 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Individual common dolphin identification via metric embedding learning
Jan 09, 2019

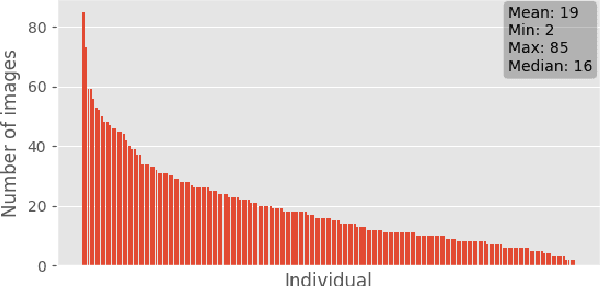
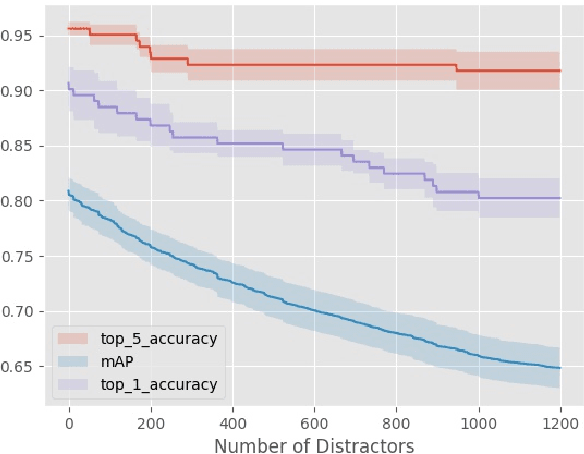
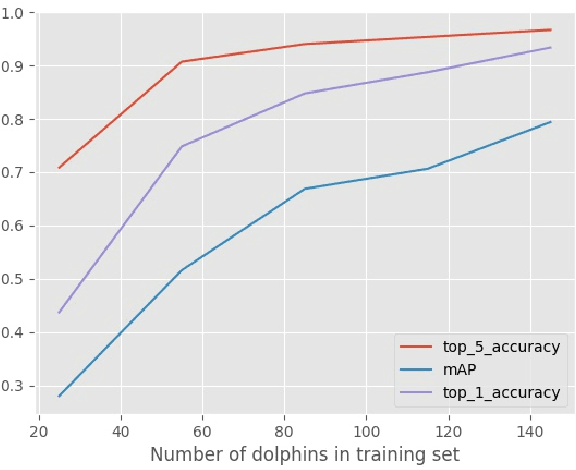
Photo-identification (photo-id) of dolphin individuals is a commonly used technique in ecological sciences to monitor state and health of individuals, as well as to study the social structure and distribution of a population. Traditional photo-id involves a laborious manual process of matching each dolphin fin photograph captured in the field to a catalogue of known individuals. We examine this problem in the context of open-set recognition and utilise a triplet loss function to learn a compact representation of fin images in a Euclidean embedding, where the Euclidean distance metric represents fin similarity. We show that this compact representation can be successfully learnt from a fairly small (in deep learning context) training set and still generalise well to out-of-sample identities (completely new dolphin individuals), with top-1 and top-5 test set (37 individuals) accuracy of $90.5\pm2$ and $93.6\pm1$ percent. In the presence of 1200 distractors, top-1 accuracy dropped by $12\%$; however, top-5 accuracy saw only a $2.8\%$ drop
Deep Photo Style Transfer
Apr 11, 2017

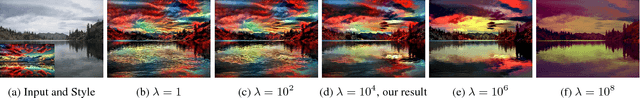

This paper introduces a deep-learning approach to photographic style transfer that handles a large variety of image content while faithfully transferring the reference style. Our approach builds upon the recent work on painterly transfer that separates style from the content of an image by considering different layers of a neural network. However, as is, this approach is not suitable for photorealistic style transfer. Even when both the input and reference images are photographs, the output still exhibits distortions reminiscent of a painting. Our contribution is to constrain the transformation from the input to the output to be locally affine in colorspace, and to express this constraint as a custom fully differentiable energy term. We show that this approach successfully suppresses distortion and yields satisfying photorealistic style transfers in a broad variety of scenarios, including transfer of the time of day, weather, season, and artistic edits.
