 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Layout-Guided Novel View Synthesis from a Single Indoor Panorama
Mar 31, 2021
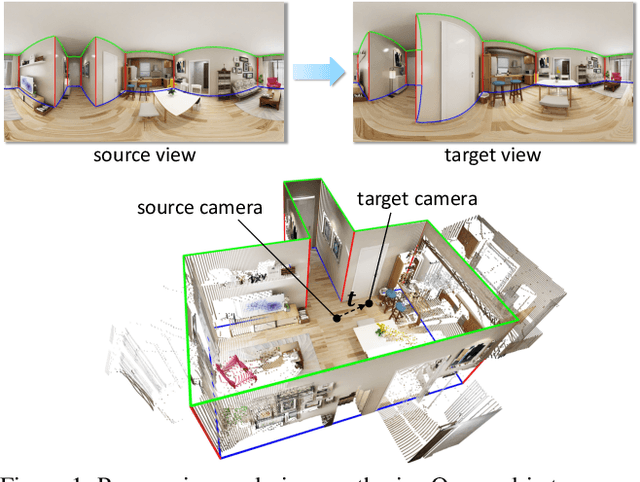
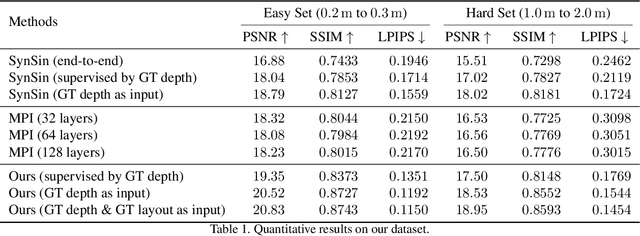
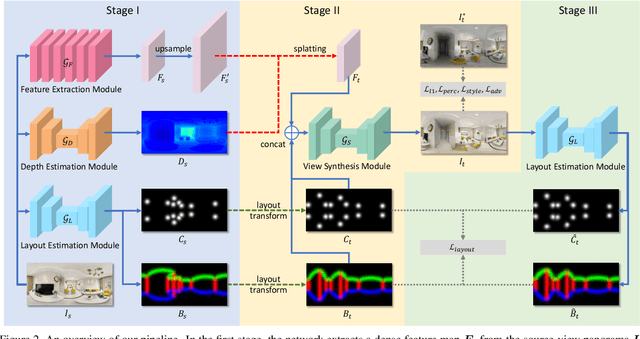
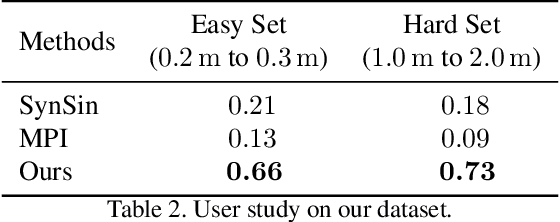
Existing view synthesis methods mainly focus on the perspective images and have shown promising results. However, due to the limited field-of-view of the pinhole camera, the performance quickly degrades when large camera movements are adopted. In this paper, we make the first attempt to generate novel views from a single indoor panorama and take the large camera translations into consideration. To tackle this challenging problem, we first use Convolutional Neural Networks (CNNs) to extract the deep features and estimate the depth map from the source-view image. Then, we leverage the room layout prior, a strong structural constraint of the indoor scene, to guide the generation of target views. More concretely, we estimate the room layout in the source view and transform it into the target viewpoint as guidance. Meanwhile, we also constrain the room layout of the generated target-view images to enforce geometric consistency. To validate the effectiveness of our method, we further build a large-scale photo-realistic dataset containing both small and large camera translations. The experimental results on our challenging dataset demonstrate that our method achieves state-of-the-art performance. The project page is at https://github.com/bluestyle97/PNVS.
