 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Unsupervised Discovery of Disentangled Manifolds in GANs
Nov 29, 2020
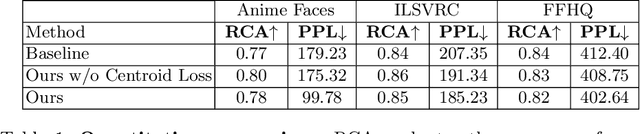
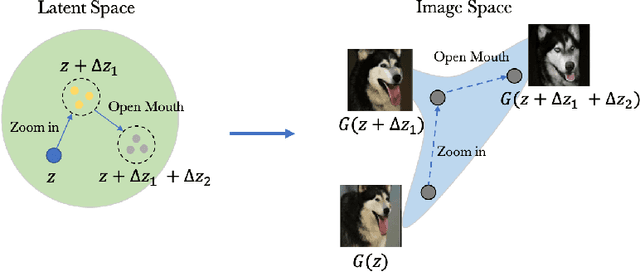
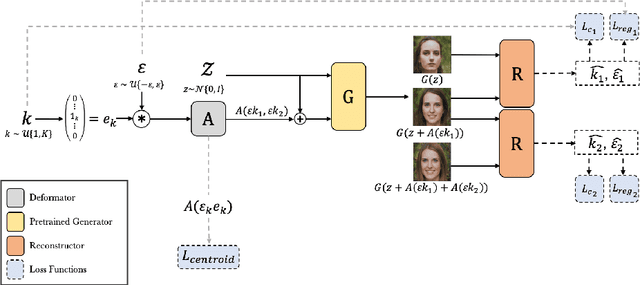

As recent generative models can generate photo-realistic images, people seek to understand the mechanism behind the generation process. Interpretable generation process is beneficial to various image editing applications. In this work, we propose a framework to discover interpretable directions in the latent space given arbitrary pre-trained generative adversarial networks. We propose to learn the transformation from prior one-hot vectors representing different attributes to the latent space used by pre-trained models. Furthermore, we apply a centroid loss function to improve consistency and smoothness while traversing through different directions. We demonstrate the efficacy of the proposed framework on a wide range of datasets. The discovered direction vectors are shown to be visually corresponding to various distinct attributes and thus enable attribute editing.
Resolution Dependant GAN Interpolation for Controllable Image Synthesis Between Domains
Oct 11, 2020
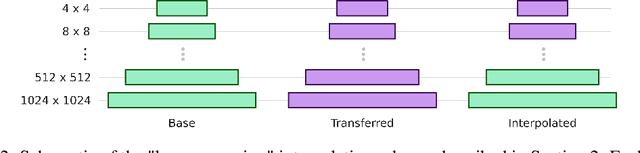


GANs can generate photo-realistic images from the domain of their training data. However, those wanting to use them for creative purposes often want to generate imagery from a truly novel domain, a task which GANs are inherently unable to do. It is also desirable to have a level of control so that there is a degree of artistic direction rather than purely curation of random results. Here we present a method for interpolating between generative models of the StyleGAN architecture in a resolution dependant manner. This allows us to generate images from an entirely novel domain and do this with a degree of control over the nature of the output.
