 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Pop Music Transformer: Generating Music with Rhythm and Harmony
Feb 01, 2020
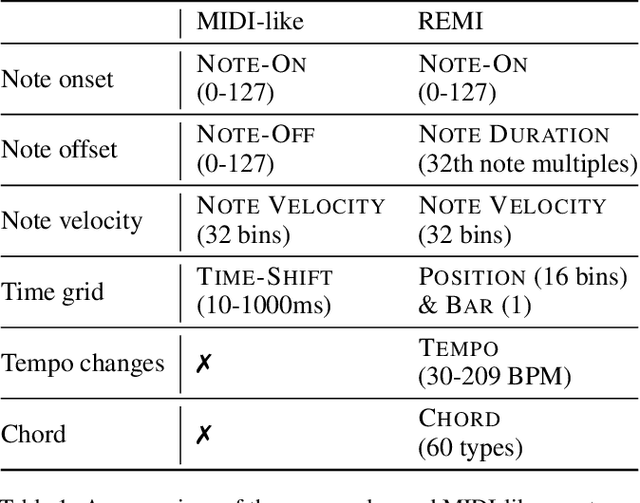
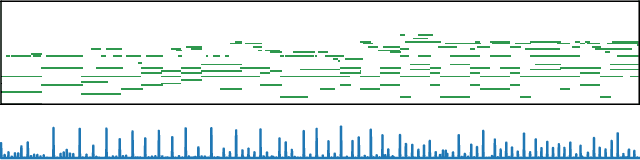
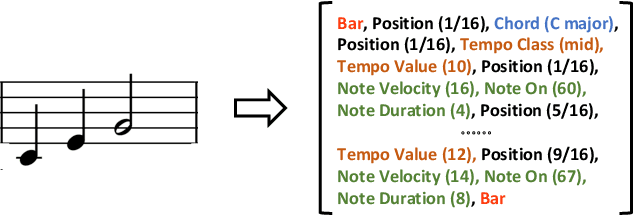
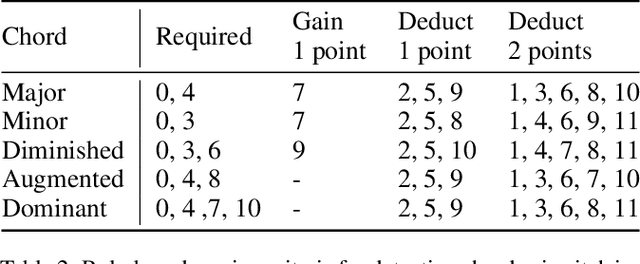
The task automatic music composition entails generative modeling of music in symbolic formats such as the musical scores. By serializing a score as a sequence of MIDI-like events, recent work has demonstrated that state-of-the-art sequence models with self-attention work nicely for this task, especially for composing music with long-range coherence. In this paper, we show that sequence models can do even better when we improve the way a musical score is converted into events. The new event set, dubbed "REMI" (REvamped MIDI-derived events), provides sequence models a metric context for modeling the rhythmic patterns of music, while allowing for local tempo changes. Moreover, it explicitly sets up a harmonic structure and makes chord progression controllable. It also facilitates coordinating different tracks of a musical piece, such as the piano, bass and drums. With this new approach, we build a Pop Music Transformer that composes Pop piano music with a more plausible rhythmic structure than prior arts do. The code, data and pre-trained model are publicly available.\footnote{\url{https://github.com/YatingMusic/remi}}
AVASpeech-SMAD: A Strongly Labelled Speech and Music Activity Detection Dataset with Label Co-Occurrence
Nov 02, 2021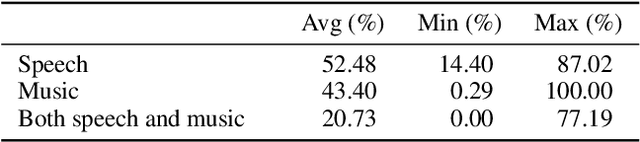

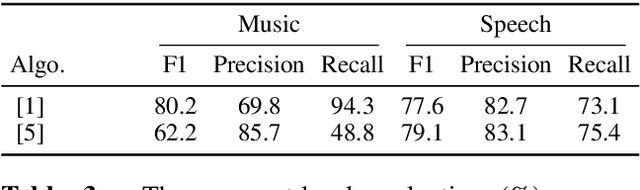
We propose a dataset, AVASpeech-SMAD, to assist speech and music activity detection research. With frame-level music labels, the proposed dataset extends the existing AVASpeech dataset, which originally consists of 45 hours of audio and speech activity labels. To the best of our knowledge, the proposed AVASpeech-SMAD is the first open-source dataset that features strong polyphonic labels for both music and speech. The dataset was manually annotated and verified via an iterative cross-checking process. A simple automatic examination was also implemented to further improve the quality of the labels. Evaluation results from two state-of-the-art SMAD systems are also provided as a benchmark for future reference.
