 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
A Closed-form Solution to Photorealistic Image Stylization
Jul 27, 2018

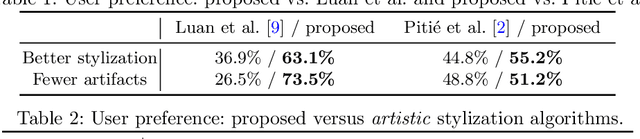


Photorealistic image stylization concerns transferring style of a reference photo to a content photo with the constraint that the stylized photo should remain photorealistic. While several photorealistic image stylization methods exist, they tend to generate spatially inconsistent stylizations with noticeable artifacts. In this paper, we propose a method to address these issues. The proposed method consists of a stylization step and a smoothing step. While the stylization step transfers the style of the reference photo to the content photo, the smoothing step ensures spatially consistent stylizations. Each of the steps has a closed-form solution and can be computed efficiently. We conduct extensive experimental validations. The results show that the proposed method generates photorealistic stylization outputs that are more preferred by human subjects as compared to those by the competing methods while running much faster. Source code and additional results are available at https://github.com/NVIDIA/FastPhotoStyle .
Mimicking the In-Camera Color Pipeline for Camera-Aware Object Compositing
Mar 27, 2019
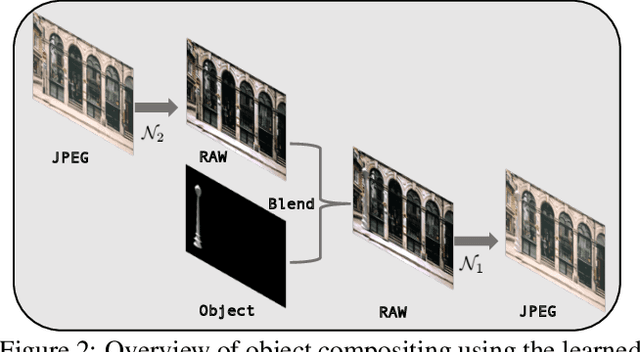
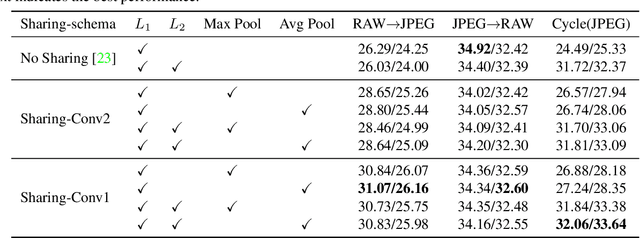
We present a method for compositing virtual objects into a photograph such that the object colors appear to have been processed by the photo's camera imaging pipeline. Compositing in such a camera-aware manner is essential for high realism, and it requires the color transformation in the photo's pipeline to be inferred, which is challenging due to the inherent one-to-many mapping that exists from a scene to a photo. To address this problem for the case of a single photo taken from an unknown camera, we propose a dual-learning approach in which the reverse color transformation (from the photo to the scene) is jointly estimated. Learning of the reverse transformation is used to facilitate learning of the forward mapping, by enforcing cycle consistency of the two processes. We additionally employ a feature sharing schema to extract evidence from the target photo in the reverse mapping to guide the forward color transformation. Our dual-learning approach achieves object compositing results that surpass those of alternative techniques.
