 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
AirSim Drone Racing Lab
Mar 12, 2020




Autonomous drone racing is a challenging research problem at the intersection of computer vision, planning, state estimation, and control. We introduce AirSim Drone Racing Lab, a simulation framework for enabling fast prototyping of algorithms for autonomy and enabling machine learning research in this domain, with the goal of reducing the time, money, and risks associated with field robotics. Our framework enables generation of racing tracks in multiple photo-realistic environments, orchestration of drone races, comes with a suite of gate assets, allows for multiple sensor modalities (monocular, depth, neuromorphic events, optical flow), different camera models, and benchmarking of planning, control, computer vision, and learning-based algorithms. We used our framework to host a simulation based drone racing competition at NeurIPS 2019. The competition binaries are available at our github repository.
DeepHist: Differentiable Joint and Color Histogram Layers for Image-to-Image Translation
May 06, 2020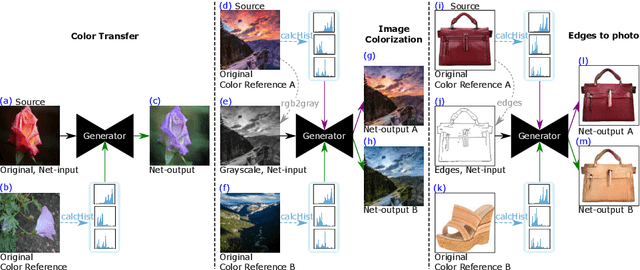
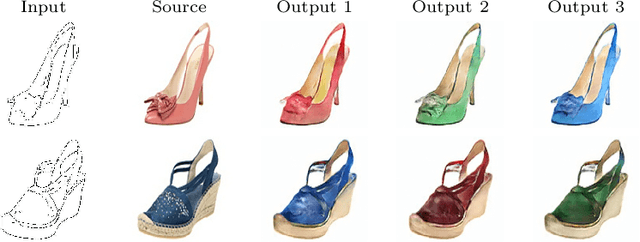

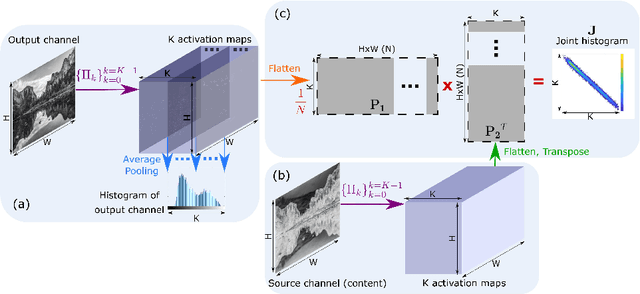
We present the DeepHist - a novel Deep Learning framework for augmenting a network by histogram layers and demonstrate its strength by addressing image-to-image translation problems. Specifically, given an input image and a reference color distribution we aim to generate an output image with the structural appearance (content) of the input (source) yet with the colors of the reference. The key idea is a new technique for a differentiable construction of joint and color histograms of the output images. We further define a color distribution loss based on the Earth Mover's Distance between the output's and the reference's color histograms and a Mutual Information loss based on the joint histograms of the source and the output images. Promising results are shown for the tasks of color transfer, image colorization and edges $\rightarrow$ photo, where the color distribution of the output image is controlled. Comparison to Pix2Pix and CyclyGANs are shown.
