 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation
Apr 22, 2021
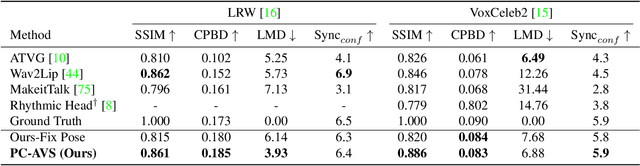
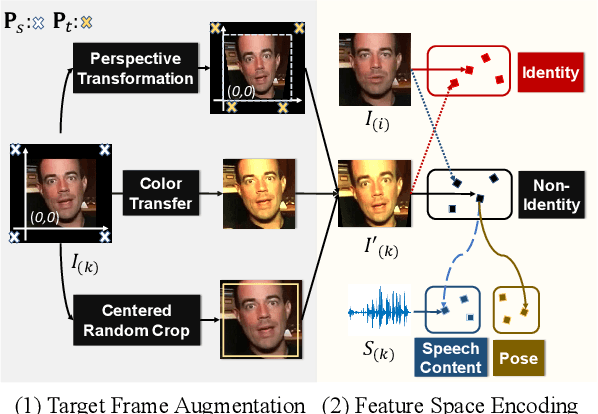

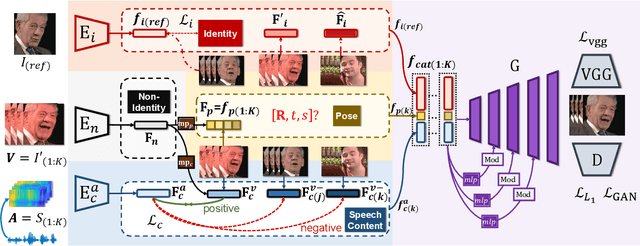
While accurate lip synchronization has been achieved for arbitrary-subject audio-driven talking face generation, the problem of how to efficiently drive the head pose remains. Previous methods rely on pre-estimated structural information such as landmarks and 3D parameters, aiming to generate personalized rhythmic movements. However, the inaccuracy of such estimated information under extreme conditions would lead to degradation problems. In this paper, we propose a clean yet effective framework to generate pose-controllable talking faces. We operate on raw face images, using only a single photo as an identity reference. The key is to modularize audio-visual representations by devising an implicit low-dimension pose code. Substantially, both speech content and head pose information lie in a joint non-identity embedding space. While speech content information can be defined by learning the intrinsic synchronization between audio-visual modalities, we identify that a pose code will be complementarily learned in a modulated convolution-based reconstruction framework. Extensive experiments show that our method generates accurately lip-synced talking faces whose poses are controllable by other videos. Moreover, our model has multiple advanced capabilities including extreme view robustness and talking face frontalization. Code, models, and demo videos are available at https://hangz-nju-cuhk.github.io/projects/PC-AVS.
AniGAN: Style-Guided Generative Adversarial Networks for Unsupervised Anime Face Generation
Feb 24, 2021
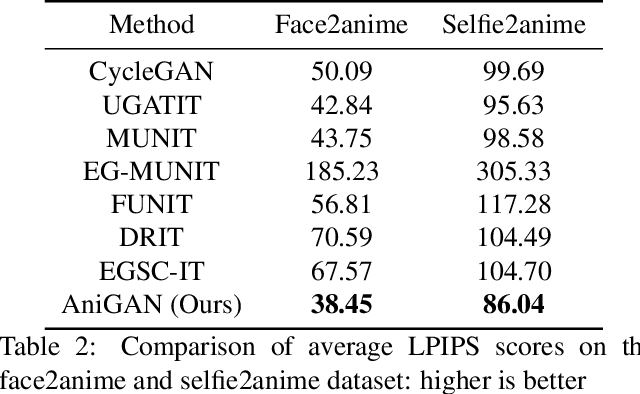
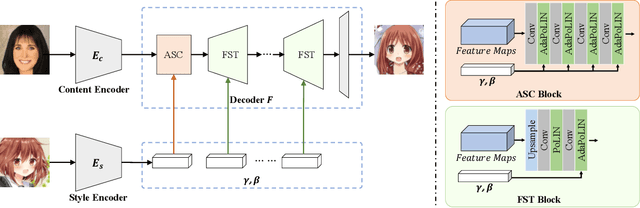
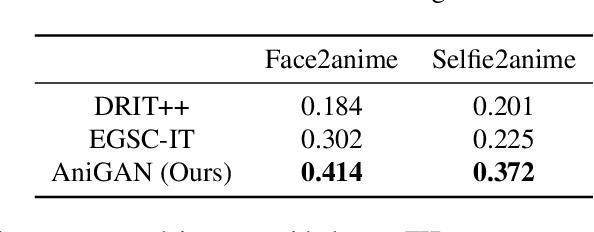
In this paper, we propose a novel framework to translate a portrait photo-face into an anime appearance. Our aim is to synthesize anime-faces which are style-consistent with a given reference anime-face. However, unlike typical translation tasks, such anime-face translation is challenging due to complex variations of appearances among anime-faces. Existing methods often fail to transfer the styles of reference anime-faces, or introduce noticeable artifacts/distortions in the local shapes of their generated faces. We propose Ani- GAN, a novel GAN-based