VIDIT: Virtual Image Dataset for Illumination Transfer
May 13, 2020
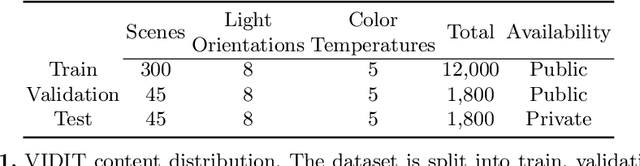
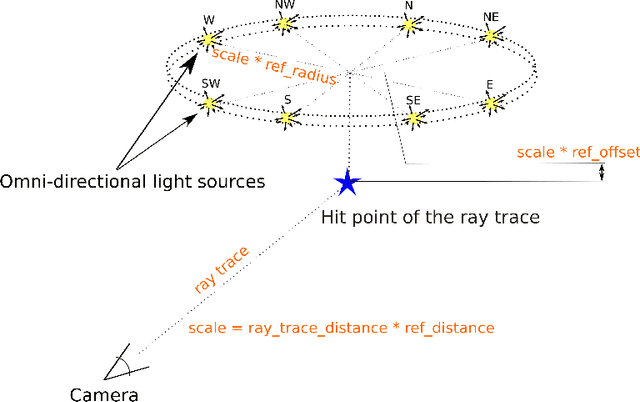

Deep image relighting is gaining more interest lately, as it allows photo enhancement through illumination-specific retouching without human effort. Aside from aesthetic enhancement and photo montage, image relighting is valuable for domain adaptation, whether to augment datasets for training or to normalize input test data. Accurate relighting is, however, very challenging for various reasons, such as the difficulty in removing and recasting shadows and the modeling of different surfaces. We present a novel dataset, the Virtual Image Dataset for Illumination Transfer (VIDIT), in an effort to create a reference evaluation benchmark and to push forward the development of illumination manipulation methods. Virtual datasets are not only an important step towards achieving real-image performance but have also proven capable of improving training even when real datasets are possible to acquire and available. VIDIT contains 300 virtual scenes used for training, where every scene is captured 40 times in total: from 8 equally-spaced azimuthal angles, each lit with 5 different illuminants.
Cross-Modal Hierarchical Modelling for Fine-Grained Sketch Based Image Retrieval
Jul 29, 2020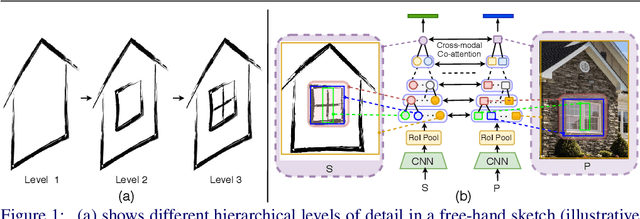
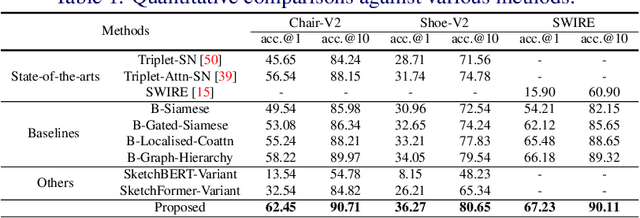
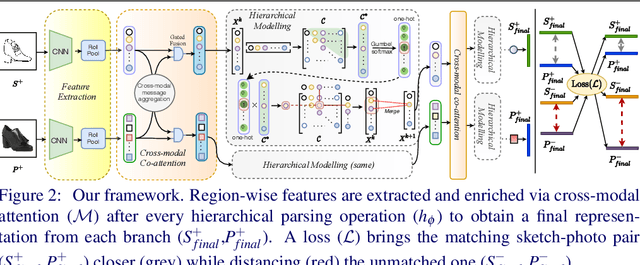
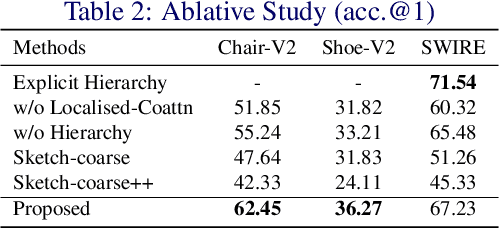
Sketch as an image search query is an ideal alternative to text in capturing the fine-grained visual details. Prior successes on fine-grained sketch-based image retrieval (FG-SBIR) have demonstrated the importance of tackling the unique traits of sketches as opposed to photos, e.g., temporal vs. static, strokes vs. pixels, and abstract vs. pixel-perfect. In this paper, we study a further trait of sketches that has been overlooked to date, that is, they are hierarchical in terms of the levels of detail -- a person typically sketches up to various extents of detail to depict an object. This hierarchical structure is often visually distinct. In this paper, we design a novel network that is capable of cultivating sketch-specific hierarchies and exploiting them to match sketch with photo at corresponding hierarchical levels. In particular, features from a sketch and a photo are enriched using cross-modal co-attention, coupled with hierarchical node fusion at every level to form a better embedding space to conduct retrieval. Experiments on common benchmarks show our method to outperform state-of-the-arts by a significant margin.
