 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Semantic Photo Manipulation with a Generative Image Prior
May 15, 2020


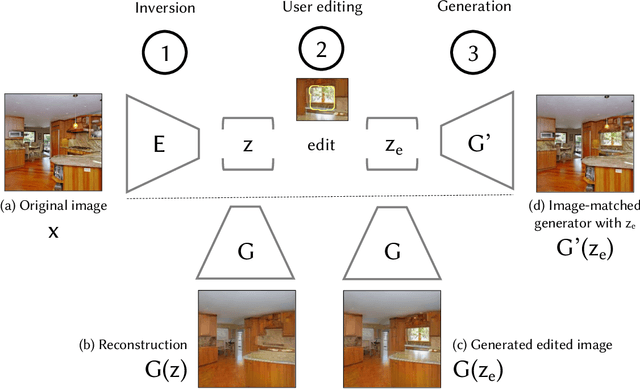
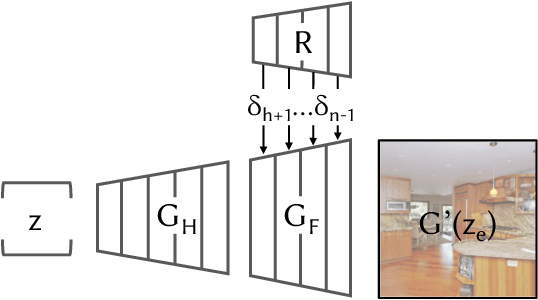
Despite the recent success of GANs in synthesizing images conditioned on inputs such as a user sketch, text, or semantic labels, manipulating the high-level attributes of an existing natural photograph with GANs is challenging for two reasons. First, it is hard for GANs to precisely reproduce an input image. Second, after manipulation, the newly synthesized pixels often do not fit the original image. In this paper, we address these issues by adapting the image prior learned by GANs to image statistics of an individual image. Our method can accurately reconstruct the input image and synthesize new content, consistent with the appearance of the input image. We demonstrate our interactive system on several semantic image editing tasks, including synthesizing new objects consistent with background, removing unwanted objects, and changing the appearance of an object. Quantitative and qualitative comparisons against several existing methods demonstrate the effectiveness of our method.
* SIGGRAPH 2019
Layout-to-Image Translation with Double Pooling Generative Adversarial Networks
Aug 29, 2021