Improving Real-time Score Following in Opera by Combining Music with Lyrics Tracking
Oct 06, 2021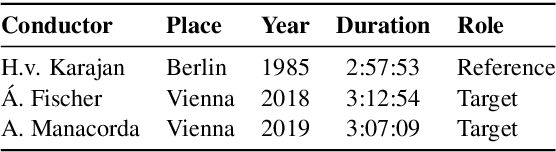
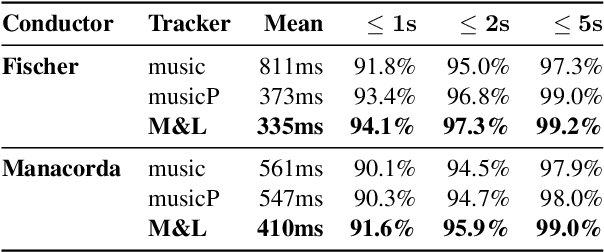
Fully automatic opera tracking is challenging because of the acoustic complexity of the genre, combining musical and linguistic information (singing, speech) in complex ways. In this paper, we propose a new pipeline for complete opera tracking. The pipeline is based on two trackers. A music tracker that has proven to be effective at tracking orchestral parts, will lead the tracking process. In addition, a lyrics tracker, that has recently been shown to reliably track the lyrics of opera songs, will correct the music tracker when tracking parts that have a text dominance over the music. We will demonstrate the efficiency of this method on the opera Don Giovanni, showing that this technique helps improving accuracy and robustness of a complete opera tracker.
Lyric document embeddings for music tagging
Nov 29, 2021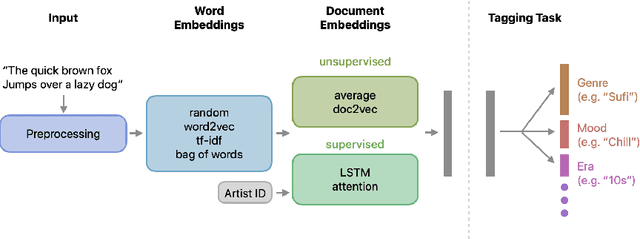
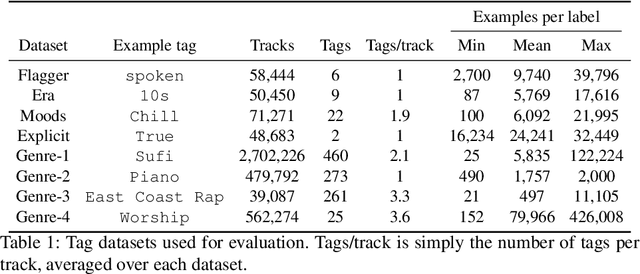
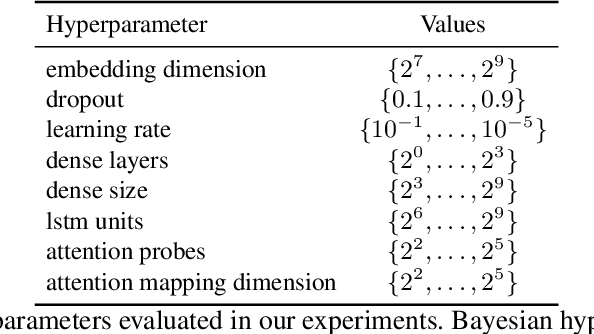
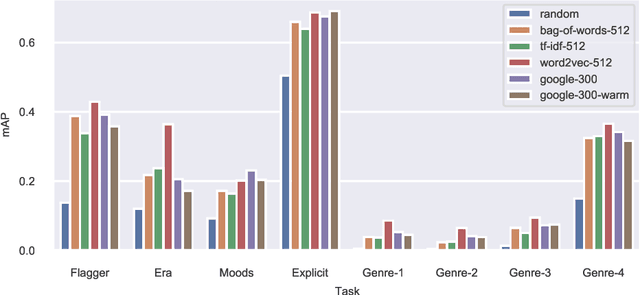
We present an empirical study on embedding the lyrics of a song into a fixed-dimensional feature for the purpose of music tagging. Five methods of computing token-level and four methods of computing document-level representations are trained on an industrial-scale dataset of tens of millions of songs. We compare simple averaging of pretrained embeddings