 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
The Northumberland Dolphin Dataset: A Multimedia Individual Cetacean Dataset for Fine-Grained Categorisation
Aug 07, 2019
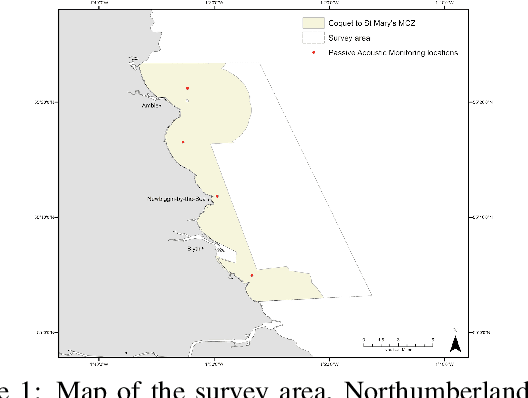
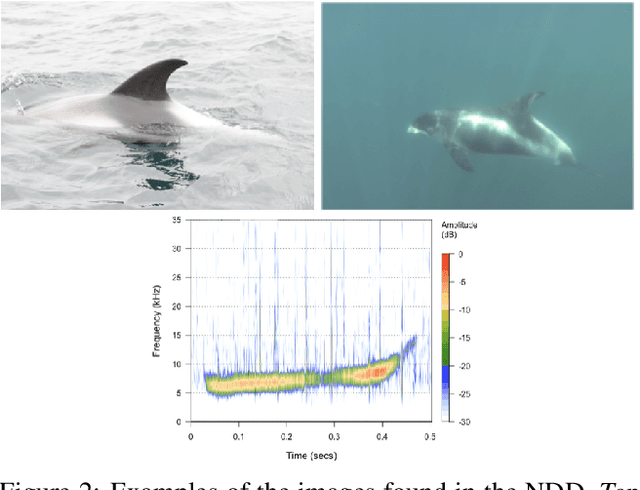


Methods for cetacean research include photo-identification (photo-id) and passive acoustic monitoring (PAM) which generate thousands of images per expedition that are currently hand categorised by researchers into the individual dolphins sighted. With the vast amount of data obtained it is crucially important to develop a system that is able to categorise this quickly. The Northumberland Dolphin Dataset (NDD) is an on-going novel dataset project made up of above and below water images of, and spectrograms of whistles from, white-beaked dolphins. These are produced by photo-id and PAM data collection methods applied off the coast of Northumberland, UK. This dataset will aid in building cetacean identification models, reducing the number of human-hours required to categorise images. Example use cases and areas identified for speed up are examined.
Image Comes Dancing with Collaborative Parsing-Flow Video Synthesis
Oct 28, 2021
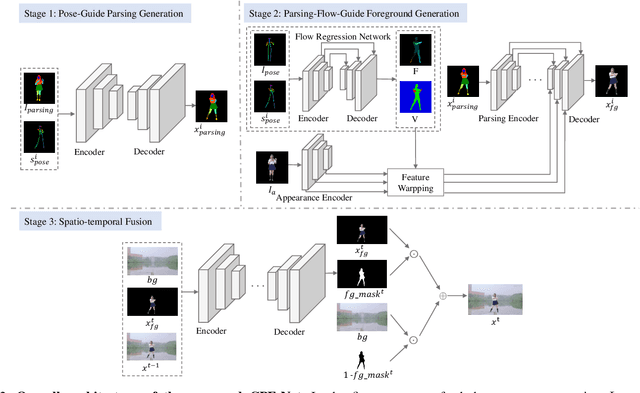


Transferring human motion from a source to a target person poses great potential in computer vision and graphics applications. A crucial step is to manipulate sequential future motion while retaining the appearance characteristic.Previous work has either relied on crafted 3D human models or trained a separate model specifically for each target person, which is not scalable in practice.This work studies a more general setting, in which we aim to learn a single model to parsimoniously transfer motion from a source video to any target person given only one image of the person, named as Collaborative Parsing-Flow Network (CPF-Net). The paucity of information regarding the target person makes the task particularly challenging to faithfully preserve the appearance in varying designated poses. To address this issue, CPF-Net integrates the structured human parsing and appearance flow to guide the realistic foreground synthesis which is merged into the background by a spatio-temporal fusion module. In particular, CPF-Net decouples the problem into stages of human parsing sequence generation, foreground sequence generation and final video generation. The human parsing generation stage captures both the pose and the body structure of the target. The appearance flow is beneficial to keep details in synthesized frames. The integration of human parsing and appearance flow effectively guides the generation of video frames with realistic appearance. Finally, the dedicated designed fusion network ensure the temporal coherence. We further collect a large set of human dancing videos to push forward this research field. Both quantitative and qualitative results show our method substantially improves over previous approaches and is able to generate appealing and photo-realistic target videos given any input person image. All source code and dataset will be released at https://github.com/xiezhy6/CPF-Net.
