 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
High Diversity Attribute Guided Face Generation with GANs
Jun 28, 2018
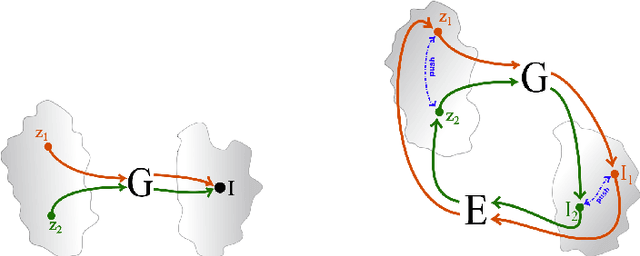
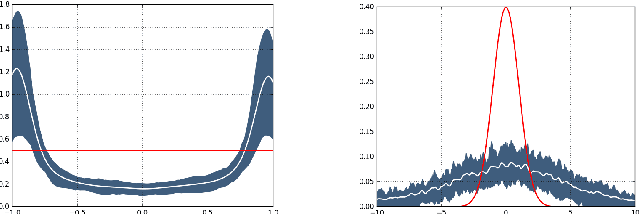

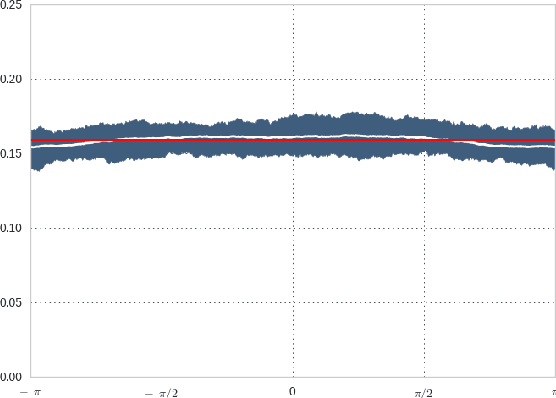
In this work we focused on GAN-based solution for the attribute guided face synthesis. Previous works exploited GANs for generation of photo-realistic face images and did not pay attention to the question of diversity of the resulting images. The proposed solution in its turn introducing novel latent space of unit complex numbers is able to provide the diversity on the "birthday paradox" score 3 times higher than the size of the training dataset. It is important to emphasize that our result is shown on relatively small dataset (20k samples vs 200k) while preserving photo-realistic properties of generated faces on significantly higher resolution (128x128 in comparison to 32x32 of previous works).
CommuNety: A Deep Learning System for the Prediction of Cohesive Social Communities
Jul 29, 2020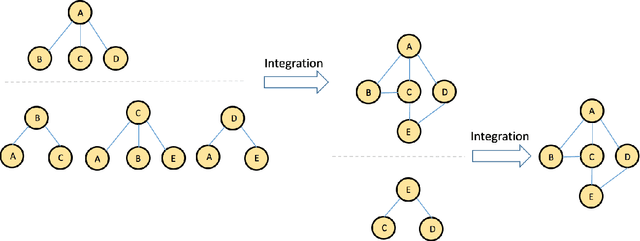

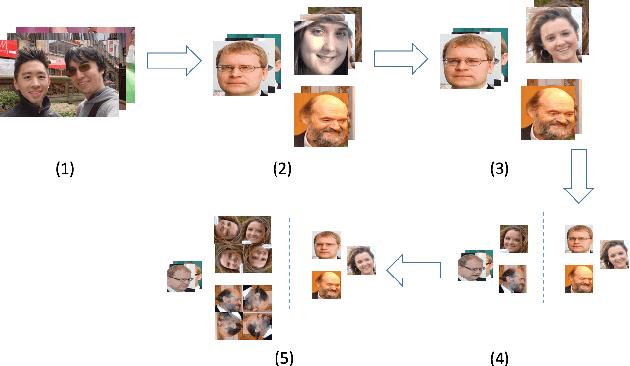
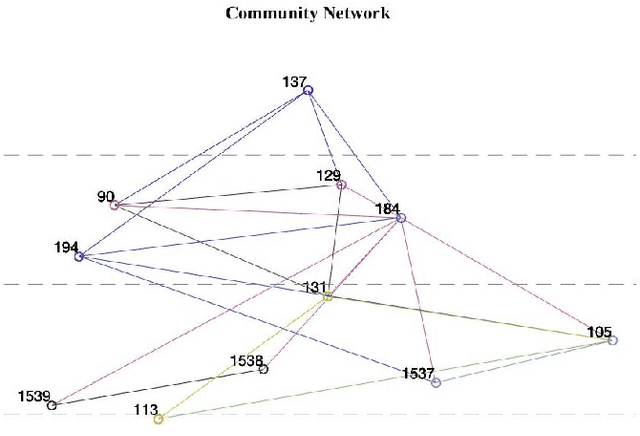
Effective mining of social media, which consists of a large number of users is a challenging task. Traditional approaches rely on the analysis of text data related to users to accomplish this task. However, text data lacks significant information about the social users and their associated groups. In this paper, we propose CommuNety, a deep learning system for the prediction of cohesive social networks using images. The proposed deep learning model consists of hierarchical CNN architecture to learn descriptive features related to each cohesive network. The paper also proposes a novel Face Co-occurrence Frequency algorithm to quantify