Password-conditioned Anonymization and Deanonymization with Face Identity Transformers
Nov 26, 2019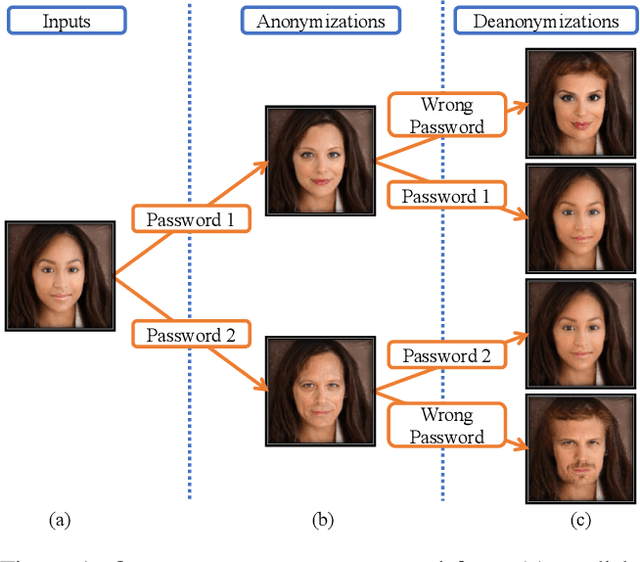

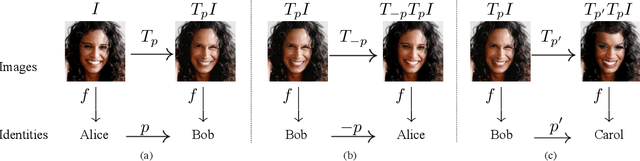
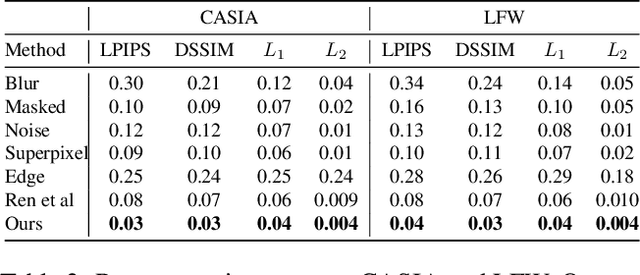
Cameras are prevalent in our daily lives, and enable many useful systems built upon computer vision technologies such as smart cameras and home robots for service applications. However, there is also an increasing societal concern as the captured images/videos may contain privacy-sensitive information (e.g., face identity). We propose a novel face identity transformer which enables automated photo-realistic password-based anonymization as well as deanonymization of human faces appearing in visual data. Our face identity transformer is trained to (1) remove face identity information after anonymization, (2) make the recovery of the original face possible when given the correct password, and (3) return a wrong--but photo-realistic--face given a wrong password. Extensive experiments show that our approach enables multimodal password-conditioned face anonymizations and deanonymizations, without sacrificing privacy compared to existing anonymization approaches.
Improving the Authentication with Built-in Camera Protocol Using Built-in Motion Sensors: A Deep Learning Solution
Jul 27, 2021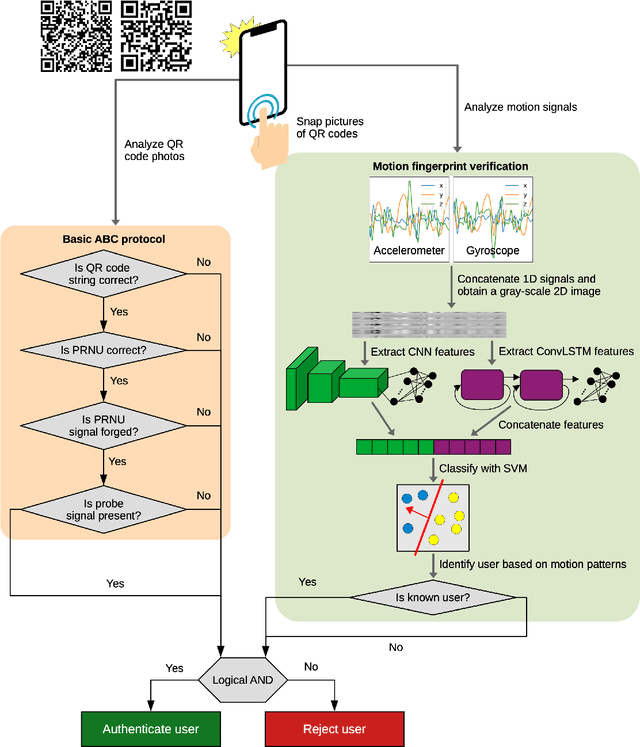
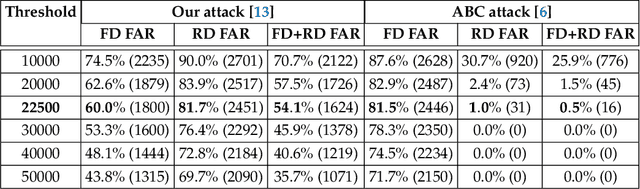
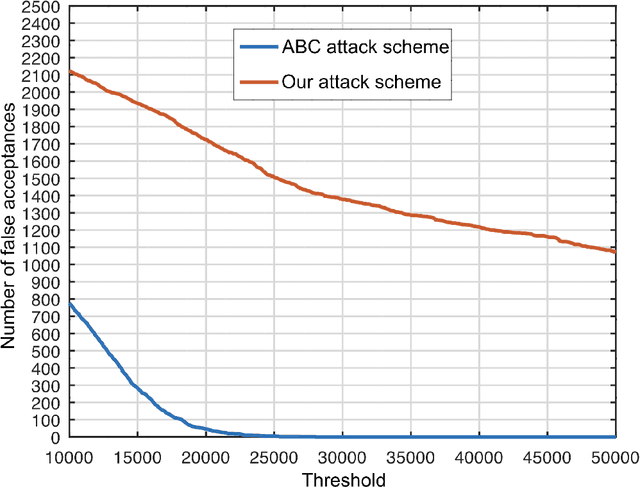
We propose an enhanced version of the Authentication with Built-in Camera (ABC) protocol by employing a deep learning solution based on built-in motion sensors. The standard ABC protocol identifies mobile devices based on the photo-response non-uniformity (PRNU) of the camera sensor, while also considering QR-code-based meta-information. During authentication, the user is required to take two photos that contain two QR codes presented on a screen. The presented QR code images also contain a unique probe signal, similar to a camera fingerprint, generated by the protocol. During verification, the server computes the fingerprint of the received photos and authenticates the user if (i) the probe signal is present, (ii) the metadata embedded in the QR codes is correct and (iii) the camera fingerprint is identified correctly. However, the