 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
SCFlow: Optical Flow Estimation for Spiking Camera
Oct 08, 2021

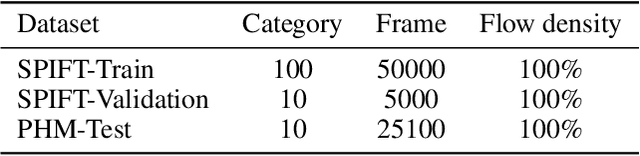

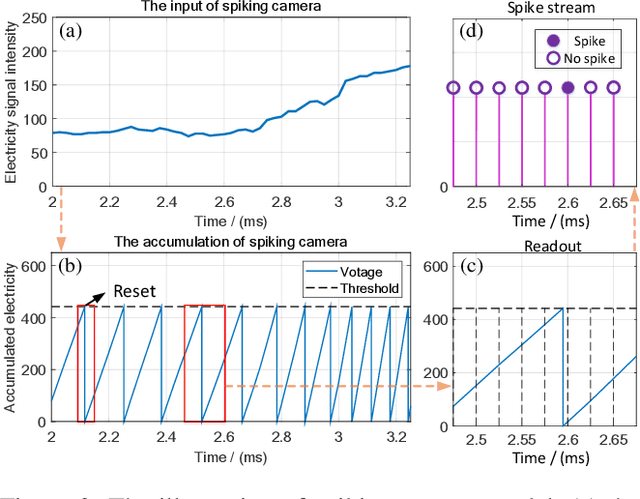
As a bio-inspired sensor with high temporal resolution, Spiking camera has an enormous potential in real applications, especially for motion estimation in high-speed scenes. Optical flow estimation has achieved remarkable success in image-based and event-based vision, but % existing methods cannot be directly applied in spike stream from spiking camera. conventional optical flow algorithms are not well matched to the spike stream data. This paper presents, SCFlow, a novel deep learning pipeline for optical flow estimation for spiking camera. Importantly, we introduce an proper input representation of a given spike stream, which is fed into SCFlow as the sole input. We introduce the \textit{first} spiking camera simulator (SPCS). Furthermore, based on SPCS, we first propose two optical flow datasets for spiking camera (SPIkingly Flying Things and Photo-realistic High-speed Motion, denoted as SPIFT and PHM respectively) corresponding to random high-speed and well-designed scenes. Empirically, we show that the SCFlow can predict optical flow from spike stream in different high-speed scenes, and express superiority to existing methods on the datasets. \textit{All codes and constructed datasets will be released after publication}.
PIRenderer: Controllable Portrait Image Generation via Semantic Neural Rendering
Sep 17, 2021
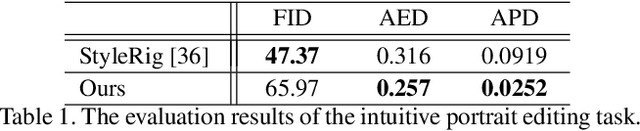
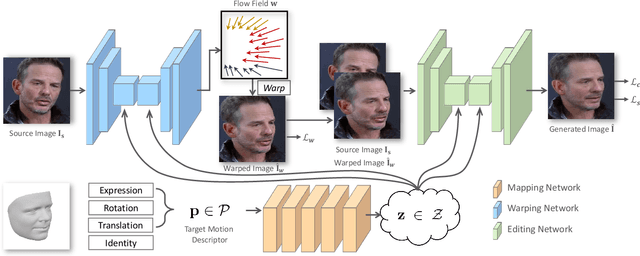

Generating portrait images by controlling the motions of existing faces is an important task of great consequence to social media industries. For easy use and intuitive control, semantically meaningful and fully disentangled parameters should be used as modifications. However, many existing techniques do not provide such fine-grained controls or use indirect editing methods i.e. mimic motions of other individuals. In this paper, a Portrait Image Neural Renderer (PIRenderer) is proposed to control the face motions with the parameters of three-dimensional morphable face models (3DMMs). The proposed model can generate photo-realistic portrait images with accurate movements according to intuitive modifications. Experiments on both direct and indirect editing tasks demonstrate the superiority of this model. Meanwhile, we further extend this model to tackle the audio-driven facial reenactment task by extracting sequential motions from audio inputs. We show that our model can generate coherent videos with convincing movements from only a single reference image and a driving audio stream. Our source code is available at https://github.com/RenYurui/PIRender.