CUDA-GR: Controllable Unsupervised Domain Adaptation for Gaze Redirection
Jun 21, 2021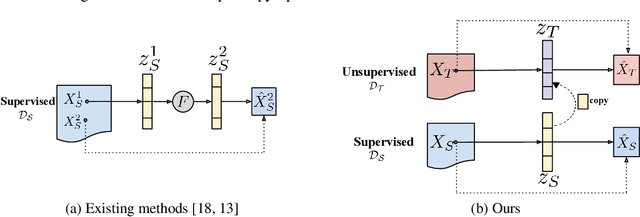
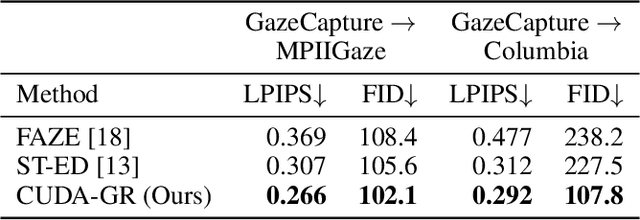
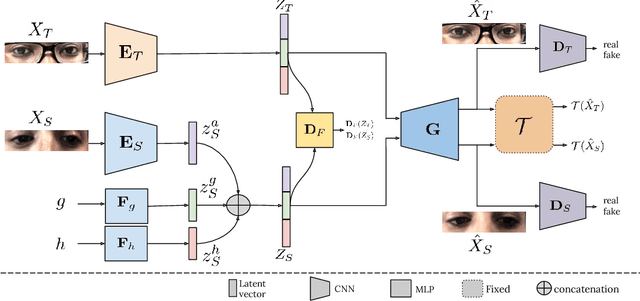

The aim of gaze redirection is to manipulate the gaze in an image to the desired direction. However, existing methods are inadequate in generating perceptually reasonable images. Advancement in generative adversarial networks has shown excellent results in generating photo-realistic images. Though, they still lack the ability to provide finer control over different image attributes. To enable such fine-tuned control, one needs to obtain ground truth annotations for the training data which can be very expensive. In this paper, we propose an unsupervised domain adaptation framework, called CUDA-GR, that learns to disentangle gaze representations from the labeled source domain and transfers them to an unlabeled target domain. Our method enables fine-grained control over gaze directions while preserving the appearance information of the person. We show that the generated image-labels pairs in the target domain are effective in knowledge transfer and can boost the performance of the downstream tasks. Extensive experiments on the benchmarking datasets show that the proposed method can outperform state-of-the-art techniques in both quantitative and qualitative evaluation.