Text to Image Generation with Semantic-Spatial Aware GAN
Apr 14, 2021
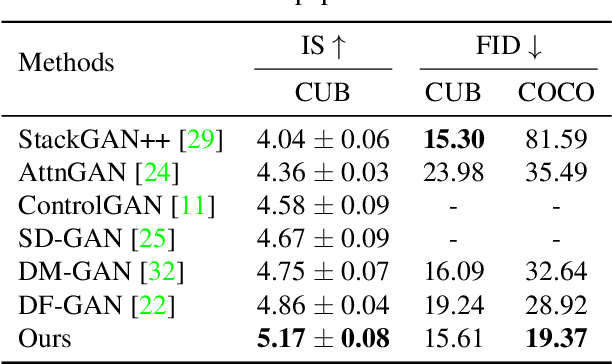


A text to image generation (T2I) model aims to generate photo-realistic images which are semantically consistent with the text descriptions. Built upon the recent advances in generative adversarial networks (GANs), existing T2I models have made great progress. However, a close inspection of their generated images reveals two major limitations: (1) The condition batch normalization methods are applied on the whole image feature maps equally, ignoring the local semantics; (2) The text encoder is fixed during training, which should be trained with the image generator jointly to learn better text representations for image generation. To address these limitations, we propose a novel framework Semantic-Spatial Aware GAN, which is trained in an end-to-end fashion so that the text encoder can exploit better text information. Concretely, we introduce a novel Semantic-Spatial Aware Convolution Network, which (1) learns semantic-adaptive transformation conditioned on text to effectively fuse text features and image features, and (2) learns a mask map in a weakly-supervised way that depends on the current text-image fusion process in order to guide the transformation spatially. Experiments on the challenging COCO and CUB bird datasets demonstrate the advantage of our method over the recent state-of-the-art approaches, regarding both visual fidelity and alignment with input text description. Code is available at https://github.com/wtliao/text2image.
Deep Factorised Inverse-Sketching
Aug 07, 2018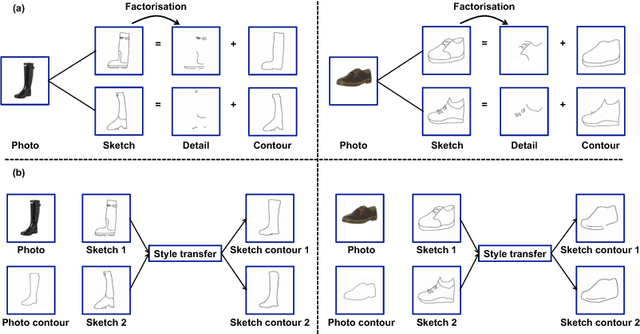
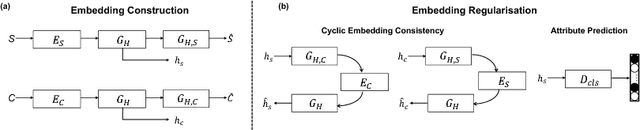
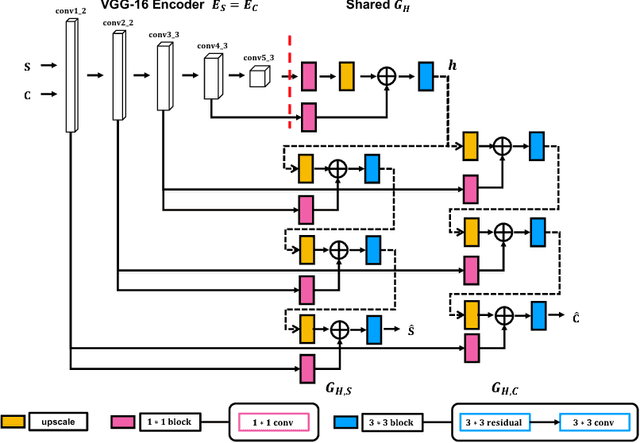
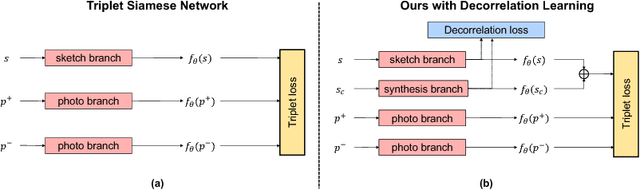
Modelling human free-hand sketches has become topical recently, driven by practical applications such as fine-grained sketch based image retrieval (FG-SBIR). Sketches are clearly related to photo edge-maps, but a human free-hand sketch of a photo is not simply a clean rendering of that photo's edge map. Instead there is a fundamental process of abstraction and iconic rendering, where overall geometry is warped and salient details are selectively included. In this paper we study this sketching process and attempt to invert it. We model this inversion by translating iconic free-hand sketches to contours that resemble more geometrically realistic projections of object boundaries, and