 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Foveal-pit inspired filtering of DVS spike response
May 29, 2021
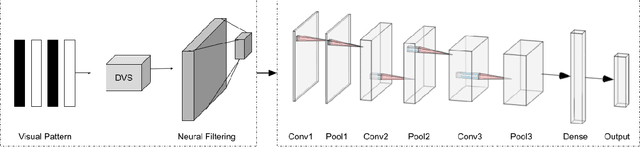
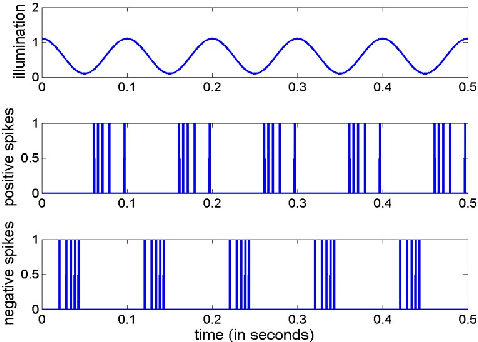

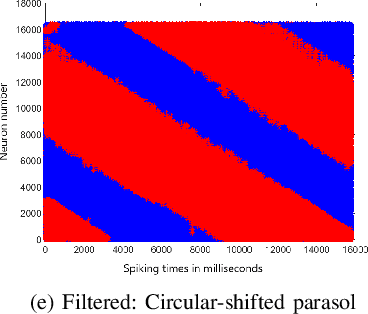
In this paper, we present results of processing Dynamic Vision Sensor (DVS) recordings of visual patterns with a retinal model based on foveal-pit inspired Difference of Gaussian (DoG) filters. A DVS sensor was stimulated with varying number of vertical white and black bars of different spatial frequencies moving horizontally at a constant velocity. The output spikes generated by the DVS sensor were applied as input to a set of DoG filters inspired by the receptive field structure of the primate visual pathway. In particular, these filters mimic the receptive fields of the midget and parasol ganglion cells (spiking neurons of the retina) that sub-serve the photo-receptors of the foveal-pit. The features extracted with the foveal-pit model are used for further classification using a spiking convolutional neural network trained with a backpropagation variant adapted for spiking neural networks.
Calliar: An Online Handwritten Dataset for Arabic Calligraphy
Jun 25, 2021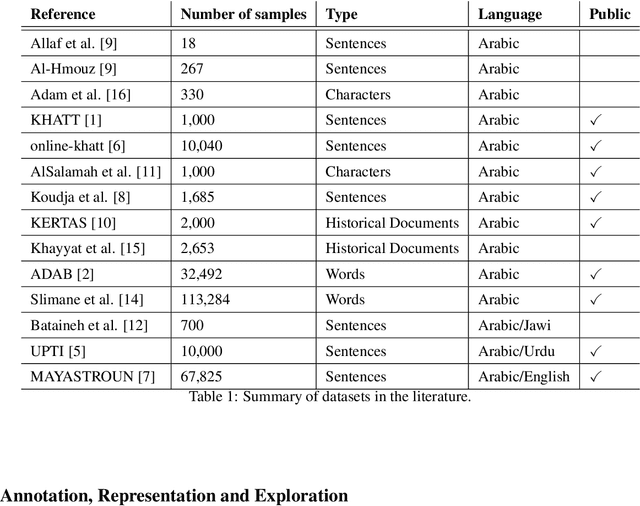

