 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks
Jun 28, 2018
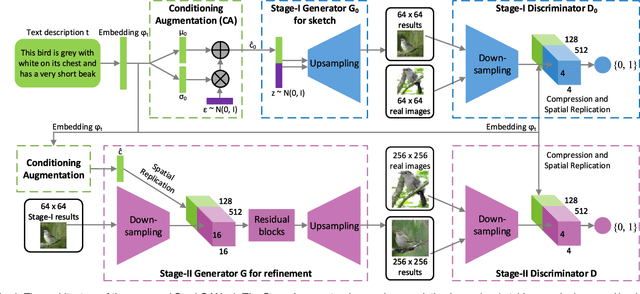

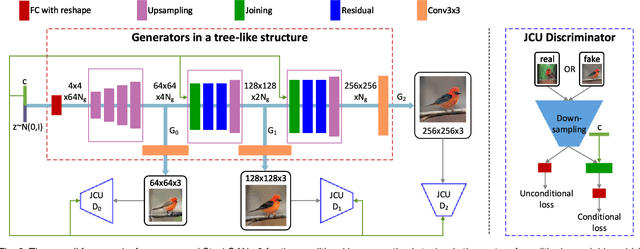

Although Generative Adversarial Networks (GANs) have shown remarkable success in various tasks, they still face challenges in generating high quality images. In this paper, we propose Stacked Generative Adversarial Networks (StackGAN) aiming at generating high-resolution photo-realistic images. First, we propose a two-stage generative adversarial network architecture, StackGAN-v1, for text-to-image synthesis. The Stage-I GAN sketches the primitive shape and colors of the object based on given text description, yielding low-resolution images. The Stage-II GAN takes Stage-I results and text descriptions as inputs, and generates high-resolution images with photo-realistic details. Second, an advanced multi-stage generative adversarial network architecture, StackGAN-v2, is proposed for both conditional and unconditional generative tasks. Our StackGAN-v2 consists of multiple generators and discriminators in a tree-like structure; images at multiple scales corresponding to the same scene are generated from different branches of the tree. StackGAN-v2 shows more stable training behavior than StackGAN-v1 by jointly approximating multiple distributions. Extensive experiments demonstrate that the proposed stacked generative adversarial networks significantly outperform other state-of-the-art methods in generating photo-realistic images.
3D Photography using Context-aware Layered Depth Inpainting
Apr 09, 2020
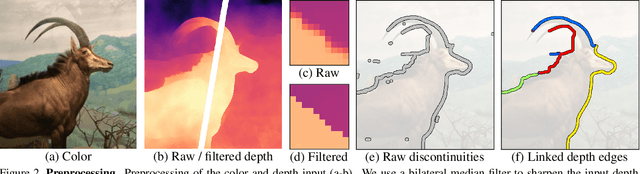
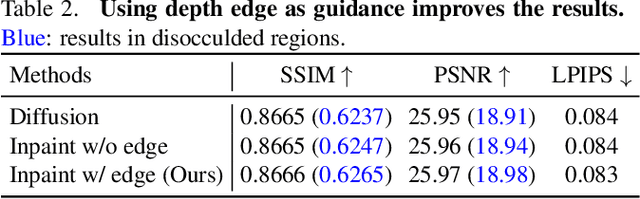

We propose a method for converting a single RGB-D input image into a 3D photo - a multi-layer representation for novel view synthesis that contains hallucinated color and depth structures in regions occluded in the original view. We use a Layered Depth Image with explicit pixel connectivity as underlying representation, and present a learning-based inpainting model that synthesizes new local color-and-depth content into the occluded region in a spatial context-aware manner. The resulting 3D photos can be efficiently rendered with motion parallax using standard graphics engines. We validate the effectiveness of our method on a wide range of challenging everyday scenes and show fewer artifacts compared with the state of the arts.
