 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Learning Compositional Radiance Fields of Dynamic Human Heads
Dec 17, 2020
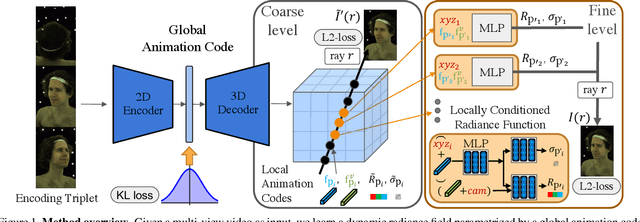



Photorealistic rendering of dynamic humans is an important ability for telepresence systems, virtual shopping, synthetic data generation, and more. Recently, neural rendering methods, which combine techniques from computer graphics and machine learning, have created high-fidelity models of humans and objects. Some of these methods do not produce results with high-enough fidelity for driveable human models (Neural Volumes) whereas others have extremely long rendering times (NeRF). We propose a novel compositional 3D representation that combines the best of previous methods to produce both higher-resolution and faster results. Our representation bridges the gap between discrete and continuous volumetric representations by combining a coarse 3D-structure-aware grid of animation codes with a continuous learned scene function that maps every position and its corresponding local animation code to its view-dependent emitted radiance and local volume density. Differentiable volume rendering is employed to compute photo-realistic novel views of the human head and upper body as well as to train our novel representation end-to-end using only 2D supervision. In addition, we show that the learned dynamic radiance field can be used to synthesize novel unseen expressions based on a global animation code. Our approach achieves state-of-the-art results for synthesizing novel views of dynamic human heads and the upper body.
Instance-level Sketch-based Retrieval by Deep Triplet Classification Siamese Network
Nov 28, 2018
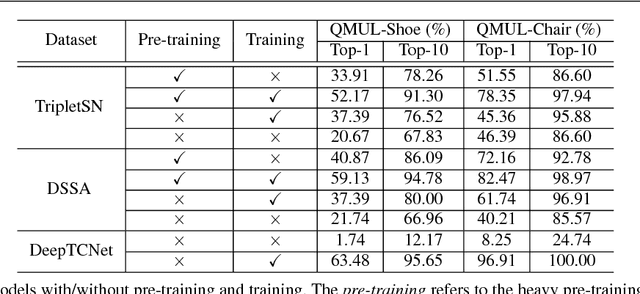


Sketch has been employed as an effective communicative tool to express the abstract and intuitive meanings of object. Recognizing the free-hand sketch drawing is extremely useful in many real-world applications. While content-based sketch recognition has been studied for several decades, the instance-level Sketch-Based Image Retrieval (SBIR) tasks have attracted significant research attention recently. The existing datasets such as QMUL-Chair and QMUL-Shoe, focus on the retrieval tasks of chairs and shoes. However, there are several key limitations in previous instance-level SBIR works. The state-of-the-art works have to heavily rely on the pre-training process, quality of edge maps, multi-cropping testing strategy, and augmenting sketch images. To efficiently solve the instance-level SBIR, we propose a new Deep Triplet Classification Siamese Network (DeepTCNet) which employs DenseNet-169 as the basic feature extractor and is optimized by the triplet loss and classification loss. Critically, our proposed DeepTCNet can break the limitations existed in previous works. The extensive experiments on five benchmark sketch datasets validate the effectiveness of the proposed model. Additionally, to study the tasks of sketch-based hairstyle retrieval, this paper contributes a new instance-level photo-sketch dataset - Hairstyle Photo-Sketch dataset, which is composed of 3600 sketches and photos, and 2400 sketch-photo pairs.
StegaStamp: Invisible Hyperlinks in Physical Photographs
Apr 10, 2019


Imagine a world in which each photo, printed or digitally displayed, hides arbitrary digital data that can be accessed through an internet-connected imaging system. Another way to think about this is physical photographs that have unique QR codes invisibly embedded within them. This paper presents an architecture, algorithms, and a prototype implementation addressing this vision. Our key technical contribution is StegaStamp, the first steganographic algorithm to enable robust encoding and decoding of arbitrary hyperlink bitstrings into photos in a manner that approaches perceptual invisibility. StegaStamp comprises a deep neural network that learns an encoding/decoding algorithm robust to image perturbations that approximate the space of distortions resulting from real printing and photography. Our system prototype demonstrates real-time decoding of hyperlinks for photos from in-the-wild video subject to real-world variation in print quality, lighting, shadows, perspective, occlusion and viewing distance. Our prototype system robustly retrieves 56 bit hyperlinks after error correction -- sufficient to embed a unique code within every photo on the internet.
Quantitative Analysis of Automatic Image Cropping Algorithms: A Dataset and Comparative Study
Jan 05, 2017
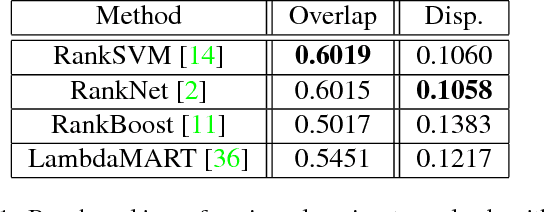