Event Recognition with Automatic Album Detection based on Sequential Processing, Neural Attention and Image Captioning
Nov 25, 2019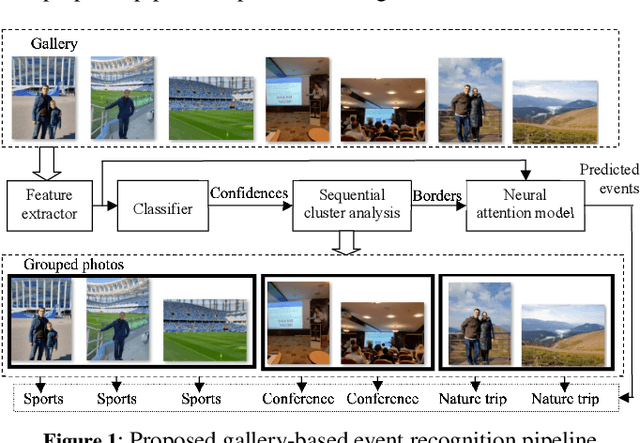
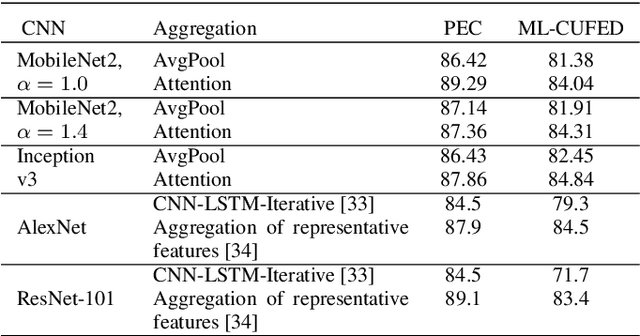
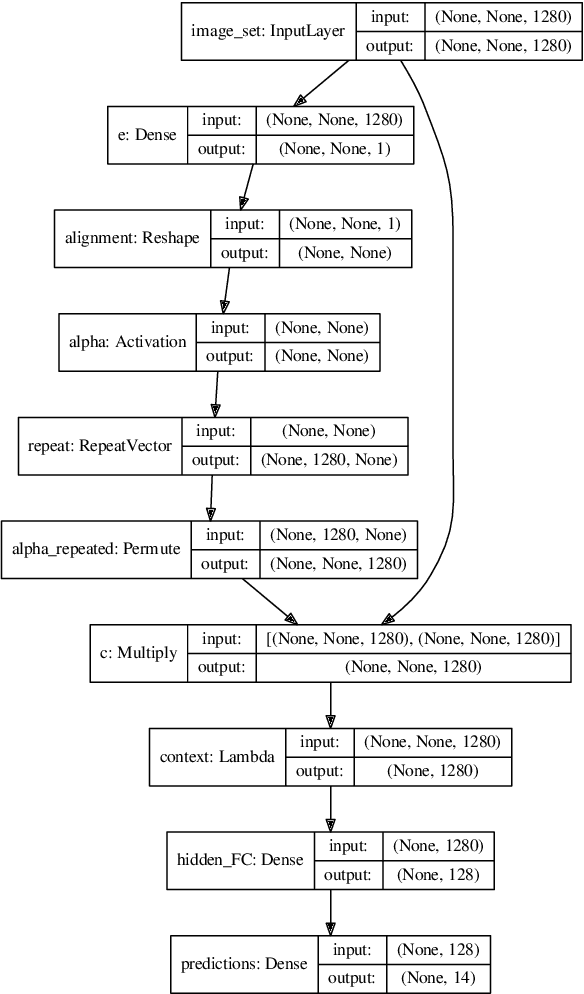
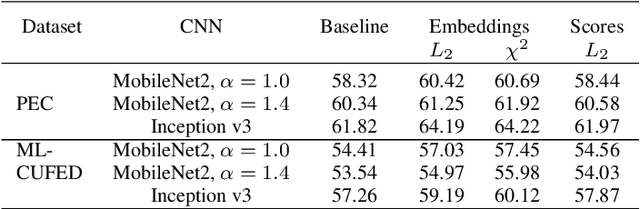
In this paper a new formulation of event recognition task is examined: it is required to predict event categories in a gallery of images, for which albums (groups of photos corresponding to a single event) are unknown. We propose the novel two-stage approach. At first, features are extracted in each photo using the pre-trained convolutional neural network. These features are classified individually. The scores of the classifier are used to group sequential photos into several clusters. Finally, the features of photos in each group are aggregated into a single descriptor using neural attention mechanism. This algorithm is optionally extended to improve the accuracy for classification of each image in an album. In contrast to conventional fine-tuning of convolutional neural networks (CNN) we proposed to use image captioning, i.e., generative model that converts images to textual descriptions. They are one-hot encoded and summarized into sparse feature vector suitable for learning of arbitrary classifier. Experimental study with Photo Event Collection and Multi-Label Curation of Flickr Events Dataset demonstrates that our approach is 9-20% more accurate than event recognition on single photos. Moreover, proposed method has 13-16% lower error rate than classification of groups of photos obtained with hierarchical clustering. It is experimentally shown that the image captions trained on Conceptual Captions dataset can be classified more accurately than the features from object detector, though they both are obviously not as rich as the CNN-based features. However, it is possible to combine our approach with conventional CNNs in an ensemble to provide the state-of-the-art results for several event datasets.