Learning to Actively Reduce Memory Requirements for Robot Control Tasks
Aug 17, 2020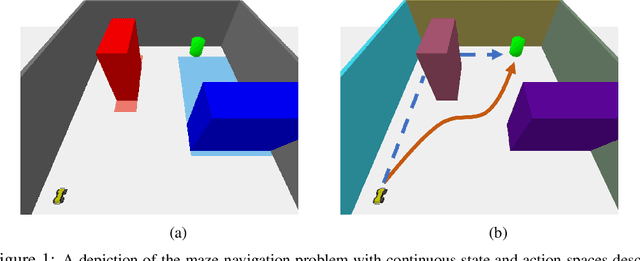
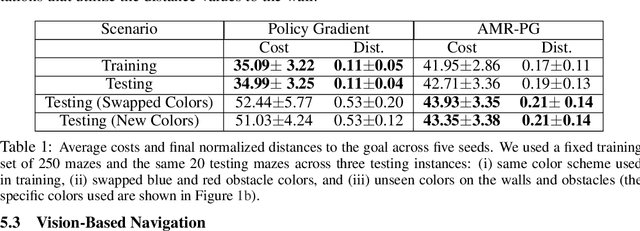
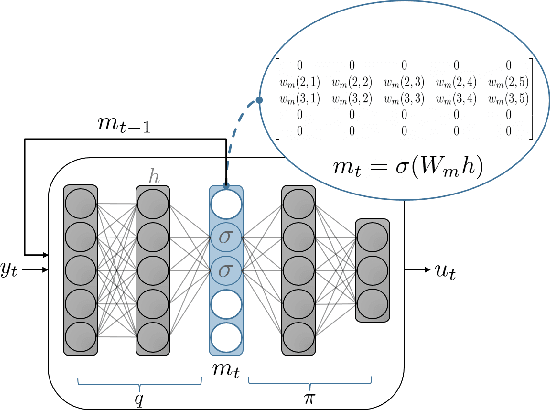
Robots equipped with rich sensing modalities (e.g., RGB-D cameras) performing long-horizon tasks motivate the need for policies that are highly memory-efficient. State-of-the-art approaches for controlling robots often use memory representations that are excessively rich for the task or rely on hand-crafted tricks for memory efficiency. Instead, this work provides a general approach for jointly synthesizing memory representations and policies; the resulting policies actively seek to reduce memory requirements (i.e., take actions that reduce memory usage). Specifically, we present a reinforcement learning framework that leverages an implementation of the group LASSO regularization to synthesize policies that employ low-dimensional and task-centric memory representations. We demonstrate the efficacy of our approach with simulated examples including navigation in discrete and continuous spaces as well as vision-based indoor navigation set in a photo-realistic simulator. The results on these examples indicate that our method is capable of finding policies that rely only on low-dimensional memory representations and actively reduce memory requirements.
Photo-Geometric Autoencoding to Learn 3D Objects from Unlabelled Images
Jun 04, 2019
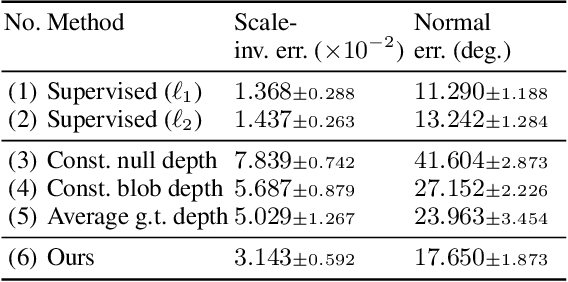
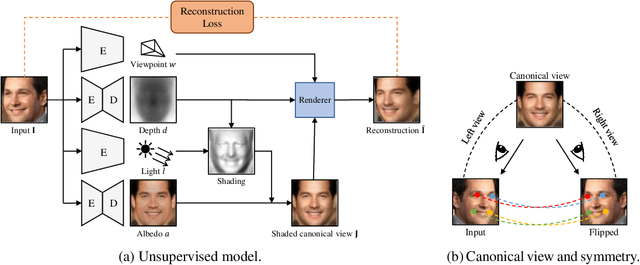

We show that generative models can be used to capture visual geometry constraints statistically. We use this fact to infer the 3D shape of object categories from raw single-view images. Differently from prior work, we use no external supervision, nor do we use multiple views or videos of the objects. We achieve this by a simple reconstruction task, exploiting the symmetry of the objects' shape and albedo. Specifically, given a single image of the object seen from an arbitrary viewpoint, our model predicts a symmetric canonical view, the corresponding 3D shape and a viewpoint transformation, and trains with the goal of reconstructing the input view, resembling an auto-encoder. Our experiments show that this method can recover the 3D shape of human faces, cat faces, and cars from single view images, without supervision. On benchmarks, we demonstrate superior accuracy compared to other methods that use supervision at the level of 2D image correspondences.