existence of people in images, and a novel photo ranking method to analyze the strength of relationship between different individuals in a predicted social network. We extensively evaluate the proposed technique on PIPA dataset and compare with state-of-the-art methods. Our experimental results demonstrate the superior performance of the proposed technique for the prediction of relationship between different individuals and the cohesiveness of communities.
PennSyn2Real: Training Object Recognition Models without Human Labeling
Oct 16, 2020

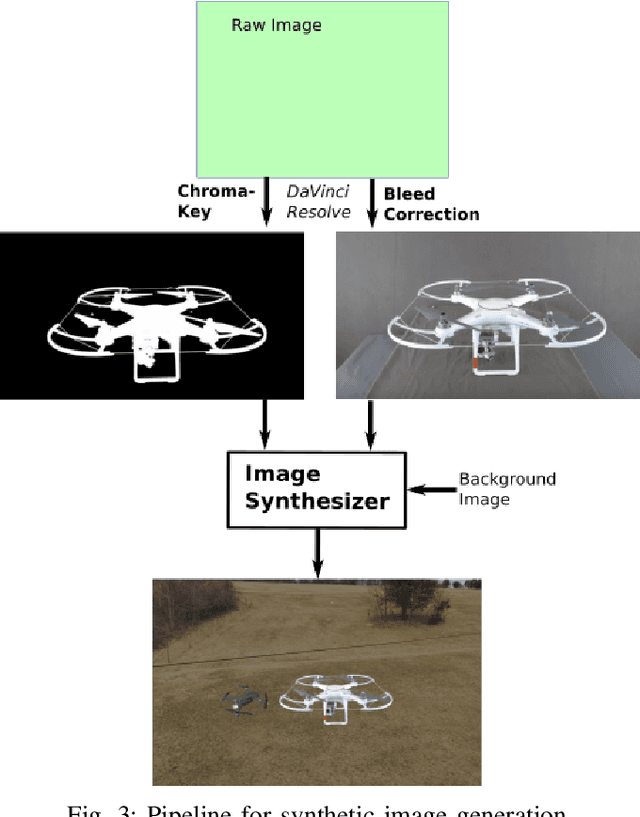
Scalable training data generation is a critical problem in deep learning. We propose PennSyn2Real - a photo-realistic synthetic dataset consisting of more than 100,000 4K images of more than 20 types of micro aerial vehicles (MAVs). The dataset can be used to generate arbitrary numbers of training images for high-level computer vision tasks such as MAV detection and classification. Our data generation framework bootstraps chroma-keying, a mature cinematography technique with a motion tracking system, providing artifact-free and curated annotated images where object orientations and lighting are controlled. This framework is easy to set up and can be applied to a broad range of objects, reducing the gap between synthetic and real-world data. We show that synthetic data generated using this framework can be directly used to train CNN models for common object recognition tasks such as detection and segmentation. We demonstrate competitive performance in comparison with training using only real images. Furthermore, bootstrapping the generated synthetic data in few-shot learning can significantly improve the overall performance, reducing the number of required training data samples to achieve the desired accuracy.