Few-shot Neural Human Performance Rendering from Sparse RGBD Videos
Jul 14, 2021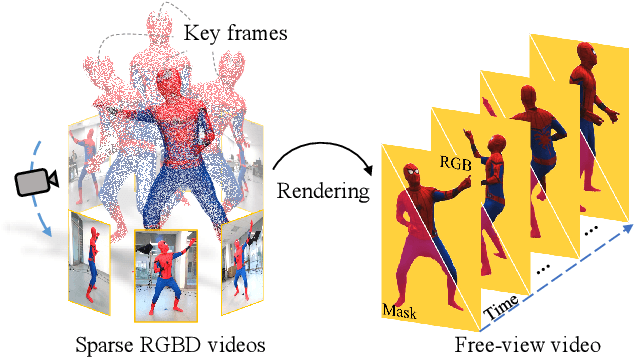
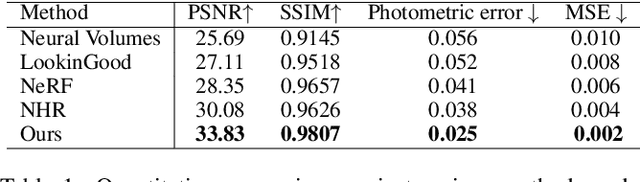
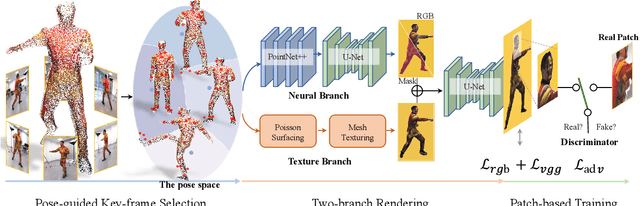
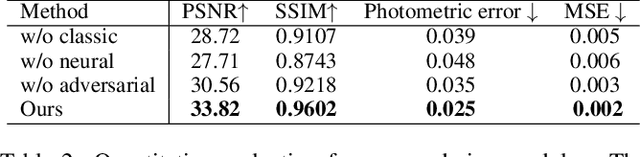
Recent neural rendering approaches for human activities achieve remarkable view synthesis results, but still rely on dense input views or dense training with all the capture frames, leading to deployment difficulty and inefficient training overload. However, existing advances will be ill-posed if the input is both spatially and temporally sparse. To fill this gap, in this paper we propose a few-shot neural human rendering approach (FNHR) from only sparse RGBD inputs, which exploits the temporal and spatial redundancy to generate photo-realistic free-view output of human activities. Our FNHR is trained only on the key-frames which expand the motion manifold in the input sequences. We introduce a two-branch neural blending to combine the neural point render and classical graphics texturing pipeline, which integrates reliable observations over sparse key-frames. Furthermore, we adopt a patch-based adversarial training process to make use of the local redundancy and avoids over-fitting to the key-frames, which generates fine-detailed rendering results. Extensive experiments demonstrate the effectiveness of our approach to generate high-quality free view-point results for challenging human performances under the sparse setting.
Multi-Modal Multi-Instance Learning for Retinal Disease Recognition
Sep 25, 2021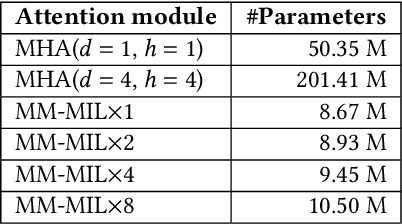
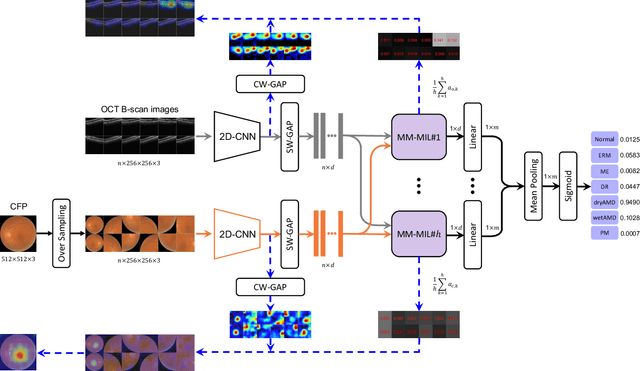
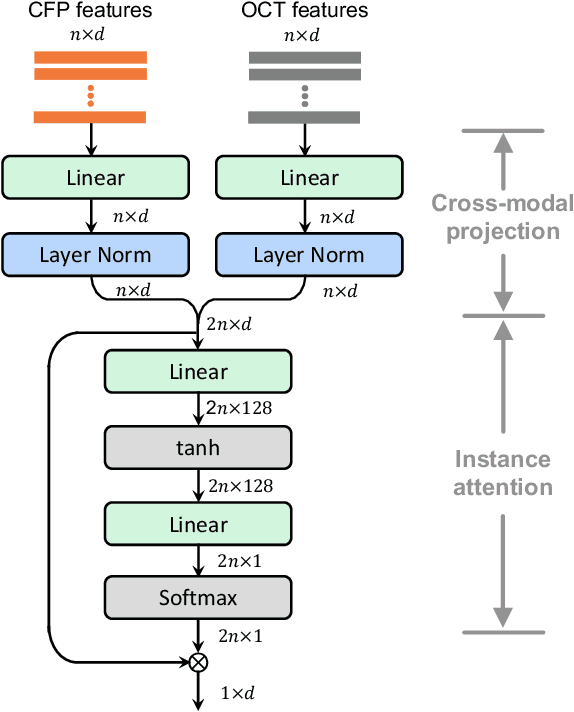
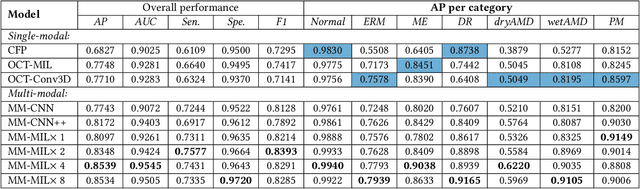
