 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Instance-Conditioned GAN
Sep 10, 2021
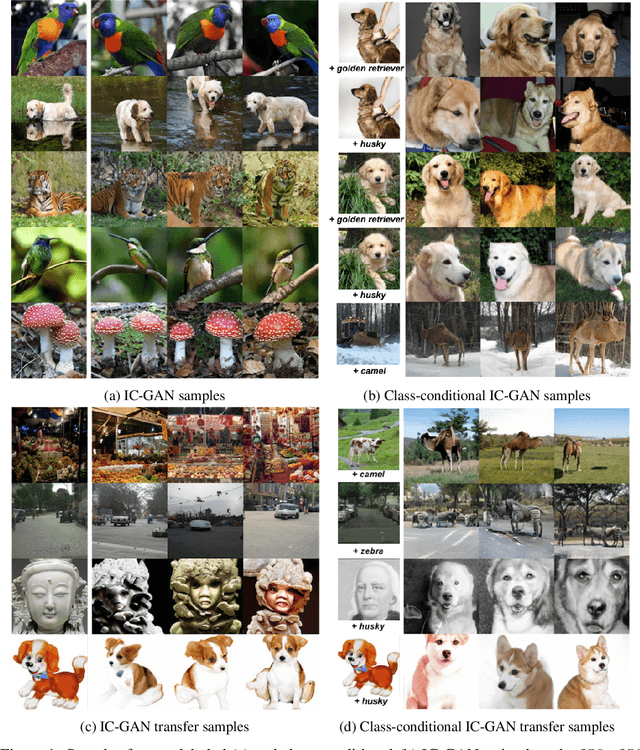
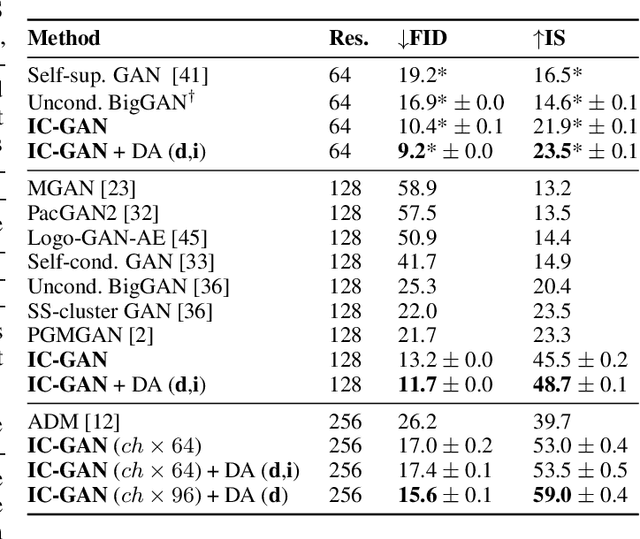
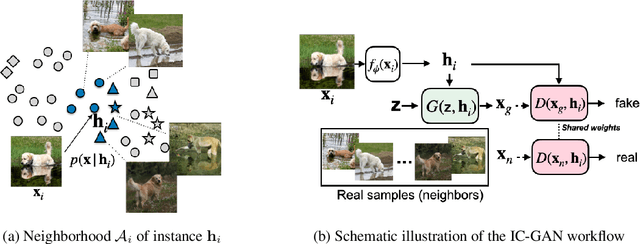
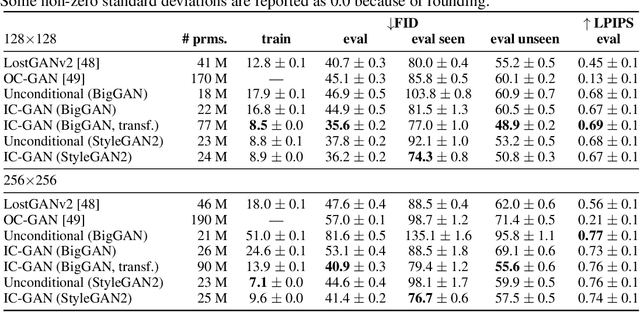
Generative Adversarial Networks (GANs) can generate near photo realistic images in narrow domains such as human faces. Yet, modeling complex distributions of datasets such as ImageNet and COCO-Stuff remains challenging in unconditional settings. In this paper, we take inspiration from kernel density estimation techniques and introduce a non-parametric approach to modeling distributions of complex datasets. We partition the data manifold into a mixture of overlapping neighborhoods described by a datapoint and its nearest neighbors, and introduce a model, called instance-conditioned GAN (IC-GAN), which learns the distribution around each datapoint. Experimental results on ImageNet and COCO-Stuff show that IC-GAN significantly improves over unconditional models and unsupervised data partitioning baselines. Moreover, we show that IC-GAN can effortlessly transfer to datasets not seen during training by simply changing the conditioning instances, and still generate realistic images. Finally, we extend IC-GAN to the class-conditional case and show semantically controllable generation and competitive quantitative results on ImageNet; while improving over BigGAN on ImageNet-LT. We will opensource our code and trained models to reproduce the reported results.