Task-agnostic Temporally Consistent Facial Video Editing
Jul 03, 2020
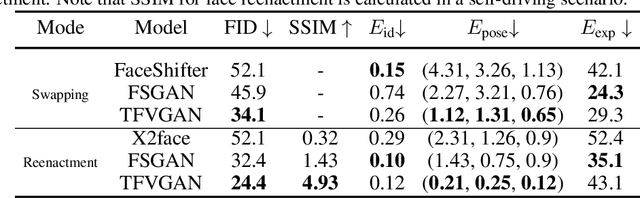
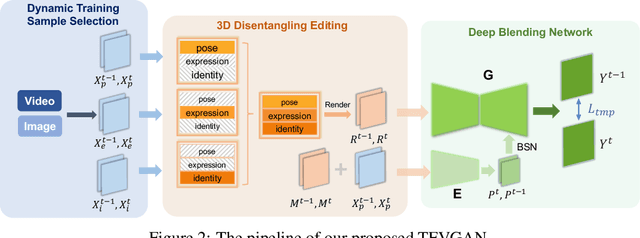
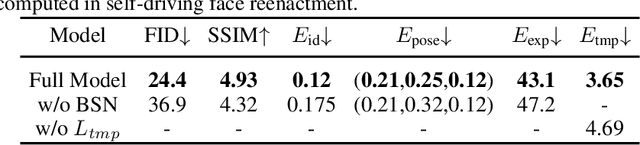
Recent research has witnessed the advances in facial image editing tasks. For video editing, however, previous methods either simply apply transformations frame by frame or utilize multiple frames in a concatenated or iterative fashion, which leads to noticeable visual flickers. In addition, these methods are confined to dealing with one specific task at a time without any extensibility. In this paper, we propose a task-agnostic temporally consistent facial video editing framework. Based on a 3D reconstruction model, our framework is designed to handle several editing tasks in a more unified and disentangled manner. The core design includes a dynamic training sample selection mechanism and a novel 3D temporal loss constraint that fully exploits both image and video datasets and enforces temporal consistency. Compared with the state-of-the-art facial image editing methods, our framework generates video portraits that are more photo-realistic and temporally smooth.
Foreground-aware Semantic Representations for Image Harmonization
Jun 01, 2020

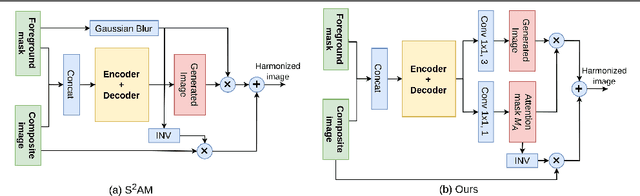
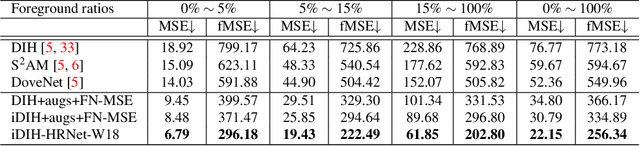
Image harmonization is an important step in photo editing to achieve visual consistency in composite images by adjusting the appearances of foreground to make it compatible with background. Previous approaches to harmonize composites are based on training of encoder-decoder networks from scratch, which makes it challenging for a neural network to learn a high-level representation of objects. We propose a novel architecture to utilize the space of high-level features learned by a pre-trained classification network. We create our models as a combination of existing encoder-decoder architectures and a pre-trained foreground-aware deep high-resolution network. We extensively evaluate the proposed method on existing image harmonization benchmark and set up a new state-of-the-art in terms of MSE and PSNR metrics. The code and trained models are available at \url{https://github.com/saic-vul/image_harmonization}.