to modern recurrent and attention-based neural architectures. Evaluating on a wide range of tagging tasks such as genre classification, explicit content identification and era detection, we find that averaging word embeddings outperform more complex architectures in many downstream metrics.
Learning Hierarchical Metrical Structure Beyond Measures
Sep 21, 2022
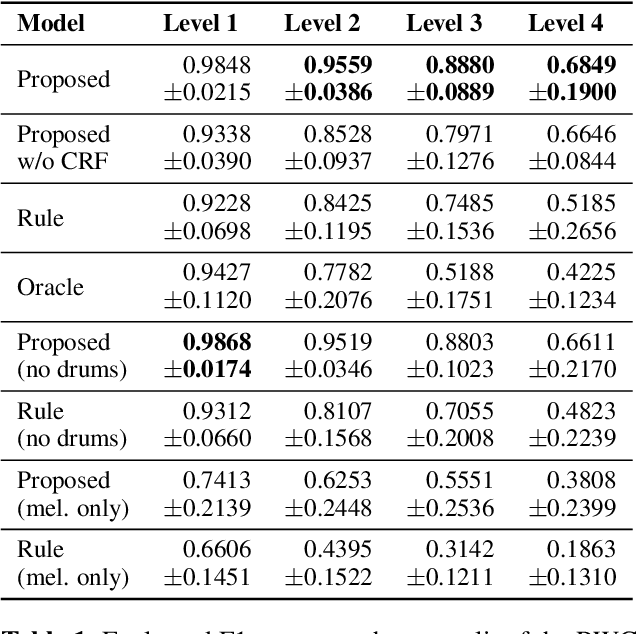
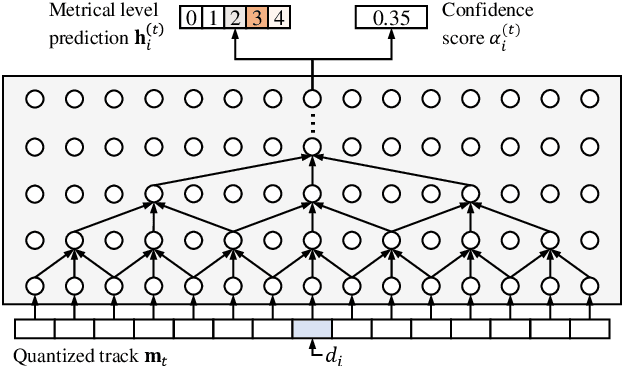
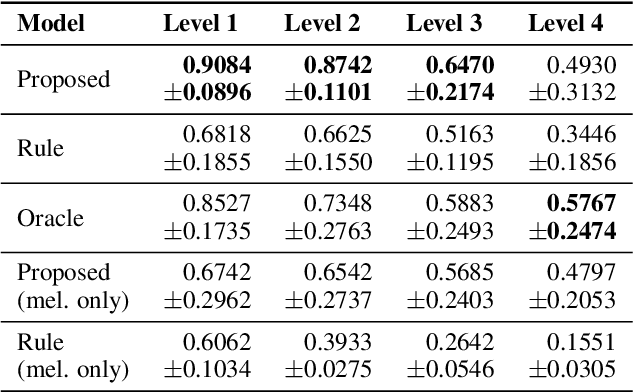
Music contains hierarchical structures beyond beats and measures. While hierarchical structure annotations are helpful for music information retrieval and computer musicology, such annotations are scarce in current digital music databases. In this paper, we explore a data-driven approach to automatically extract hierarchical metrical structures from scores. We propose a new model with a Temporal Convolutional Network-Conditional Random Field (TCN-CRF) architecture. Given a symbolic music score, our model takes in an arbitrary number of voices in a beat-quantized form, and predicts a 4-level hierarchical metrical structure from downbeat-level to section-level. We also annotate a dataset using RWC-POP MIDI files to facilitate training and evaluation. We show by experiments that the proposed method performs better than the rule-based approach under different orchestration settings. We also perform some simple musicological analysis on the model predictions. All demos, datasets and pre-trained models are publicly available on Github.