Indoor Semantic Scene Understanding using Multi-modality Fusion
Aug 17, 2021
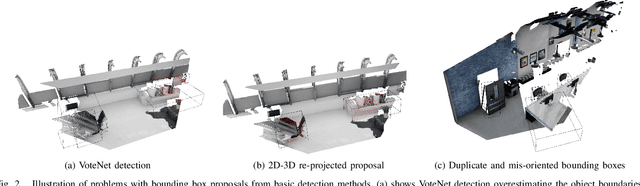

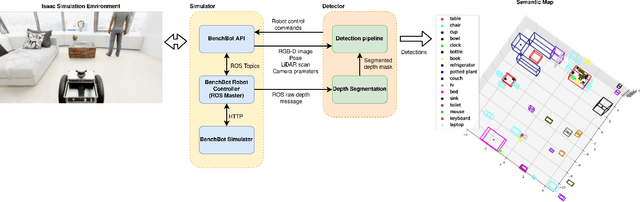
Seamless Human-Robot Interaction is the ultimate goal of developing service robotic systems. For this, the robotic agents have to understand their surroundings to better complete a given task. Semantic scene understanding allows a robotic agent to extract semantic knowledge about the objects in the environment. In this work, we present a semantic scene understanding pipeline that fuses 2D and 3D detection branches to generate a semantic map of the environment. The 2D mask proposals from state-of-the-art 2D detectors are inverse-projected to the 3D space and combined with 3D detections from point segmentation networks. Unlike previous works that were evaluated on collected datasets, we test our pipeline on an active photo-realistic robotic environment - BenchBot. Our novelty includes rectification of 3D proposals using projected 2D detections and modality fusion based on object size. This work is done as part of the Robotic Vision Scene Understanding Challenge (RVSU). The performance evaluation demonstrates that our pipeline has improved on baseline methods without significant computational bottleneck.
Perceptual Learned Video Compression with Recurrent Conditional GAN
Sep 09, 2021

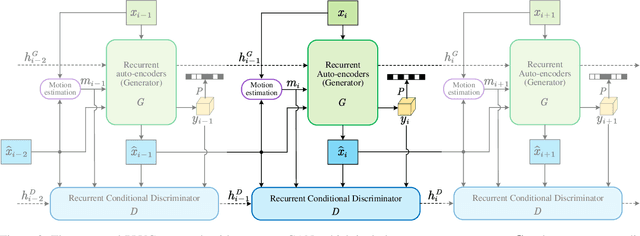
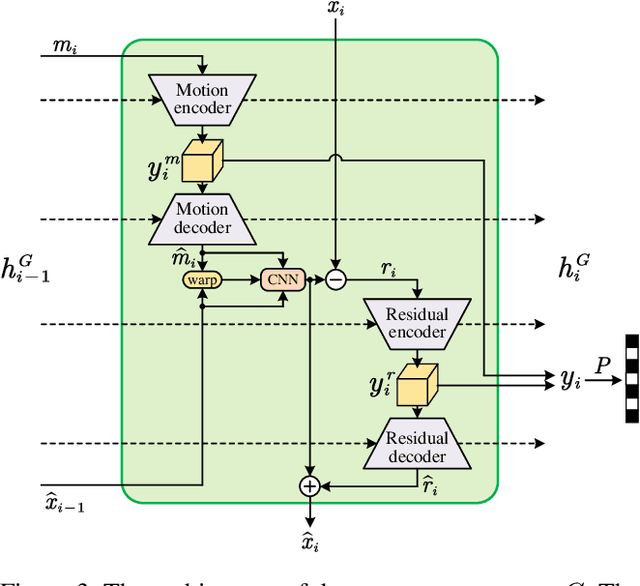
This paper proposes a Perceptual Learned Video Compression (PLVC) approach with recurrent conditional generative adversarial network. In our approach, the recurrent auto-encoder-based generator learns to fully explore the temporal correlation for compressing video. More importantly, we propose a recurrent conditional discriminator, which judges raw and compressed video conditioned on both spatial and temporal information, including the latent representation, temporal motion and hidden states in recurrent cells. This way, in the adversarial training, it pushes the generated video to be not only spatially photo-realistic but also temporally consistent with groundtruth and coherent among video frames. The experimental results show that the proposed PLVC model learns to compress video towards good perceptual quality at low bit-rate, and outperforms the previous traditional and learned approaches on several perceptual quality metrics. The user study further validates the outstanding perceptual performance of PLVC in comparison with the latest learned video compression approaches and the official HEVC test model (HM 16.20). The codes will be released at https://github.com/RenYang-home/PLVC.