Real-time Webcam Heart-Rate and Variability Estimation with Clean Ground Truth for Evaluation
Dec 31, 2020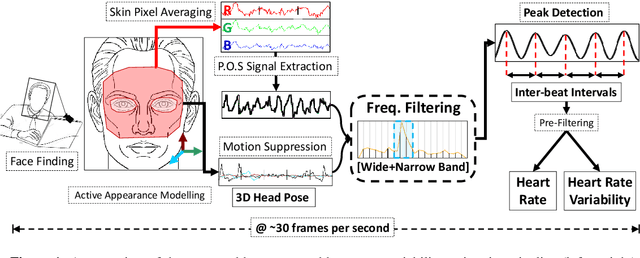
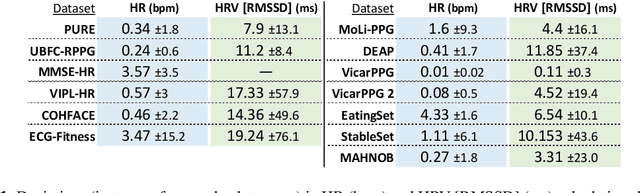
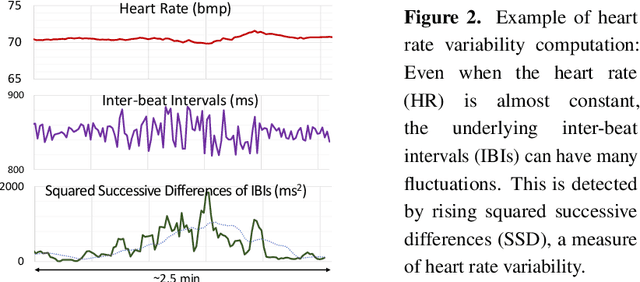
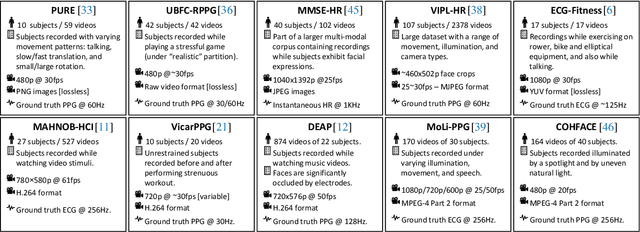
Remote photo-plethysmography (rPPG) uses a camera to estimate a person's heart rate (HR). Similar to how heart rate can provide useful information about a person's vital signs, insights about the underlying physio/psychological conditions can be obtained from heart rate variability (HRV). HRV is a measure of the fine fluctuations in the intervals between heart beats. However, this measure requires temporally locating heart beats with a high degree of precision. We introduce a refined and efficient real-time rPPG pipeline with novel filtering and motion suppression that not only estimates heart rates, but also extracts the pulse waveform to time heart beats and measure heart rate variability. This unsupervised method requires no rPPG specific training and is able to operate in real-time. We also introduce a new multi-modal video dataset, VicarPPG 2, specifically designed to evaluate rPPG algorithms on HR and HRV estimation. We validate and study our method under various conditions on a comprehensive range of public and self-recorded datasets, showing state-of-the-art results and providing useful insights into some unique aspects. Lastly, we make available CleanerPPG, a collection of human-verified ground truth peak/heart-beat annotations for existing rPPG datasets. These verified annotations should make future evaluations and benchmarking of rPPG algorithms more accurate, standardized and fair.