Multi-Level Visual Similarity Based Personalized Tourist Attraction Recommendation Using Geo-Tagged Photos
Sep 17, 2021
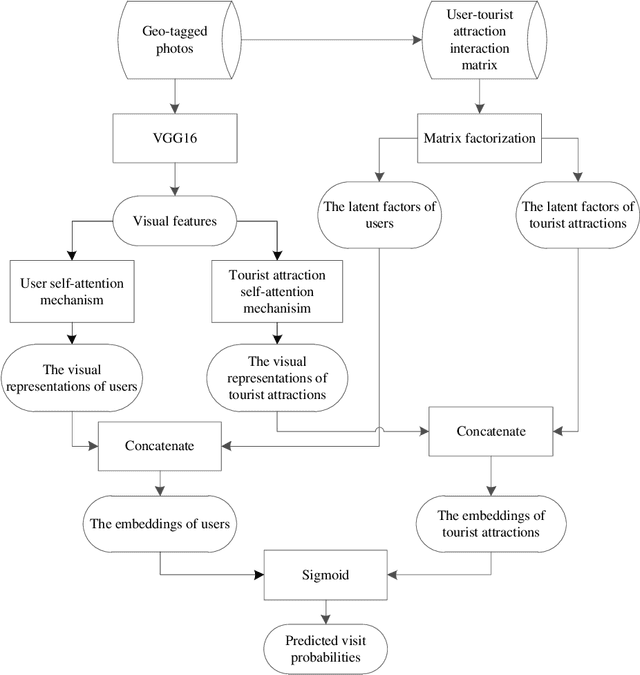
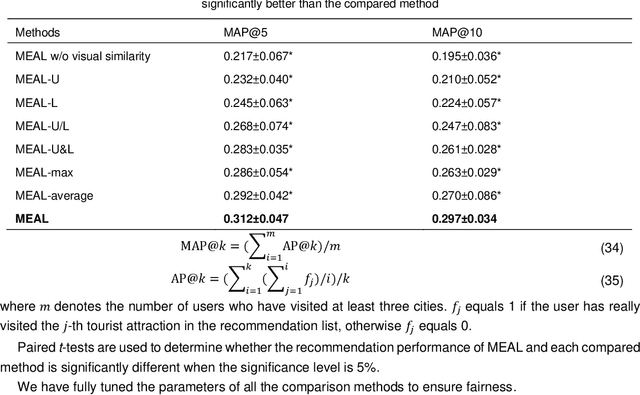
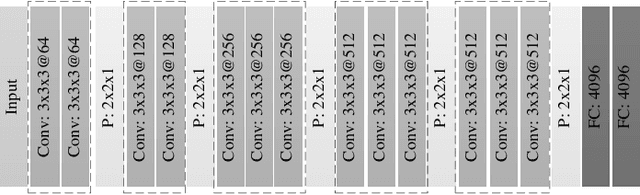
Geo-tagged photo based tourist attraction recommendation can discover users' travel preferences from their taken photos, so as to recommend suitable tourist attractions to them. However, existing visual content based methods cannot fully exploit the user and tourist attraction information of photos to extract visual features, and do not differentiate the significances of different photos. In this paper, we propose multi-level visual similarity based personalized tourist attraction recommendation using geo-tagged photos (MEAL). MEAL utilizes the visual contents of photos and interaction behavior data to obtain the final embeddings of users and tourist attractions, which are then used to predict the visit probabilities. Specifically, by crossing the user and tourist attraction information of photos, we define four visual similarity levels and introduce a corresponding quintuplet loss to embed the visual contents of photos. In addition, to capture the significances of different photos, we exploit the self-attention mechanism to obtain the visual representations of users and tourist attractions. We conducted experiments on a dataset crawled from Flickr, and the experimental results proved the advantage of this method.