DeepSEE: Deep Disentangled Semantic Explorative Extreme Super-Resolution
Apr 09, 2020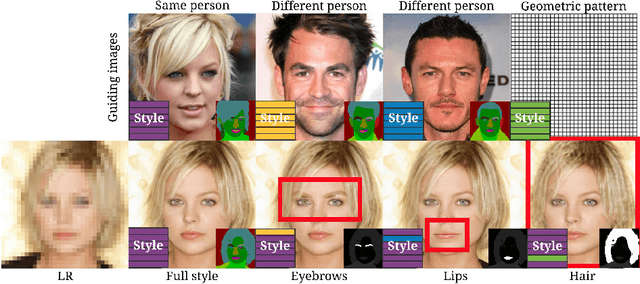
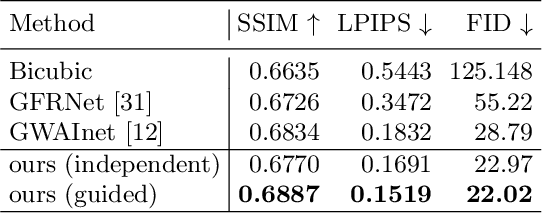
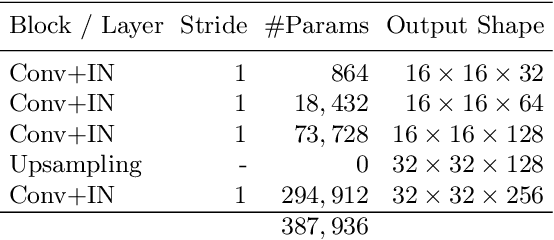
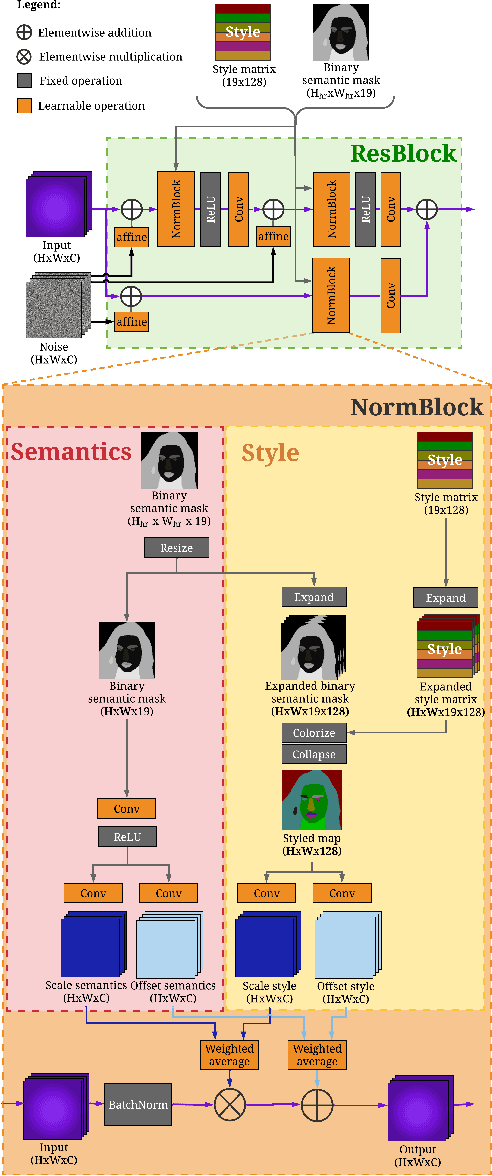
Super-resolution (SR) is by definition ill-posed. There are infinitely many plausible high-resolution variants for a given low-resolution natural image. This is why example-based SR methods study upscaling factors up to 4x (or up to 8x for face hallucination). Most of the current literature aims at a single deterministic solution of either high reconstruction fidelity or photo-realistic perceptual quality. In this work, we propose a novel framework, DeepSEE, for Deep disentangled Semantic Explorative Extreme super-resolution. To the best of our knowledge, DeepSEE is the first method to leverage semantic maps for explorative super-resolution. In particular, it provides control of the semantic regions, their