Auto-Embedding Generative Adversarial Networks for High Resolution Image Synthesis
Mar 29, 2019

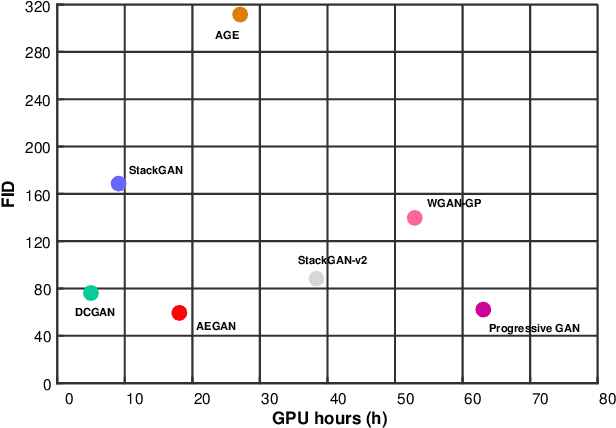
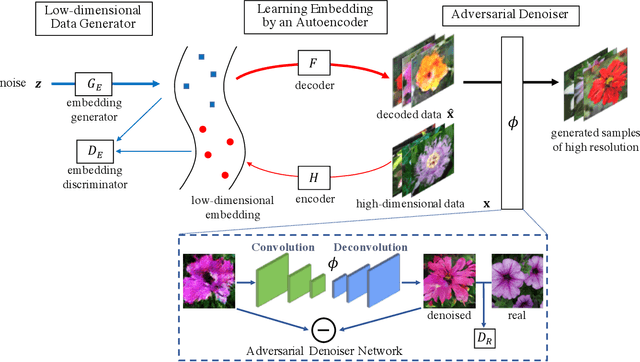
Generating images via the generative adversarial network (GAN) has attracted much attention recently. However, most of the existing GAN-based methods can only produce low-resolution images of limited quality. Directly generating high-resolution images using GANs is nontrivial, and often produces problematic images with incomplete objects. To address this issue, we develop a novel GAN called Auto-Embedding Generative Adversarial Network (AEGAN), which simultaneously encodes the global structure features and captures the fine-grained details. In our network, we use an autoencoder to learn the intrinsic high-level structure of real images and design a novel denoiser network to provide photo-realistic details for the generated images. In the experiments, we are able to produce 512x512 images of promising quality directly from the input noise. The resultant images exhibit better perceptual photo-realism, i.e., with sharper structure and richer details, than other baselines on several datasets, including Oxford-102 Flowers, Caltech-UCSD Birds (CUB), High-Quality Large-scale CelebFaces Attributes (CelebA-HQ), Large-scale Scene Understanding (LSUN) and ImageNet.
Kimera-Multi: a System for Distributed Multi-Robot Metric-Semantic Simultaneous Localization and Mapping
Nov 08, 2020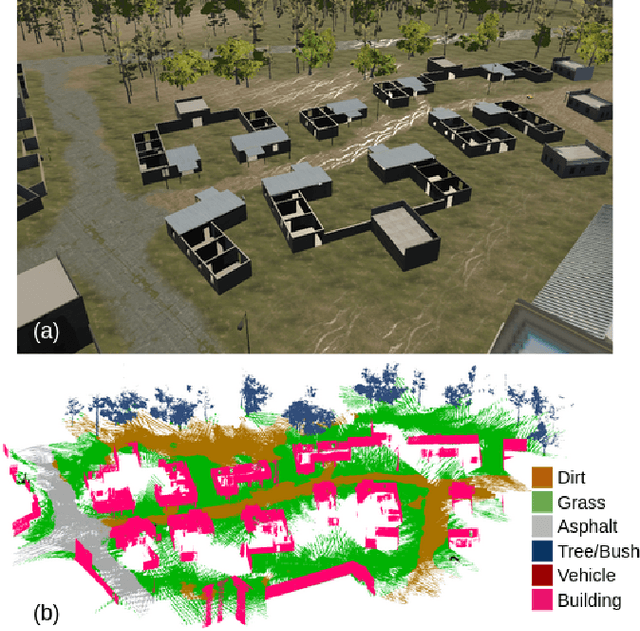
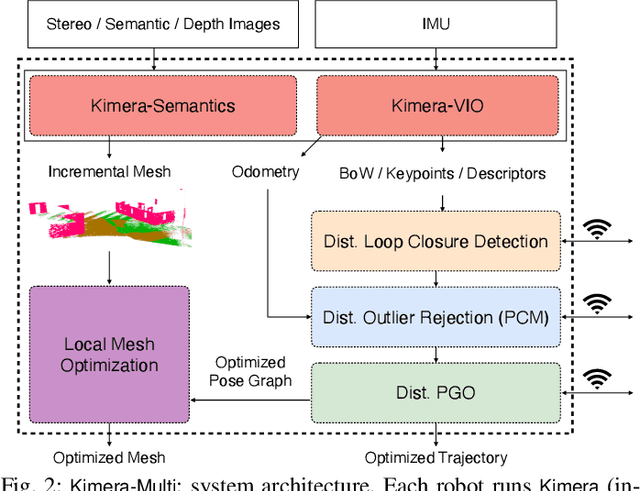
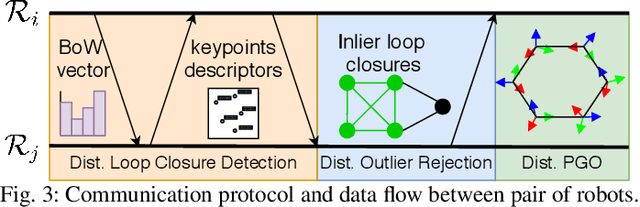
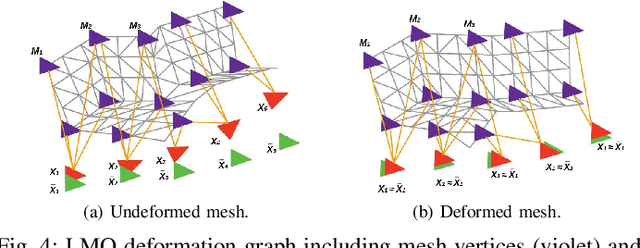
We present the first fully distributed multi-robot system for dense metric-semantic Simultaneous Localization and Mapping (SLAM). Our system, dubbed Kimera-Multi, is implemented by a team of robots equipped with visual-inertial sensors, and builds a 3D mesh model of the environment in real-time, where each face of the mesh is annotated with a semantic label (e.g., building, road, objects). In Kimera-Multi, each