Perceptual Learned Video Compression with Recurrent Conditional GAN
Sep 13, 2021

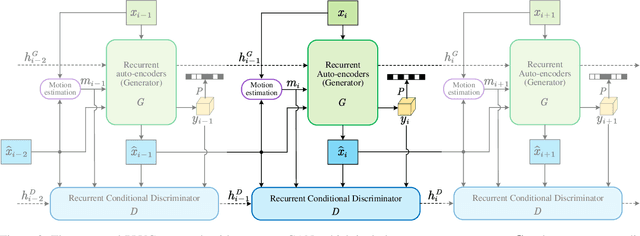
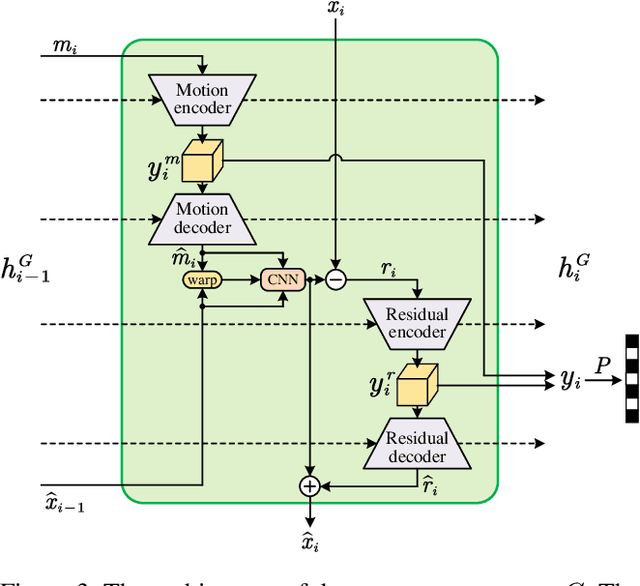
This paper proposes a Perceptual Learned Video Compression (PLVC) approach with recurrent conditional generative adversarial network. In our approach, the recurrent auto-encoder-based generator learns to fully explore the temporal correlation for compressing video. More importantly, we propose a recurrent conditional discriminator, which judges raw and compressed video conditioned on both spatial and temporal information, including the latent representation, temporal motion and hidden states in recurrent cells. This way, in the adversarial training, it pushes the generated video to be not only spatially photo-realistic but also temporally consistent with groundtruth and coherent among video frames. The experimental results show that the proposed PLVC model learns to compress video towards good perceptual quality at low bit-rate, and outperforms the previous traditional and learned approaches on several perceptual quality metrics. The user study further validates the outstanding perceptual performance of PLVC in comparison with the latest learned video compression approaches and the official HEVC test model (HM 16.20). The codes will be released at https://github.com/RenYang-home/PLVC.
PROVES: Establishing Image Provenance using Semantic Signatures
Oct 21, 2021
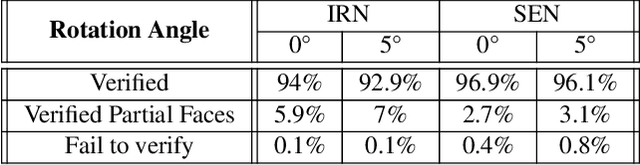
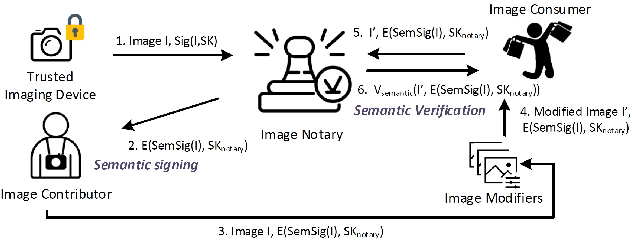
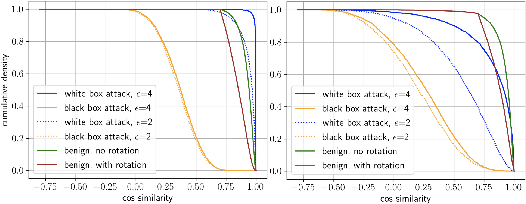
Modern AI tools, such as generative adversarial networks, have transformed our ability to create and modify visual data with photorealistic results. However, one of the deleterious side-effects of these advances is the emergence of nefarious uses in manipulating information in visual data, such as through the use of deep fakes. We propose a novel architecture for preserving the provenance of semantic information in images to make them less susceptible to deep fake attacks. Our architecture includes semantic signing and verification steps. We apply this architecture to verifying two types of semantic information: individual identities (faces) and whether the photo was taken indoors or outdoors. Verification accounts for a collection of common image transformation, such as translation, scaling, cropping, and small rotations, and rejects adversarial transformations, such as adversarially perturbed or, in the case of face verification, swapped faces. Experiments demonstrate that in the case of provenance of faces in an image, our approach is robust to black-box adversarial transformations (which are rejected) as well as benign transformations (which are accepted), with few false negatives and false positives. Background verification, on the other hand, is susceptible to black-box adversarial examples, but becomes significantly more robust after adversarial training.