In this paper, we address the task of layout-to-image translation, which aims to translate an input semantic layout to a realistic image. One open challenge widely observed in existing methods is the lack of effective semantic constraints during the image translation process, leading to models that cannot preserve the semantic information and ignore the semantic dependencies within the same object. To address this issue, we propose a novel Double Pooing GAN (DPGAN) for generating photo-realistic and semantically-consistent results from the input layout. We also propose a novel Double Pooling Module (DPM), which consists of the Square-shape Pooling Module (SPM) and the Rectangle-shape Pooling Module (RPM). Specifically, SPM aims to capture short-range semantic dependencies of the input layout with different spatial scales, while RPM aims to capture long-range semantic dependencies from both horizontal and vertical directions. We then effectively fuse both outputs of SPM and RPM to further enlarge the receptive field of our generator. Extensive experiments on five popular datasets show that the proposed DPGAN achieves better results than state-of-the-art methods. Finally, both SPM and SPM are general and can be seamlessly integrated into any GAN-based architectures to strengthen the feature representation. The code is available at https://github.com/Ha0Tang/DPGAN.
Exploring Visual Engagement Signals for Representation Learning
Apr 15, 2021
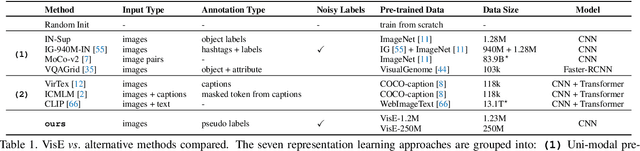
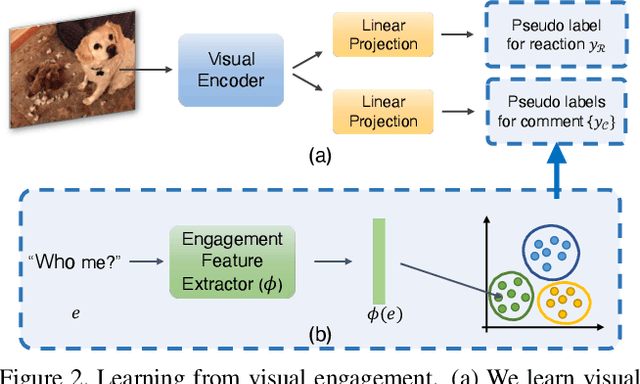
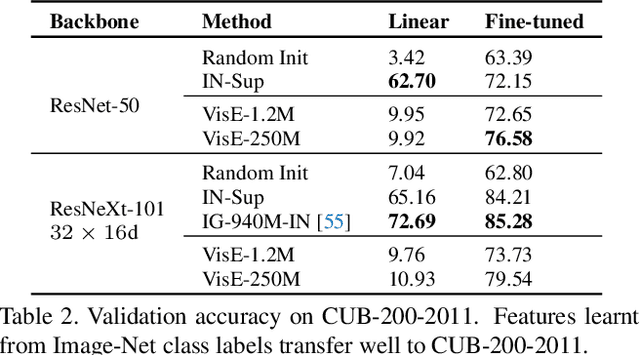
Visual engagement in social media platforms comprises interactions with photo posts including comments, shares, and likes. In this paper, we leverage such visual engagement clues as supervisory signals for representation learning. However, learning from engagement signals is non-trivial as it is not clear how to bridge the gap between low-level visual information and high-level social interactions. We present VisE, a weakly supervised learning approach, which maps social images to pseudo labels derived by clustered engagement signals. We then study how models trained in this way benefit subjective downstream computer vision tasks such as emotion recognition or political bias detection. Through extensive studies, we empirically demonstrate the effectiveness of VisE across a diverse set of classification tasks beyond the scope of conventional recognition.
A Survey on the Visual Perceptions of Gaussian Noise Filtering on Photography
Dec 18, 2020



Statisticians, as well as machine learning and computer vision experts, have been studying image reconstitution through denoising different domains of photography, such as textual documentation, tomographic, astronomical, and low-light photography. In this paper, we apply common inferential kernel filters in the R and python languages, as well as Adobe Lightroom's denoise filter, and compare their effectiveness in removing noise from JPEG images. We ran standard benchmark tests to evaluate each method's effectiveness for removing noise. In doing so, we also surveyed students at Elon University about their opinion of a single filtered photo from a collection of photos processed by the various filter methods. Many scientists believe that noise filters cause blurring and image quality loss so we analyzed whether or not people felt as though denoising causes any quality loss as compared to their noiseless images. Individuals assigned scores indicating the image quality of a denoised photo compared to its noiseless counterpart on a 1 to 10 scale. Survey scores are compared across filters to evaluate whether there were significant differences in image quality scores received. Benchmark scores were compared to the visual perception scores. Then, an analysis of covariance test was run to identify whether or not survey training scores explained any unplanned variation in visual scores assigned by students across the filter methods.
Iconify: Converting Photographs into Icons
Apr 07, 2020
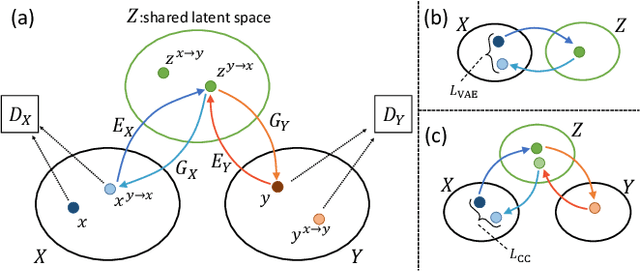