FaceDet3D: Facial Expressions with 3D Geometric Detail Prediction
Dec 22, 2020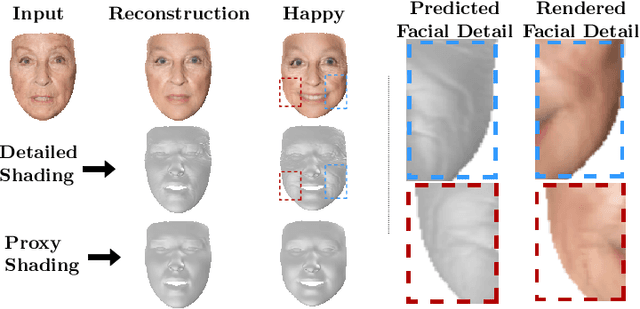
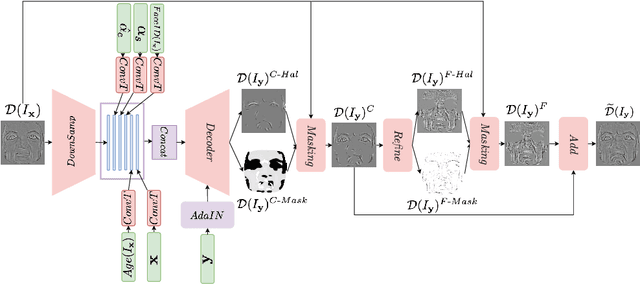
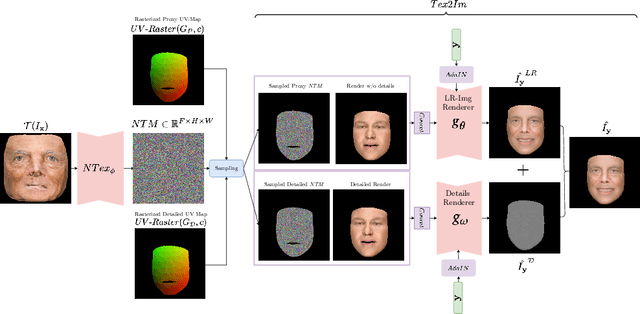

Facial Expressions induce a variety of high-level details on the 3D face geometry. For example, a smile causes the wrinkling of cheeks or the formation of dimples, while being angry often causes wrinkling of the forehead. Morphable Models (3DMMs) of the human face fail to capture such fine details in their PCA-based representations and consequently cannot generate such details when used to edit expressions. In this work, we introduce FaceDet3D, a first-of-its-kind method that generates - from a single image - geometric facial details that are consistent with any desired target expression. The facial details are represented as a vertex displacement map and used then by a Neural Renderer to photo-realistically render novel images of any single image in any desired expression and view. The project website is: http://shahrukhathar.github.io/2020/12/14/FaceDet3D.html
SocNavBench: A Grounded Simulation Testing Framework for Evaluating Social Navigation
Feb 26, 2021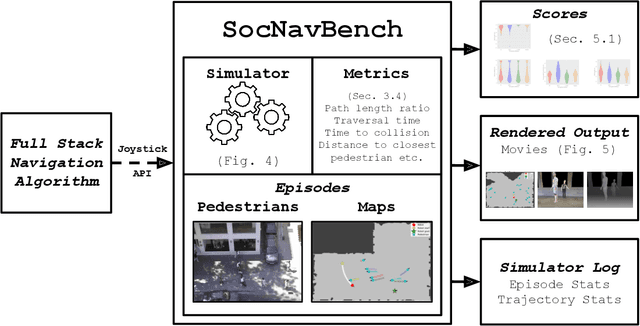
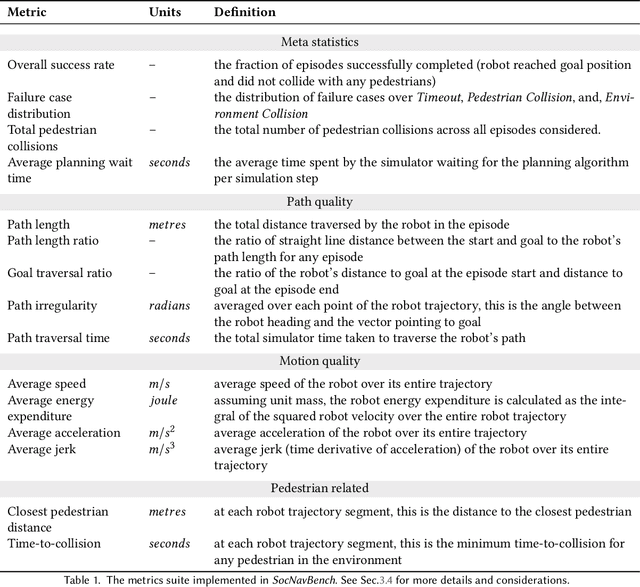

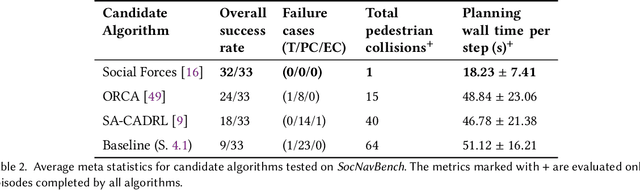
The human-robot interaction (HRI) community has developed many methods for robots to navigate safely and socially alongside humans. However, experimental procedures to evaluate these works are usually constructed on a per-method basis. Such disparate evaluations make it difficult to compare the performance of such methods across the literature. To bridge this gap, we introduce SocNavBench, a simulation framework for evaluating social navigation algorithms. SocNavBench comprises a simulator with photo-realistic capabilities and curated social navigation scenarios grounded in real-world pedestrian data. We also provide an implementation of a suite of metrics to quantify the performance of navigation algorithms on these scenarios. Altogether, SocNavBench provides a test framework for evaluating