Instance-Conditioned GAN
Sep 10, 2021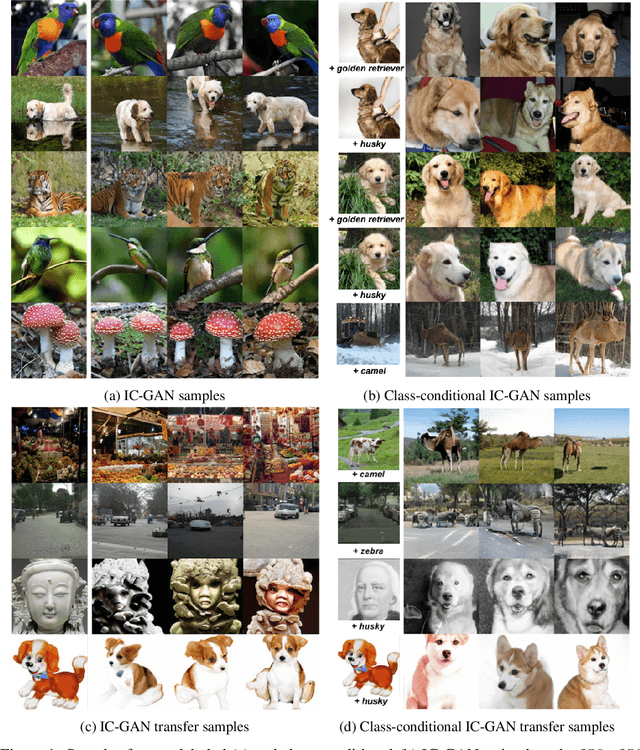
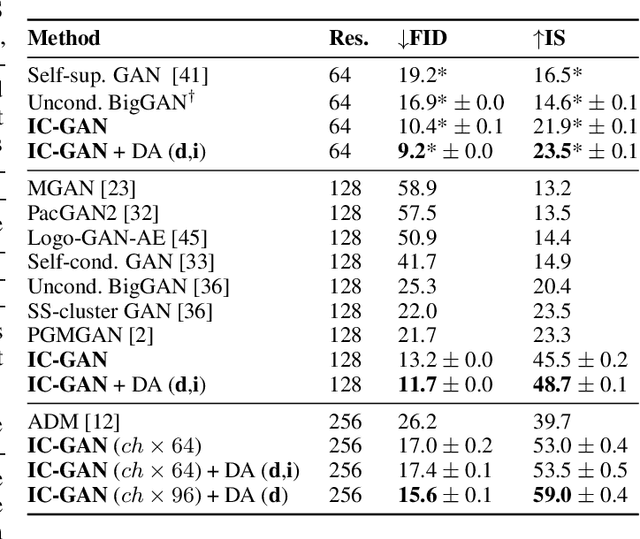
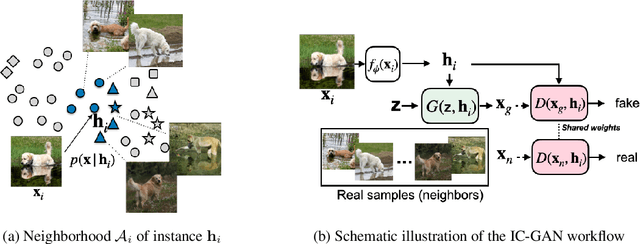
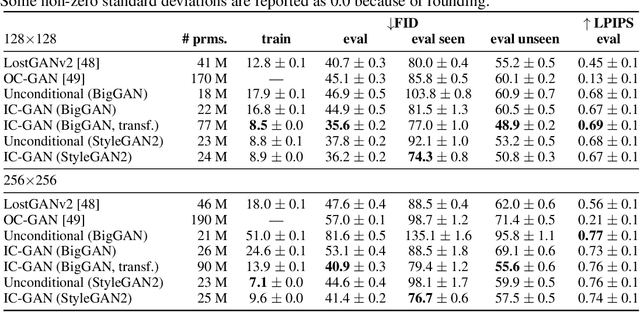
Generative Adversarial Networks (GANs) can generate near photo realistic images in narrow domains such as human faces. Yet, modeling complex distributions of datasets such as ImageNet and COCO-Stuff remains challenging in unconditional settings. In this paper, we take inspiration from kernel density estimation techniques and introduce a non-parametric approach to modeling distributions of complex datasets. We partition the data manifold into a mixture of overlapping neighborhoods described by a datapoint and its nearest neighbors, and introduce a model, called instance-conditioned GAN (IC-GAN), which learns the distribution around each datapoint. Experimental results on ImageNet and COCO-Stuff show that IC-GAN significantly improves over unconditional models and unsupervised data partitioning baselines. Moreover, we show that IC-GAN can effortlessly transfer to datasets not seen during training by simply changing the conditioning instances, and still generate realistic images. Finally, we extend IC-GAN to the class-conditional case and show semantically controllable generation and competitive quantitative results on ImageNet; while improving over BigGAN on ImageNet-LT. We will opensource our code and trained models to reproduce the reported results.