This paper attacks an emerging challenge of multi-modal retinal disease recognition. Given a multi-modal case consisting of a color fundus photo (CFP) and an array of OCT B-scan images acquired during an eye examination, we aim to build a deep neural network that recognizes multiple vision-threatening diseases for the given case. As the diagnostic efficacy of CFP and OCT is disease-dependent, the network's ability of being both selective and interpretable is important. Moreover, as both data acquisition and manual labeling are extremely expensive in the medical domain, the network has to be relatively lightweight for learning from a limited set of labeled multi-modal samples. Prior art on retinal disease recognition focuses either on a single disease or on a single modality, leaving multi-modal fusion largely underexplored. We propose in this paper Multi-Modal Multi-Instance Learning (MM-MIL) for selectively fusing CFP and OCT modalities. Its lightweight architecture (as compared to current multi-head attention modules) makes it suited for learning from relatively small-sized datasets. For an effective use of MM-MIL, we propose to generate a pseudo sequence of CFPs by over sampling a given CFP. The benefits of this tactic include well balancing instances across modalities, increasing the resolution of the CFP input, and finding out regions of the CFP most relevant with respect to the final diagnosis. Extensive experiments on a real-world dataset consisting of 1,206 multi-modal cases from 1,193 eyes of 836 subjects demonstrate the viability of the proposed model.
S-Flow GAN
May 21, 2019



This work offers a new method for generating photo-realistic images from semantic label maps and a simulator edge map images. We do so in a conditional manner, where we train a Generative Adversarial network (GAN) given an image and its semantic label map to output a photo-realistic version of that scene. Existing architectures of GANs still lack the photo-realism capabilities. We address this issue by embedding edge maps, and presenting the Generator with an edge map image as a prior, which enables generating high level details in the image. We offer a model that uses this generator to create visually appealing videos as well, when a sequence of images is given.