protocol is vulnerable to forgery attacks when the attacker can compute the camera fingerprint from external photos, as shown in our preliminary work. In this context, we propose an enhancement for the ABC protocol based on motion sensor data, as an additional and passive authentication layer. Smartphones can be identified through their motion sensor data, which, unlike photos, is never posted by users on social media platforms, thus being more secure than using photographs alone. To this end, we transform motion signals into embedding vectors produced by deep neural networks, applying Support Vector Machines for the smartphone identification task. Our change to the ABC protocol results in a multi-modal protocol that lowers the false acceptance rate for the attack proposed in our previous work to a percentage as low as 0.07%.
HoughNet: Integrating near and long-range evidence for visual detection
Apr 14, 2021
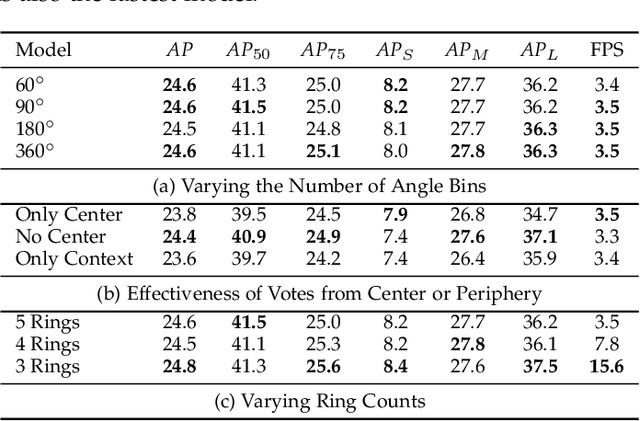
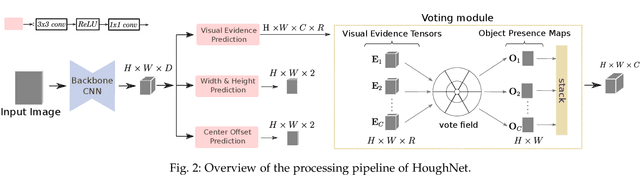

This paper presents HoughNet, a one-stage, anchor-free, voting-based, bottom-up object detection method. Inspired by the Generalized Hough Transform, HoughNet determines the presence of an object at a certain location by the sum of the votes cast on that location. Votes are collected from both near and long-distance locations based on a log-polar vote field. Thanks to this voting mechanism, HoughNet is able to integrate both near and long-range, class-conditional evidence for visual recognition, thereby generalizing and enhancing current object detection methodology, which typically relies on only local evidence. On the COCO dataset, HoughNet's best model achieves $46.4$ $AP$ (and $65.1$ $AP_{50}$), performing on par with the state-of-the-art in bottom-up object detection and outperforming most major one-stage and two-stage methods. We further validate the effectiveness of our proposal in other visual detection tasks, namely, video object detection, instance segmentation, 3D object detection and keypoint detection for human pose estimation, and an additional ``labels to photo`` image generation task, where the integration of our voting module consistently improves performance in all cases. Code is available at \url{https://github.com/nerminsamet/houghnet}.