disentangled appearance and it allows a broad range of image manipulations. We validate DeepSEE for up to 32x magnification and exploration of the space of super-resolution.
Self-supervised Dense 3D Reconstruction from Monocular Endoscopic Video
Sep 06, 2019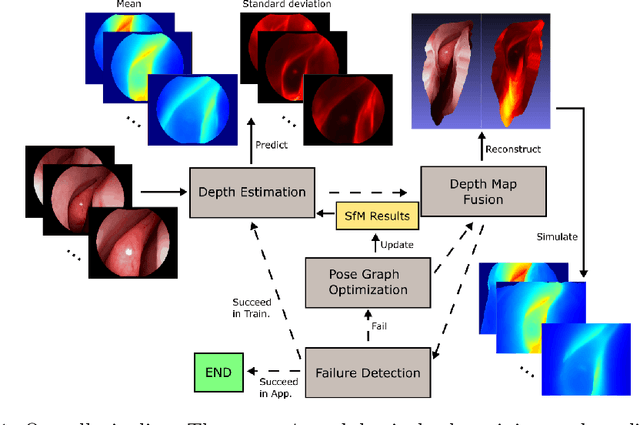
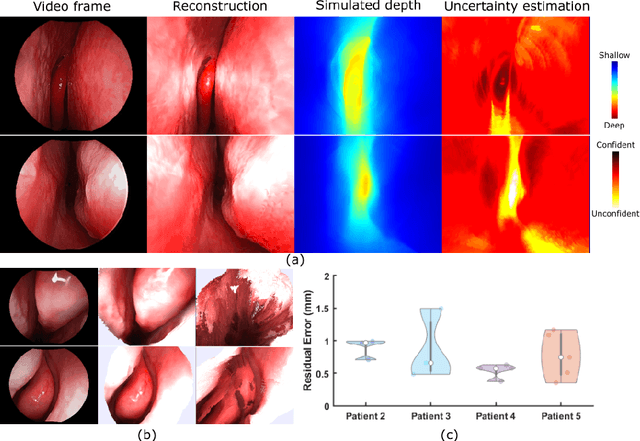
We present a self-supervised learning-based pipeline for dense 3D reconstruction from full-length monocular endoscopic videos without a priori modeling of anatomy or shading. Our method only relies on unlabeled monocular endoscopic videos and conventional multi-view stereo algorithms, and requires neither manual interaction nor patient CT in both training and application phases. In a cross-patient study using CT scans as groundtruth, we show that our method is able to produce photo-realistic dense 3D reconstructions with submillimeter mean residual errors from endoscopic videos from unseen patients and scopes.
