 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Signal reconstruction via operator guiding
May 09, 2017
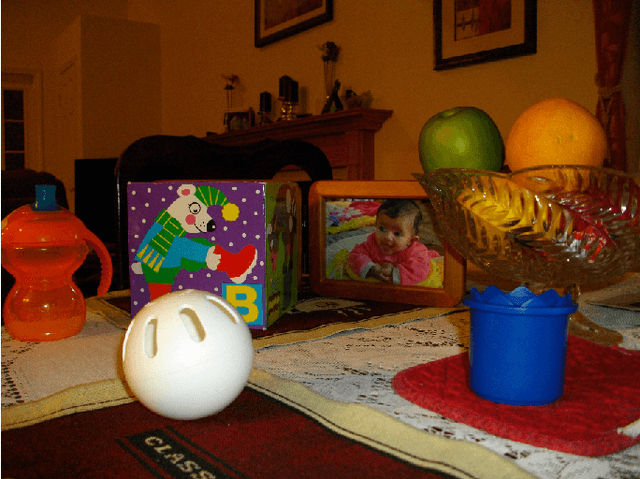
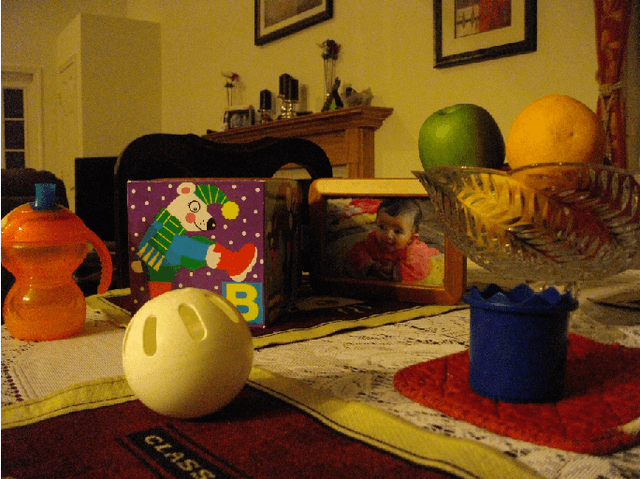
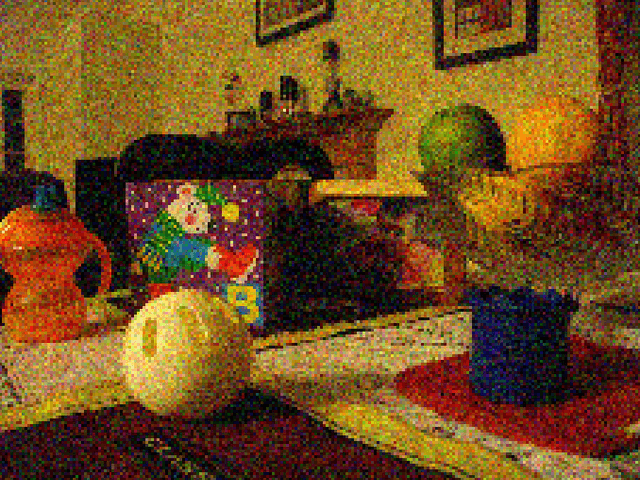

Signal reconstruction from a sample using an orthogonal projector onto a guiding subspace is theoretically well justified, but may be difficult to practically implement. We propose more general guiding operators, which increase signal components in the guiding subspace relative to those in a complementary subspace, e.g., iterative low-pass edge-preserving filters for super-resolution of images. Two examples of super-resolution illustrate our technology: a no-flash RGB photo guided using a high resolution flash RGB photo, and a depth image guided using a high resolution RGB photo.
* 5 pages, 8 figures. To appear in Proceedings of SampTA 2017: Sampling Theory and Applications, 12th International Conference, July 3-7, 2017, Tallinn, Estonia
A picture is worth a thousand words but how to organize thousands of pictures?