Learning Semantic Person Image Generation by Region-Adaptive Normalization
Apr 14, 2021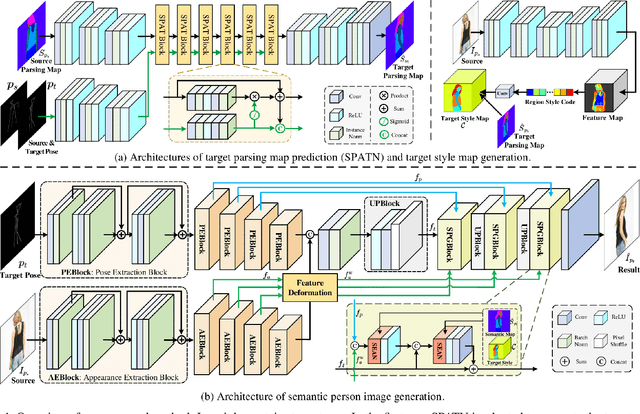
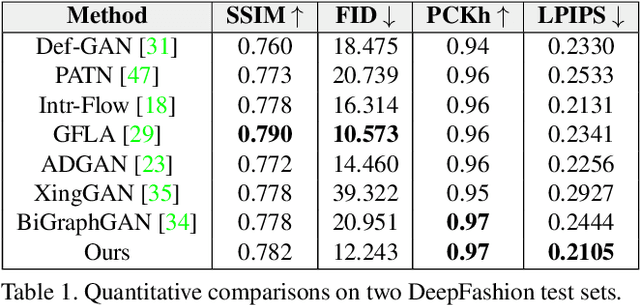
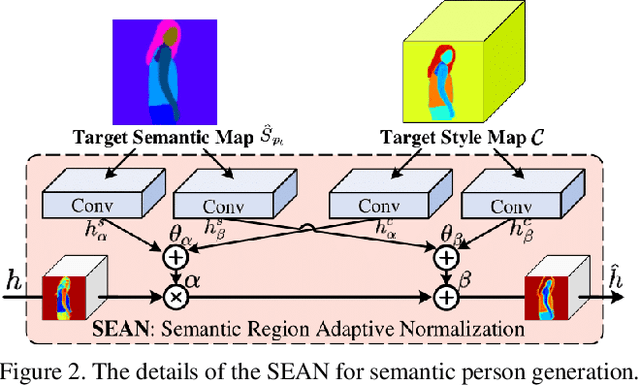

Human pose transfer has received great attention due to its wide applications, yet is still a challenging task that is not well solved. Recent works have achieved great success to transfer the person image from the source to the target pose. However, most of them cannot well capture the semantic appearance, resulting in inconsistent and less realistic textures on the reconstructed results. To address this issue, we propose a new two-stage framework to handle the pose and appearance translation. In the first stage, we predict the target semantic parsing maps to eliminate the difficulties of pose transfer and further benefit the latter translation of per-region appearance style. In the second one, with the predicted target semantic maps, we suggest a new person image generation method by incorporating the region-adaptive normalization, in which it takes the per-region styles to guide the target appearance generation. Extensive experiments show that our proposed SPGNet can generate more semantic, consistent, and photo-realistic results and perform favorably against the state of the art methods in terms of quantitative and qualitative evaluation. The source code and model are available at https://github.com/cszy98/SPGNet.git.
VOGUE: Try-On by StyleGAN Interpolation Optimization
Jan 06, 2021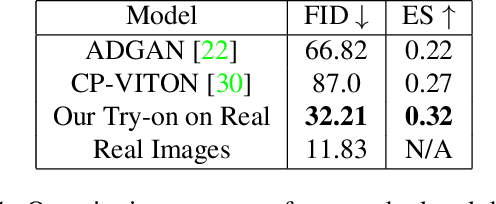
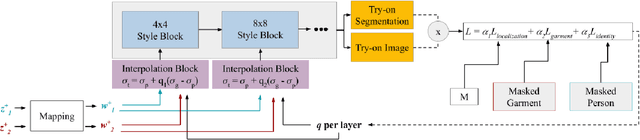
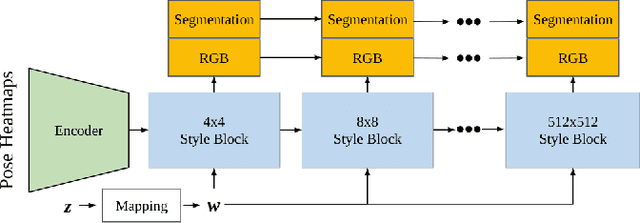

Given an image of a target person and an image of another person wearing a garment, we automatically generate the target person in the given garment. At the core of our method is a pose-conditioned StyleGAN2 latent space interpolation, which seamlessly combines the areas of interest from each image, i.e., body shape, hair, and skin color are derived from the target person, while the garment with its folds, material properties, and shape comes from the garment image. By automatically optimizing for interpolation coefficients per layer in the latent space, we can perform a seamless, yet true to source, merging of the garment and target person. Our algorithm allows for garments to deform according to the given body shape, while preserving pattern and material details. Experiments demonstrate state-of-the-art photo-realistic results at high resolution ($512\times 512$).