Cross-modal Subspace Learning for Fine-grained Sketch-based Image Retrieval
May 28, 2017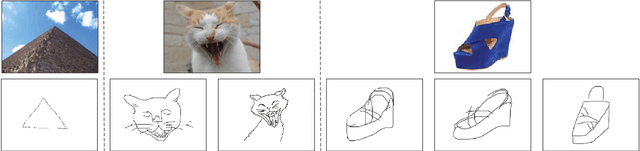
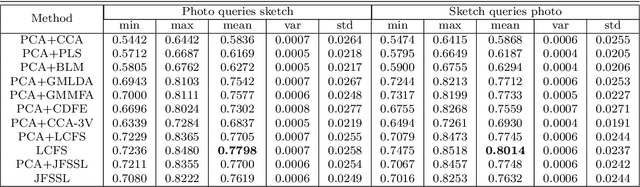
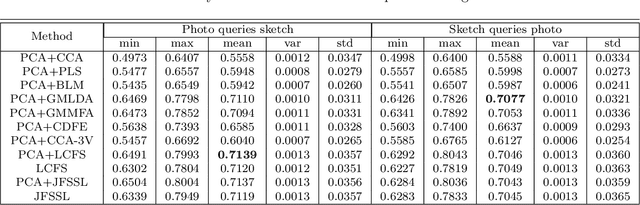
Sketch-based image retrieval (SBIR) is challenging due to the inherent domain-gap between sketch and photo. Compared with pixel-perfect depictions of photos, sketches are iconic renderings of the real world with highly abstract. Therefore, matching sketch and photo directly using low-level visual clues are unsufficient, since a common low-level subspace that traverses semantically across the two modalities is non-trivial to establish. Most existing SBIR studies do not directly tackle this cross-modal problem. This naturally motivates us to explore the effectiveness of cross-modal retrieval methods in SBIR, which have been applied in the image-text matching successfully. In this paper, we introduce and compare a series of state-of-the-art cross-modal subspace learning methods and benchmark them on two recently released fine-grained SBIR datasets. Through thorough examination of the experimental results, we have demonstrated that the subspace learning can effectively model the sketch-photo domain-gap. In addition we draw a few key insights to drive future research.
Neural Hair Rendering
Apr 28, 2020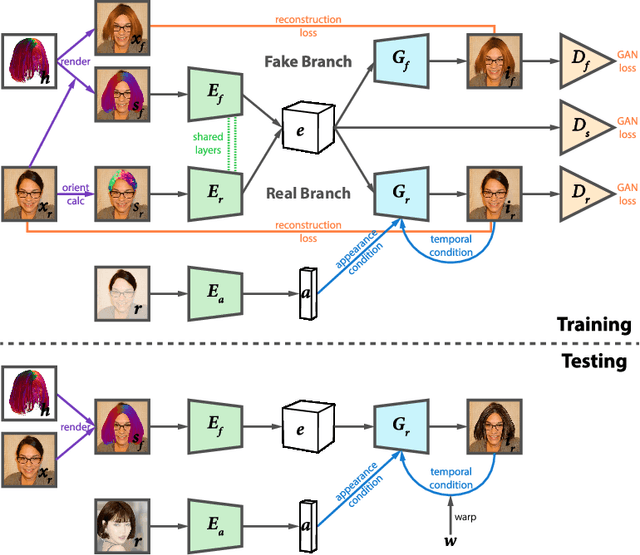
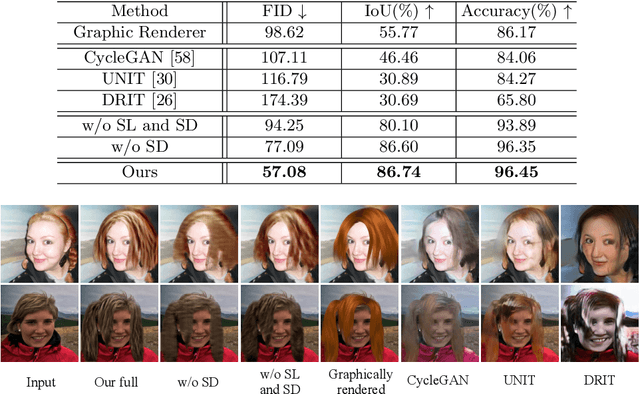


In this paper, we propose a generic neural-based hair rendering pipeline that can synthesize photo-realistic images from virtual 3D hair models. Unlike existing supervised translation methods that require model-level similarity to preserve consistent structure representation for both real images and fake renderings, our method adopts an unsupervised solution to work on arbitrary hair models. The key component of our method is a shared latent space to encode appearance-invariant structure information of both domains, which generates realistic renderings conditioned by extra appearance inputs. This is achieved by domain-specific pre-disentangled structure representation, partially shared domain encoder layers, and a structure discriminator. We also propose a simple yet effective temporal conditioning method to enforce consistency for video sequence generation. We demonstrate the superiority of our method by testing it on large amount of portraits, and comparing with alternative baselines and state-of-the-art unsupervised image translation methods.