translator that synthesizes highquality anime-faces. Specifically, a new generator architecture is proposed to simultaneously transfer color/texture styles and transform local facial shapes into anime-like counterparts based on the style of a reference anime-face, while preserving the global structure of the source photoface. We propose a double-branch discriminator to learn both domain-specific distributions and domain-shared distributions, helping generate visually pleasing anime-faces and effectively mitigate artifacts. Extensive experiments qualitatively and quantitatively demonstrate the superiority of our method over state-of-the-art methods.
FaceDet3D: Facial Expressions with 3D Geometric Detail Prediction
Dec 14, 2020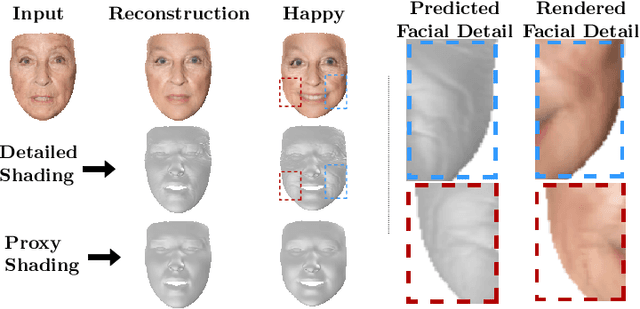

Facial Expressions induce a variety of high-level details on the 3D face geometry. For example, a smile causes the wrinkling of cheeks or the formation of dimples, while being angry often causes wrinkling of the forehead. Morphable Models (3DMMs) of the human face fail to capture such fine details in their PCA-based representations and consequently cannot generate such details when used to edit expressions. In this work, we introduce FaceDet3D, a first-of-its-kind method that generates - from a single image - geometric facial details that are consistent with any desired target expression. The facial details are represented as a vertex displacement map and used then by a Neural Renderer to photo-realistically render novel images of any single image in any desired expression and view. The Project website is: http://shahrukhathar.github.io/2020/12/14/FaceDet3D.html
The UU-Net: Reversible Face De-Identification for Visual Surveillance Video Footage
Jul 08, 2020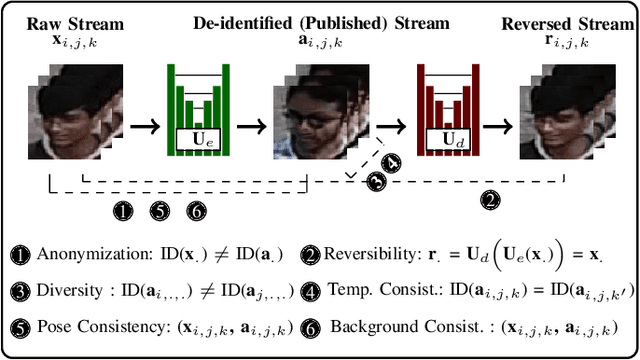

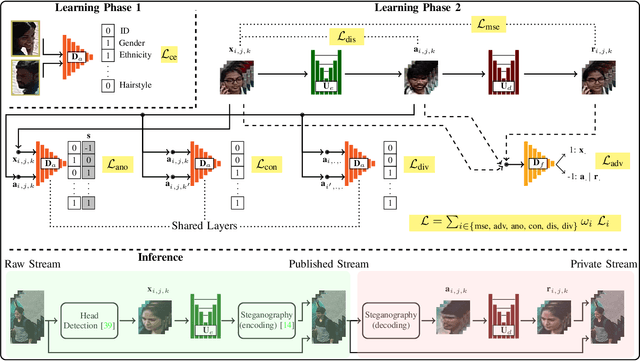

We propose a reversible face de-identification method for low resolution video data, where landmark-based techniques cannot be reliably used. Our solution is able to generate a photo realistic de-identified stream that meets the data protection regulations and can be publicly released under minimal privacy constraints. Notably, such stream encapsulates all the information required to later reconstruct the original scene, which is useful for scenarios, such as crime investigation, where the identification of the subjects is of most importance. We describe a learning process