Shuffled Patch-Wise Supervision for Presentation Attack Detection
Sep 09, 2021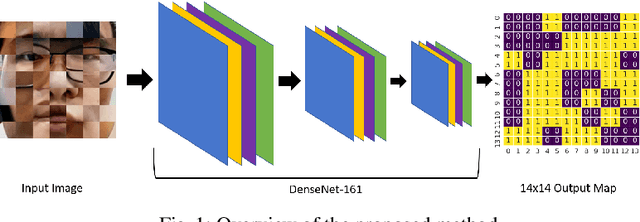
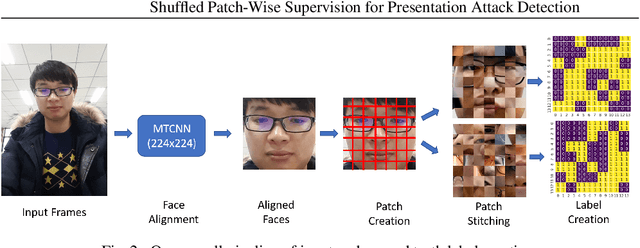

Face anti-spoofing is essential to prevent false facial verification by using a photo, video, mask, or a different substitute for an authorized person's face. Most of the state-of-the-art presentation attack detection (PAD) systems suffer from overfitting, where they achieve near-perfect scores on a single dataset but fail on a different dataset with more realistic data. This problem drives researchers to develop models that perform well under real-world conditions. This is an especially challenging problem for frame-based presentation attack detection systems that use convolutional neural networks (CNN). To this end, we propose a new PAD approach, which combines pixel-wise binary supervision with patch-based CNN. We believe that training a CNN with face patches allows the model to distinguish spoofs without learning background or dataset-specific traces. We tested the proposed method both on the standard benchmark datasets -- Replay-Mobile, OULU-NPU -- and on a real-world dataset. The proposed approach shows its superiority on challenging experimental setups. Namely, it achieves higher performance on OULU-NPU protocol 3, 4 and on inter-dataset real-world experiments.