disparate social navigation methods in a consistent and interpretable manner. To illustrate its use, we demonstrate testing three existing social navigation methods and a baseline method on SocNavBench, showing how the suite of metrics helps infer their performance trade-offs. Our code is open-source, allowing the addition of new scenarios and metrics by the community to help evolve SocNavBench to reflect advancements in our understanding of social navigation.
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation
Apr 22, 2021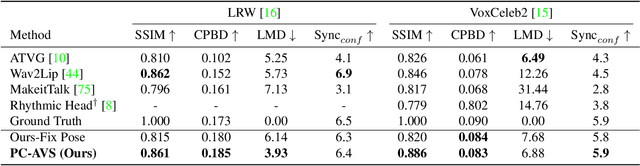
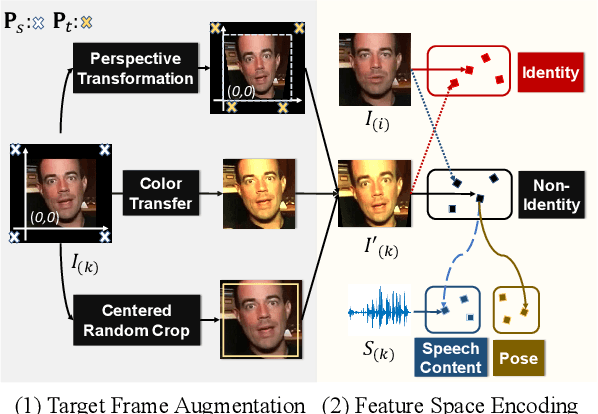

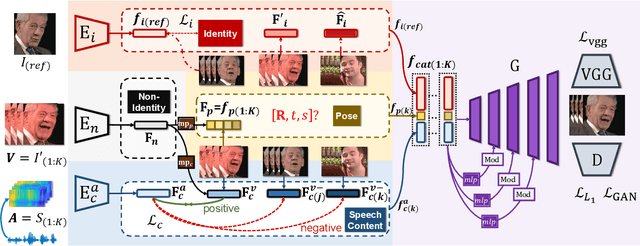
While accurate lip synchronization has been achieved for arbitrary-subject audio-driven talking face generation, the problem of how to efficiently drive the head pose remains. Previous methods rely on pre-estimated structural information such as landmarks and 3D parameters, aiming to generate personalized rhythmic movements. However, the inaccuracy of such estimated information under extreme conditions would lead to degradation problems. In this paper, we propose a clean yet effective framework to generate pose-controllable talking faces. We operate on raw face images, using only a single photo as an identity reference. The key is to modularize audio-visual representations by devising an implicit low-dimension pose code. Substantially, both speech content and head pose information lie in a joint non-identity embedding space. While speech content information can be defined by learning the intrinsic synchronization between audio-visual modalities, we identify that a pose code will be complementarily learned in a modulated convolution-based reconstruction framework. Extensive experiments show that our method generates accurately lip-synced talking faces whose poses are controllable by other videos. Moreover, our model has multiple advanced capabilities including extreme view robustness and talking face frontalization. Code, models, and demo videos are available at https://hangz-nju-cuhk.github.io/projects/PC-AVS.