that jointly optimizes two main components: 1) a public module, that receives the raw data and generates the de-identified stream, where the ID information is surrogated in a photo-realistic and seamless way; and 2) a private module, designed for legal/security authorities, that analyses the public stream and reconstructs the original scene, disclosing the actual IDs of all the subjects in the scene. The proposed solution is landmarks-free and uses a conditional generative adversarial network to generate synthetic faces that preserve pose, lighting, background information and even facial expressions. Also, we enable full control over the set of soft facial attributes that should be preserved between the raw and de-identified data, which broads the range of applications for this solution. Our experiments were conducted in three different visual surveillance datasets (BIODI, MARS and P-DESTRE) and showed highly encouraging results. The source code is available at https://github.com/hugomcp/uu-net.
Generative Modelling of BRDF Textures from Flash Images
Feb 23, 2021
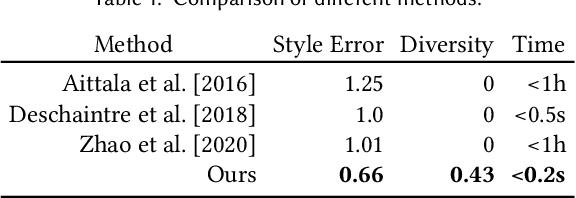
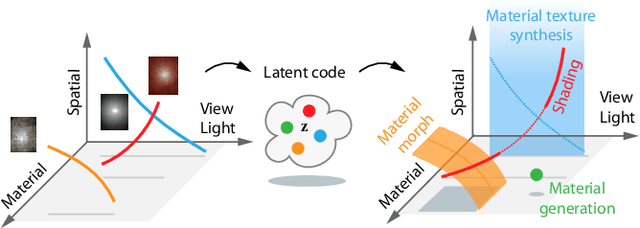
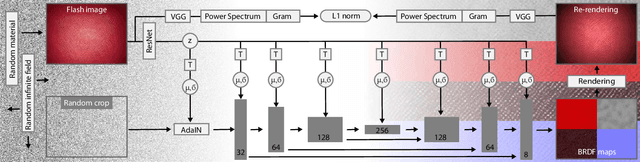
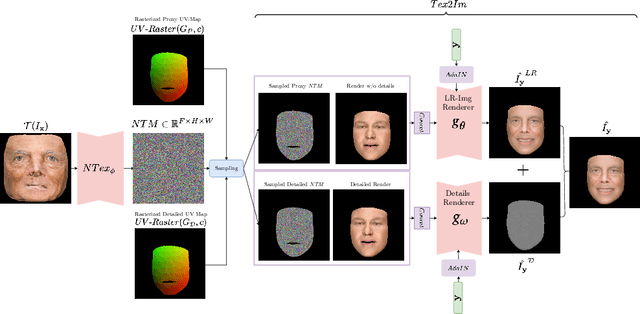
We learn a latent space for easy capture, semantic editing, consistent interpolation, and efficient reproduction of visual material appearance. When users provide a photo of a stationary natural material captured under flash light illumination, it is converted in milliseconds into a latent material code. In a second step, conditioned on the material code, our method, again in milliseconds, produces an infinite and diverse spatial field of BRDF model parameters (diffuse albedo, specular albedo, roughness, normals) that allows rendering in complex scenes and illuminations, matching the appearance of the input picture. Technically, we jointly embed all flash images into a latent space using a convolutional encoder, and -- conditioned on these latent codes -- convert random spatial fields into fields of BRDF parameters using a convolutional neural network (CNN). We condition these BRDF parameters to match the visual characteristics (statistics and spectra of visual features) of the input under matching light. A user study confirms that the semantics of the latent material space agree with user expectations and compares our approach favorably to previous work.
