 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
CNN-based Repetitive self-revised learning for photos' aesthetics imbalanced classification
Mar 09, 2020
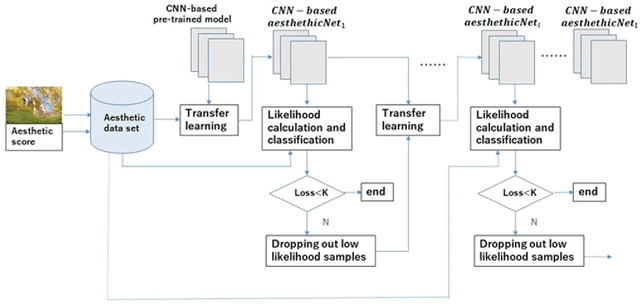
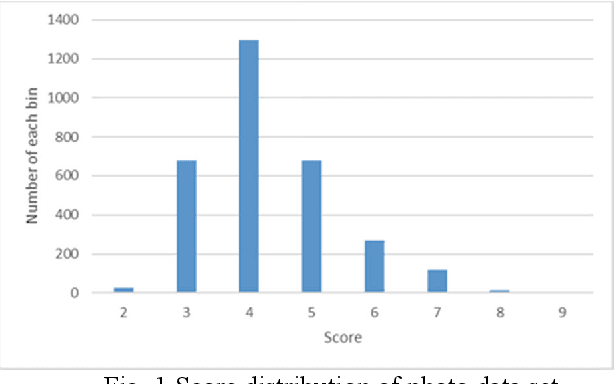
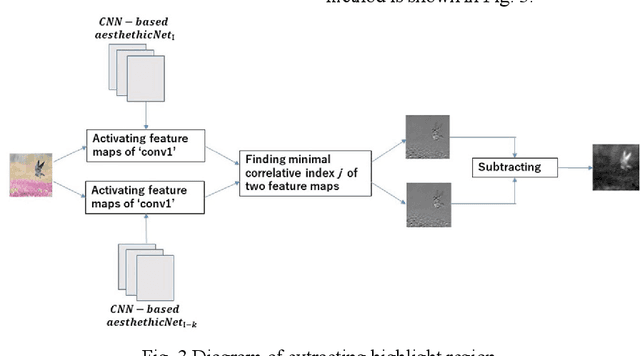

Aesthetic assessment is subjective, and the distribution of the aesthetic levels is imbalanced. In order to realize the auto-assessment of photo aesthetics, we focus on using repetitive self-revised learning (RSRL) to train the CNN-based aesthetics classification network by imbalanced data set. As RSRL, the network is trained repetitively by dropping out the low likelihood photo samples at the middle levels of aesthetics from the training data set based on the previously trained network. Further, the retained two networks are used in extracting highlight regions of the photos related with the aesthetic assessment. Experimental results show that the CNN-based repetitive self-revised learning is effective for improving the performances of the imbalanced classification.