CCA: Exploring the Possibility of Contextual Camouflage Attack on Object Detection
Aug 19, 2020
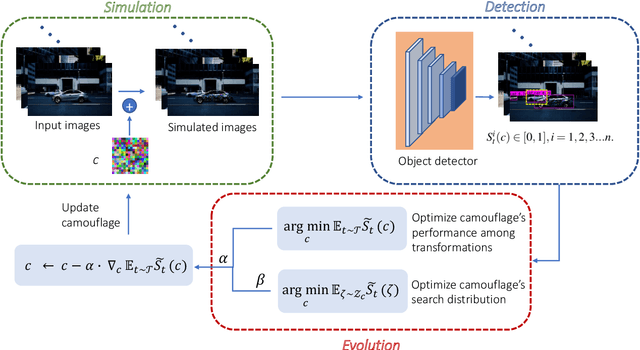
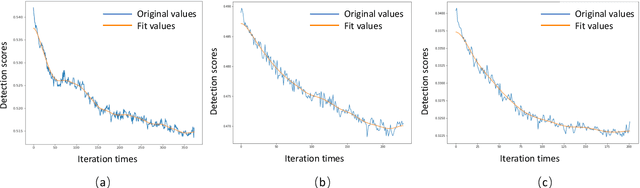
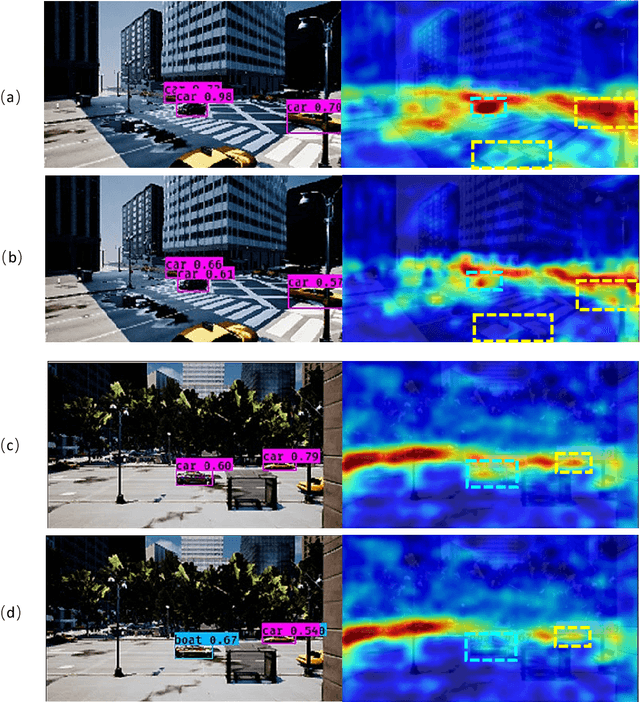
Deep neural network based object detection hasbecome the cornerstone of many real-world applications. Alongwith this success comes concerns about its vulnerability tomalicious attacks. To gain more insight into this issue, we proposea contextual camouflage attack (CCA for short) algorithm to in-fluence the performance of object detectors. In this paper, we usean evolutionary search strategy and adversarial machine learningin interactions with a photo-realistic simulated environment tofind camouflage patterns that are effective over a huge varietyof object locations, camera poses, and lighting conditions. Theproposed camouflages are validated effective to most of the state-of-the-art object detectors.