Semantic-driven Colorization
Jun 18, 2020



Recent deep colorization works predict the semantic information implicitly while learning to colorize black-and-white photographic images. As a consequence, the generated color is easier to be overflowed, and the semantic faults are invisible. As human experience in coloring, the human first recognize which objects and their location in the photo, imagine which color is plausible for the objects as in real life, then colorize it. In this study, we simulate that human-like action to firstly let our network learn to segment what is in the photo, then colorize it. Therefore, our network can choose a plausible color under semantic constraint for specific objects, and give discriminative colors between them. Moreover, the segmentation map becomes understandable and interactable for the user. Our models are trained on PASCAL-Context and evaluated on selected images from the public domain and COCO-Stuff, which has several unseen categories compared to training data. As seen from the experimental results, our colorization system can provide plausible colors for specific objects and generate harmonious colors competitive with state-of-the-art methods.
Reverse Engineering of Generative Models: Inferring Model Hyperparameters from Generated Images
Jun 15, 2021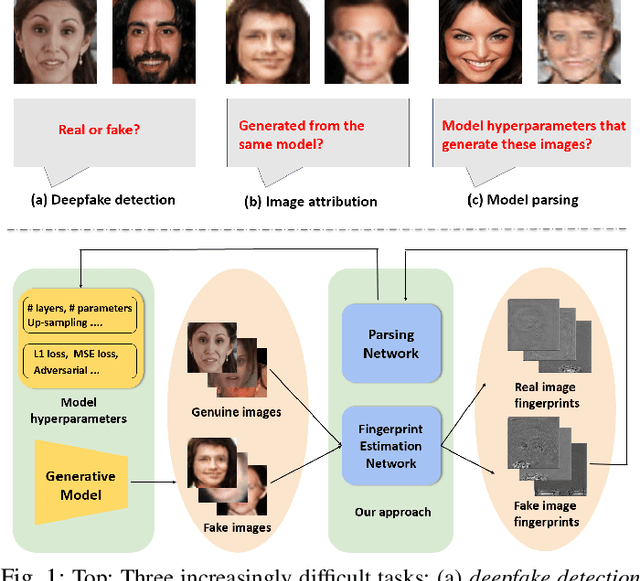


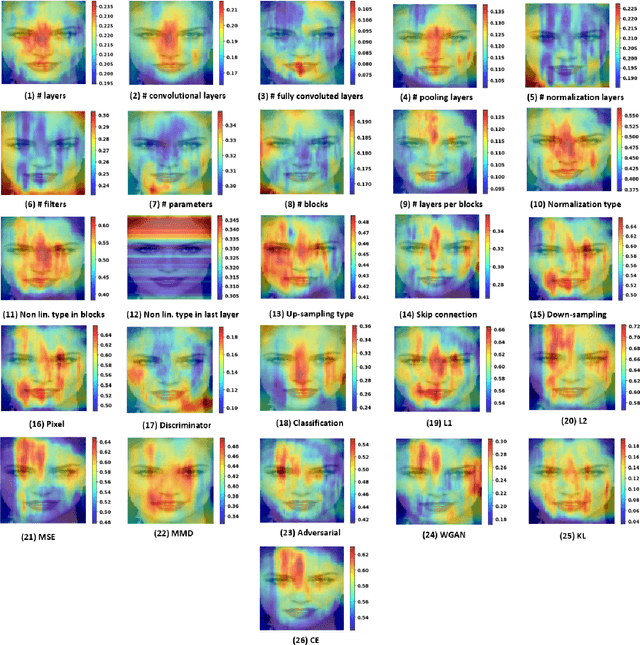
State-of-the-art (SOTA) Generative Models (GMs) can synthesize photo-realistic images that are hard for humans to distinguish from genuine photos. We propose to perform reverse engineering of GMs to infer the model hyperparameters from the images generated by these models. We define a novel problem, "model parsing", as estimating GM network architectures and training loss functions by examining their generated images -- a task seemingly impossible for human beings. To tackle this problem, we propose a framework with two components: a Fingerprint Estimation Network (FEN), which estimates a GM fingerprint from a generated image by training with four constraints to encourage the fingerprint to have desired properties, and a Parsing Network (PN), which predicts network architecture and loss functions from the estimated fingerprints. To evaluate our approach, we collect a fake image dataset with $100$K images generated by $100$ GMs. Extensive experiments show encouraging results in parsing the hyperparameters of the unseen models. Finally, our fingerprint estimation can be leveraged for deepfake detection and image attribution, as we show by reporting SOTA results on both the recent Celeb-DF and image attribution benchmarks.