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction
Aug 09, 2021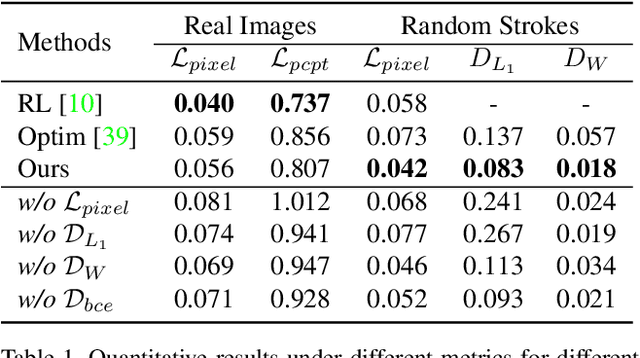
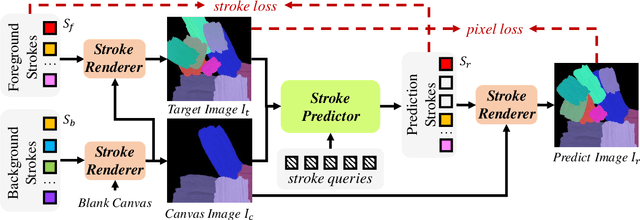
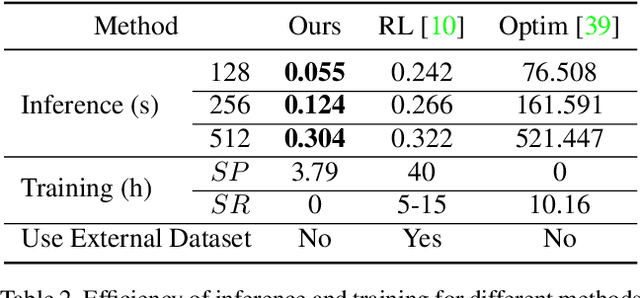
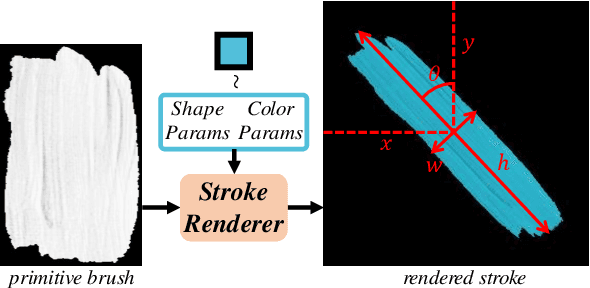
Neural painting refers to the procedure of producing a series of strokes for a given image and non-photo-realistically recreating it using neural networks. While reinforcement learning (RL) based agents can generate a stroke sequence step by step for this task, it is not easy to train a stable RL agent. On the other hand, stroke optimization methods search for a set of stroke parameters iteratively in a large search space; such low efficiency significantly limits their prevalence and practicality. Different from previous methods, in this paper, we formulate the task as a set prediction problem and propose a novel Transformer-based framework, dubbed Paint Transformer, to predict the parameters of a stroke set with a feed forward network. This way, our model can generate a set of strokes in parallel and obtain the final painting of size 512 * 512 in near real time. More importantly, since there is no dataset available for training the Paint Transformer, we devise a self-training pipeline such that it can be trained without any off-the-shelf dataset while still achieving excellent generalization capability. Experiments demonstrate that our method achieves better painting performance than previous ones with cheaper training and inference costs. Codes and models are available.
CAGAN: Text-To-Image Generation with Combined Attention GANs
Apr 26, 2021
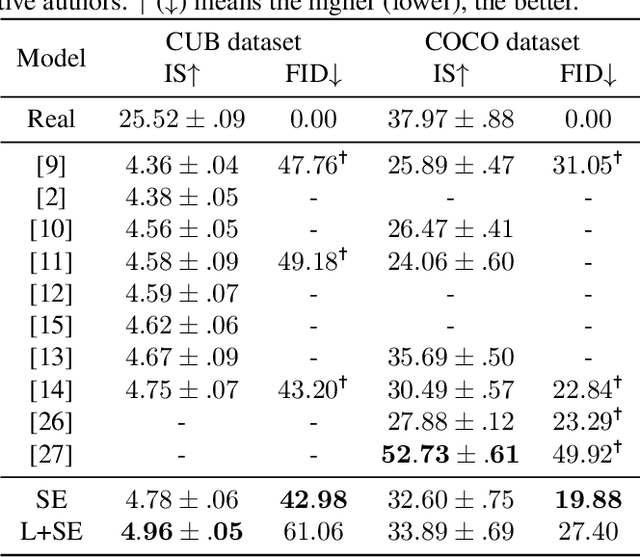
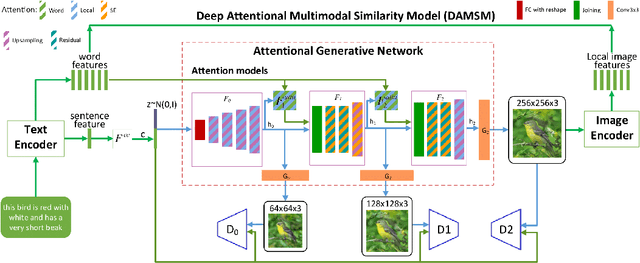

Generating images according to natural language descriptions is a challenging task. In this work, we propose the Combined Attention Generative Adversarial Network (CAGAN) to generate photo-realistic images according to textual descriptions. The proposed CAGAN utilises two attention models: word attention to draw different sub-regions conditioned on related words; and squeeze-and-excitation attention to capture non-linear interaction among channels. With spectral normalisation to stabilise training, our proposed CAGAN improves the state of the art on the IS and FID on the CUB dataset and the FID on the more challenging COCO dataset. Furthermore, we demonstrate that judging a model by a single evaluation metric can be misleading by developing an additional model adding local self-attention which scores a higher IS, outperforming the state of the art on the CUB dataset, but generates unrealistic images through feature repetition.