Category-Based Deep CCA for Fine-Grained Venue Discovery from Multimodal Data
May 08, 2018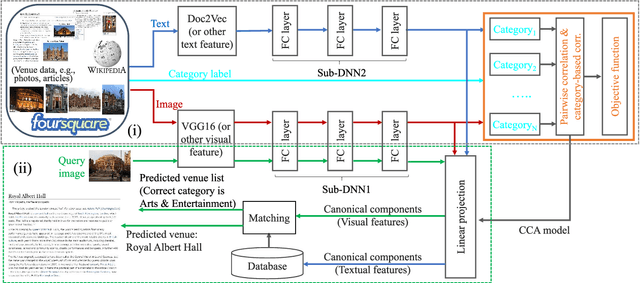
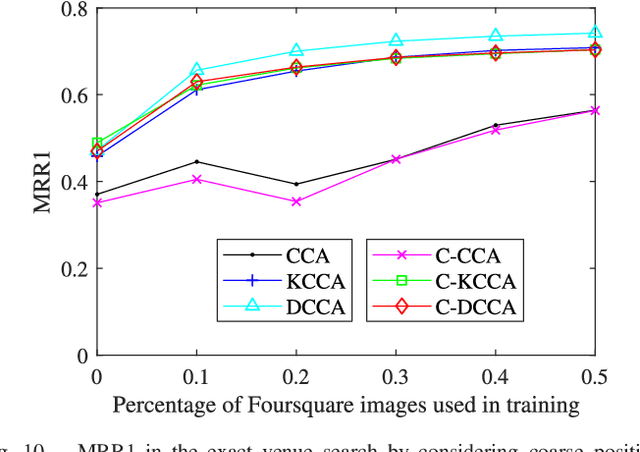
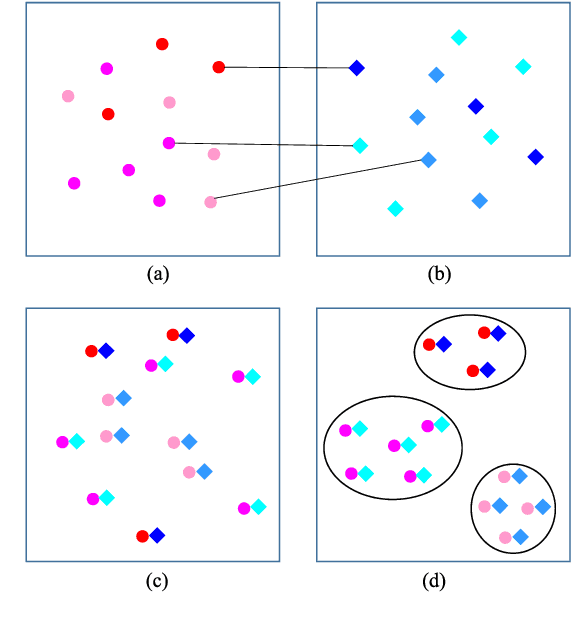
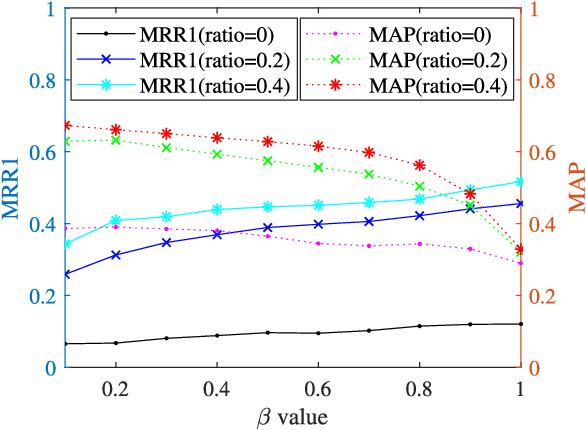
In this work, travel destination and business location are taken as venues. Discovering a venue by a photo is very important for context-aware applications. Unfortunately, few efforts paid attention to complicated real images such as venue photos generated by users. Our goal is fine-grained venue discovery from heterogeneous social multimodal data. To this end, we propose a novel deep learning model, Category-based Deep Canonical Correlation Analysis (C-DCCA). Given a photo as input, this model performs (i) exact venue search (find the venue where the photo was taken), and (ii) group venue search (find relevant venues with the same category as that of the photo), by the cross-modal correlation between the input photo and textual description of venues. In this model, data in different modalities are projected to a same space via deep networks. Pairwise correlation (between different modal data from the same venue) for exact venue search and category-based correlation (between different modal data from different venues with the same category) for group venue search are jointly optimized. Because a photo cannot fully reflect rich text description of a venue, the number of photos per venue in the training phase is increased to capture more aspects of a venue. We build a new venue-aware multimodal dataset by integrating Wikipedia featured articles and Foursquare venue photos. Experimental results on this dataset confirm the feasibility of the proposed method. Moreover, the evaluation over another publicly available dataset confirms that the proposed method outperforms state-of-the-arts for cross-modal retrieval between image and text.