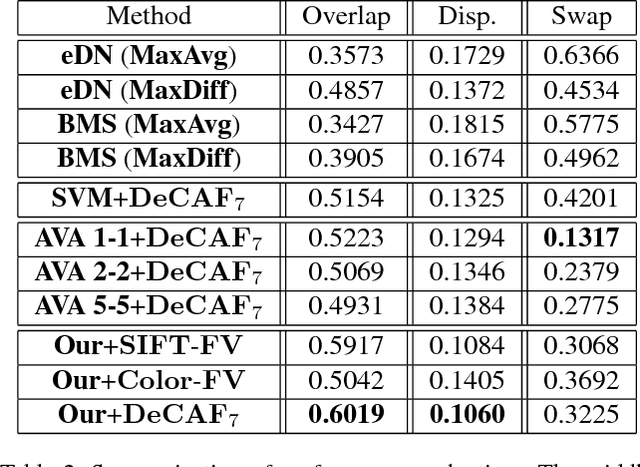
Automatic photo cropping is an important tool for improving visual quality of digital photos without resorting to tedious manual selection. Traditionally, photo cropping is accomplished by determining the best proposal window through visual quality assessment or saliency detection. In essence, the performance of an image cropper highly depends on the ability to correctly rank a number of visually similar proposal windows. Despite the ranking nature of automatic photo cropping, little attention has been paid to learning-to-rank algorithms in tackling such a problem. In this work, we conduct an extensive study on traditional approaches as well as ranking-based croppers trained on various image features. In addition, a new dataset consisting of high quality cropping and pairwise ranking annotations is presented to evaluate the performance of various baselines. The experimental results on the new dataset provide useful insights into the design of better photo cropping algorithms.
More Than Accuracy: Towards Trustworthy Machine Learning Interfaces for Object Recognition
Aug 05, 2020
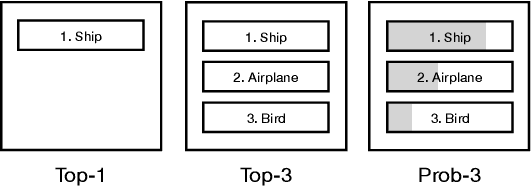
This paper investigates the user experience of visualizations of a machine learning (ML) system that recognizes objects in images. This is important since even good systems can fail in unexpected ways as misclassifications on photo-sharing websites showed. In our study, we exposed users with a background in ML to three visualizations of three systems with different levels of accuracy. In interviews, we explored how the visualization helped users assess the accuracy of systems in use and how the visualization and the accuracy of the system affected trust and reliance. We found that participants do not only focus on accuracy when assessing ML systems. They also take the perceived plausibility and severity of misclassification into account and prefer seeing the probability of predictions. Semantically plausible errors are judged as less severe than errors that are implausible, which means that system accuracy could be communicated through the types of errors.
* UMAP '20: Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization
Photo-Geometric Autoencoding to Learn 3D Objects from Unlabelled Images
Jun 04, 2019
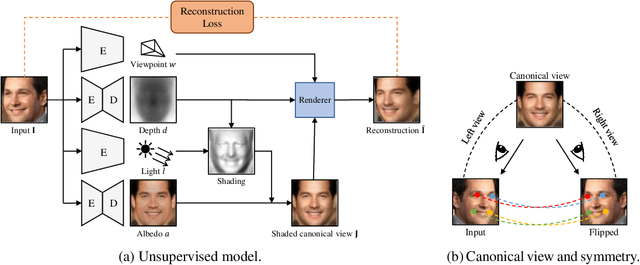