Efficient High-Resolution Image-to-Image Translation using Multi-Scale Gradient U-Net
May 27, 2021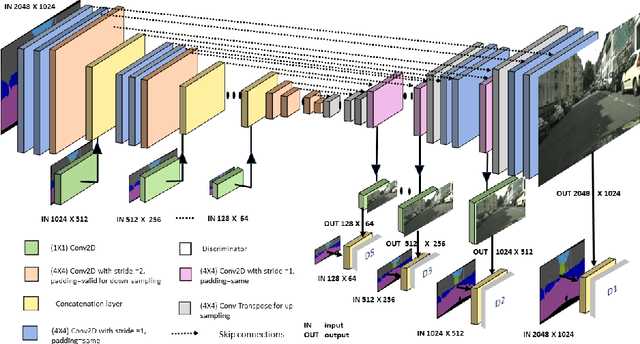
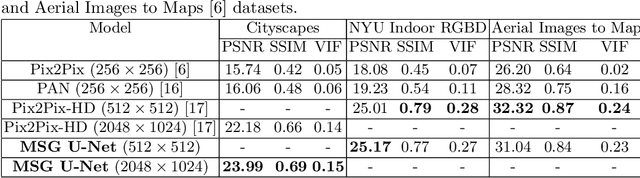
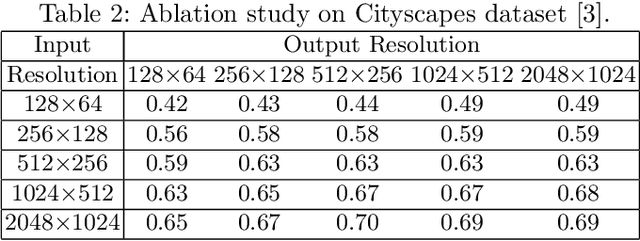
Recently, Conditional Generative Adversarial Network (Conditional GAN) have shown very promising performance in several image-to-image translation applications. However, the uses of these conditional GANs are quite limited to low-resolution images, such as 256X256.The Pix2Pix-HD is a recent attempt to utilize the conditional GAN for high-resolution image synthesis. In this paper, we propose a Multi-Scale Gradient based U-Net (MSG U-Net) model for high-resolution image-to-image translation up to 2048X1024 resolution. The proposed model is trained by allowing the flow of gradients from multiple-discriminators to a single generator at multiple scales. The proposed MSG U-Net architecture leads to photo-realistic high-resolution image-to-image translation. Moreover, the proposed model is computationally efficient as com-pared to the Pix2Pix-HD with an improvement in the inference time nearly by 2.5 times. We provide the code of MSG U-Net model at https://github.com/laxmaniron/MSG-U-Net.