GAN Prior Embedded Network for Blind Face Restoration in the Wild
May 13, 2021
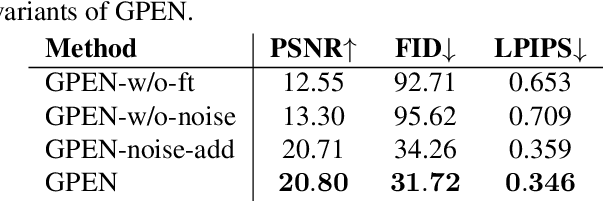
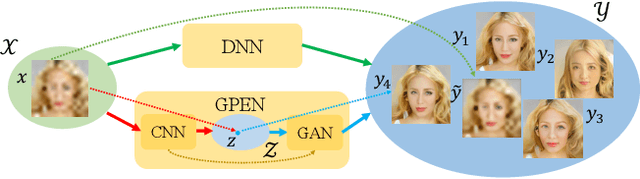
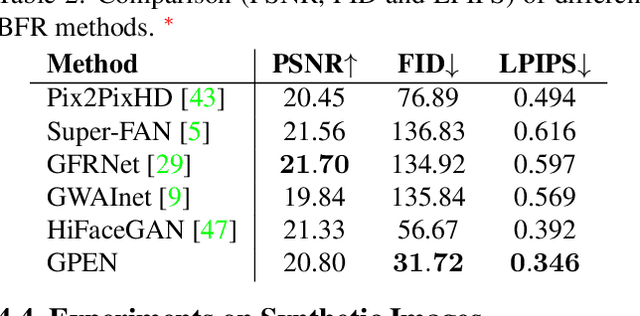
Blind face restoration (BFR) from severely degraded face images in the wild is a very challenging problem. Due to the high illness of the problem and the complex unknown degradation, directly training a deep neural network (DNN) usually cannot lead to acceptable results. Existing generative adversarial network (GAN) based methods can produce better results but tend to generate over-smoothed restorations. In this work, we propose a new method by first learning a GAN for high-quality face image generation and embedding it into a U-shaped DNN as a prior decoder, then fine-tuning the GAN prior embedded DNN with a set of synthesized low-quality face images. The GAN blocks are designed to ensure that the latent code and noise input to the GAN can be respectively generated from the deep and shallow features of the DNN, controlling the global face structure, local face details and background of the reconstructed image. The proposed GAN prior embedded network (GPEN) is easy-to-implement, and it can generate visually photo-realistic results. Our experiments demonstrated that the proposed GPEN achieves significantly superior results to state-of-the-art BFR methods both quantitatively and qualitatively, especially for the restoration of severely degraded face images in the wild. The source code and models can be found at https://github.com/yangxy/GPEN.