* Published in the MDPI Applied Sciences journal special issue Video Analysis for Health Monitoring on December 2, 2020. arXiv admin note: text overlap with arXiv:1909.01206
Accelerating Probabilistic Volumetric Mapping using Ray-Tracing Graphics Hardware
Dec 02, 2020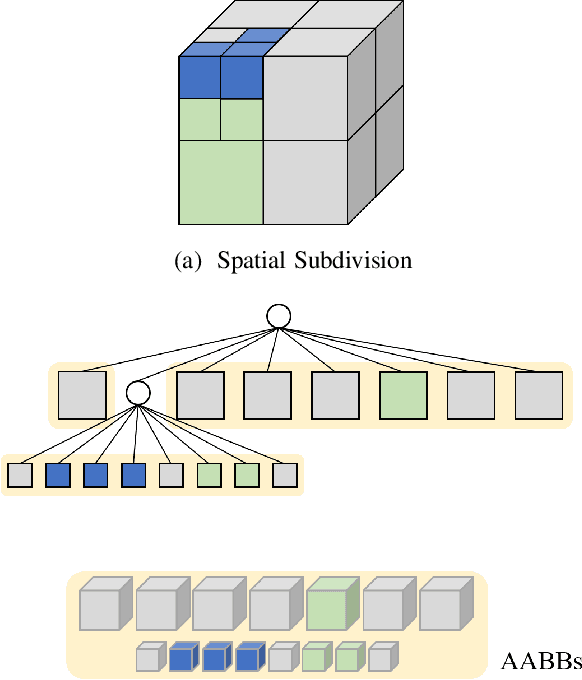
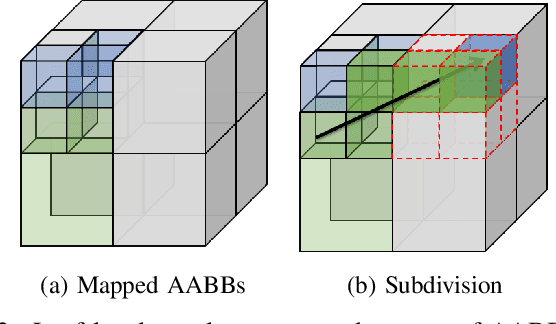
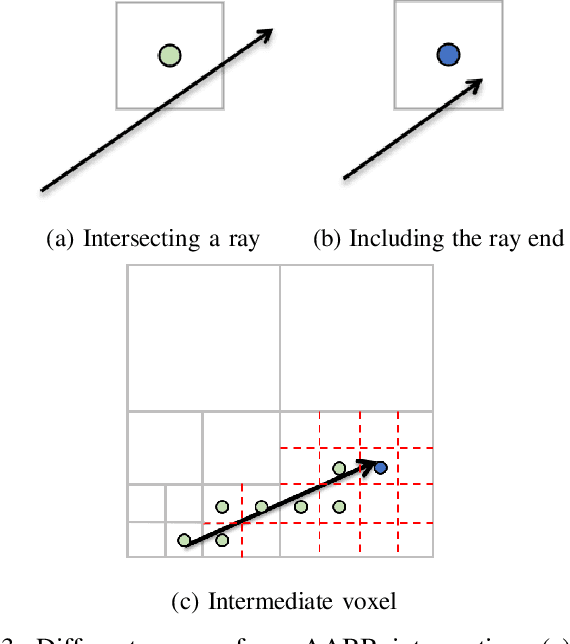
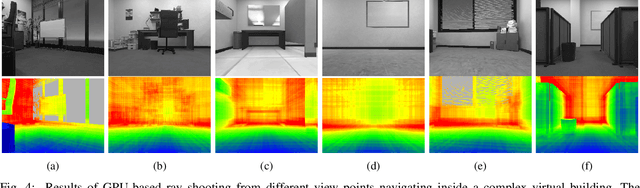
Probabilistic volumetric mapping (PVM) represents a 3D environmental map for an autonomous robotic navigational task. A popular implementation such as Octomap is widely used in the robotics community for such a purpose. The Octomap relies on octree to represent a PVM and its main bottleneck lies in massive ray-shooting to determine the occupancy of the underlying volumetric voxel grids. In this paper, we propose GPU-based ray shooting to drastically improve the ray shooting performance in Octomap. Our main idea is based on the use of recent ray-tracing RTX GPU, mainly designed for real-time photo-realistic computer graphics and the accompanying graphics API, known as DXR. Our ray-shooting first maps leaf-level voxels in the given octree to a set of axis-aligned bounding boxes (AABBs) and employ massively parallel ray shooting on them using GPUs to find free and occupied voxels. These are fed back into CPU to update the voxel occupancy and restructure the octree. In our experiments, we have observed more than three-orders-of-magnitude performance improvement in terms of ray shooting using ray-tracing RTX GPU over a state-of-the-art Octomap CPU implementation, where the benchmarking environments consist of more than 77K points and 25K~34K voxel grids.