Neural Reflectance Fields for Appearance Acquisition
Aug 16, 2020
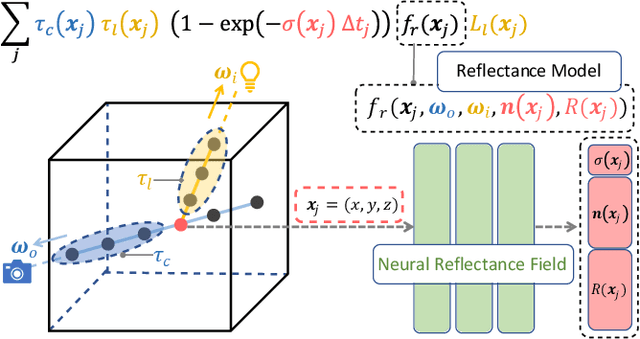
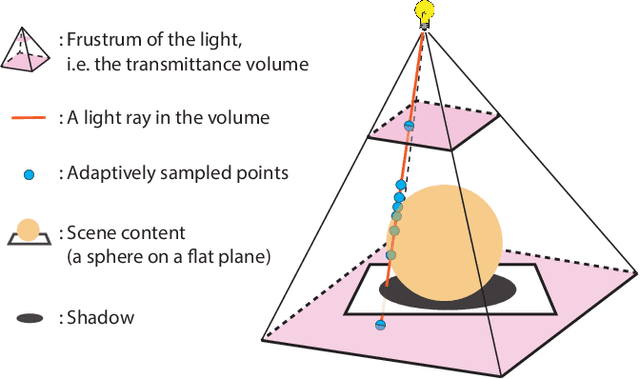
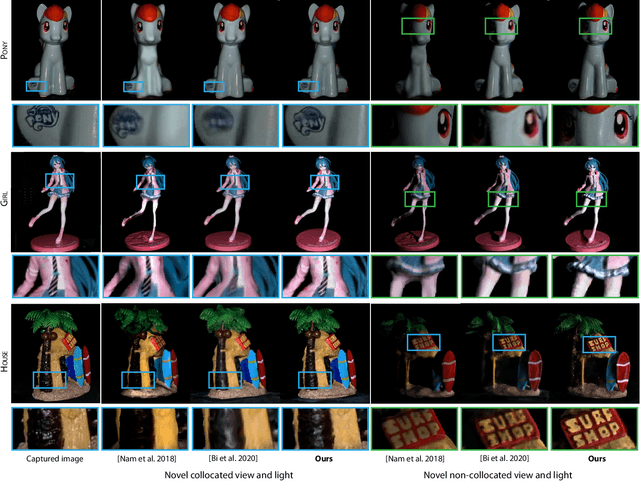
We present Neural Reflectance Fields, a novel deep scene representation that encodes volume density, normal and reflectance properties at any 3D point in a scene using a fully-connected neural network. We combine this representation with a physically-based differentiable ray marching framework that can render images from a neural reflectance field under any viewpoint and light. We demonstrate that neural reflectance fields can be estimated from images captured with a simple collocated camera-light setup, and accurately model the appearance of real-world scenes with complex geometry and reflectance. Once estimated, they can be used to render photo-realistic images under novel viewpoint and (non-collocated) lighting conditions and accurately reproduce challenging effects like specularities, shadows and occlusions. This allows us to perform high-quality view synthesis and relighting that is significantly better than previous methods. We also demonstrate that we can compose the estimated neural reflectance field of a real scene with traditional scene models and render them using standard Monte Carlo rendering engines. Our work thus enables a complete pipeline from high-quality and practical appearance acquisition to 3D scene composition and rendering.