Label Geometry Aware Discriminator for Conditional Generative Networks
May 12, 2021
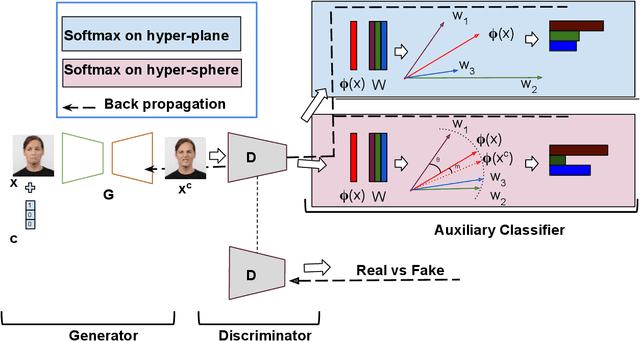
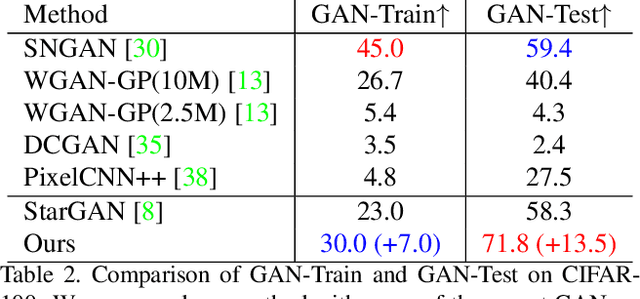
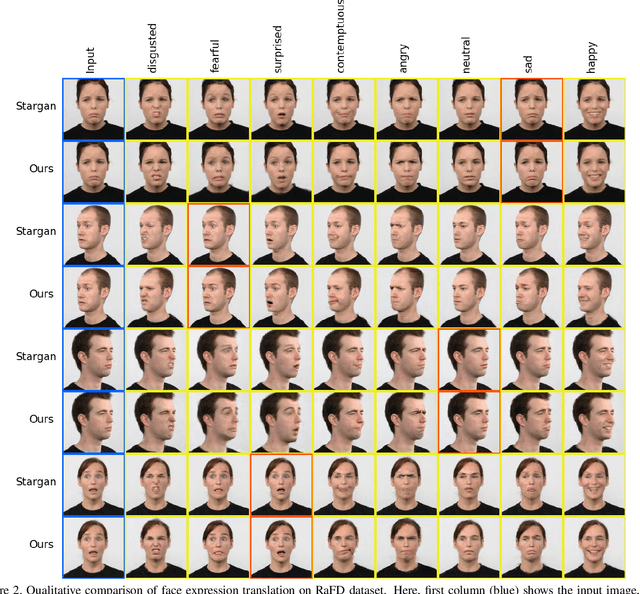
Multi-domain image-to-image translation with conditional Generative Adversarial Networks (GANs) can generate highly photo realistic images with desired target classes, yet these synthetic images have not always been helpful to improve downstream supervised tasks such as image classification. Improving downstream tasks with synthetic examples requires generating images with high fidelity to the unknown conditional distribution of the target class, which many labeled conditional GANs attempt to achieve by adding soft-max cross-entropy loss based auxiliary classifier in the discriminator. As recent studies suggest that the soft-max loss in Euclidean space of deep feature does not leverage their intrinsic angular distribution, we propose to replace this loss in auxiliary classifier with an additive angular margin (AAM) loss that takes benefit of the intrinsic angular distribution, and promotes intra-class compactness and inter-class separation to help generator synthesize high fidelity images. We validate our method on RaFD and CIFAR-100, two challenging face expression and natural image classification data set. Our method outperforms state-of-the-art methods in several different evaluation criteria including recently proposed GAN-train and GAN-test metrics designed to assess the impact of synthetic data on downstream classification task, assessing the usefulness in data augmentation for supervised tasks with prediction accuracy score and average confidence score, and the well known FID metric.