Towards Unsupervised Deep Image Enhancement with Generative Adversarial Network
Dec 30, 2020


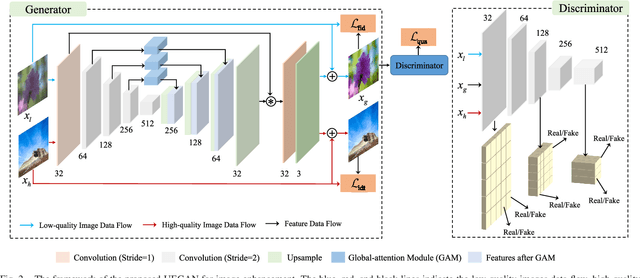
Improving the aesthetic quality of images is challenging and eager for the public. To address this problem, most existing algorithms are based on supervised learning methods to learn an automatic photo enhancer for paired data, which consists of low-quality photos and corresponding expert-retouched versions. However, the style and characteristics of photos retouched by experts may not meet the needs or preferences of general users. In this paper, we present an unsupervised image enhancement generative adversarial network (UEGAN), which learns the corresponding image-to-image mapping from a set of images with desired characteristics in an unsupervised manner, rather than learning on a large number of paired images. The proposed model is based on single deep GAN which embeds the modulation and attention mechanisms to capture richer global and local features. Based on the proposed model, we introduce two losses to deal with the unsupervised image enhancement: (1) fidelity loss, which is defined as a L2 regularization in the feature domain of a pre-trained VGG network to ensure the content between the enhanced image and the input image is the same, and (2) quality loss that is formulated as a relativistic hinge adversarial loss to endow the input image the desired characteristics. Both quantitative and qualitative results show that the proposed model effectively improves the aesthetic quality of images. Our code is available at: https://github.com/eezkni/UEGAN.