A comparison study of CNN denoisers on PRNU extraction
Dec 06, 2021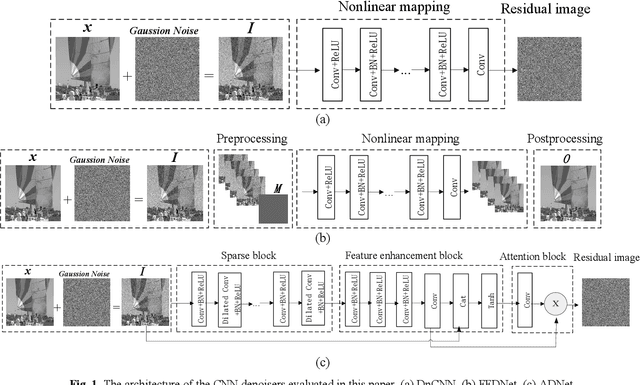
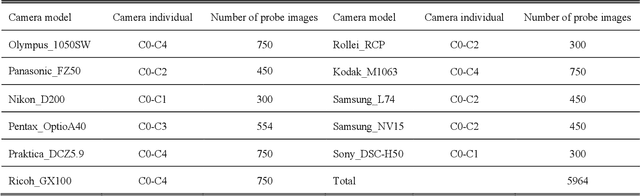
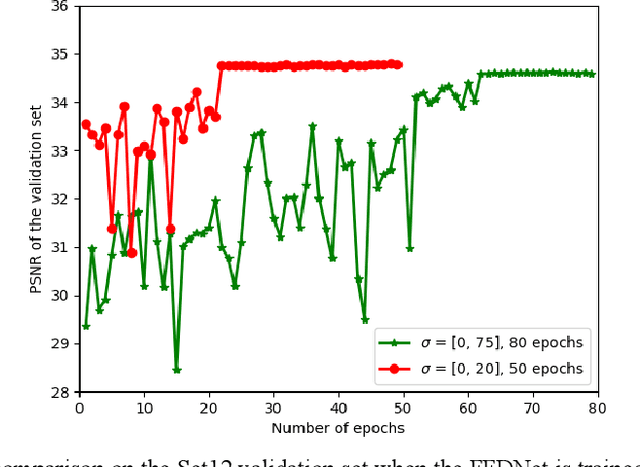
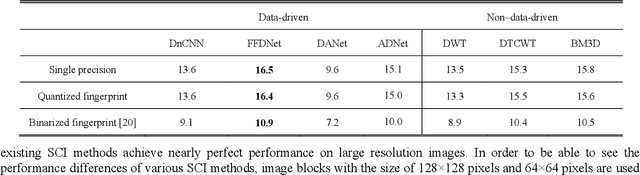
Performance of the sensor-based camera identification (SCI) method heavily relies on the denoising filter in estimating Photo-Response Non-Uniformity (PRNU). Given various attempts on enhancing the quality of the extracted PRNU, it still suffers from unsatisfactory performance in low-resolution images and high computational demand. Leveraging the similarity of PRNU estimation and image denoising, we take advantage of the latest achievements of Convolutional Neural Network (CNN)-based denoisers for PRNU extraction. In this paper, a comparative evaluation of such CNN denoisers on SCI performance is carried out on the public "Dresden Image Database". Our findings are two-fold. From one aspect, both the PRNU extraction and image denoising separate noise from the image content. Hence, SCI can benefit from the recent CNN denoisers if carefully trained. From another aspect, the goals and the scenarios of PRNU extraction and image denoising are different since one optimizes the quality of noise and the other optimizes the image quality. A carefully tailored training is needed when CNN denoisers are used for PRNU estimation. Alternative strategies of training data preparation and loss function design are analyzed theoretically and evaluated experimentally. We point out that feeding the CNNs with image-PRNU pairs and training them with correlation-based loss function result in the best PRNU estimation performance. To facilitate further studies of SCI, we also propose a minimum-loss camera fingerprint quantization scheme using which we save the fingerprints as image files in PNG format. Furthermore, we make the quantized fingerprints of the cameras from the "Dresden Image Database" publicly available.