HoughNet: Integrating near and long-range evidence for bottom-up object detection
Jul 05, 2020
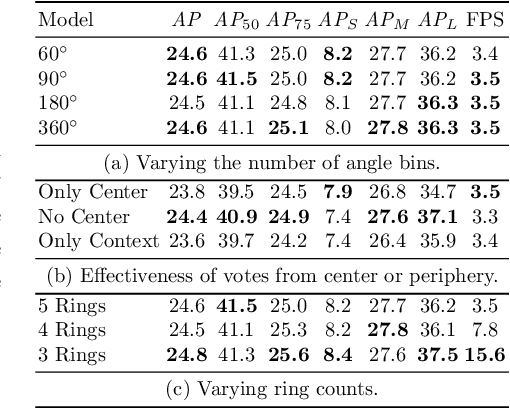
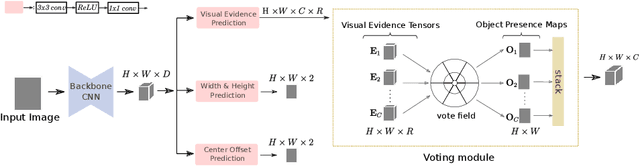
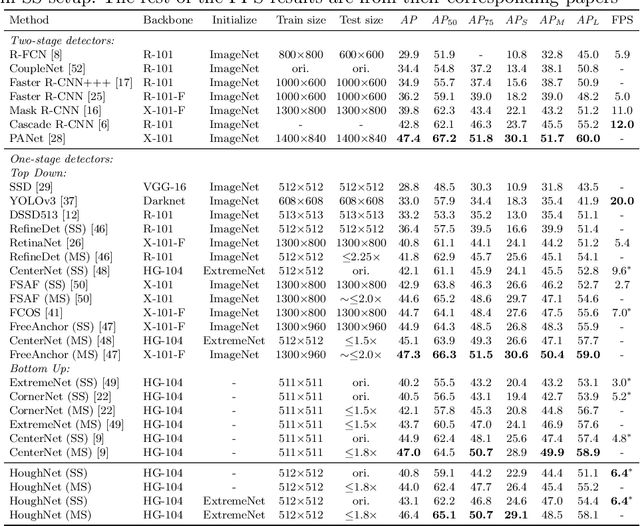
This paper presents HoughNet, a one-stage, anchor-free, voting-based, bottom-up object detection method. Inspired by the Generalized Hough Transform, HoughNet determines the presence of an object at a certain location by the sum of the votes cast on that location. Votes are collected from both near and long-distance locations based on a log-polar vote field. Thanks to this voting mechanism, HoughNet is able to integrate both near and long-range, class-conditional evidence for visual recognition, thereby generalizing and enhancing current object detection methodology, which typically relies on only local evidence. On the COCO dataset, HoughNet achieves 46.4 AP (and 65.1 AP_50), performing on par with the state-of-the-art in bottom-up object detection and outperforming most major one-stage and two-stage methods. We further validate the effectiveness of our proposal in another task, namely, "labels to photo" image generation by integrating the voting module of HoughNet to two different GAN models and showing that the accuracy is significantly improved in both cases. Code is available at: https://github.com/nerminsamet/houghnet