Mar 15, 2018
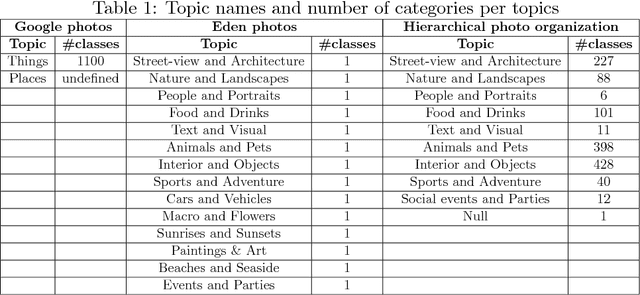

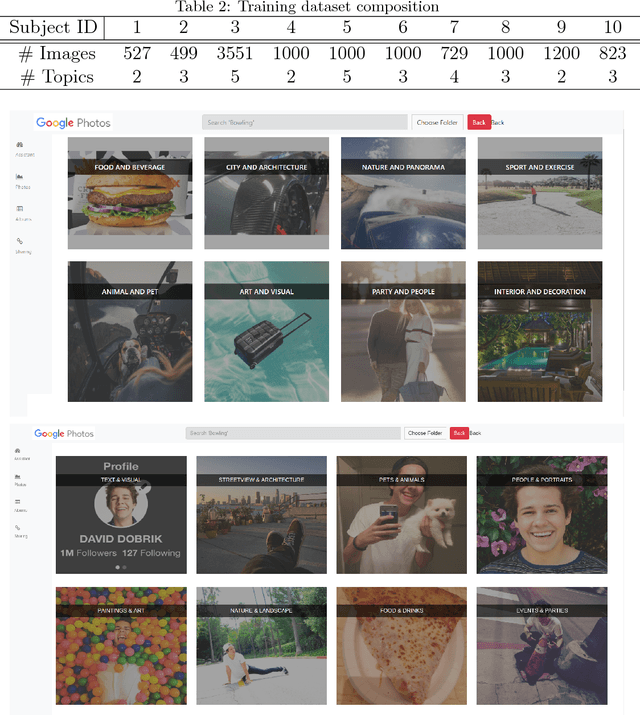
We live in a society where the large majority of the population has a camera-equipped smartphone. In addition, hard drives and cloud storage are getting cheaper and cheaper, leading to a tremendous growth in stored personal photos. Unlike photo collections captured by a digital camera, which typically are pre-processed by the user who organizes them into event-related folders, smartphone pictures are automatically stored in the cloud. As a consequence, photo collections captured by a smartphone are highly unstructured and because smartphones are ubiquitous, they present a larger variability compared to pictures captured by a digital camera. To solve the need of organizing large smartphone photo collections automatically, we propose here a new methodology for hierarchical photo organization into topics and topic-related categories. Our approach successfully estimates latent topics in the pictures by applying probabilistic Latent Semantic Analysis, and automatically assigns a name to each topic by relying on a lexical database. Topic-related categories are then estimated by using a set of topic-specific Convolutional Neuronal Networks. To validate our approach, we ensemble and make public a large dataset of more than 8,000 smartphone pictures from 10 persons. Experimental results demonstrate better user satisfaction with respect to state of the art solutions in terms of organization.
From IC Layout to Die Photo: A CNN-Based Data-Driven Approach
Feb 11, 2020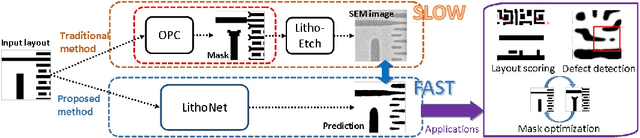

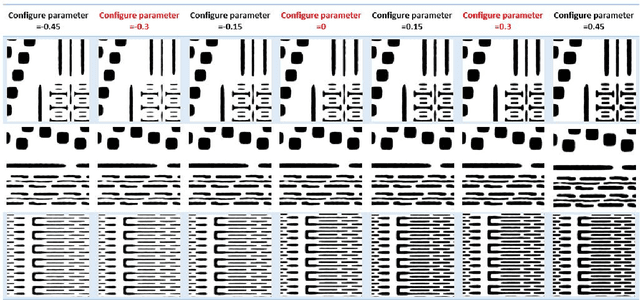
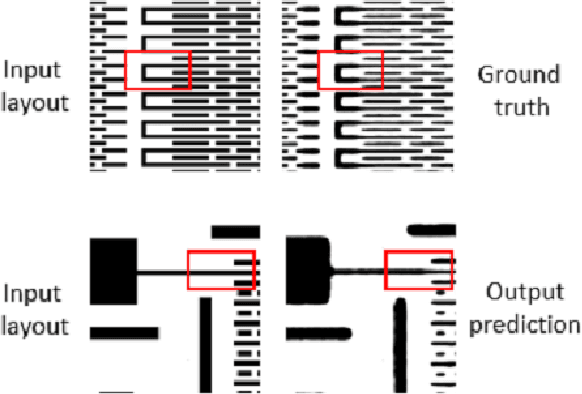
Since IC fabrication is costly and time-consuming, it is highly desirable to develop virtual metrology tools that can predict the properties of a wafer based on fabrication configurations without performing physical measurements on a fabricated IC. We propose a deep learning-based data-driven framework consisting of two convolutional neural networks: i) LithoNet that predicts the shape deformations on a circuit due to IC fabrication, and ii) OPCNet that suggests IC layout corrections to compensate for such shape deformations. By learning the shape correspondence between pairs of layout design patterns and their SEM images of the product wafer thereof, given an IC layout pattern, LithoNet