A comparison study of CNN denoisers on PRNU extraction
Dec 06, 2021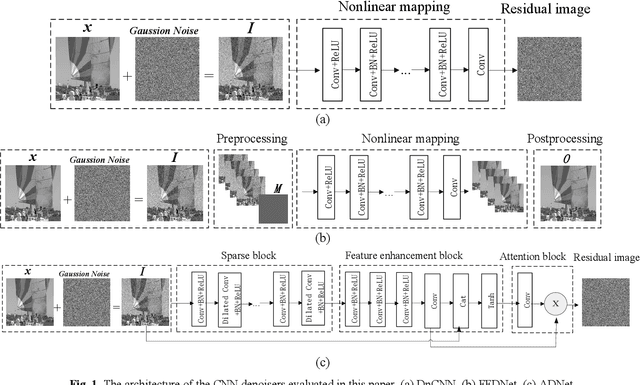
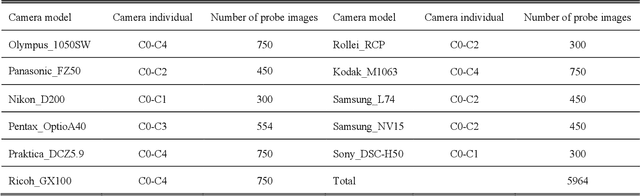
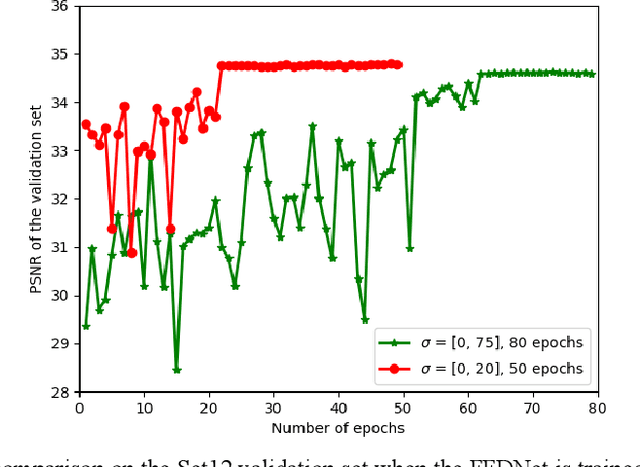
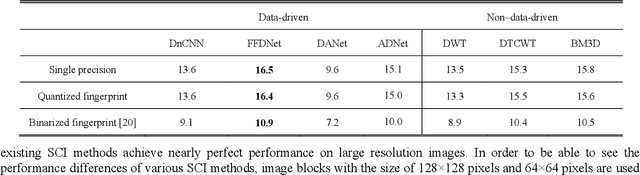
Performance of the sensor-based camera identification (SCI) method heavily relies on the denoising filter in estimating Photo-Response Non-Uniformity (PRNU). Given various attempts on enhancing the quality of the extracted PRNU, it still suffers from unsatisfactory performance in low-resolution images and high computational demand. Leveraging the similarity of PRNU estimation and image denoising, we take advantage of the latest achievements of Convolutional Neural Network (CNN)-based denoisers for PRNU extraction. In this paper, a comparative evaluation of such CNN denoisers on SCI performance is carried out on the public "Dresden Image Database". Our findings are two-fold. From one aspect, both the PRNU extraction and image denoising separate noise from the image content. Hence, SCI can benefit from the recent CNN denoisers if carefully trained. From another aspect, the goals and the scenarios of PRNU extraction and image denoising are different since one optimizes the quality of noise and the other optimizes the image quality. A carefully tailored training is needed when CNN denoisers are used for PRNU estimation. Alternative strategies of training data preparation and loss function design are analyzed theoretically and evaluated experimentally. We point out that feeding the CNNs with image-PRNU pairs and training them with correlation-based loss function result in the best PRNU estimation performance. To facilitate further studies of SCI, we also propose a minimum-loss camera fingerprint quantization scheme using which we save the fingerprints as image files in PNG format. Furthermore, we make the quantized fingerprints of the cameras from the "Dresden Image Database" publicly available.
ClevrTex: A Texture-Rich Benchmark for Unsupervised Multi-Object Segmentation
Nov 19, 2021


There has been a recent surge in methods that aim to decompose and segment scenes into multiple objects in an unsupervised manner, i.e., unsupervised multi-object segmentation. Performing such a task is a long-standing goal of computer vision, offering to unlock object-level reasoning without requiring dense annotations to train segmentation models. Despite significant progress, current models are developed and trained on visually simple scenes depicting mono-colored objects on plain backgrounds. The natural world, however, is visually complex with confounding aspects such as diverse textures and complicated lighting effects. In this study, we present a new benchmark called ClevrTex, designed as the next challenge to compare, evaluate and analyze algorithms. ClevrTex features synthetic scenes with diverse shapes, textures and photo-mapped materials, created using physically based rendering techniques. It includes 50k examples depicting 3-10 objects arranged on a background, created using a catalog of 60 materials, and a further test set featuring 10k images created using 25 different materials. We benchmark a large set of recent unsupervised multi-object segmentation models on ClevrTex and find all state-of-the-art approaches fail to learn good representations in the textured setting, despite impressive performance on simpler data. We also create variants of the ClevrTex dataset, controlling for different aspects of scene complexity, and probe current approaches for individual shortcomings. Dataset and code are available at https://www.robots.ox.ac.uk/~vgg/research/clevrtex.