Upgrading the Newsroom: An Automated Image Selection System for News Articles
Apr 23, 2020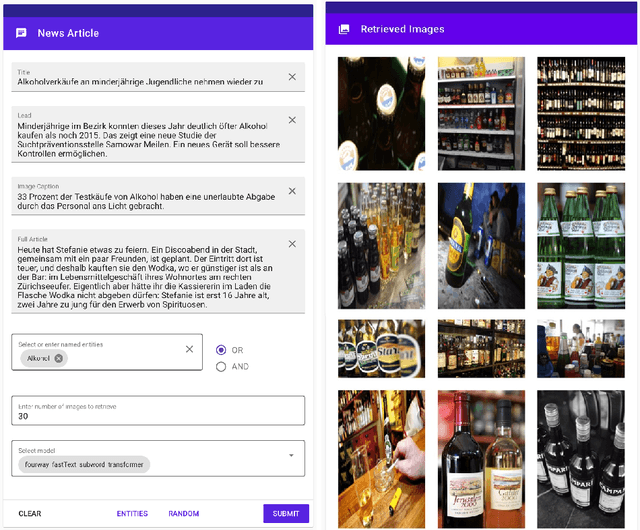
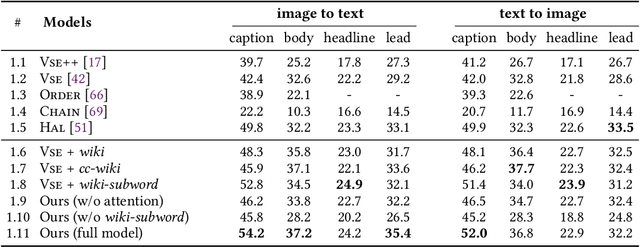
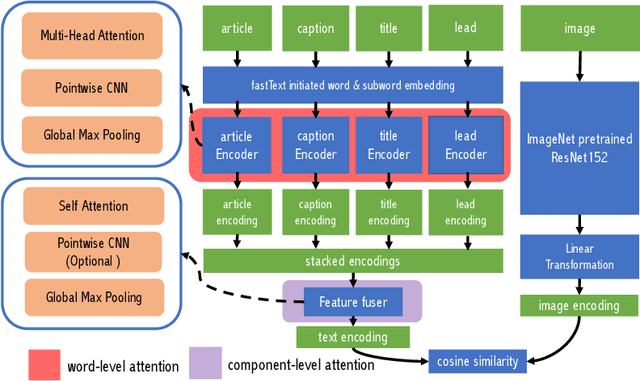
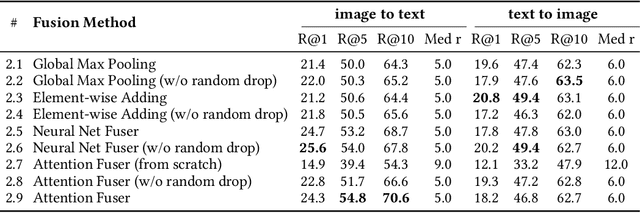
We propose an automated image selection system to assist photo editors in selecting suitable images for news articles. The system fuses multiple textual sources extracted from news articles and accepts multilingual inputs. It is equipped with char-level word embeddings to help both modeling morphologically rich languages, e.g. German, and transferring knowledge across nearby languages. The text encoder adopts a hierarchical self-attention mechanism to attend more to both keywords within a piece of text and informative components of a news article. We extensively experiment with our system on a large-scale text-image database containing multimodal multilingual news articles collected from Swiss local news media websites. The system is compared with multiple baselines with ablation studies and is shown to beat existing text-image retrieval methods in a weakly-supervised learning setting. Besides, we also offer insights on the advantage of using multiple textual sources and multilingual data.