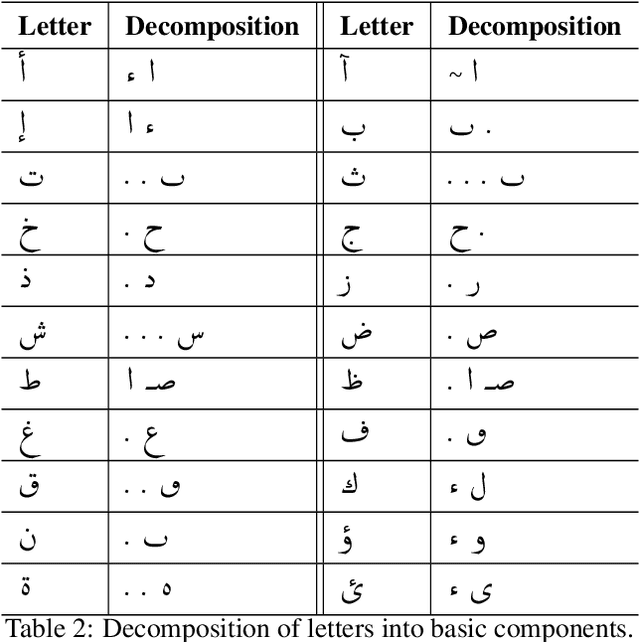

Calligraphy is an essential part of the Arabic heritage and culture. It has been used in the past for the decoration of houses and mosques. Usually, such calligraphy is designed manually by experts with aesthetic insights. In the past few years, there has been a considerable effort to digitize such type of art by either taking a photo of decorated buildings or drawing them using digital devices. The latter is considered an online form where the drawing is tracked by recording the apparatus movement, an electronic pen for instance, on a screen. In the literature, there are many offline datasets collected with a diversity of Arabic styles for calligraphy. However, there is no available online dataset for Arabic calligraphy. In this paper, we illustrate our approach for the collection and annotation of an online dataset for Arabic calligraphy called Calliar that consists of 2,500 sentences. Calliar is annotated for stroke, character, word and sentence level prediction.
Animatable Neural Radiance Fields from Monocular RGB Video
Jun 25, 2021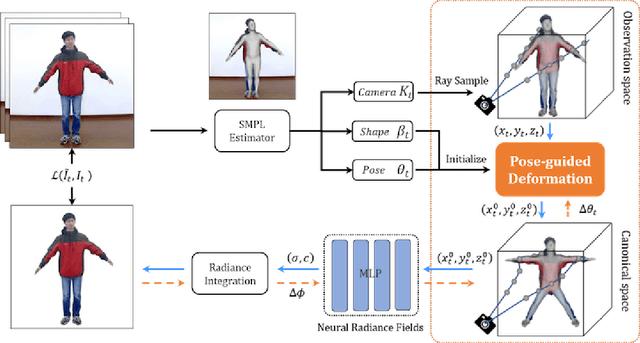
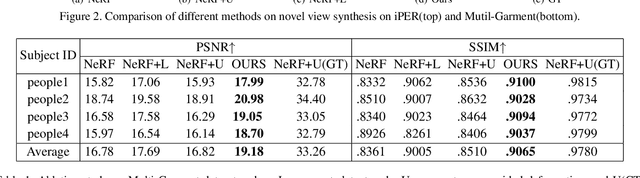


We present animatable neural radiance fields for detailed human avatar creation from monocular videos. Our approach extends neural radiance fields (NeRF) to the dynamic scenes with human movements via introducing explicit pose-guided deformation while learning the scene representation network. In particular, we estimate the human pose for each frame and learn a constant canonical space for the detailed human template, which enables natural shape deformation from the observation space to the canonical space under the explicit control of the pose parameters. To compensate for inaccurate pose estimation, we introduce the pose refinement strategy that updates the initial pose during the learning process, which not only helps to learn more accurate human reconstruction but also accelerates the convergence. In experiments we show that the proposed approach achieves 1) implicit human geometry and appearance reconstruction with high-quality details, 2) photo-realistic rendering of the human from arbitrary views, and 3) animation of the human with arbitrary poses.
UMFA: A photorealistic style transfer method based on U-Net and multi-layer feature aggregation
Aug 13, 2021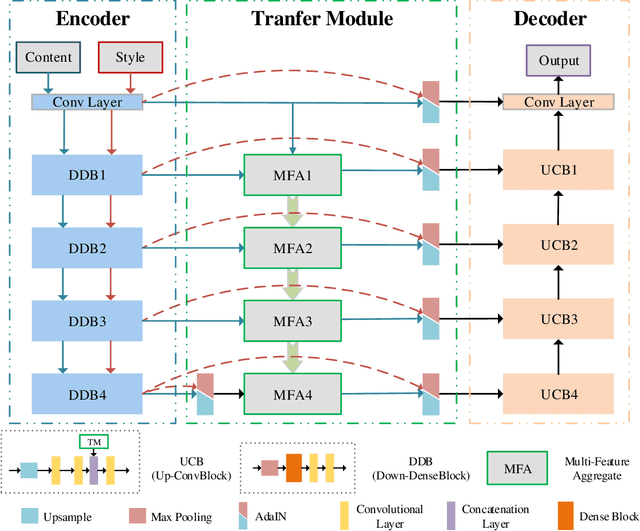