Fast Camera Image Denoising on Mobile GPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

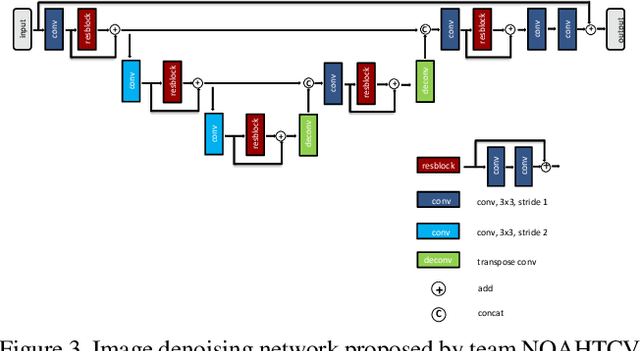
Image denoising is one of the most critical problems in mobile photo processing. While many solutions have been proposed for this task, they are usually working with synthetic data and are too computationally expensive to run on mobile devices. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image denoising solution that can demonstrate high efficiency on smartphone GPUs. For this, the participants were provided with a novel large-scale dataset consisting of noisy-clean image pairs captured in the wild. The runtime of all models was evaluated on the Samsung Exynos 2100 chipset with a powerful Mali GPU capable of accelerating floating-point and quantized neural networks. The proposed solutions are fully compatible with any mobile GPU and are capable of processing 480p resolution images under 40-80 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
Image Super-Resolution via Iterative Refinement
Apr 15, 2021
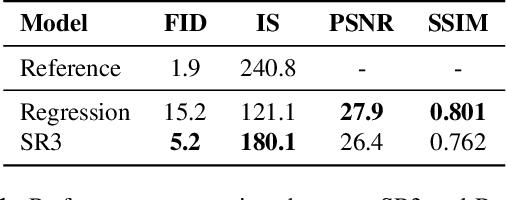
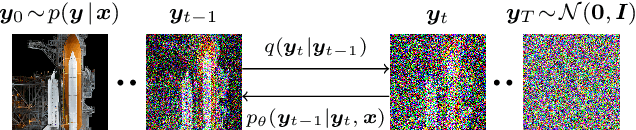

We present SR3, an approach to image Super-Resolution via Repeated Refinement. SR3 adapts denoising diffusion probabilistic models to conditional image generation and performs super-resolution through a stochastic denoising process. Inference starts with pure Gaussian noise and iteratively refines the noisy output using a U-Net model trained on denoising at various noise levels. SR3 exhibits strong performance on super-resolution tasks at different magnification factors, on faces and natural images. We conduct human evaluation on a standard 8X face super-resolution task on CelebA-HQ, comparing with SOTA GAN methods. SR3 achieves a fool rate close to 50%, suggesting photo-realistic outputs, while GANs do not exceed a fool rate of 34%. We further show the effectiveness of SR3 in cascaded image generation, where generative models are chained with super-resolution models, yielding a competitive FID score of 11.3 on ImageNet.
Empirical Evaluation of PRNU Fingerprint Variation for Mismatched Imaging Pipelines
Apr 04, 2020
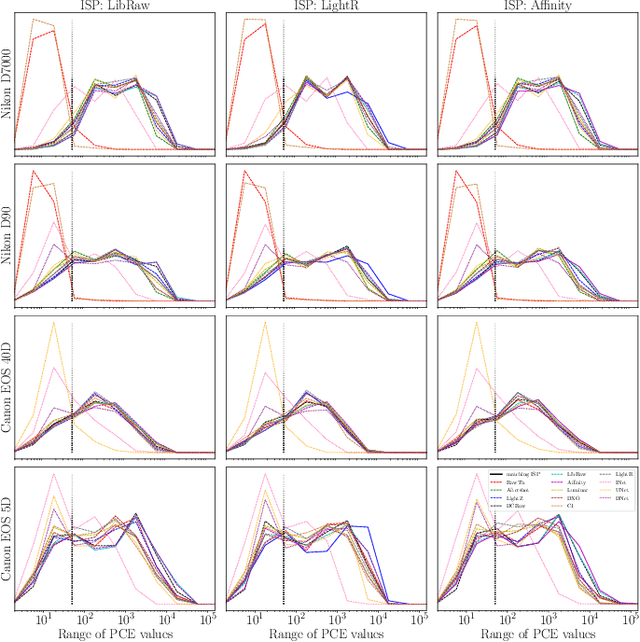
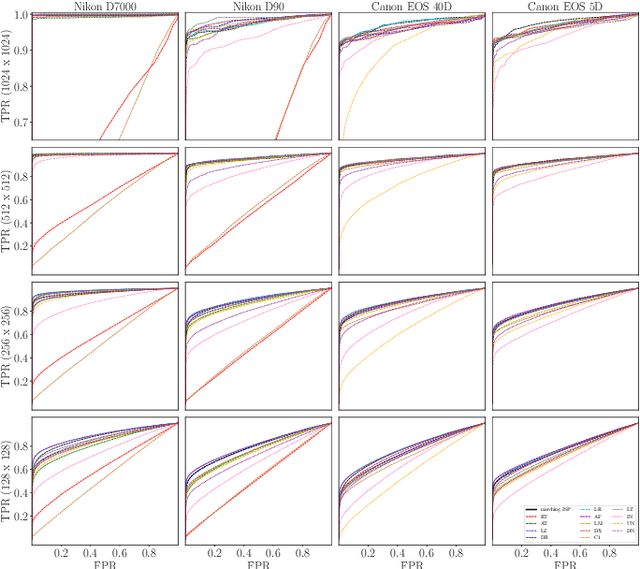