One-Shot Mutual Affine-Transfer for Photorealistic Stylization
Jul 24, 2019

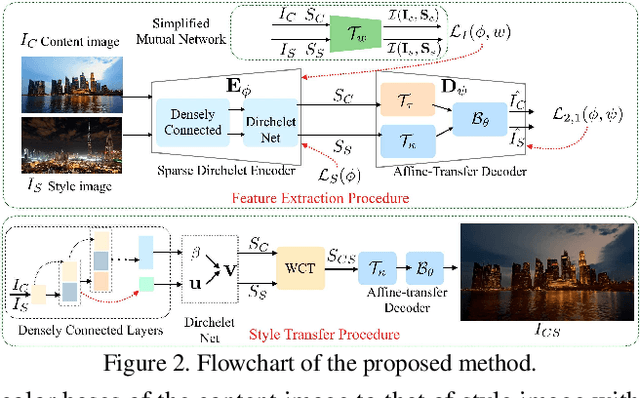
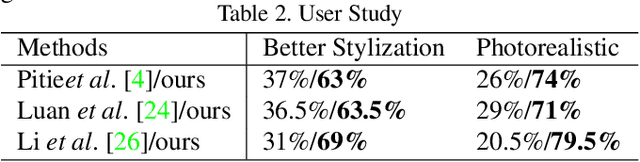
Photorealistic style transfer aims to transfer the style of a reference photo onto a content photo naturally, such that the stylized image looks like a real photo taken by a camera. Existing state-of-the-art methods are prone to spatial structure distortion of the content image and global color inconsistency across different semantic objects, making the results less photorealistic. In this paper, we propose a one-shot mutual Dirichlet network, to address these challenging issues. The essential contribution of the work is the realization of a representation scheme that successfully decouples the spatial structure and color information of images, such that the spatial structure can be well preserved during stylization. This representation is discriminative and context-sensitive with respect to semantic objects. It is extracted with a shared sparse Dirichlet encoder. Moreover, such representation is encouraged to be matched between the content and style images for faithful color transfer. The affine-transfer model is embedded in the decoder of the network to facilitate the color transfer. The strong representative and discriminative power of the proposed network enables one-shot learning given only one content-style image pair. Experimental results demonstrate that the proposed method is able to generate photorealistic photos without spatial distortion or abrupt color changes.