In this paper, we tackle a challenging domain conversion task between photo and icon images. Although icons often originate from real object images (i.e., photographs), severe abstractions and simplifications are applied to generate icon images by professional graphic designers. Moreover, there is no one-to-one correspondence between the two domains, for this reason we cannot use it as the ground-truth for learning a direct conversion function. Since generative adversarial networks (GAN) can undertake the problem of domain conversion without any correspondence, we test CycleGAN and UNIT to generate icons from objects segmented from photo images. Our experiments with several image datasets prove that CycleGAN learns sufficient abstraction and simplification ability to generate icon-like images.
Vision-Only Robot Navigation in a Neural Radiance World
Oct 01, 2021
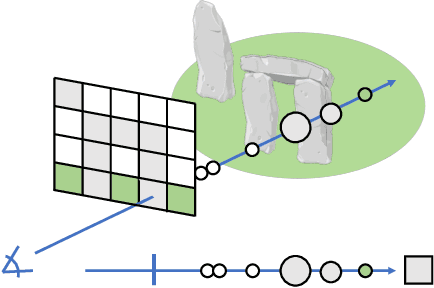
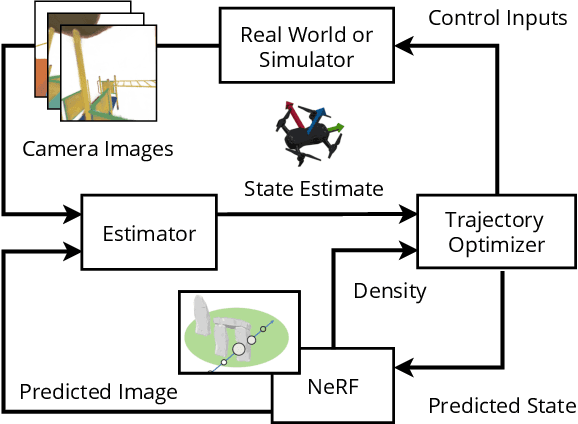
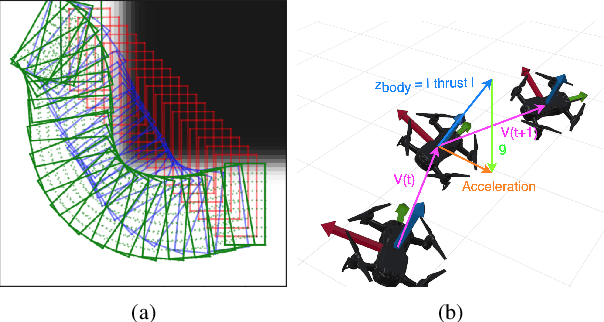
Neural Radiance Fields (NeRFs) have recently emerged as a powerful paradigm for the representation of natural, complex 3D scenes. NeRFs represent continuous volumetric density and RGB values in a neural network, and generate photo-realistic images from unseen camera viewpoints through ray tracing. We propose an algorithm for navigating a robot through a 3D environment represented as a NeRF using only an on-board RGB camera for localization. We assume the NeRF for the scene has been pre-trained offline, and the robot's objective is to navigate through unoccupied space in the NeRF to reach a goal pose. We introduce a trajectory optimization algorithm that avoids collisions with high-density regions in the NeRF based on a discrete time version of differential flatness that is amenable to constraining the robot's full pose and control inputs. We also introduce an optimization based filtering method to estimate 6DoF pose and velocities for the robot in the NeRF given only an onboard RGB camera. We combine the trajectory planner with the pose filter in an online replanning loop to give a vision-based robot navigation pipeline. We present simulation results with a quadrotor robot navigating through a jungle gym environment, the inside of a church, and Stonehenge using only an RGB camera. We also demonstrate an omnidirectional ground robot navigating through the church, requiring it to reorient to fit through the narrow gap. Videos of this work can be found at https://mikh3x4.github.io/nerf-navigation/ .
SinIR: Efficient General Image Manipulation with Single Image Reconstruction
Jun 14, 2021