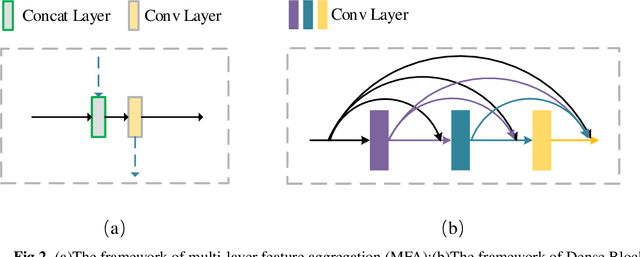

In this paper, we propose a photorealistic style transfer network to emphasize the natural effect of photorealistic image stylization. In general, distortion of the image content and lacking of details are two typical issues in the style transfer field. To this end, we design a novel framework employing the U-Net structure to maintain the rich spatial clues, with a multi-layer feature aggregation (MFA) method to simultaneously provide the details obtained by the shallow layers in the stylization processing. In particular, an encoder based on the dense block and a decoder form a symmetrical structure of U-Net are jointly staked to realize an effective feature extraction and image reconstruction. Besides, a transfer module based on MFA and "adaptive instance normalization" (AdaIN) is inserted in the skip connection positions to achieve the stylization. Accordingly, the stylized image possesses the texture of a real photo and preserves rich content details without introducing any mask or post-processing steps. The experimental results on public datasets demonstrate that our method achieves a more faithful structural similarity with a lower style loss, reflecting the effectiveness and merit of our approach.
S2FGAN: Semantically Aware Interactive Sketch-to-Face Translation
Nov 30, 2020
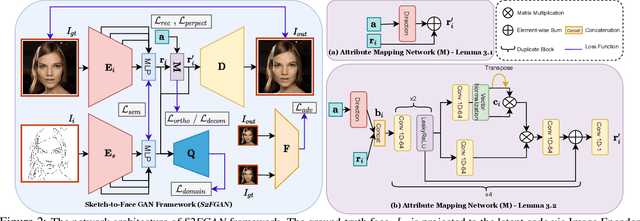
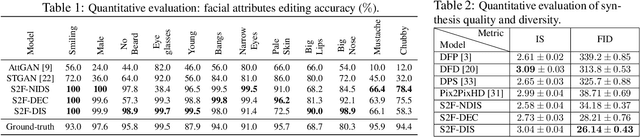