AniGAN: Style-Guided Generative Adversarial Networks for Unsupervised Anime Face Generation
Feb 24, 2021
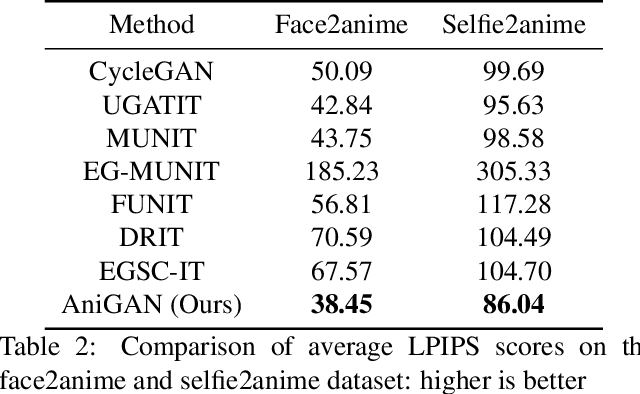
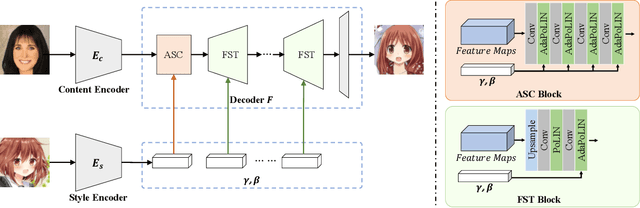
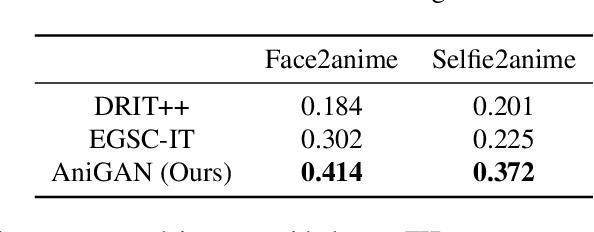
In this paper, we propose a novel framework to translate a portrait photo-face into an anime appearance. Our aim is to synthesize anime-faces which are style-consistent with a given reference anime-face. However, unlike typical translation tasks, such anime-face translation is challenging due to complex variations of appearances among anime-faces. Existing methods often fail to transfer the styles of reference anime-faces, or introduce noticeable artifacts/distortions in the local shapes of their generated faces. We propose Ani- GAN, a novel GAN-based translator that synthesizes highquality anime-faces. Specifically, a new generator architecture is proposed to simultaneously transfer color/texture styles and transform local facial shapes into anime-like counterparts based on the style of a reference anime-face, while preserving the global structure of the source photoface. We propose a double-branch discriminator to learn both domain-specific distributions and domain-shared distributions, helping generate visually pleasing anime-faces and effectively mitigate artifacts. Extensive experiments qualitatively and quantitatively demonstrate the superiority of our method over state-of-the-art methods.