Egocentric Activity Recognition and Localization on a 3D Map
May 20, 2021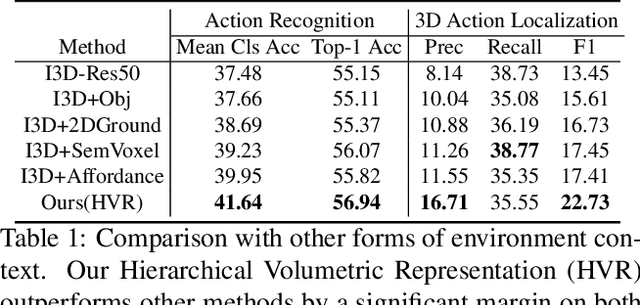
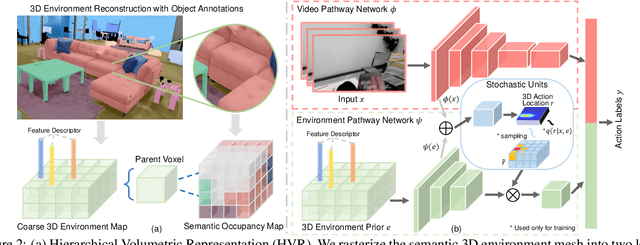
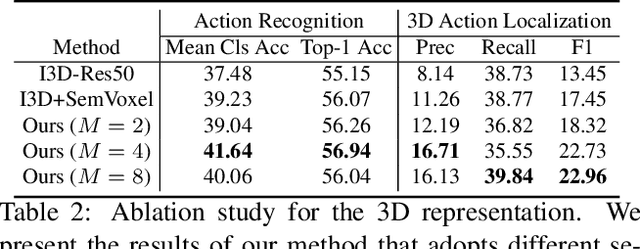
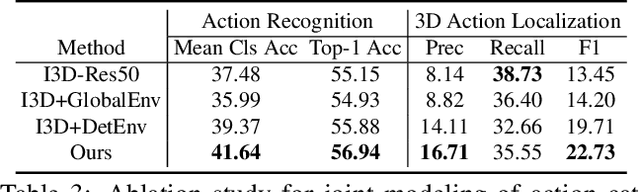
Given a video captured from a first person perspective and recorded in a familiar environment, can we recognize what the person is doing and identify where the action occurs in the 3D space? We address this challenging problem of jointly recognizing and localizing actions of a mobile user on a known 3D map from egocentric videos. To this end, we propose a novel deep probabilistic model. Our model takes the inputs of a Hierarchical Volumetric Representation (HVR) of the environment and an egocentric video, infers the 3D action location as a latent variable, and recognizes the action based on the video and contextual cues surrounding its potential locations. To evaluate our model, we conduct extensive experiments on a newly collected egocentric video dataset, in which both human naturalistic actions and photo-realistic 3D environment reconstructions are captured. Our method demonstrates strong results on both action recognition and 3D action localization across seen and unseen environments. We believe our work points to an exciting research direction in the intersection of egocentric vision, and 3D scene understanding.