Image Comes Dancing with Collaborative Parsing-Flow Video Synthesis
Oct 28, 2021
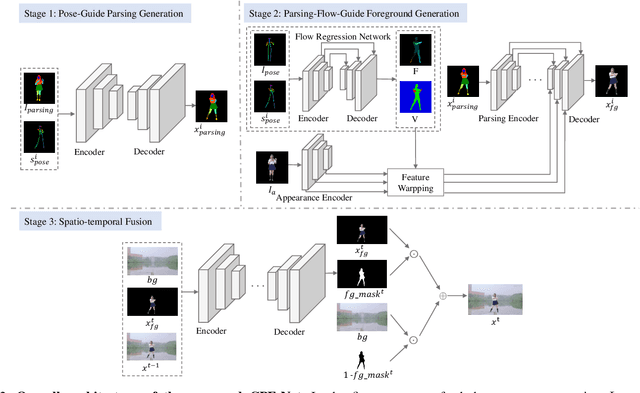


Transferring human motion from a source to a target person poses great potential in computer vision and graphics applications. A crucial step is to manipulate sequential future motion while retaining the appearance characteristic.Previous work has either relied on crafted 3D human models or trained a separate model specifically for each target person, which is not scalable in practice.This work studies a more general setting, in which we aim to learn a single model to parsimoniously transfer motion from a source video to any target person given only one image of the person, named as Collaborative Parsing-Flow Network (CPF-Net). The paucity of information regarding the target person makes the task particularly challenging to faithfully preserve the appearance in varying designated poses. To address this issue, CPF-Net integrates the structured human parsing and appearance flow to guide the realistic foreground synthesis which is merged into the background by a spatio-temporal fusion module. In particular, CPF-Net decouples the problem into stages of human parsing sequence generation, foreground sequence generation and final video generation. The human parsing generation stage captures both the pose and the body structure of the target. The appearance flow is beneficial to keep details in synthesized frames. The integration of human parsing and appearance flow effectively guides the generation of video frames with realistic appearance. Finally, the dedicated designed fusion network ensure the temporal coherence. We further collect a large set of human dancing videos to push forward this research field. Both quantitative and qualitative results show our method substantially improves over previous approaches and is able to generate appealing and photo-realistic target videos given any input person image. All source code and dataset will be released at https://github.com/xiezhy6/CPF-Net.
Spatial Imagination With Semantic Cognition for Mobile Robots
Apr 08, 2021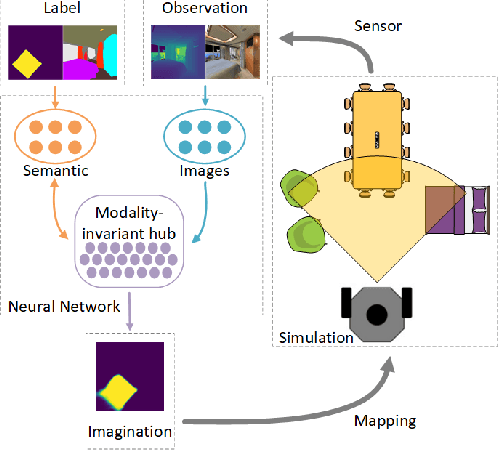
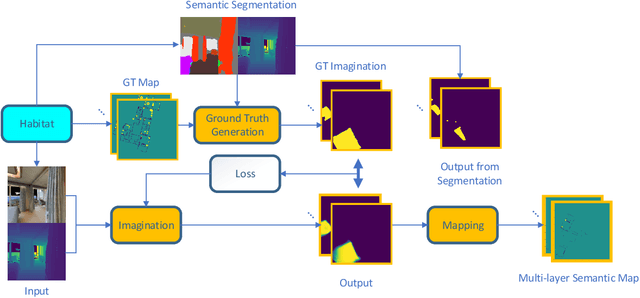

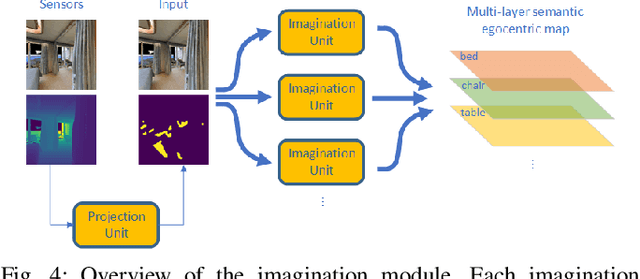
The imagination of the surrounding environment based on experience and semantic cognition has great potential to extend the limited observations and provide more information for mapping, collision avoidance, and path planning. This paper provides a training-based algorithm for mobile robots to perform spatial imagination based on semantic cognition and evaluates the proposed method for the mapping task. We utilize a photo-realistic simulation environment, Habitat, for training and evaluation. The trained model is composed of Resent-18 as encoder and Unet as the backbone. We demonstrate that the algorithm can perform imagination for unseen parts of the object universally, by recalling the images and experience and compare our approach with traditional semantic mapping methods. It is found that our approach will improve the efficiency and accuracy of semantic mapping.