Downlink and Uplink Cooperative Joint Communication and Sensing
Nov 08, 2022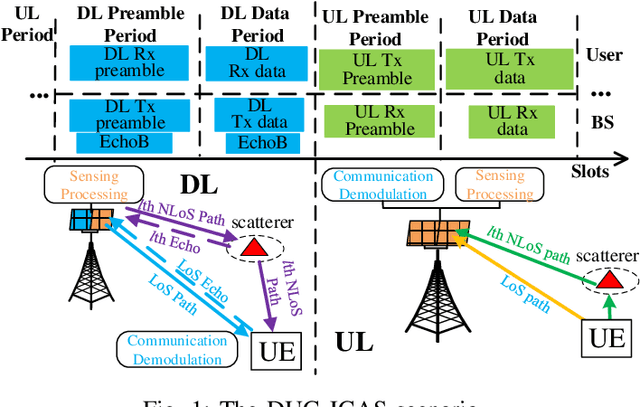
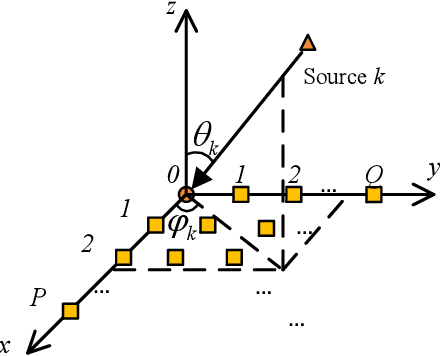
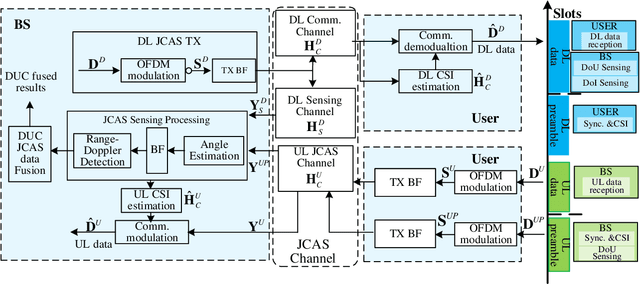
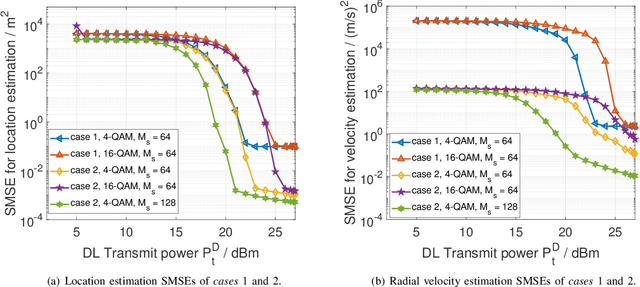
Downlink (DL) and uplink (UL) joint communication and sensing (JCAS) technologies have been individually studied for realizing sensing using DL and UL communication signals, respectively. Since the spatial environment and JCAS channels in the consecutive DL and UL JCAS time slots are generally unchanged, DL and UL JCAS may be jointly designed to achieve better sensing performance. In this paper, we propose a novel DL and UL cooperative (DUC) JCAS scheme, including a unified multiple signal classification (MUSIC)-based JCAS sensing scheme for both DL and UL JCAS and a DUC JCAS fusion method. The unified MUSIC JCAS sensing scheme can accurately estimate AoA, range, and Doppler based on a unified MUSIC-based sensing module. The DUC JCAS fusion method can distinguish between the sensing results of the communication user and other dumb targets. Moreover, by exploiting the channel reciprocity, it can also improve the sensing and channel state information (CSI) estimation accuracy. Extensive simulation results validate the proposed DUC JCAS scheme. It is shown that the minimum location and velocity estimation mean square errors of the proposed DUC JCAS scheme are about 20 dB lower than those of the state-of-the-art separated DL and UL JCAS schemes.