We show that generative models can be used to capture visual geometry constraints statistically. We use this fact to infer the 3D shape of object categories from raw single-view images. Differently from prior work, we use no external supervision, nor do we use multiple views or videos of the objects. We achieve this by a simple reconstruction task, exploiting the symmetry of the objects' shape and albedo. Specifically, given a single image of the object seen from an arbitrary viewpoint, our model predicts a symmetric canonical view, the corresponding 3D shape and a viewpoint transformation, and trains with the goal of reconstructing the input view, resembling an auto-encoder. Our experiments show that this method can recover the 3D shape of human faces, cat faces, and cars from single view images, without supervision. On benchmarks, we demonstrate superior accuracy compared to other methods that use supervision at the level of 2D image correspondences.
CartoonRenderer: An Instance-based Multi-Style Cartoon Image Translator
Nov 14, 2019
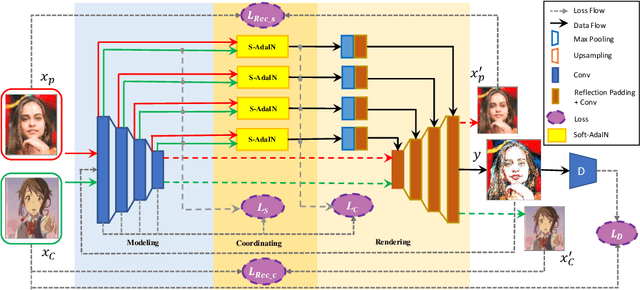

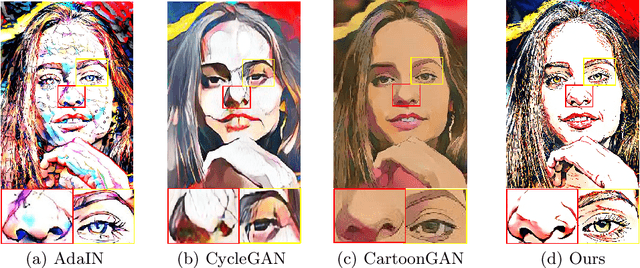
Instance based photo cartoonization is one of the challenging image stylization tasks which aim at transforming realistic photos into cartoon style images while preserving the semantic contents of the photos. State-of-the-art Deep Neural Networks (DNNs) methods still fail to produce satisfactory results with input photos in the wild, especially for photos which have high contrast and full of rich textures. This is due to that: cartoon style images tend to have smooth color regions and emphasized edges which are contradict to realistic photos which require clear semantic contents, i.e., textures, shapes etc. Previous methods have difficulty in satisfying cartoon style textures and preserving semantic contents at the same time. In this work, we propose a novel "CartoonRenderer" framework which utilizing a single trained model to generate multiple cartoon styles. In a nutshell, our method maps photo into a feature model and renders the feature model back into image space. In particular, cartoonization is achieved by conducting some transformation manipulation in the feature space with our proposed Soft-AdaIN. Extensive experimental results show our method produces higher quality cartoon style images than prior arts, with accurate semantic content preservation. In addition, due to the decoupling of whole generating process into "Modeling-Coordinating-Rendering" parts, our method could easily process higher resolution photos, which is intractable for existing methods.
Two-Stream Appearance Transfer Network for Person Image Generation
Nov 09, 2020
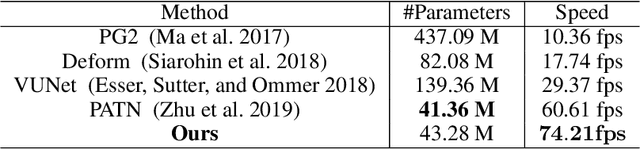
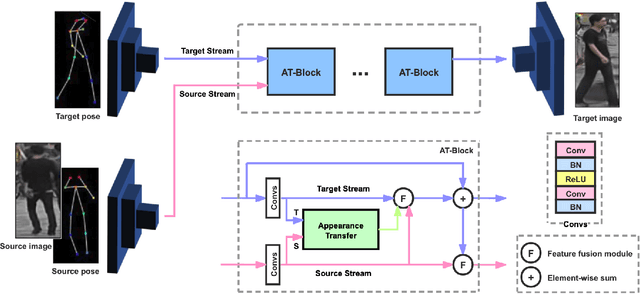