can mimic the fabrication procedure to predict its fabricated circuit shape for virtual metrology. Furthermore, LithoNet can take the wafer fabrication parameters as a latent vector to model the parametric product variations that can be inspected on SEM images. In addition, traditional lithography simulation methods used to suggest a correction on a lithographic photomask is computationally expensive. Our proposed OPCNet mimics the optical proximity correction (OPC) procedure and efficiently generates a corrected photomask by collaborating with LithoNet to examine if the shape of a fabricated IC circuitry best matches its original layout design. As a result, the proposed LithoNet-OPCNet framework cannot only predict the shape of a fabricated IC from its layout pattern, but also suggests a layout correction according to the consistency between the predicted shape and the given layout. Experimental results with several benchmark layout patterns demonstrate the effectiveness of the proposed method.
Neural Scene Graphs for Dynamic Scenes
Nov 20, 2020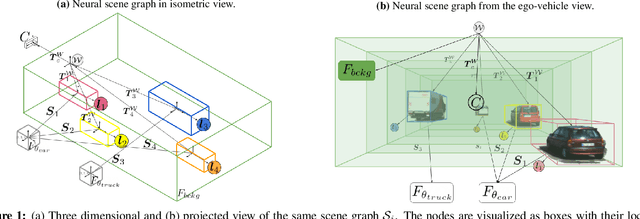
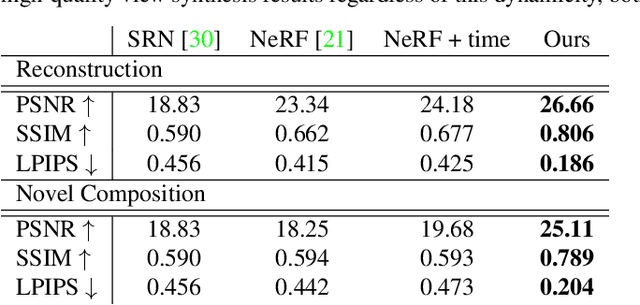
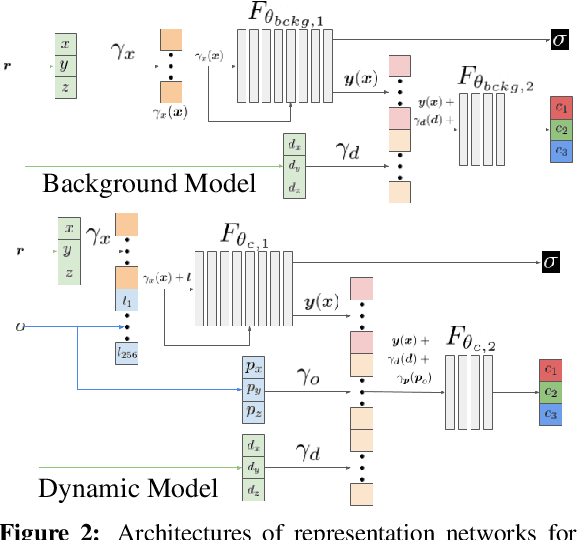

Recent implicit neural rendering methods have demonstrated that it is possible to learn accurate view synthesis for complex scenes by predicting their volumetric density and color supervised solely by a set of RGB images. However, existing methods are restricted to learning efficient interpolations of static scenes that encode all scene objects into a single neural network, lacking the ability to represent dynamic scenes and decompositions into individual scene objects. In this work, we present the first neural rendering method that decomposes dynamic scenes into scene graphs. We propose a learned scene graph representation, which encodes object transformation and radiance, to efficiently render novel arrangements and views of the scene. To this end, we learn implicitly encoded scenes, combined with a jointly learned latent representation to describe objects with a single implicit function. We assess the proposed method on synthetic and real automotive data, validating that our approach learns dynamic scenes - only by observing a video of this scene - and allows for rendering novel photo-realistic views of novel scene compositions with unseen sets of objects at unseen poses.