robot builds a local trajectory estimate and a local mesh using Kimera. Then, when two robots are within communication range, they initiate a distributed place recognition and robust pose graph optimization protocol with a novel incremental maximum clique outlier rejection; the protocol allows the robots to improve their local trajectory estimates by leveraging inter-robot loop closures. Finally, each robot uses its improved trajectory estimate to correct the local mesh using mesh deformation techniques. We demonstrate Kimera-Multi in photo-realistic simulations and real data. Kimera-Multi (i) is able to build accurate 3D metric-semantic meshes, (ii) is robust to incorrect loop closures while requiring less computation than state-of-the-art distributed SLAM back-ends, and (iii) is efficient, both in terms of computation at each robot as well as communication bandwidth.
Wavelet-Based Dual-Branch Network for Image Demoireing
Jul 17, 2020

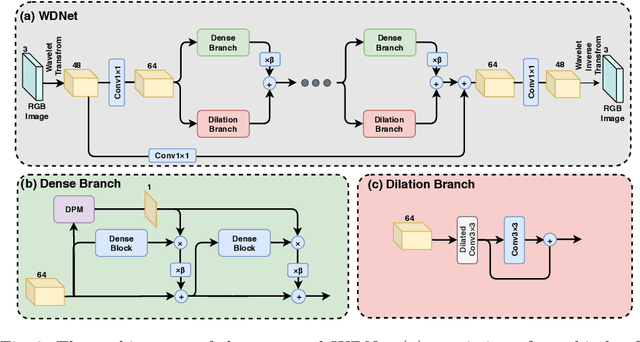

When smartphone cameras are used to take photos of digital screens, usually moire patterns result, severely degrading photo quality. In this paper, we design a wavelet-based dual-branch network (WDNet) with a spatial attention mechanism for image demoireing. Existing image restoration methods working in the RGB domain have difficulty in distinguishing moire patterns from true scene texture. Unlike these methods, our network removes moire patterns in the wavelet domain to separate the frequencies of moire patterns from the image content. The network combines dense convolution modules and dilated convolution modules supporting large receptive fields. Extensive experiments demonstrate the effectiveness of our method, and we further show that WDNet generalizes to removing moire artifacts on non-screen images. Although designed for image demoireing, WDNet has been applied to two other low-levelvision tasks, outperforming state-of-the-art image deraining and derain-drop methods on the Rain100h and Raindrop800 data sets, respectively.