Pose guided person image generation means to generate a photo-realistic person image conditioned on an input person image and a desired pose. This task requires spatial manipulation of the source image according to the target pose. However, the generative adversarial networks (GANs) widely used for image generation and translation rely on spatially local and translation equivariant operators, i.e., convolution, pooling and unpooling, which cannot handle large image deformation. This paper introduces a novel two-stream appearance transfer network (2s-ATN) to address this challenge. It is a multi-stage architecture consisting of a source stream and a target stream. Each stage features an appearance transfer module and several two-stream feature fusion modules. The former finds the dense correspondence between the two-stream feature maps and then transfers the appearance information from the source stream to the target stream. The latter exchange local information between the two streams and supplement the non-local appearance transfer. Both quantitative and qualitative results indicate the proposed 2s-ATN can effectively handle large spatial deformation and occlusion while retaining the appearance details. It outperforms prior states of the art on two widely used benchmarks.
This Face Does Not Exist ... But It Might Be Yours! Identity Leakage in Generative Models
Dec 10, 2020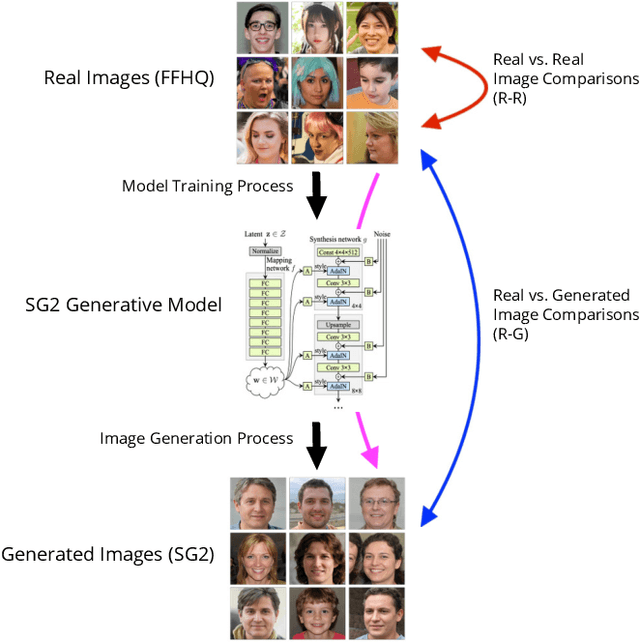


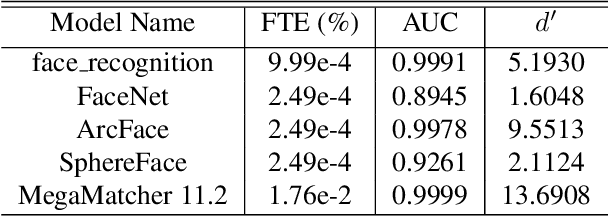
Generative adversarial networks (GANs) are able to generate high resolution photo-realistic images of objects that "do not exist." These synthetic images are rather difficult to detect as fake. However, the manner in which these generative models are trained hints at a potential for information leakage from the supplied training data, especially in the context of synthetic faces. This paper presents experiments suggesting that identity information in face images can flow from the training corpus into synthetic samples without any adversarial actions when building or using the existing model. This raises privacy-related questions, but also stimulates discussions of (a) the face manifold's characteristics in the feature space and (b) how to create generative models that do not inadvertently reveal identity information of real subjects whose images were used for training. We used five different face matchers (face_recognition, FaceNet, ArcFace, SphereFace and Neurotechnology MegaMatcher) and the StyleGAN2 synthesis model, and show that this identity leakage does exist for some, but not all methods. So, can we say that these synthetically generated faces truly do not exist? Databases of real and synthetically generated faces are made available with this paper to allow full replicability of the results discussed in this work.
3D Photography using Context-aware Layered Depth Inpainting
Apr 14, 2020
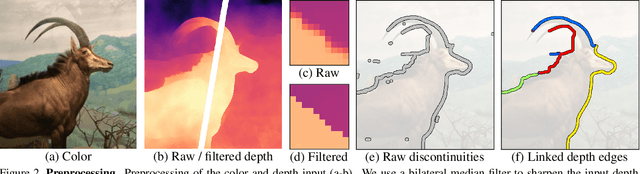
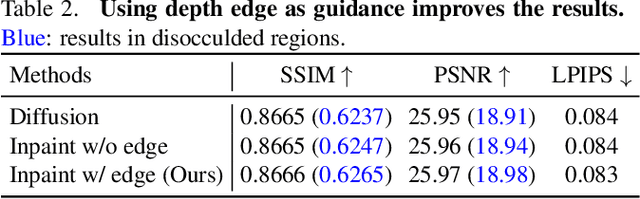

We propose a method for converting a single RGB-D input image into a 3D photo - a multi-layer representation for novel view synthesis that contains hallucinated color and depth structures in regions occluded in the original view. We use a Layered Depth Image with explicit pixel connectivity as underlying representation, and present a learning-based inpainting model that synthesizes new local color-and-depth content into the occluded region in a spatial context-aware manner. The resulting 3D photos can be efficiently rendered with motion parallax using standard graphics engines. We validate the effectiveness of our method on a wide range of challenging everyday scenes and show fewer artifacts compared with the state of the arts.