We assess the variability of PRNU-based camera fingerprints with mismatched imaging pipelines (e.g., different camera ISP or digital darkroom software). We show that camera fingerprints exhibit non-negligible variations in this setup, which may lead to unexpected degradation of detection statistics in real-world use-cases. We tested 13 different pipelines, including standard digital darkroom software and recent neural-networks. We observed that correlation between fingerprints from mismatched pipelines drops on average to 0.38 and the PCE detection statistic drops by over 40%. The degradation in error rates is the strongest for small patches commonly used in photo manipulation detection, and when neural networks are used for photo development. At a fixed 0.5% FPR setting, the TPR drops by 17 ppt (percentage points) for 128 px and 256 px patches.
TrueImage: A Machine Learning Algorithm to Improve the Quality of Telehealth Photos
Oct 01, 2020

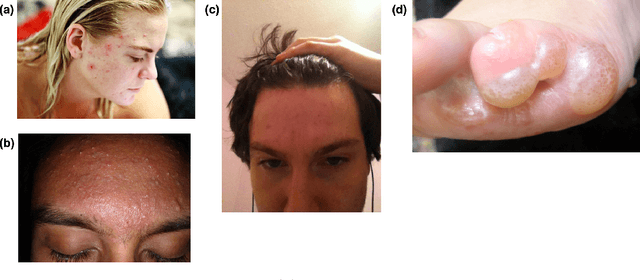

Telehealth is an increasingly critical component of the health care ecosystem, especially due to the COVID-19 pandemic. Rapid adoption of telehealth has exposed limitations in the existing infrastructure. In this paper, we study and highlight photo quality as a major challenge in the telehealth workflow. We focus on teledermatology, where photo quality is particularly important; the framework proposed here can be generalized to other health domains. For telemedicine, dermatologists request that patients submit images of their lesions for assessment. However, these images are often of insufficient quality to make a clinical diagnosis since patients do not have experience taking clinical photos. A clinician has to manually triage poor quality images and request new images to be submitted, leading to wasted time for both the clinician and the patient. We propose an automated image assessment machine learning pipeline, TrueImage, to detect poor quality dermatology photos and to guide patients in taking better photos. Our experiments indicate that TrueImage can reject 50% of the sub-par quality images, while retaining 80% of good quality images patients send in, despite heterogeneity and limitations in the training data. These promising results suggest that our solution is feasible and can improve the quality of teledermatology care.