Identifying the Origin of Finger Vein Samples Using Texture Descriptors
Feb 08, 2021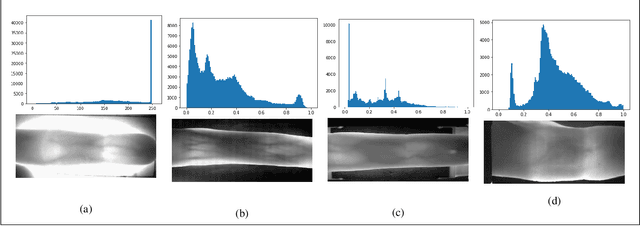
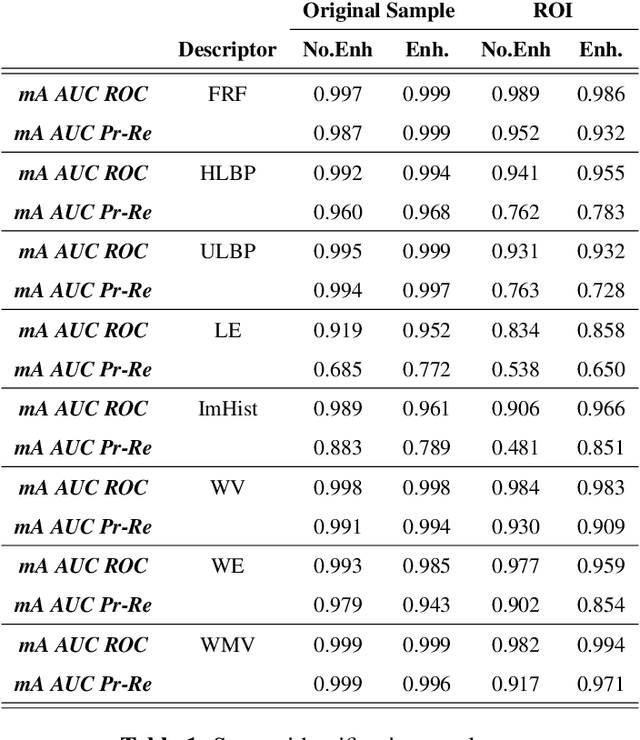


Identifying the origin of a sample image in biometric systems can be beneficial for data authentication in case of attacks against the system and for initiating sensor-specific processing pipelines in sensor-heterogeneous environments. Motivated by shortcomings of the photo response non-uniformity (PRNU) based method in the biometric context, we use a texture classification approach to detect the origin of finger vein sample images. Based on eight publicly available finger vein datasets and applying eight classical yet simple texture descriptors and SVM classification, we demonstrate excellent sensor model identification results for raw finger vein samples as well as for the more challenging region of interest data. The observed results establish texture descriptors as effective competitors to PRNU in finger vein sensor model identification.
Image color correction, enhancement, and editing
Jul 28, 2021This thesis presents methods and approaches to image color correction, color enhancement, and color editing. To begin, we study the color correction problem from the standpoint of the camera's image signal processor (ISP). A camera's ISP is hardware that applies a series of in-camera image processing and color manipulation steps, many of which are nonlinear in nature, to render the initial sensor image to its final photo-finished representation saved in the 8-bit standard RGB (sRGB) color space. As white balance (WB) is one of the major procedures applied by the ISP for color correction, this thesis presents two different methods for ISP white balancing. Afterward, we discuss another scenario of correcting and editing image colors, where we present a set of methods to correct and edit WB settings for images that have been improperly white-balanced by the ISP. Then, we explore another factor that has a significant impact on the quality of camera-rendered colors, in which we outline two different methods to correct exposure errors in camera-rendered images. Lastly, we discuss post-capture auto color editing and manipulation. In particular, we propose auto image recoloring methods to generate different realistic versions of the same camera-rendered image with new colors. Through extensive evaluations, we demonstrate that our methods provide superior solutions compared to existing alternatives targeting color correction, color enhancement, and color editing.