VISITRON: Visual Semantics-Aligned Interactively Trained Object-Navigator
May 25, 2021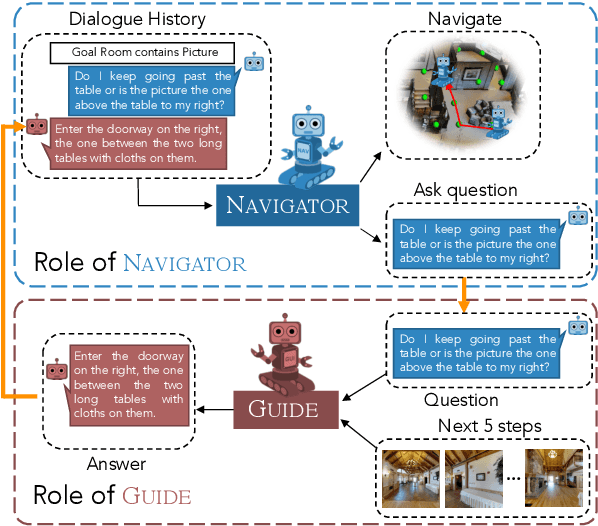
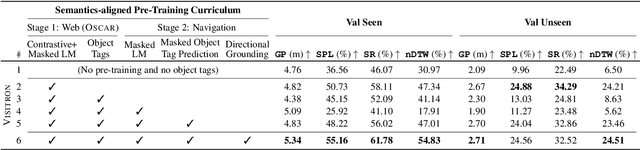
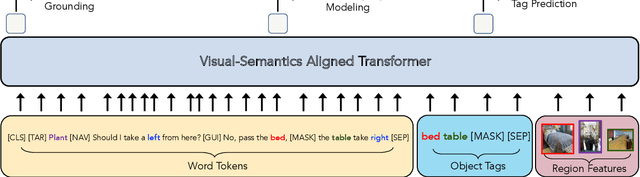
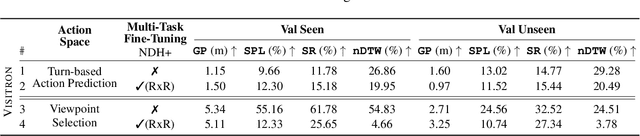
Interactive robots navigating photo-realistic environments face challenges underlying vision-and-language navigation (VLN), but in addition, they need to be trained to handle the dynamic nature of dialogue. However, research in Cooperative Vision-and-Dialog Navigation (CVDN), where a navigator interacts with a guide in natural language in order to reach a goal, treats the dialogue history as a VLN-style static instruction. In this paper, we present VISITRON, a navigator better suited to the interactive regime inherent to CVDN by being trained to: i) identify and associate object-level concepts and semantics between the environment and dialogue history, ii) identify when to interact vs. navigate via imitation learning of a binary classification head. We perform extensive ablations with VISITRON to gain empirical insights and improve performance on CVDN. VISITRON is competitive with models on the static CVDN leaderboard. We also propose a generalized interactive regime to fine-tune and evaluate VISITRON and future such models with pre-trained guides for adaptability.