An Automatic Reader of Identity Documents
Jun 26, 2020
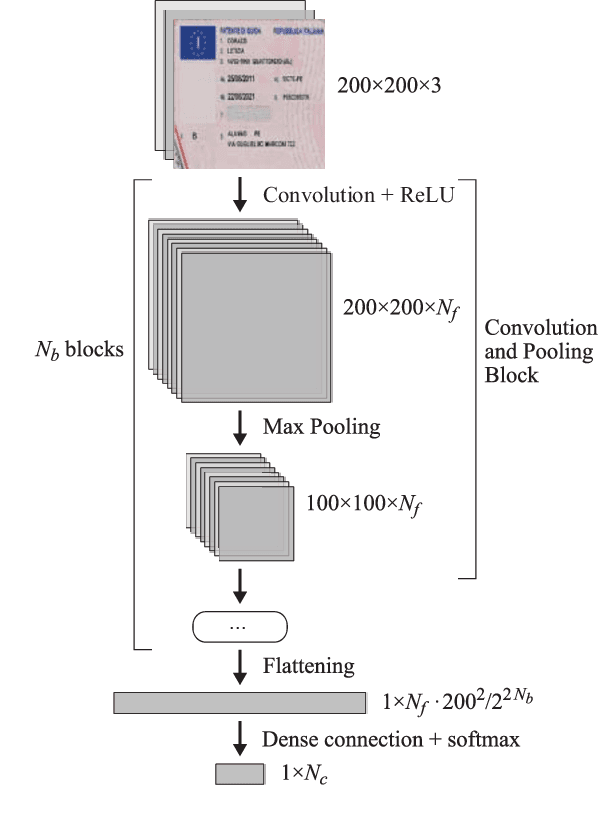


Identity documents automatic reading and verification is an appealing technology for nowadays service industry, since this task is still mostly performed manually, leading to waste of economic and time resources. In this paper the prototype of a novel automatic reading system of identity documents is presented. The system has been thought to extract data of the main Italian identity documents from photographs of acceptable quality, like those usually required to online subscribers of various services. The document is first localized inside the photo, and then classified; finally, text recognition is executed. A synthetic dataset has been used, both for neural networks training, and for performance evaluation of the system. The synthetic dataset avoided privacy issues linked to the use of real photos of real documents, which will be used, instead, for future developments of the system.
PAT image reconstruction using augmented sparsity regularization with semi-automated tuning of regularization weight
Mar 24, 2021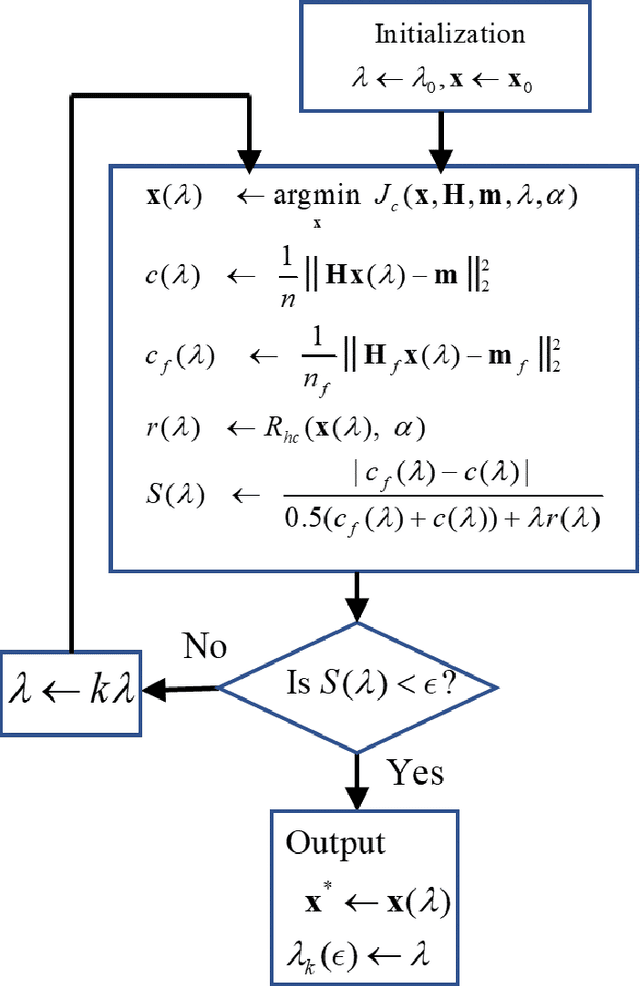
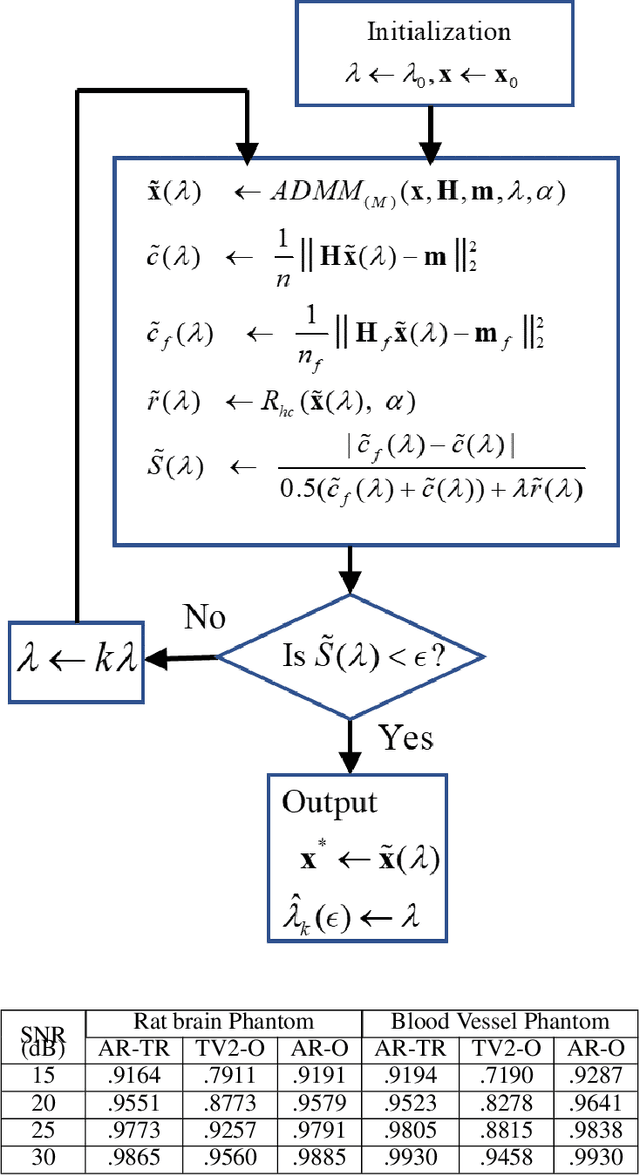
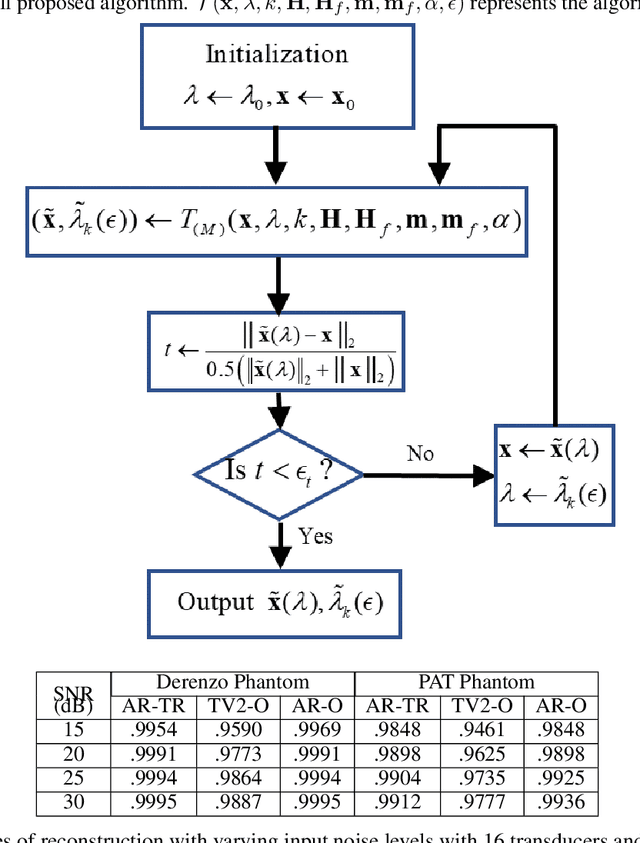
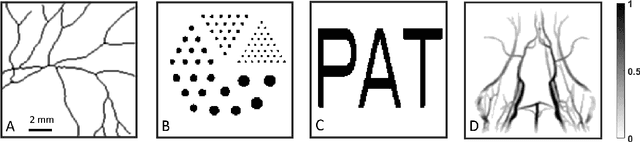
Among all tissue imaging modalities, photo-acoustic tomography (PAT) has been getting increasing attention in the recent past due to the fact that it has high contrast, high penetrability, and has capability of retrieving high resolution. The reconstruction methods used in PAT plays a crucial role in the