BIM Hyperreality: Data Synthesis Using BIM and Hyperrealistic Rendering for Deep Learning
May 10, 2021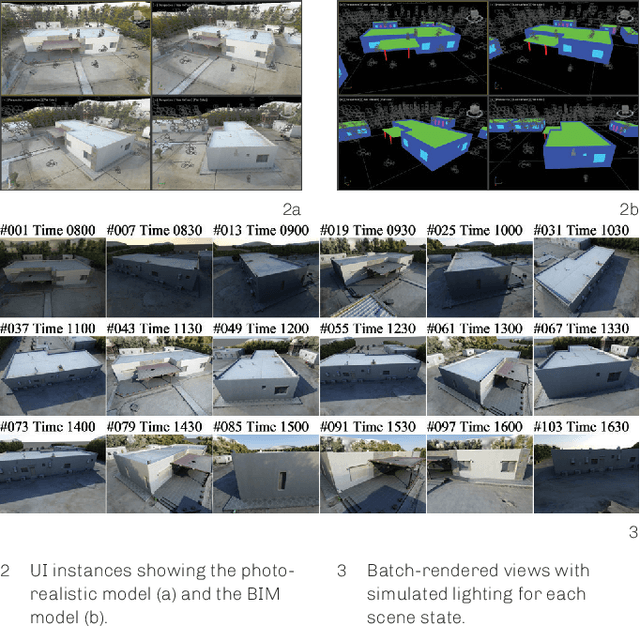
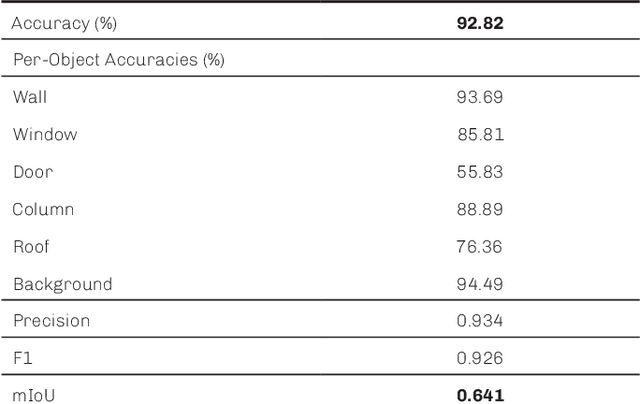

Deep learning is expected to offer new opportunities and a new paradigm for the field of architecture. One such opportunity is teaching neural networks to visually understand architectural elements from the built environment. However, the availability of large training datasets is one of the biggest limitations of neural networks. Also, the vast majority of training data for visual recognition tasks is annotated by humans. In order to resolve this bottleneck, we present a concept of a hybrid system using both building information modeling (BIM) and hyperrealistic (photorealistic) rendering to synthesize datasets for training a neural network for building object recognition in photos. For generating our training dataset BIMrAI, we used an existing BIM model and a corresponding photo-realistically rendered model of the same building. We created methods for using renderings to train a deep learning model, trained a generative adversarial network (GAN) model using these methods, and tested the output model on real-world photos. For the specific case study presented in this paper, our results show that a neural network trained with synthetic data; i.e., photorealistic renderings and BIM-based semantic labels, can be used to identify building objects from photos without using photos in the training data. Future work can enhance the presented methods using available BIM models and renderings for more generalized mapping and description of photographed built environments.
Write-a-speaker: Text-based Emotional and Rhythmic Talking-head Generation
Apr 16, 2021
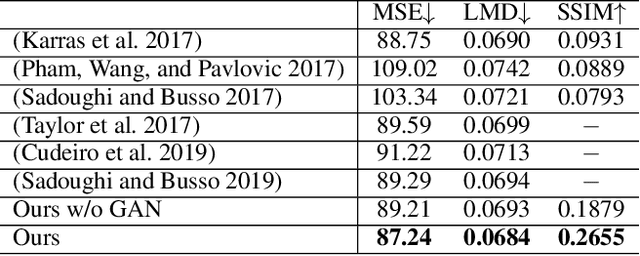
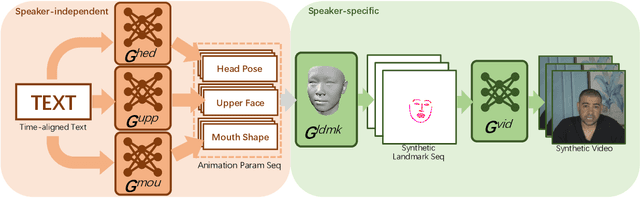
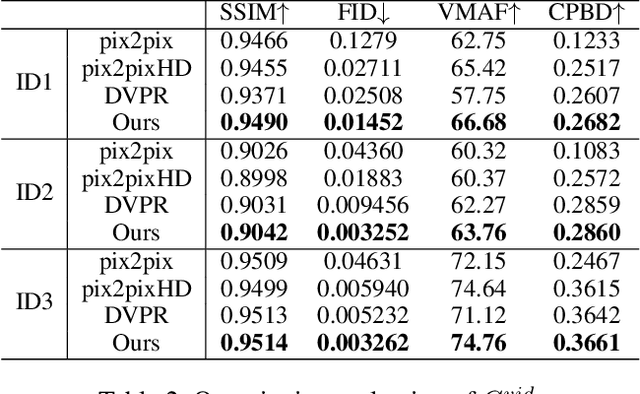
In this paper, we propose a novel text-based talking-head video generation framework that synthesizes high-fidelity facial expressions and head motions in accordance with contextual sentiments as well as speech rhythm and pauses. To be specific, our framework consists of a speaker-independent stage and a speaker-specific stage. In the speaker-independent stage, we design three parallel networks to generate animation parameters of the mouth, upper