Talking-head Generation with Rhythmic Head Motion
Jul 16, 2020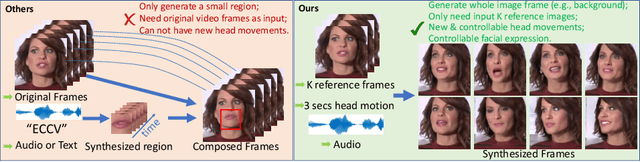
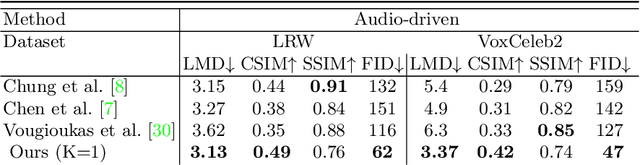
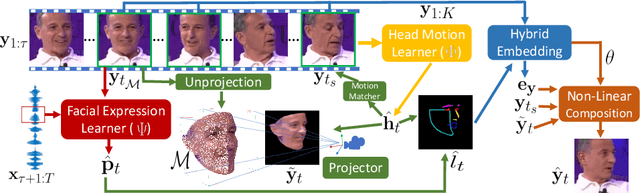
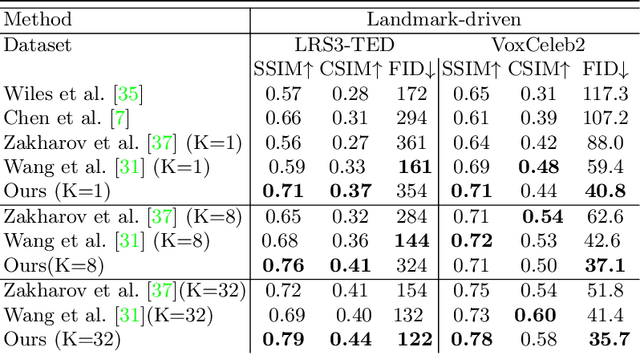
When people deliver a speech, they naturally move heads, and this rhythmic head motion conveys prosodic information. However, generating a lip-synced video while moving head naturally is challenging. While remarkably successful, existing works either generate still talkingface videos or rely on landmark/video frames as sparse/dense mapping guidance to generate head movements, which leads to unrealistic or uncontrollable video synthesis. To overcome the limitations, we propose a 3D-aware generative network along with a hybrid embedding module and a non-linear composition module. Through modeling the head motion and facial expressions1 explicitly, manipulating 3D animation carefully, and embedding reference images dynamically, our approach achieves controllable, photo-realistic, and temporally coherent talking-head videos with natural head movements. Thoughtful experiments on several standard benchmarks demonstrate that our method achieves significantly better results than the state-of-the-art methods in both quantitative and qualitative comparisons. The code is available on https://github.com/ lelechen63/Talking-head-Generation-with-Rhythmic-Head-Motion.
Enhancing Underexposed Photos using Perceptually Bidirectional Similarity
Jul 25, 2019



This paper addresses the problem of enhancing underexposed photos. Existing methods have tackled this problem from many different perspectives and achieved remarkable progress. However, they may fail to produce satisfactory results due to the presence of visual artifacts such as color distortion, loss of details and uneven exposure, etc. To obtain high-quality results free of these artifacts, we present a novel underexposed photo enhancement approach in this paper. Our main observation is that, the reason why existing methods induce the artifacts is because they break a perceptual consistency between the input and the enhanced output. Based on this observation, an effective criterion, called perceptually bidirectional similarity (PBS) is proposed for preserving the perceptual consistency during enhancement. Particularly, we cast the underexposed photo enhancement as PBS-constrained illumination estimation optimization, where the PBS is defined as three constraints for estimating the illumination that can recover the enhancement results with normal exposure, distinct contrast, clear details and vivid color. To make our method more efficient and scalable to high-resolution images, we introduce a sampling-based strategy for accelerating the illumination estimation. Moreover, we extend our method to handle underexposed videos. Qualitative and quantitative comparisons as well as the user study demonstrate the superiority of our method over the state-of-the-art methods.