applicability of PAT, and PAT finds particularly a wider applicability if a model-based regularized reconstruction method is used. A crucial factor that determines the quality of reconstruction in such methods is the choice of regularization weight. Unfortunately, an appropriately tuned value of regularization weight varies significantly with variation in the noise level, as well as, with the variation in the high resolution contents of the image, in a way that has not been well understood. There has been attempts to determine optimum regularization weight from the measured data in the context of using elementary and general purpose regularizations. In this paper, we develop a method for semi-automated tuning of the regularization weight in the context of using a modern type of regularization that was specifically designed for PAT image reconstruction. As a first step, we introduce a relative smoothness constraint with a parameter; this parameter computationally maps into the actual regularization weight, but, its tuning does not vary significantly with variation in the noise level, and with the variation in the high resolution contents of the image. Next, we construct an algorithm that integrates the task of determining this mapping along with obtaining the reconstruction. Finally we demonstrate experimentally that we can run this algorithm with a nominal value of the relative smoothness parameter -- a value independent of the noise level and the structure of the underlying image -- to obtain good quality reconstructions.
Deep View Synthesis via Self-Consistent Generative Network
Jan 19, 2021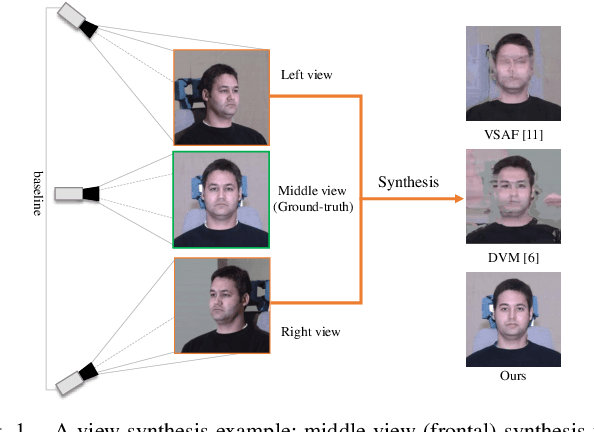



View synthesis aims to produce unseen views from a set of views captured by two or more cameras at different positions. This task is non-trivial since it is hard to conduct pixel-level matching among different views. To address this issue, most existing methods seek to exploit the geometric information to match pixels. However, when the distinct cameras have a large baseline (i.e., far away from each other), severe geometry distortion issues would occur and the geometric information may fail to provide useful guidance, resulting in very blurry synthesized images. To address the above issues, in this paper, we propose a novel deep generative model, called Self-Consistent Generative Network (SCGN), which synthesizes novel views from the given input views without explicitly exploiting the geometric information. The proposed SCGN model consists of two main components, i.e., a View Synthesis Network (VSN) and a View Decomposition Network (VDN), both employing an Encoder-Decoder structure. Here, the VDN seeks to reconstruct input views from the synthesized novel view to preserve the consistency of view synthesis. Thanks to VDN, SCGN is able to synthesize novel views without using any geometric rectification before encoding, making it easier for both training and applications. Finally, adversarial loss is introduced to improve the photo-realism of novel views. Both qualitative and quantitative comparisons against several state-of-the-art methods on two benchmark tasks demonstrated the superiority of our approach.