Diamond in the rough: Improving image realism by traversing the GAN latent space
Apr 12, 2021
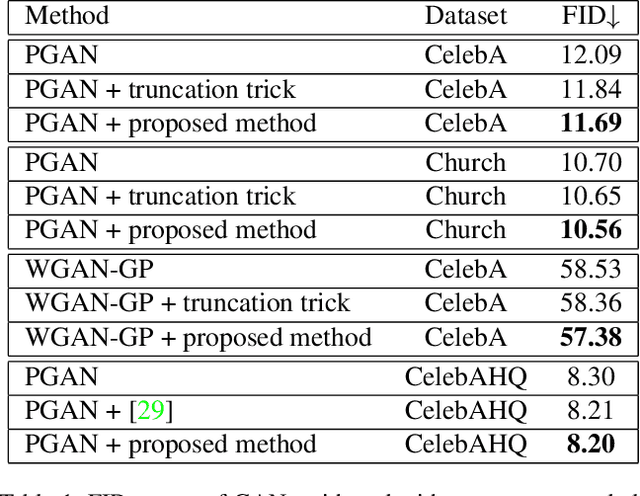
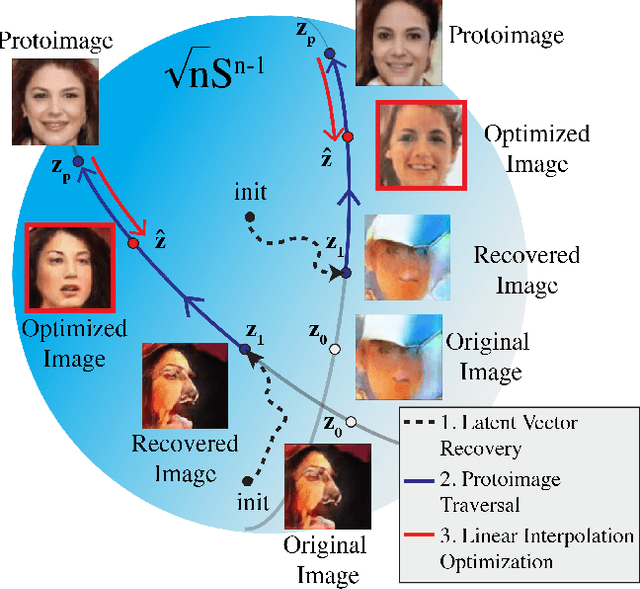
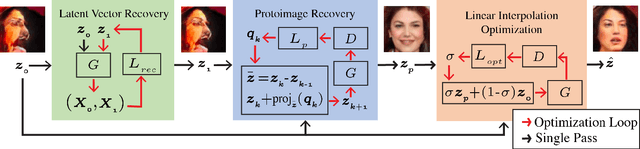
In just a few years, the photo-realism of images synthesized by Generative Adversarial Networks (GANs) has gone from somewhat reasonable to almost perfect largely by increasing the complexity of the networks, e.g., adding layers, intermediate latent spaces, style-transfer parameters, etc. This trajectory has led many of the state-of-the-art GANs to be inaccessibly large, disengaging many without large computational resources. Recognizing this, we explore a method for squeezing additional performance from existing, low-complexity GANs. Formally, we present an unsupervised method to find a direction in the latent space that aligns with improved photo-realism. Our approach leaves the network unchanged while enhancing the fidelity of the generated image. We use a simple generator inversion to find the direction in the latent space that results in the smallest change in the image space. Leveraging the learned structure of the latent space, we find moving in this direction corrects many image artifacts and brings the image into greater realism. We verify our findings qualitatively and quantitatively, showing an improvement in Frechet Inception Distance (FID) exists along our trajectory which surpasses the original GAN and other approaches including a supervised method. We expand further and provide an optimization method to automatically select latent vectors along the path that balance the variation and realism of samples. We apply our method to several diverse datasets and three architectures of varying complexity to illustrate the generalizability of our approach. By expanding the utility of low-complexity and existing networks, we hope to encourage the democratization of GANs.