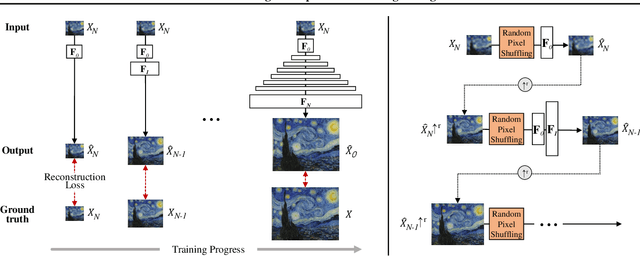
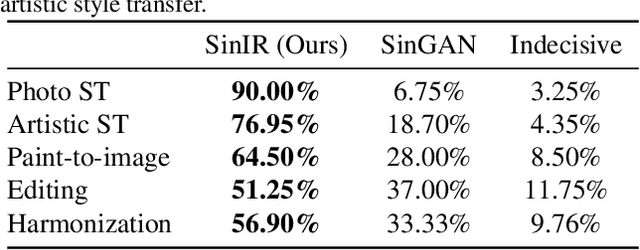
We propose SinIR, an efficient reconstruction-based framework trained on a single natural image for general image manipulation, including super-resolution, editing, harmonization, paint-to-image, photo-realistic style transfer, and artistic style transfer. We train our model on a single image with cascaded multi-scale learning, where each network at each scale is responsible for image reconstruction. This reconstruction objective greatly reduces the complexity and running time of training, compared to the GAN objective. However, the reconstruction objective also exacerbates the output quality. Therefore, to solve this problem, we further utilize simple random pixel shuffling, which also gives control over manipulation, inspired by the Denoising Autoencoder. With quantitative evaluation, we show that SinIR has competitive performance on various image manipulation tasks. Moreover, with a much simpler training objective (i.e., reconstruction), SinIR is trained 33.5 times faster than SinGAN (for 500 X 500 images) that solves similar tasks. Our code is publicly available at github.com/YooJiHyeong/SinIR.
Reconstructing NBA Players
Jul 27, 2020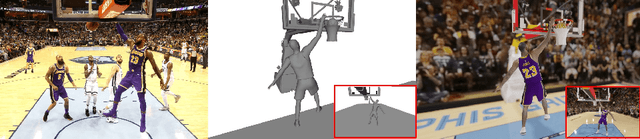

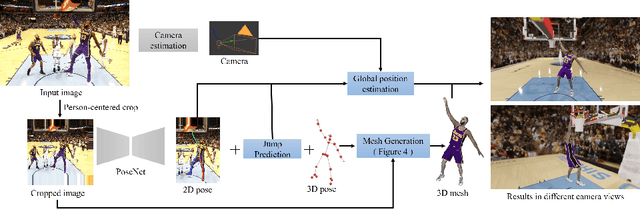

Great progress has been made in 3D body pose and shape estimation from a single photo. Yet, state-of-the-art results still suffer from errors due to challenging body poses, modeling clothing, and self occlusions. The domain of basketball games is particularly challenging, as it exhibits all of these challenges. In this paper, we introduce a new approach for reconstruction of basketball players that outperforms the state-of-the-art. Key to our approach is a new method for creating poseable, skinned models of NBA players, and a large database of meshes (derived from the NBA2K19 video game), that we are releasing to the research community. Based on these models, we introduce a new method that takes as input a single photo of a clothed player in any basketball pose and outputs a high resolution mesh and 3D pose for that player. We demonstrate substantial improvement over state-of-the-art, single-image methods for body shape reconstruction.
Identifying Human Edited Images using a CNN
Jan 09, 2021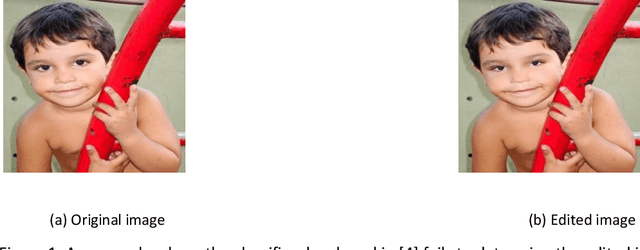
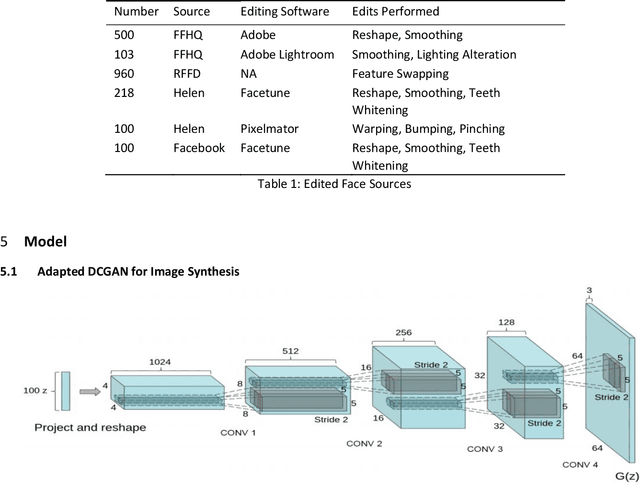
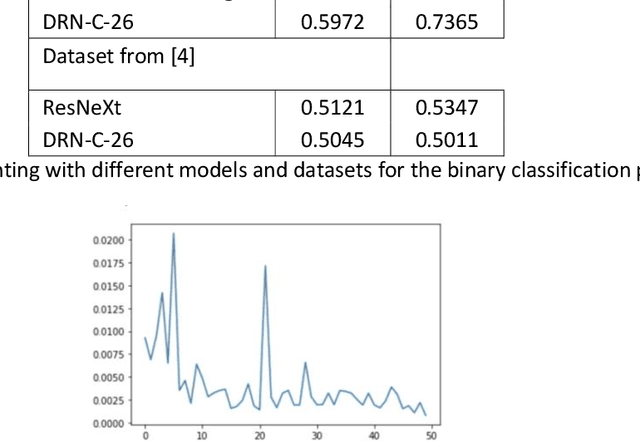