separately factorise out the salient added details. This factorised re-representation makes it easier to match a free-hand sketch to a photo instance of an object. Specifically, we propose a novel unsupervised image style transfer model based on enforcing a cyclic embedding consistency constraint. A deep FG-SBIR model is then formulated to accommodate complementary discriminative detail from each factorised sketch for better matching with the corresponding photo. Our method is evaluated both qualitatively and quantitatively to demonstrate its superiority over a number of state-of-the-art alternatives for style transfer and FG-SBIR.
C2CL: Contact to Contactless Fingerprint Matching
Apr 08, 2021
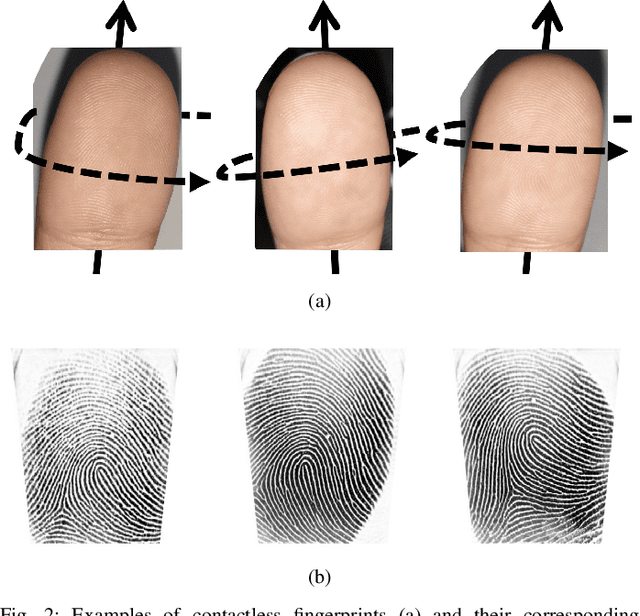
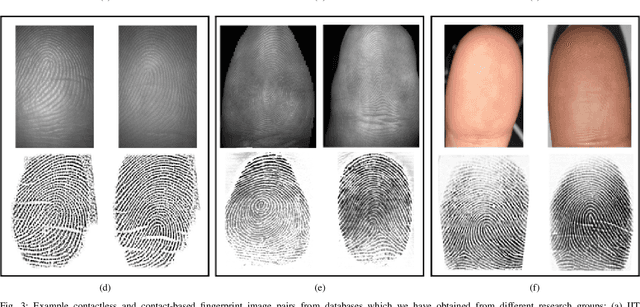
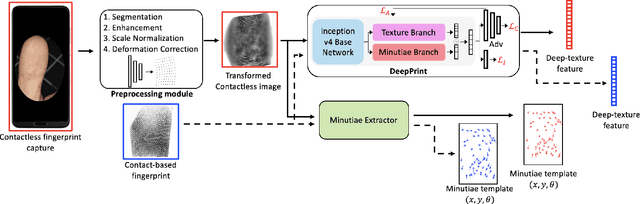
Matching contactless fingerprints or finger photos to contact-based fingerprint impressions has received increased attention in the wake of COVID-19 due to the superior hygiene of the contactless acquisition and the widespread availability of low cost mobile phones capable of capturing photos of fingerprints with sufficient resolution for verification purposes. This paper presents an end-to-end automated system, called C2CL, comprised of a mobile finger photo capture app, preprocessing, and matching algorithms to handle the challenges inhibiting previous cross-matching methods; namely i) low ridge-valley contrast of contactless fingerprints, ii) varying roll, pitch, yaw, and distance of the finger to the camera, iii) non-linear distortion of contact-based fingerprints, and vi) different image qualities of smartphone cameras. Our preprocessing algorithm segments, enhances, scales, and unwarps contactless fingerprints, while our matching algorithm extracts both minutiae and texture representations. A sequestered dataset of 9,888 contactless 2D fingerprints and corresponding contact-based fingerprints from 206 subjects (2 thumbs and 2 index fingers for each subject) acquired using our mobile capture app is used to evaluate the cross-database performance of our proposed algorithm. Furthermore, additional experimental results on 3 publicly available datasets demonstrate, for the first time, contact to contactless fingerprint matching accuracy that is comparable to existing contact to contact fingerprint matching systems (TAR in the range of 96.67% to 98.15% at FAR=0.01%).
Enabling Robots to Draw and Tell: Towards Visually Grounded Multimodal Description Generation