Melody Infilling with User-Provided Structural Context
Oct 06, 2022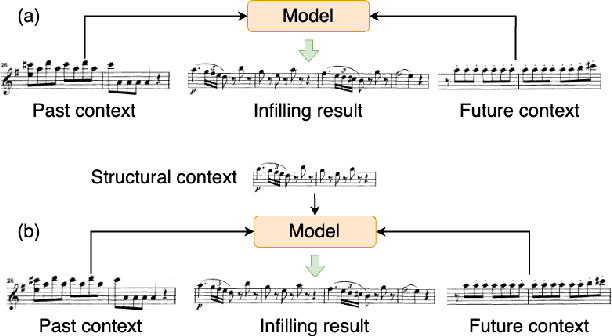
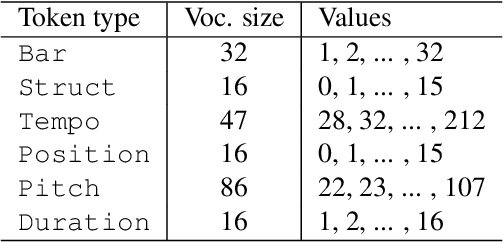
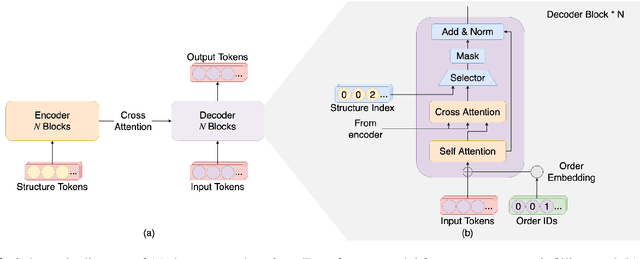
This paper proposes a novel Transformer-based model for music score infilling, to generate a music passage that fills in the gap between given past and future contexts. While existing infilling approaches can generate a passage that connects smoothly locally with the given contexts, they do not take into account the musical form or structure of the music and may therefore generate overly smooth results. To address this issue, we propose a structure-aware conditioning approach that employs a novel attention-selecting module to supply user-provided structure-related information to the Transformer for infilling. With both objective and subjective evaluations, we show that the proposed model can harness the structural information effectively and generate melodies in the style of pop of higher quality than the two existing structure-agnostic infilling models.