Style Intervention: How to Achieve Spatial Disentanglement with Style-based Generators?
Nov 19, 2020


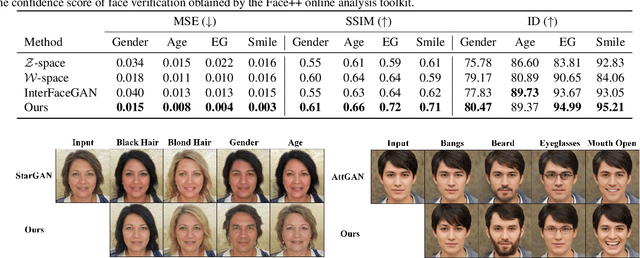
Generative Adversarial Networks (GANs) with style-based generators (e.g. StyleGAN) successfully enable semantic control over image synthesis, and recent studies have also revealed that interpretable image translations could be obtained by modifying the latent code. However, in terms of the low-level image content, traveling in the latent space would lead to `spatially entangled changes' in corresponding images, which is undesirable in many real-world applications where local editing is required. To solve this problem, we analyze properties of the 'style space' and explore the possibility of controlling the local translation with pre-trained style-based generators. Concretely, we propose 'Style Intervention', a lightweight optimization-based algorithm which could adapt to arbitrary input images and render natural translation effects under flexible objectives. We verify the performance of the proposed framework in facial attribute editing on high-resolution images, where both photo-realism and consistency are required. Extensive qualitative results demonstrate the effectiveness of our method, and quantitative measurements also show that the proposed algorithm outperforms state-of-the-art benchmarks in various aspects.
Photo-realistic Facial Texture Transfer
Jun 14, 2017
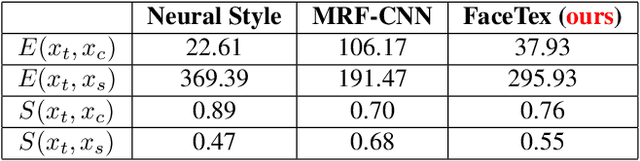

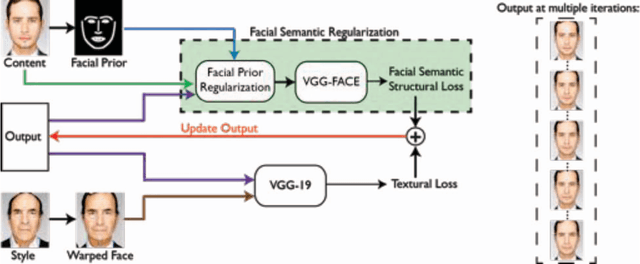
Style transfer methods have achieved significant success in recent years with the use of convolutional neural networks. However, many of these methods concentrate on artistic style transfer with few constraints on the output image appearance. We address the challenging problem of transferring face texture from a style face image to a content face image in a photorealistic manner without changing the identity of the original content image. Our framework for face texture transfer (FaceTex) augments the prior work of MRF-CNN with a novel facial semantic regularization that incorporates a face prior regularization smoothly suppressing the changes around facial meso-structures (e.g eyes, nose and mouth) and a facial structure loss function which implicitly preserves the facial structure so that face texture can be transferred without changing the original identity. We demonstrate results on face images and compare our approach with recent state-of-the-art methods. Our results demonstrate superior texture transfer because of the ability to maintain the identity of the original face image.