Active Bayesian Multi-class Mapping from Range and Semantic Segmentation Observation
Jan 06, 2021
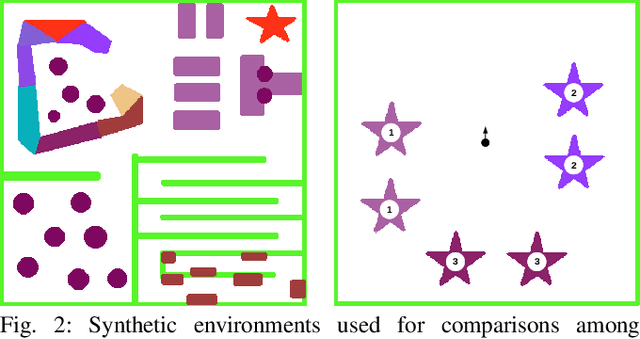
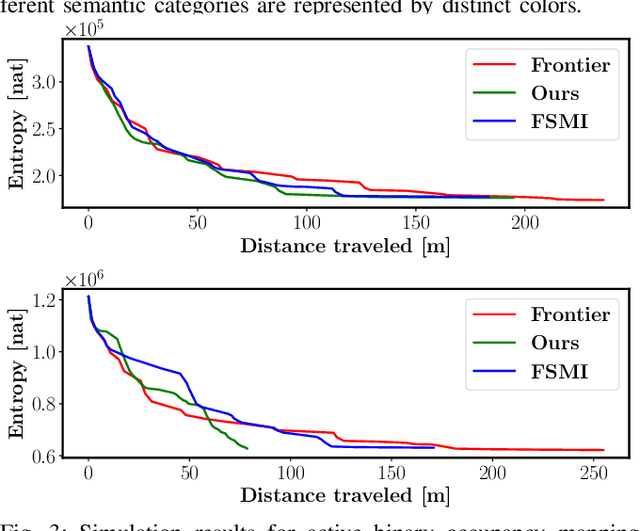
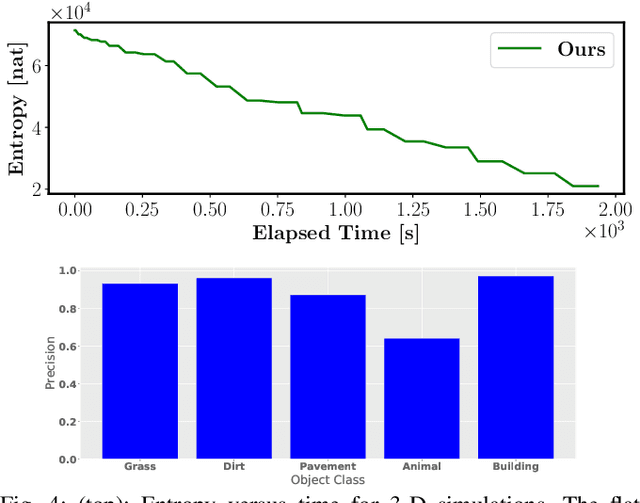
Many robot applications call for autonomous exploration and mapping of unknown and unstructured environments. Information-based exploration techniques, such as Cauchy-Schwarz quadratic mutual information (CSQMI) and fast Shannon mutual information (FSMI), have successfully achieved active binary occupancy mapping with range measurements. However, as we envision robots performing complex tasks specified with semantically meaningful objects, it is necessary to capture semantic categories in the measurements, map representation, and exploration objective. This work develops a Bayesian multi-class mapping algorithm utilizing range-category measurements. We derive a closed-form efficiently computable lower bound for the Shannon mutual information between the multi-class map and the measurements. The bound allows rapid evaluation of many potential robot trajectories for autonomous exploration and mapping. We compare our method against frontier-based and FSMI exploration and apply it in a 3-D photo-realistic simulation environment.