Interactive facial image manipulation attempts to edit single and multiple face attributes using a photo-realistic face and/or semantic mask as input. In the absence of the photo-realistic image (only sketch/mask available), previous methods only retrieve the original face but ignore the potential of aiding model controllability and diversity in the translation process. This paper proposes a sketch-to-image generation framework called S2FGAN, aiming to improve users' ability to interpret and flexibility of face attribute editing from a simple sketch. The proposed framework modifies the constrained latent space semantics trained on Generative Adversarial Networks (GANs). We employ two latent spaces to control the face appearance and adjust the desired attributes of the generated face. Instead of constraining the translation process by using a reference image, the users can command the model to retouch the generated images by involving the semantic information in the generation process. In this way, our method can manipulate single or multiple face attributes by only specifying attributes to be changed. Extensive experimental results on CelebAMask-HQ dataset empirically shows our superior performance and effectiveness on this task. Our method successfully outperforms state-of-the-art methods on attribute manipulation by exploiting greater control of attribute intensity.
Collaborative Visual Navigation
Jul 20, 2021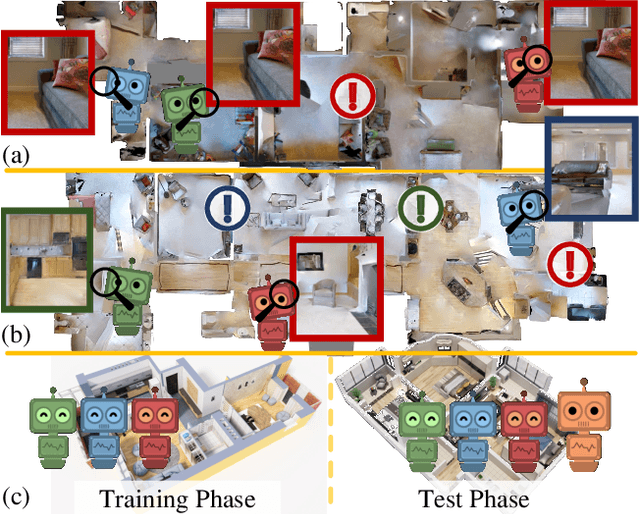
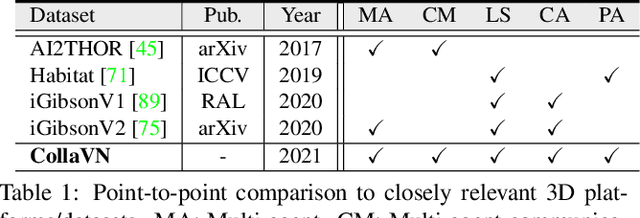
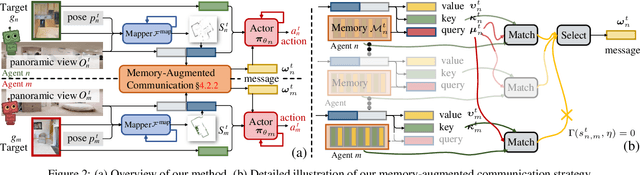
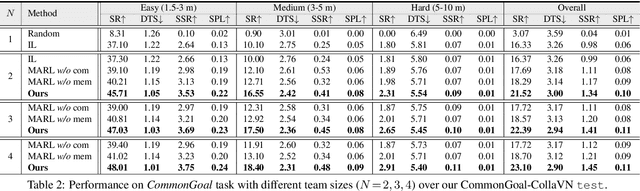
As a fundamental problem for Artificial Intelligence, multi-agent system (MAS) is making rapid progress, mainly driven by multi-agent reinforcement learning (MARL) techniques. However, previous MARL methods largely focused on grid-world like or game environments; MAS in visually rich environments has remained less explored. To narrow this gap and emphasize the crucial role of perception in MAS, we propose a large-scale 3D dataset, CollaVN, for multi-agent visual navigation (MAVN). In CollaVN, multiple agents are entailed to cooperatively navigate across photo-realistic environments to reach target locations. Diverse MAVN variants are explored to make our problem more general. Moreover, a memory-augmented communication framework is proposed. Each agent is equipped with a private, external memory to persistently store communication information. This allows agents to make better use of their past communication information, enabling more efficient collaboration and robust long-term planning. In our experiments, several baselines and evaluation metrics are designed. We also empirically verify the efficacy of our proposed MARL approach across different MAVN task settings.
Hierarchical Conditional Flow: A Unified Framework for Image Super-Resolution and Image Rescaling
Aug 11, 2021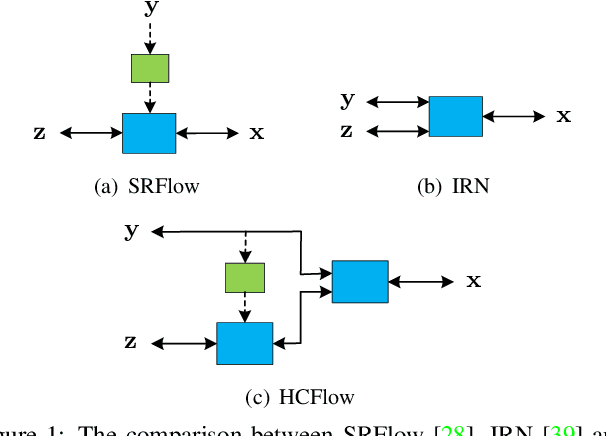

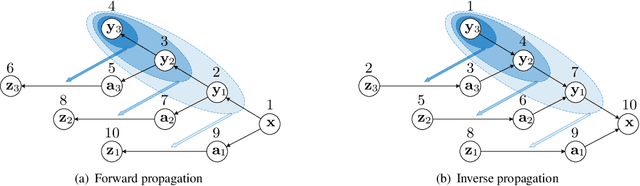
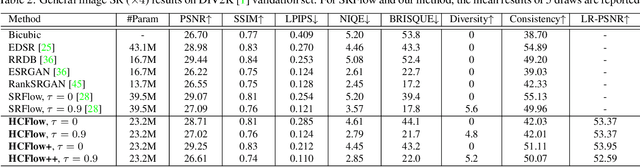
Normalizing flows have recently demonstrated promising results for low-level vision tasks. For image super-resolution (SR), it learns to predict diverse photo-realistic high-resolution (HR) images from the low-resolution (LR) image rather than learning a deterministic mapping. For image rescaling, it achieves high accuracy by jointly modelling the downscaling and upscaling processes. While existing approaches employ specialized techniques for these two tasks, we set out to unify them in a single formulation. In this paper, we propose the hierarchical conditional flow (HCFlow) as a unified framework for image SR and image rescaling. More specifically, HCFlow learns a bijective mapping between HR and LR image pairs by modelling the distribution of the LR image and the rest high-frequency component simultaneously. In particular, the high-frequency component is conditional on the LR image in a hierarchical manner. To further enhance the performance, other losses such as perceptual loss and GAN loss are combined with the commonly used negative log-likelihood loss in training. Extensive experiments on general image SR, face image SR and image rescaling have demonstrated that the proposed HCFlow achieves state-of-the-art performance in terms of both quantitative metrics and visual quality.
Layout-to-Image Translation with Double Pooling Generative Adversarial Networks
Aug 29, 2021