Smartphone Camera De-identification while Preserving Biometric Utility
Sep 17, 2020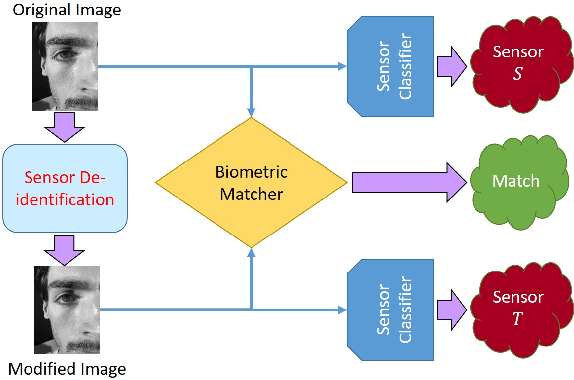
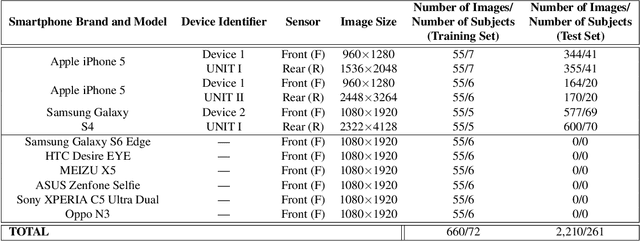
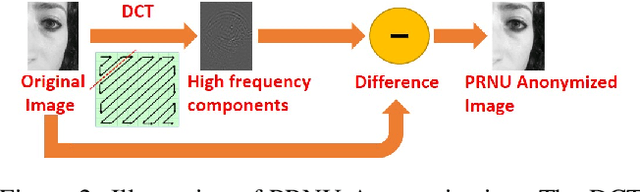
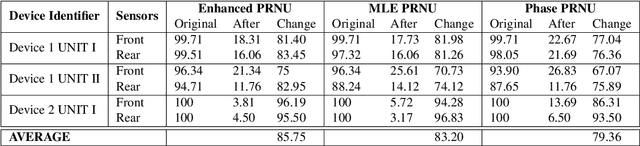
The principle of Photo Response Non Uniformity (PRNU) is often exploited to deduce the identity of the smartphone device whose camera or sensor was used to acquire a certain image. In this work, we design an algorithm that perturbs a face image acquired using a smartphone camera such that (a) sensor-specific details pertaining to the smartphone camera are suppressed (sensor anonymization); (b) the sensor pattern of a different device is incorporated (sensor spoofing); and (c) biometric matching using the perturbed image is not affected (biometric utility). We employ a simple approach utilizing Discrete Cosine Transform to achieve the aforementioned objectives. Experiments conducted on the MICHE-I and OULU-NPU datasets, which contain periocular and facial data acquired using 12 smartphone cameras, demonstrate the efficacy of the proposed de-identification algorithm on three different PRNU-based sensor identification schemes. This work has application in sensor forensics and personal privacy.
TartanAir: A Dataset to Push the Limits of Visual SLAM
Mar 31, 2020



We present a challenging dataset, the TartanAir, for robot navigation task and more. The data is collected in photo-realistic simulation environments in the presence of various light conditions, weather and moving objects. By collecting data in simulation, we are able to obtain multi-modal sensor data and precise ground truth labels, including the stereo RGB image, depth image, segmentation, optical flow, camera poses, and LiDAR point cloud. We set up a large number of environments with various styles and scenes, covering challenging viewpoints and diverse motion patterns, which are difficult to achieve by using physical data collection platforms.