CUDA-GR: Controllable Unsupervised Domain Adaptation for Gaze Redirection
Jun 21, 2021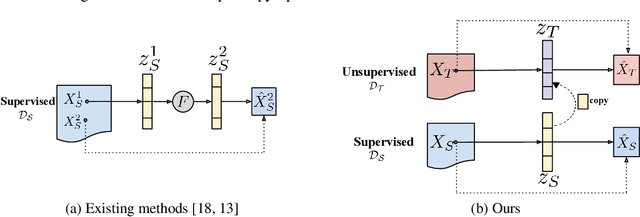
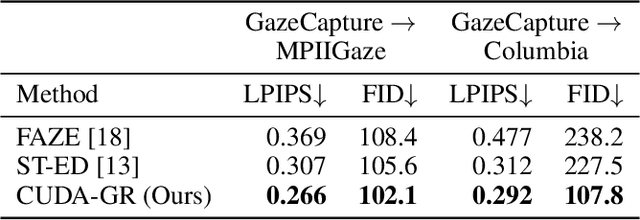
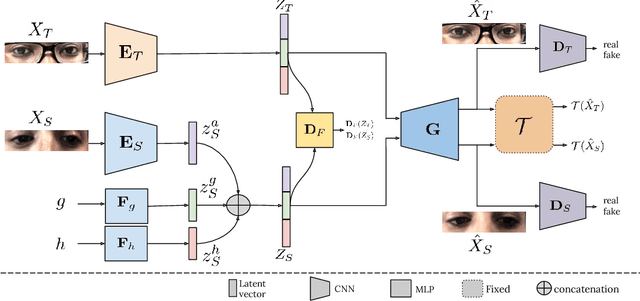

The aim of gaze redirection is to manipulate the gaze in an image to the desired direction. However, existing methods are inadequate in generating perceptually reasonable images. Advancement in generative adversarial networks has shown excellent results in generating photo-realistic images. Though, they still lack the ability to provide finer control over different image attributes. To enable such fine-tuned control, one needs to obtain ground truth annotations for the training data which can be very expensive. In this paper, we propose an unsupervised domain adaptation framework, called CUDA-GR, that learns to disentangle gaze representations from the labeled source domain and transfers them to an unlabeled target domain. Our method enables fine-grained control over gaze directions while preserving the appearance information of the person. We show that the generated image-labels pairs in the target domain are effective in knowledge transfer and can boost the performance of the downstream tasks. Extensive experiments on the benchmarking datasets show that the proposed method can outperform state-of-the-art techniques in both quantitative and qualitative evaluation.
Few-shot Neural Human Performance Rendering from Sparse RGBD Videos
Jul 14, 2021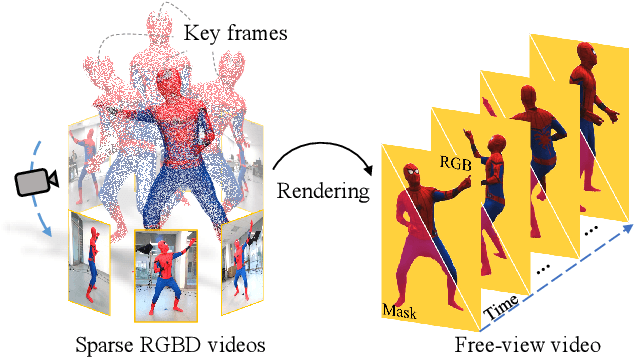
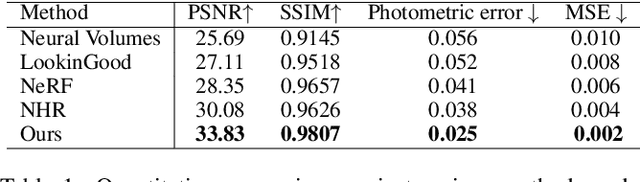
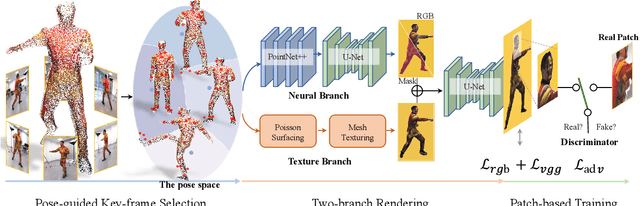
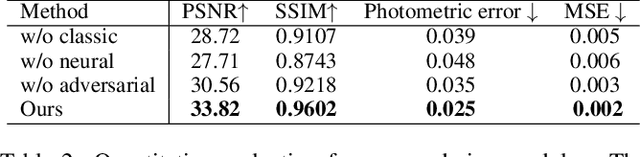
Recent neural rendering approaches for human activities achieve remarkable view synthesis results, but still rely on dense input views or dense training with all the capture frames, leading to deployment difficulty and inefficient training overload. However, existing advances will be ill-posed if the input is both spatially and