Indoor Semantic Scene Understanding using Multi-modality Fusion
Aug 17, 2021
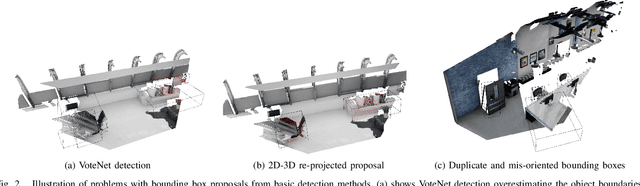

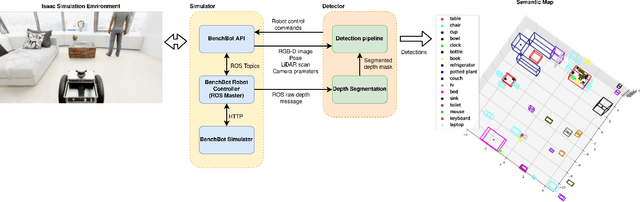
Seamless Human-Robot Interaction is the ultimate goal of developing service robotic systems. For this, the robotic agents have to understand their surroundings to better complete a given task. Semantic scene understanding allows a robotic agent to extract semantic knowledge about the objects in the environment. In this work, we present a semantic scene understanding pipeline that fuses 2D and 3D detection branches to generate a semantic map of the environment. The 2D mask proposals from state-of-the-art 2D detectors are inverse-projected to the 3D space and combined with 3D detections from point segmentation networks. Unlike previous works that were evaluated on collected datasets, we test our pipeline on an active photo-realistic robotic environment - BenchBot. Our novelty includes rectification of 3D proposals using projected 2D detections and modality fusion based on object size. This work is done as part of the Robotic Vision Scene Understanding Challenge (RVSU). The performance evaluation demonstrates that our pipeline has improved on baseline methods without significant computational bottleneck.
Shuffled Patch-Wise Supervision for Presentation Attack Detection
Sep 09, 2021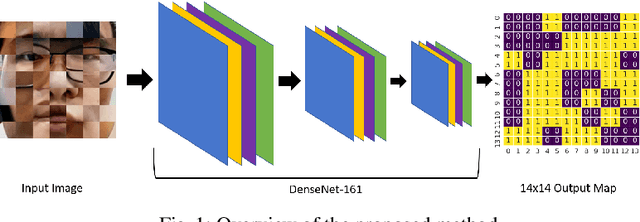
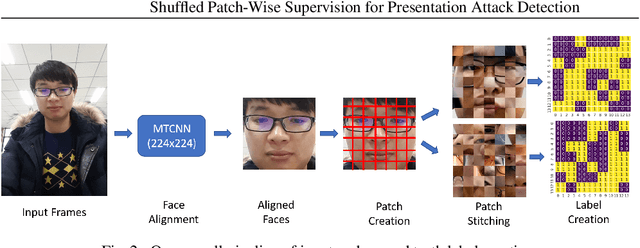

Face anti-spoofing is essential to prevent false facial verification by using a photo, video, mask, or a different substitute for an authorized person's face. Most of the state-of-the-art presentation attack detection (PAD) systems suffer from overfitting, where they achieve near-perfect scores on a single dataset but fail on a different dataset with more realistic data. This problem drives researchers to develop models that perform well under real-world conditions. This is an especially challenging problem for frame-based presentation attack detection systems that use convolutional neural networks (CNN). To this end, we propose a new PAD approach, which combines pixel-wise binary supervision with patch-based CNN. We believe that training a CNN with face patches allows the model to distinguish spoofs without learning background or dataset-specific traces. We tested the proposed method both on the standard benchmark datasets -- Replay-Mobile, OULU-NPU -- and on a real-world dataset. The proposed approach shows its superiority on challenging experimental setups. Namely, it achieves higher performance on OULU-NPU protocol 3, 4 and on inter-dataset real-world experiments.