DGL-GAN: Discriminator Guided Learning for GAN Compression
Dec 13, 2021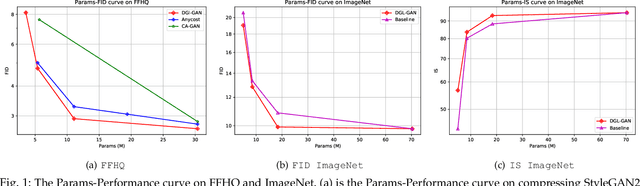
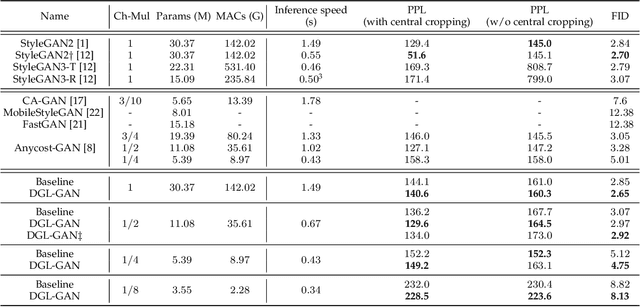
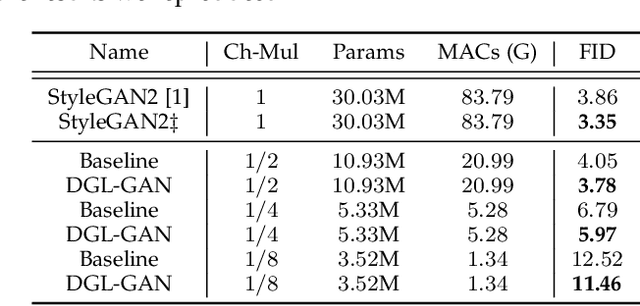
Generative Adversarial Networks (GANs) with high computation costs, e.g., BigGAN and StyleGAN2, have achieved remarkable results in synthesizing high resolution and diverse images with high fidelity from random noises. Reducing the computation cost of GANs while keeping generating photo-realistic images is an urgent and challenging field for their broad applications on computational resource-limited devices. In this work, we propose a novel yet simple {\bf D}iscriminator {\bf G}uided {\bf L}earning approach for compressing vanilla {\bf GAN}, dubbed {\bf DGL-GAN}. Motivated by the phenomenon that the teacher discriminator may contain some meaningful information, we transfer the knowledge merely from the teacher discriminator via the adversarial function. We show DGL-GAN is valid since empirically, learning from the teacher discriminator could facilitate the performance of student GANs, verified by extensive experimental findings. Furthermore, we propose a two-stage training strategy for training DGL-GAN, which can largely stabilize its training process and achieve superior performance when we apply DGL-GAN to compress the two most representative large-scale vanilla GANs, i.e., StyleGAN2 and BigGAN. Experiments show that DGL-GAN achieves state-of-the-art (SOTA) results on both StyleGAN2 (FID 2.92 on FFHQ with nearly $1/3$ parameters of StyleGAN2) and BigGAN (IS 93.29 and FID 9.92 on ImageNet with nearly $1/4$ parameters of BigGAN) and also outperforms several existing vanilla GAN compression techniques. Moreover, DGL-GAN is also effective in boosting the performance of original uncompressed GANs, original uncompressed StyleGAN2 boosted with DGL-GAN achieves FID 2.65 on FFHQ, which achieves a new state-of-the-art performance. Code and models are available at \url{https://github.com/yuesongtian/DGL-GAN}.