cGANs for Cartoon to Real-life Images
Jan 24, 2021

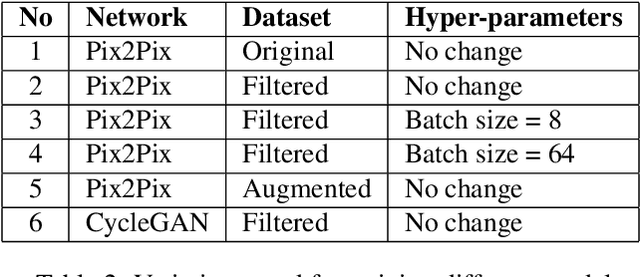

The image-to-image translation is a learning task to establish a visual mapping between an input and output image. The task has several variations differentiated based on the purpose of the translation, such as synthetic to real translation, photo to caricature translation, and many others. The problem has been tackled using different approaches, either through traditional computer vision methods, as well as deep learning approaches in recent trends. One approach currently deemed popular and effective is using the conditional generative adversarial network, also known shortly as cGAN. It is adapted to perform image-to-image translation tasks with typically two networks: a generator and a discriminator. This project aims to evaluate the robustness of the Pix2Pix model by applying the Pix2Pix model to datasets consisting of cartoonized images. Using the Pix2Pix model, it should be possible to train the network to generate real-life images from the cartoonized images.
BlendTorch: A Real-Time, Adaptive Domain Randomization Library
Oct 06, 2020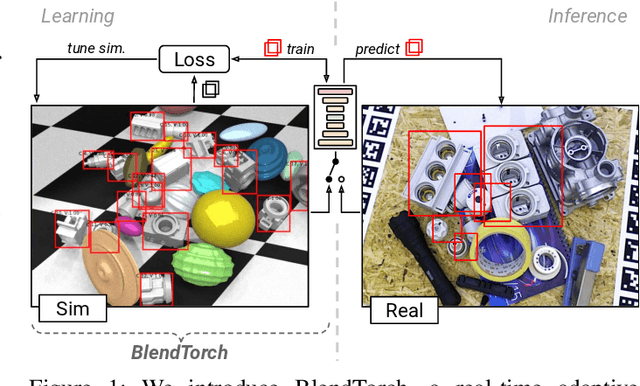
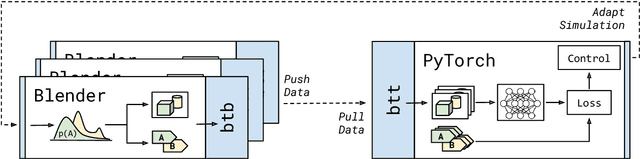

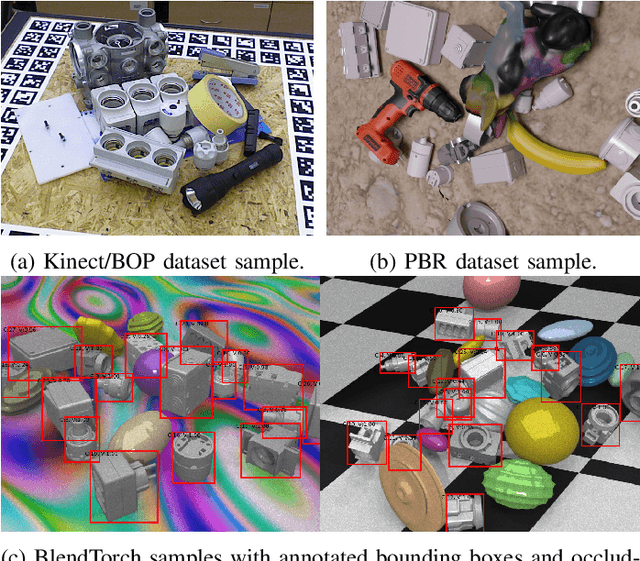
Solving complex computer vision tasks by deep learning techniques relies on large amounts of (supervised) image data, typically unavailable in industrial environments. The lack of training data starts to impede the successful transfer of state-of-the-art methods in computer vision to industrial applications. We introduce BlendTorch, an adaptive Domain Randomization (DR) library, to help creating infinite streams of synthetic training data. BlendTorch generates data by massively randomizing low-fidelity simulations and takes care of distributing artificial training data for model learning in real-time. We show that models trained with BlendTorch repeatedly perform better in an industrial object detection task than those trained on real or photo-realistic datasets.