In this paper, we address the task of layout-to-image translation, which aims to translate an input semantic layout to a realistic image. One open challenge widely observed in existing methods is the lack of effective semantic constraints during the image translation process, leading to models that cannot preserve the semantic information and ignore the semantic dependencies within the same object. To address this issue, we propose a novel Double Pooing GAN (DPGAN) for generating photo-realistic and semantically-consistent results from the input layout. We also propose a novel Double Pooling Module (DPM), which consists of the Square-shape Pooling Module (SPM) and the Rectangle-shape Pooling Module (RPM). Specifically, SPM aims to capture short-range semantic dependencies of the input layout with different spatial scales, while RPM aims to capture long-range semantic dependencies from both horizontal and vertical directions. We then effectively fuse both outputs of SPM and RPM to further enlarge the receptive field of our generator. Extensive experiments on five popular datasets show that the proposed DPGAN achieves better results than state-of-the-art methods. Finally, both SPM and SPM are general and can be seamlessly integrated into any GAN-based architectures to strengthen the feature representation. The code is available at https://github.com/Ha0Tang/DPGAN.
Exploring Visual Engagement Signals for Representation Learning
Apr 15, 2021
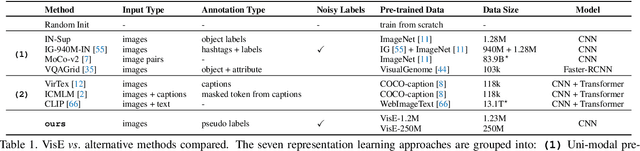
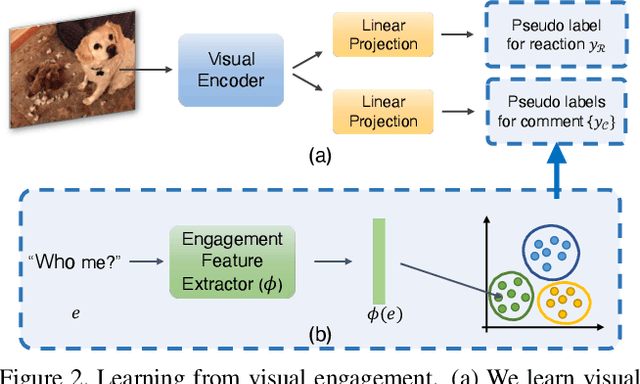
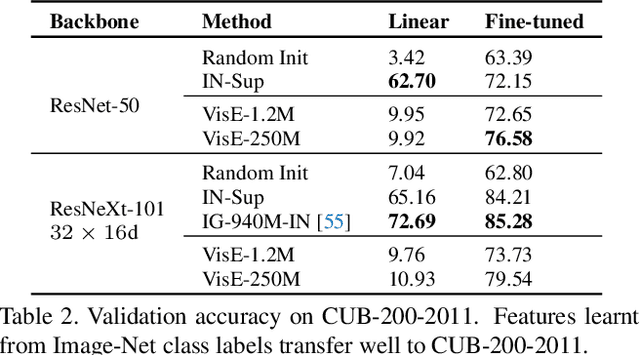
Visual engagement in social media platforms comprises interactions with photo posts including comments, shares, and likes. In this paper, we leverage such visual engagement clues as supervisory signals for representation learning. However, learning from engagement signals is non-trivial as it is not clear how to bridge the gap between low-level visual information and high-level social interactions. We present VisE, a weakly supervised learning approach, which maps social images to pseudo labels derived by clustered engagement signals. We then study how models trained in this way benefit subjective downstream computer vision tasks such as emotion recognition or political bias detection. Through extensive studies, we empirically demonstrate the effectiveness of VisE across a diverse set of classification tasks beyond the scope of conventional recognition.