face, and head from texts, separately. In the speaker-specific stage, we present a 3D face model guided attention network to synthesize videos tailored for different individuals. It takes the animation parameters as input and exploits an attention mask to manipulate facial expression changes for the input individuals. Furthermore, to better establish authentic correspondences between visual motions (i.e., facial expression changes and head movements) and audios, we leverage a high-accuracy motion capture dataset instead of relying on long videos of specific individuals. After attaining the visual and audio correspondences, we can effectively train our network in an end-to-end fashion. Extensive experiments on qualitative and quantitative results demonstrate that our algorithm achieves high-quality photo-realistic talking-head videos including various facial expressions and head motions according to speech rhythms and outperforms the state-of-the-art.
DSRN: an Efficient Deep Network for Image Relighting
Feb 18, 2021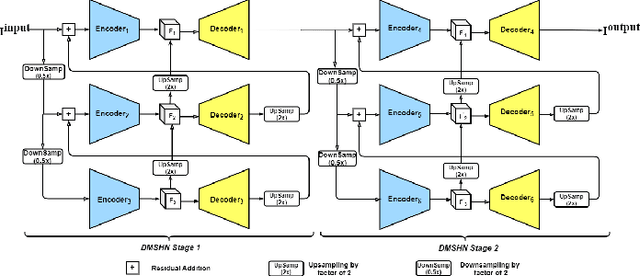
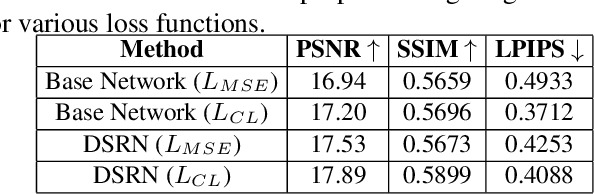
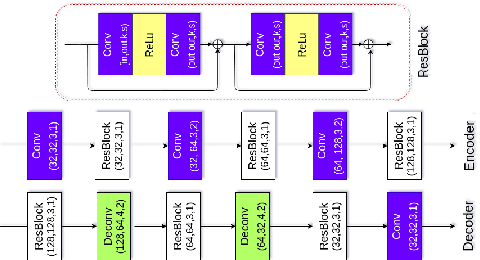
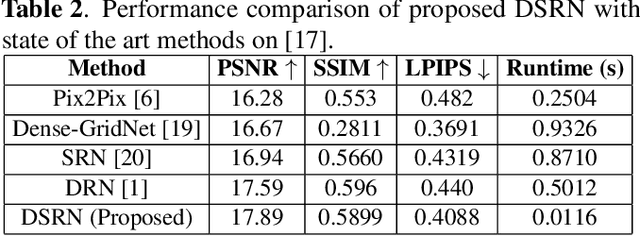
Custom and natural lighting conditions can be emulated in images of the scene during post-editing. Extraordinary capabilities of the deep learning framework can be utilized for such purpose. Deep image relighting allows automatic photo enhancement by illumination-specific retouching. Most of the state-of-the-art methods for relighting are run-time intensive and memory inefficient. In this paper, we propose an efficient, real-time framework Deep Stacked Relighting Network (DSRN) for image relighting by utilizing the aggregated features from input image at different scales. Our model is very lightweight with total size of about 42 MB and has an average inference time of about 0.0116s for image of resolution $1024 \times 1024$ which is faster as compared to other multi-scale models. Our solution is quite robust for translating image color temperature from input image to target image and also performs moderately for light gradient generation with respect to the target image. Additionally, we show that if images illuminated from opposite directions are used as input, the qualitative results improve over using a single input image.