Jan 14, 2021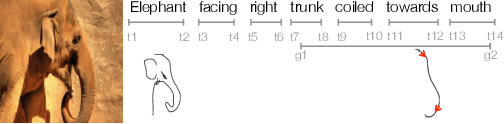
Socially competent robots should be equipped with the ability to perceive the world that surrounds them and communicate about it in a human-like manner. Representative skills that exhibit such ability include generating image descriptions and visually grounded referring expressions. In the NLG community, these generation tasks are largely investigated in non-interactive and language-only settings. However, in face-to-face interaction, humans often deploy multiple modalities to communicate, forming seamless integration of natural language, hand gestures and other modalities like sketches. To enable robots to describe what they perceive with speech and sketches/gestures, we propose to model the task of generating natural language together with free-hand sketches/hand gestures to describe visual scenes and real life objects, namely, visually-grounded multimodal description generation. In this paper, we discuss the challenges and evaluation metrics of the task, and how the task can benefit from progress recently made in the natural language processing and computer vision realms, where related topics such as visually grounded NLG, distributional semantics, and photo-based sketch generation have been extensively studied.
Beyond Photo Realism for Domain Adaptation from Synthetic Data
Sep 04, 2019
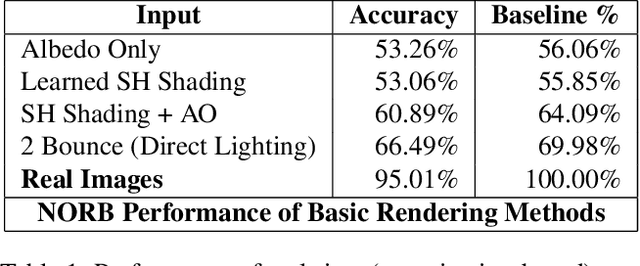
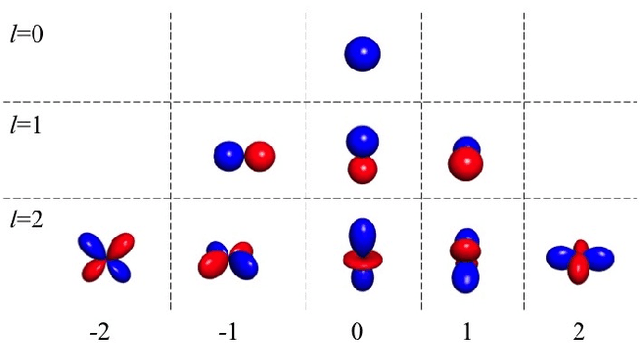
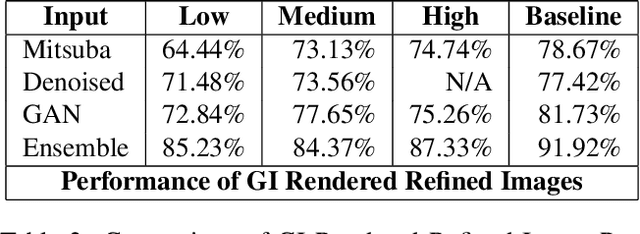
As synthetic imagery is used more frequently in training deep models, it is important to understand how different synthesis techniques impact the performance of such models. In this work, we perform a thorough evaluation of the effectiveness of several different synthesis techniques and their impact on the complexity of classifier domain adaptation to the "real" underlying data distribution that they seek to replicate. In addition, we propose a novel learned synthesis technique to better train classifier models than state-of-the-art offline graphical methods, while using significantly less computational resources. We accomplish this by learning a generative model to perform shading of synthetic geometry conditioned on a "g-buffer" representation of the scene to render, as well as a low sample Monte Carlo rendered image. The major contributions are (i) a dataset that allows comparison of real and synthetic versions of the same