Unpaired Learning for High Dynamic Range Image Tone Mapping
Oct 30, 2021
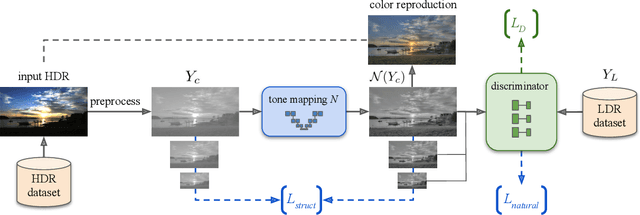
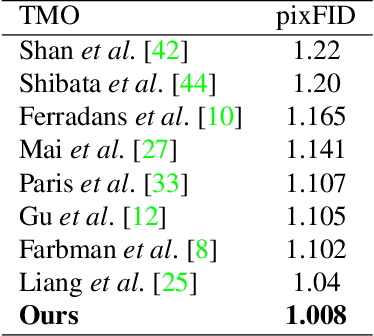
High dynamic range (HDR) photography is becoming increasingly popular and available by DSLR and mobile-phone cameras. While deep neural networks (DNN) have greatly impacted other domains of image manipulation, their use for HDR tone-mapping is limited due to the lack of a definite notion of ground-truth solution, which is needed for producing training data. In this paper we describe a new tone-mapping approach guided by the distinct goal of producing low dynamic range (LDR) renditions that best reproduce the visual characteristics of native LDR images. This goal enables the use of an unpaired adversarial training based on unrelated sets of HDR and LDR images, both of which are widely available and easy to acquire. In order to achieve an effective training under this minimal requirements, we introduce the following new steps and components: (i) a range-normalizing pre-process which estimates and applies a different level of curve-based compression, (ii) a loss that preserves the input content while allowing the network to achieve its goal, and (iii) the use of a more concise discriminator network, designed to promote the reproduction of low-level attributes native LDR possess. Evaluation of the resulting network demonstrates its ability to produce photo-realistic artifact-free tone-mapped images, and state-of-the-art performance on different image fidelity indices and visual distances.
Editable Free-viewpoint Video Using a Layered Neural Representation
Apr 30, 2021
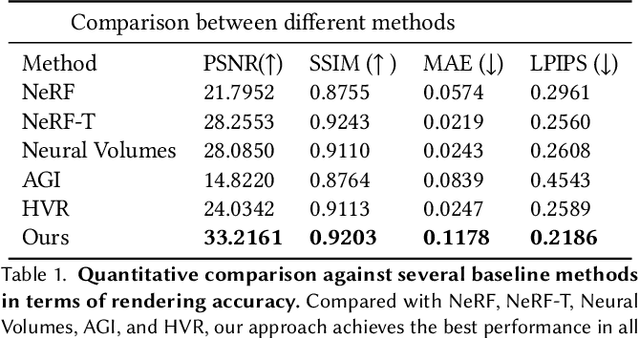
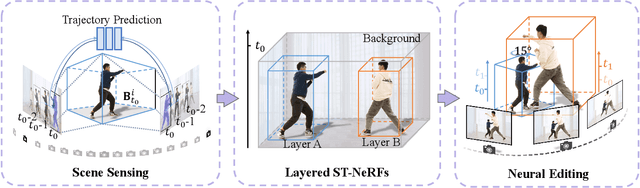
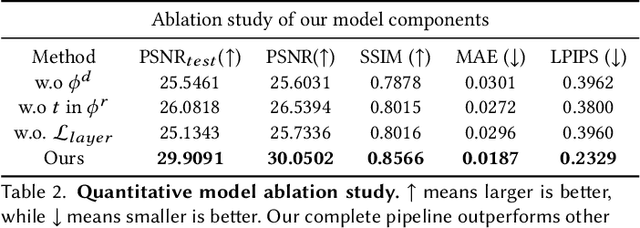
Generating free-viewpoint videos is critical for immersive VR/AR experience but recent neural advances still lack the editing ability to manipulate the visual perception for large dynamic scenes. To fill this gap, in this paper we propose the first approach for editable photo-realistic free-viewpoint video generation for large-scale dynamic scenes using only sparse 16 cameras. The core of our approach is a new layered neural representation, where each dynamic entity including the environment itself is formulated into a space-time coherent neural layered radiance representation called ST-NeRF. Such layered representation supports fully perception and realistic manipulation of the dynamic scene whilst still supporting a free viewing experience in a wide range. In our ST-NeRF, the dynamic entity/layer is represented as continuous functions, which achieves the disentanglement of location, deformation as well as the appearance of the dynamic entity in a continuous and self-supervised manner. We propose a scene parsing 4D label map tracking to disentangle the spatial information explicitly, and a continuous deform module to disentangle the temporal motion implicitly. An object-aware volume rendering scheme is further introduced for the re-assembling of all the neural layers. We adopt a novel layered loss and motion-aware ray sampling strategy to enable efficient training for a large dynamic scene with multiple performers, Our framework further enables a variety of editing functions, i.e., manipulating the scale and location, duplicating or retiming individual neural layers to create numerous visual effects while preserving high realism. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality, photo-realistic, and editable free-viewpoint video generation for dynamic scenes.