with the discriminator architecture of a state-of-the-art coupled Variational Auto-Encoder (VAE) - GAN model on diverse, mismatched datasets show that the discriminator receptive field is directly correlated with semantic content discrepancy of the generated image.
Recent Progress of Face Image Synthesis
Jun 15, 2017



Face synthesis has been a fascinating yet challenging problem in computer vision and machine learning. Its main research effort is to design algorithms to generate photo-realistic face images via given semantic domain. It has been a crucial prepossessing step of main-stream face recognition approaches and an excellent test of AI ability to use complicated probability distributions. In this paper, we provide a comprehensive review of typical face synthesis works that involve traditional methods as well as advanced deep learning approaches. Particularly, Generative Adversarial Net (GAN) is highlighted to generate photo-realistic and identity preserving results. Furthermore, the public available databases and evaluation metrics are introduced in details. We end the review with discussing unsolved difficulties and promising directions for future research.