scene, (ii) an augmented data representation that boosts the stability of learning and improves the datasets accuracy, (iii) three different partially differentiable rendering techniques where lighting, denoising and shading are learned, and (iv) we improve a state of the art generative adversarial network (GAN) approach by using an ensemble of trained models to generate datasets that approach the performance of training on real data and surpass the performance of the full global illumination rendering.
Normalized Avatar Synthesis Using StyleGAN and Perceptual Refinement
Jun 21, 2021


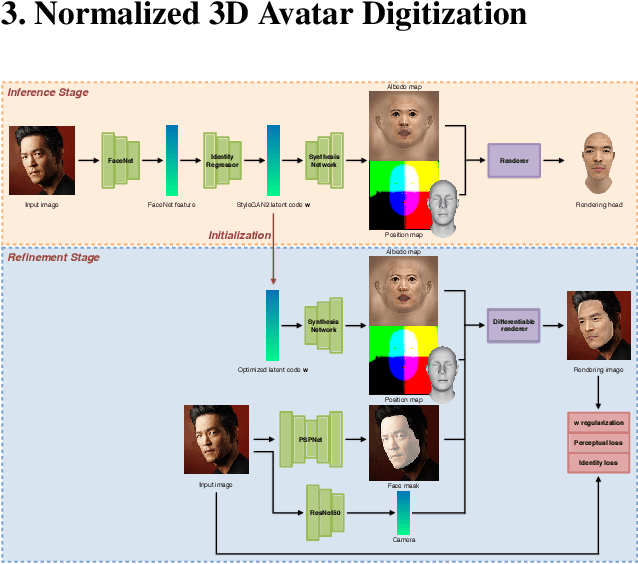
We introduce a highly robust GAN-based framework for digitizing a normalized 3D avatar of a person from a single unconstrained photo. While the input image can be of a smiling person or taken in extreme lighting conditions, our method can reliably produce a high-quality textured model of a person's face in neutral expression and skin textures under diffuse lighting condition. Cutting-edge 3D face reconstruction methods use non-linear morphable face models combined with GAN-based decoders to capture the likeness and details of a person but fail to produce neutral head models with unshaded albedo textures which is critical for creating relightable and animation-friendly avatars for integration in virtual environments. The key challenges for existing methods to work is the lack of training and ground truth data containing normalized 3D faces. We propose a two-stage approach to address this problem. First, we adopt a highly robust normalized 3D face generator by embedding a non-linear morphable face model into a StyleGAN2 network. This allows us to generate detailed but normalized facial assets. This inference is then followed by a perceptual refinement step that uses the generated assets as regularization to cope with the limited available training samples of normalized faces. We further introduce a Normalized Face Dataset, which consists of a combination photogrammetry scans, carefully selected photographs, and generated fake people with neutral expressions in diffuse lighting conditions. While our prepared dataset contains two orders of magnitude less subjects than cutting edge GAN-based 3D facial reconstruction methods, we show that it is possible to produce high-quality normalized face models for very challenging unconstrained input images, and demonstrate superior performance to the current state-of-the-art.