Cross-Modal Contrastive Learning for Text-to-Image Generation
Jan 15, 2021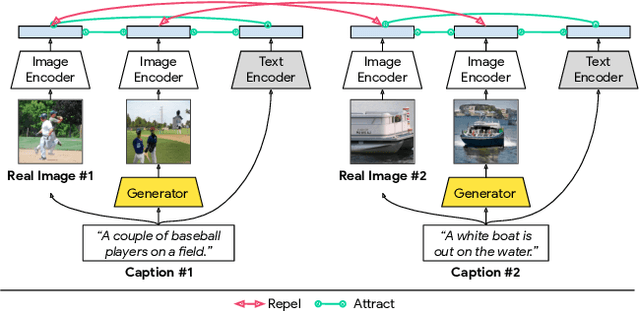
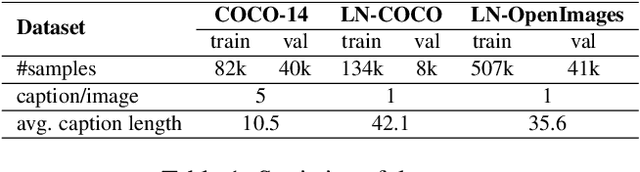
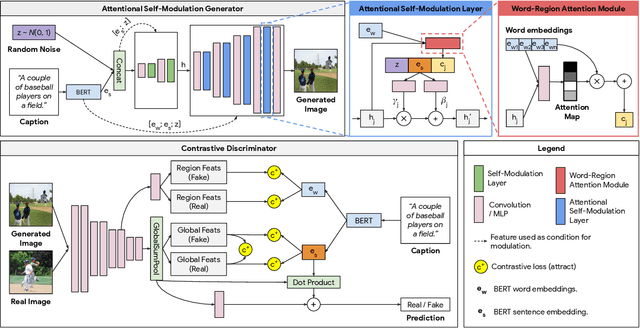
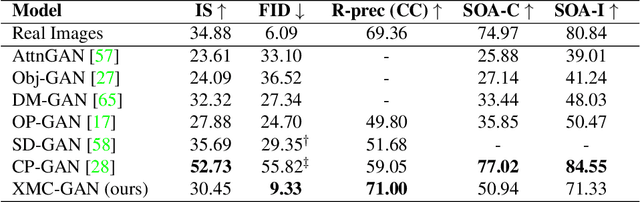
The output of text-to-image synthesis systems should be coherent, clear, photo-realistic scenes with high semantic fidelity to their conditioned text descriptions. Our Cross-Modal Contrastive Generative Adversarial Network (XMC-GAN) addresses this challenge by maximizing the mutual information between image and text. It does this via multiple contrastive losses which capture inter-modality and intra-modality correspondences. XMC-GAN uses an attentional self-modulation generator, which enforces strong text-image correspondence, and a contrastive discriminator, which acts as a critic as well as a feature encoder for contrastive learning. The quality of XMC-GAN's output is a major step up from previous models, as we show on three challenging datasets. On MS-COCO, not only does XMC-GAN improve state-of-the-art FID from 24.70 to 9.33, but--more importantly--people prefer XMC-GAN by 77.3 for image quality and 74.1 for image-text alignment, compared to three other recent models. XMC-GAN also generalizes to the challenging Localized Narratives dataset (which has longer, more detailed descriptions), improving state-of-the-art FID from 48.70 to 14.12. Lastly, we train and evaluate XMC-GAN on the challenging Open Images data, establishing a strong benchmark FID score of 26.91.
Do You See What I See? Coordinating Multiple Aerial Cameras for Robot Cinematography
Nov 10, 2020
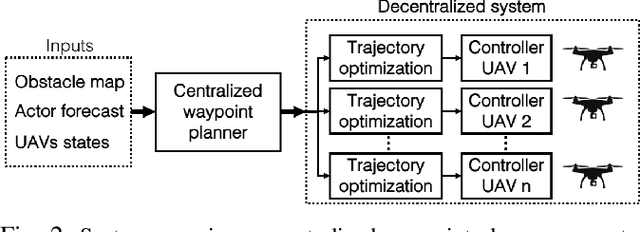
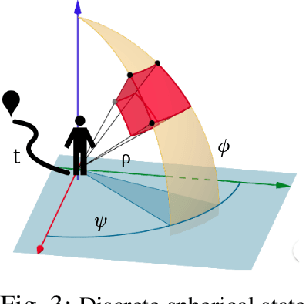

Aerial cinematography is significantly expanding the capabilities of film-makers. Recent progress in autonomous unmanned aerial vehicles (UAVs) has further increased the potential impact of aerial cameras, with systems that can safely track actors in unstructured cluttered environments. Professional productions, however, require the use of multiple cameras simultaneously to record different viewpoints of the same scene, which are edited into the final footage either in real time or in post-production. Such extreme motion coordination is particularly hard for unscripted action scenes, which are a common use case of aerial cameras. In this work we develop a real-time multi-UAV coordination system that is capable of recording dynamic targets while maximizing shot diversity and avoiding collisions and mutual visibility between cameras. We validate our approach in multiple cluttered environments of a photo-realistic simulator, and deploy the system using two UAVs in real-world experiments. We show that our coordination scheme has low computational cost and takes only 1.17 ms on average to plan for a team of 3 UAVs over a 10 s time horizon. Supplementary video: https://youtu.be/m2R3anv2ADE