temporally sparse. To fill this gap, in this paper we propose a few-shot neural human rendering approach (FNHR) from only sparse RGBD inputs, which exploits the temporal and spatial redundancy to generate photo-realistic free-view output of human activities. Our FNHR is trained only on the key-frames which expand the motion manifold in the input sequences. We introduce a two-branch neural blending to combine the neural point render and classical graphics texturing pipeline, which integrates reliable observations over sparse key-frames. Furthermore, we adopt a patch-based adversarial training process to make use of the local redundancy and avoids over-fitting to the key-frames, which generates fine-detailed rendering results. Extensive experiments demonstrate the effectiveness of our approach to generate high-quality free view-point results for challenging human performances under the sparse setting.
The Northumberland Dolphin Dataset: A Multimedia Individual Cetacean Dataset for Fine-Grained Categorisation
Aug 07, 2019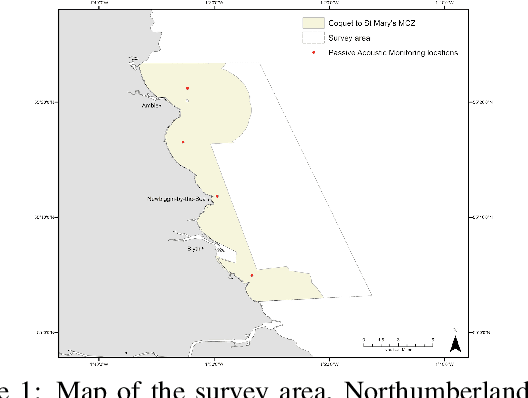
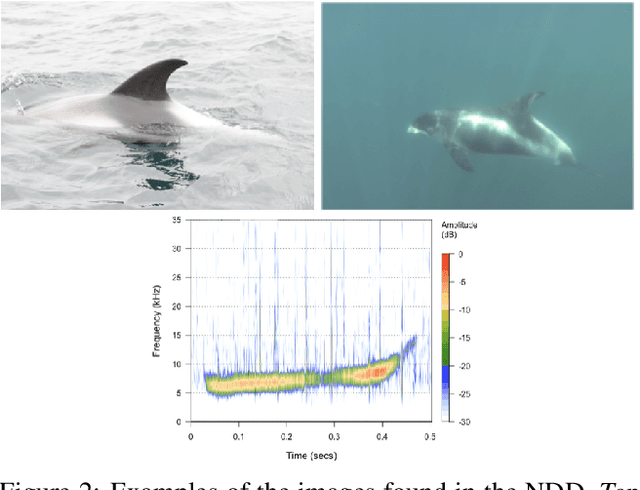


Methods for cetacean research include photo-identification (photo-id) and passive acoustic monitoring (PAM) which generate thousands of images per expedition that are currently hand categorised by researchers into the individual dolphins sighted. With the vast amount of data obtained it is crucially important to develop a system that is able to categorise this quickly. The Northumberland Dolphin Dataset (NDD) is an on-going novel dataset project made up of above and below water images of, and spectrograms of whistles from, white-beaked dolphins. These are produced by photo-id and PAM data collection methods applied off the coast of Northumberland, UK. This dataset will aid in building cetacean identification models, reducing the number of human-hours required to categorise images. Example use cases and areas identified for speed up are examined.