Photo-Sketching: Inferring Contour Drawings from Images
Jan 02, 2019

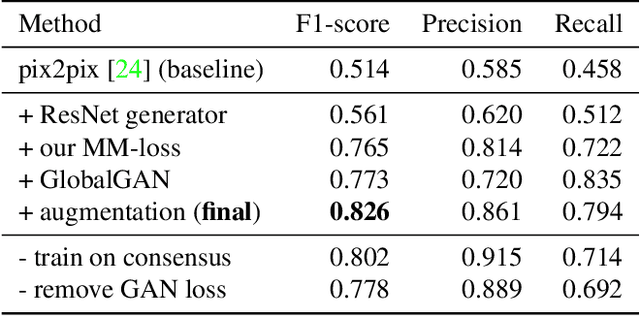

Edges, boundaries and contours are important subjects of study in both computer graphics and computer vision. On one hand, they are the 2D elements that convey 3D shapes, on the other hand, they are indicative of occlusion events and thus separation of objects or semantic concepts. In this paper, we aim to generate contour drawings, boundary-like drawings that capture the outline of the visual scene. Prior art often cast this problem as boundary detection. However, the set of visual cues presented in the boundary detection output are different from the ones in contour drawings, and also the artistic style is ignored. We address these issues by collecting a new dataset of contour drawings and proposing a learning-based method that resolves diversity in the annotation and, unlike boundary detectors, can work with imperfect alignment of the annotation and the actual ground truth. Our method surpasses previous methods quantitatively and qualitatively. Surprisingly, when our model fine-tunes on BSDS500, we achieve the state-of-the-art performance in salient boundary detection, suggesting contour drawing might be a scalable alternative to boundary annotation, which at the same time is easier and more interesting for annotators to draw.
An Image Forensic Technique Based on JPEG Ghosts
Jun 19, 2021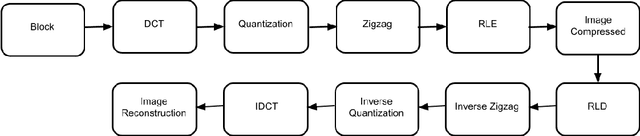
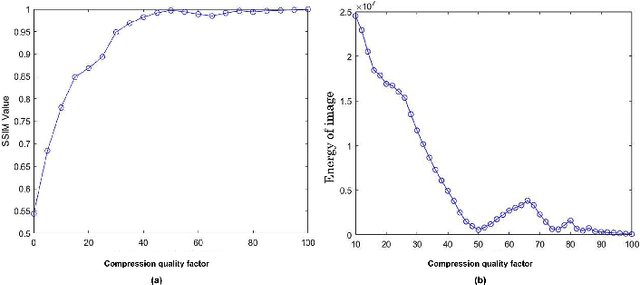


The unprecedented growth in the easy availability of photo-editing tools has endangered the power of digital images.An image was supposed to be worth more than a thousand words,but now this can be said only if it can be authenticated orthe integrity of the image can be proved to be intact. In thispaper, we propose a digital image forensic technique for JPEG images. It can detect any forgery in the image if the forged portion called a ghost image is having a compression quality different from that of the cover image. It is based on resaving the JPEG image at different JPEG qualities, and the detection of the forged portion is maximum when it is saved at the same JPEG quality as the cover image. Also, we can precisely predictthe JPEG quality of the cover image by analyzing the similarity using Structural Similarity Index Measure (SSIM) or the energyof the images. The first maxima in SSIM or the first minima inenergy correspond to the cover image JPEG quality. We created adataset for varying JPEG compression qualities of the ghost and the cover images and validated the scalability of the experimental results.We also, experimented with varied attack scenarios, e.g. high-quality ghost image embedded in low quality of cover image,low-quality ghost image embedded in high-quality of cover image,and ghost image and cover image both at the same quality.The proposed method is able to localize the tampered portions accurately even for forgeries as small as 10x10 sized pixel blocks.Our technique is also robust against other attack scenarios like copy-move forgery, inserting text into image, rescaling (zoom-out/zoom-in) ghost image and then pasting on cover image.