GAN Prior Embedded Network for Blind Face Restoration in the Wild
May 13, 2021
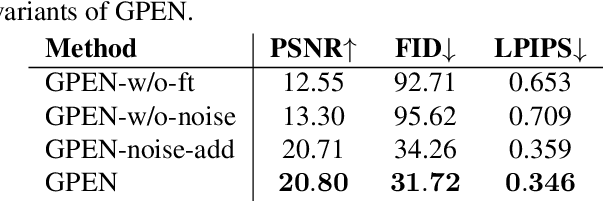
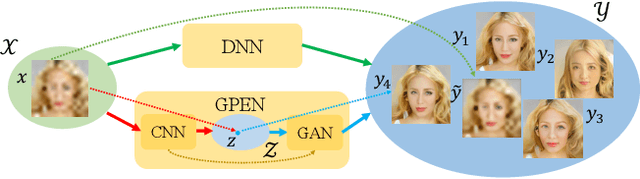
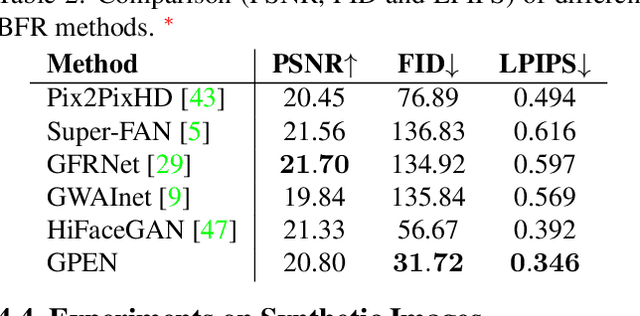
Blind face restoration (BFR) from severely degraded face images in the wild is a very challenging problem. Due to the high illness of the problem and the complex unknown degradation, directly training a deep neural network (DNN) usually cannot lead to acceptable results. Existing generative adversarial network (GAN) based methods can produce better results but tend to generate over-smoothed restorations. In this work, we propose a new method by first learning a GAN for high-quality face image generation and embedding it into a U-shaped DNN as a prior decoder, then fine-tuning the GAN prior embedded DNN with a set of synthesized low-quality face images. The GAN blocks are designed to ensure that the latent code and noise input to the GAN can be respectively generated from the deep and shallow features of the DNN, controlling the global face structure, local face details and background of the reconstructed image. The proposed GAN prior embedded network (GPEN) is easy-to-implement, and it can generate visually photo-realistic results. Our experiments demonstrated that the proposed GPEN achieves significantly superior results to state-of-the-art BFR methods both quantitatively and qualitatively, especially for the restoration of severely degraded face images in the wild. The source code and models can be found at https://github.com/yangxy/GPEN.
Generative Modelling of BRDF Textures from Flash Images
Feb 23, 2021
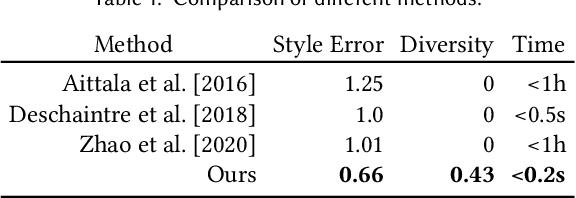
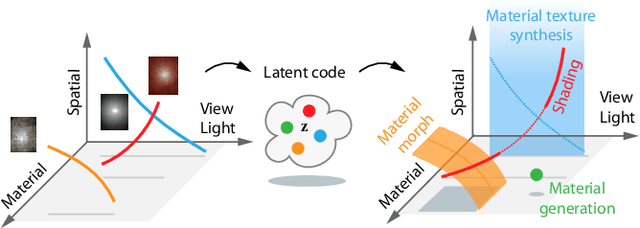
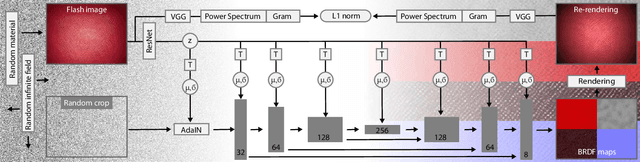
We learn a latent space for easy capture, semantic editing, consistent interpolation, and efficient reproduction of visual material appearance. When users provide a photo of a stationary natural material captured under flash light illumination, it is converted in milliseconds into a latent material code. In a second step, conditioned on the material code, our method, again in milliseconds, produces an infinite and diverse spatial field of BRDF model parameters (diffuse albedo, specular albedo, roughness, normals) that allows rendering in complex scenes and illuminations, matching the appearance of the input picture. Technically, we jointly embed all flash images into a latent space using a convolutional encoder, and -- conditioned on these latent codes -- convert random spatial fields into fields of BRDF parameters using a convolutional neural network (CNN). We condition these BRDF parameters to match the visual characteristics (statistics and spectra of visual features) of the input under matching light. A user study confirms that the semantics of the latent material space agree with user expectations and compares our approach favorably to previous work.