Most non-professional photo manipulations are not made using propriety software like Adobe Photoshop, which is expensive and complicated to use for the average consumer selfie-taker or meme-maker. Instead, these individuals opt for user friendly mobile applications like FaceTune and Pixlr to make human face edits and alterations. Unfortunately, there is no existing dataset to train a model to classify these type of manipulations. In this paper, we present a generative model that approximates the distribution of human face edits and a method for detecting Facetune and Pixlr manipulations to human faces.
Identifying Hijacked Reviews
Jul 07, 2021


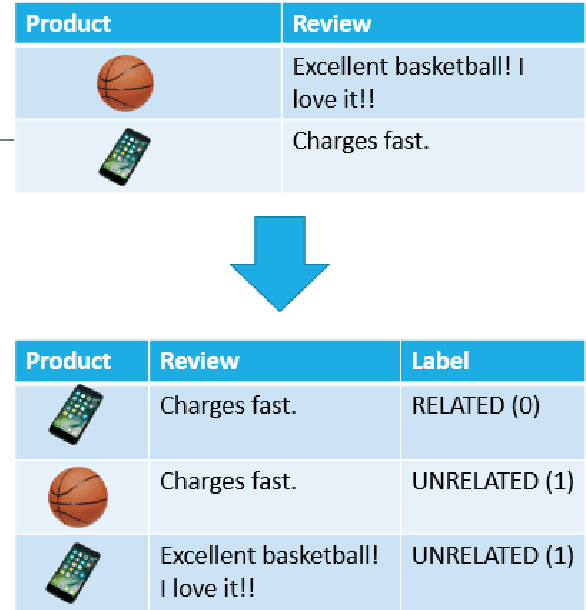
Fake reviews and review manipulation are growing problems on online marketplaces globally. Review Hijacking is a new review manipulation tactic in which unethical sellers "hijack" an existing product page (usually one with many positive reviews), then update the product details like title, photo, and description with those of an entirely different product. With the earlier reviews still attached, the new item appears well-reviewed. However, there are no public datasets of review hijacking and little is known in the literature about this tactic. Hence, this paper proposes a three-part study: (i) we propose a framework to generate synthetically labeled data for review hijacking by swapping products and reviews; (ii) then, we evaluate the potential of both a Twin LSTM network and BERT sequence pair classifier to distinguish legitimate reviews from hijacked ones using this data; and (iii) we then deploy the best performing model on a collection of 31K products (with 6.5 M reviews) in the original data, where we find 100s of previously unknown examples of review hijacking.