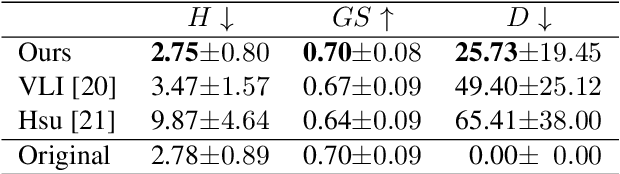
Dancing to Music
Nov 05, 2019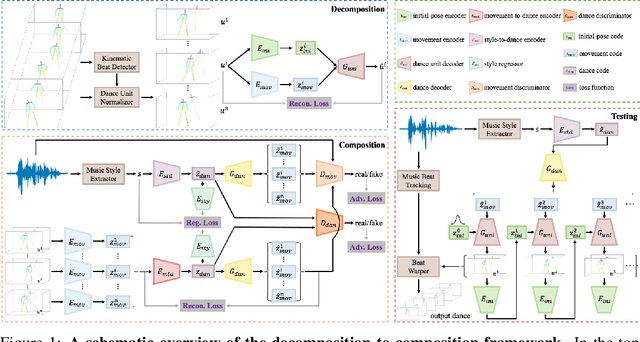
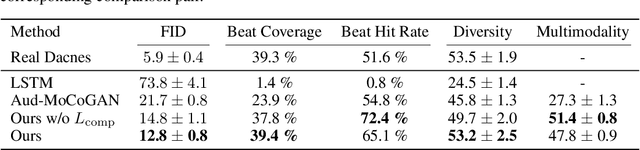
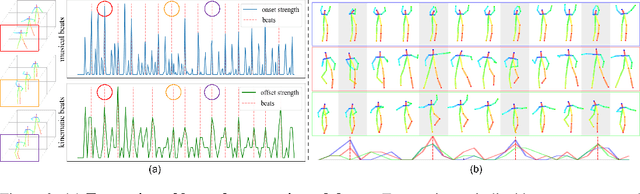
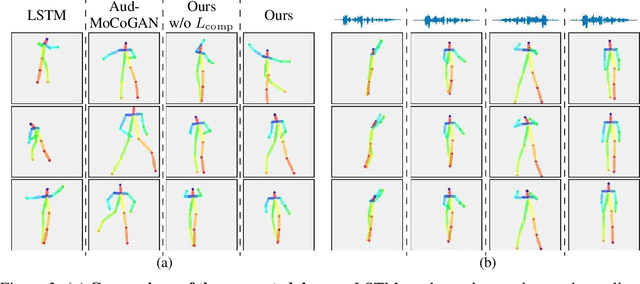
Dancing to music is an instinctive move by humans. Learning to model the music-to-dance generation process is, however, a challenging problem. It requires significant efforts to measure the correlation between music and dance as one needs to simultaneously consider multiple aspects, such as style and beat of both music and dance. Additionally, dance is inherently multimodal and various following movements of a pose at any moment are equally likely. In this paper, we propose a synthesis-by-analysis learning framework to generate dance from music. In the analysis phase, we decompose a dance into a series of basic dance units, through which the model learns how to move. In the synthesis phase, the model learns how to compose a dance by organizing multiple basic dancing movements seamlessly according to the input music. Experimental qualitative and quantitative results demonstrate that the proposed method can synthesize realistic, diverse,style-consistent, and beat-matching dances from music.
Exploring modality-agnostic representations for music classification
Jun 02, 2021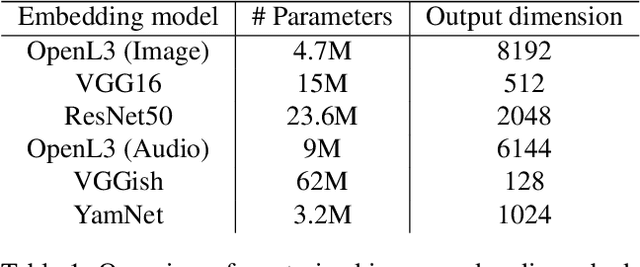
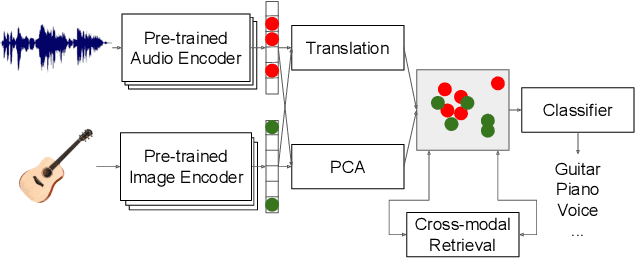
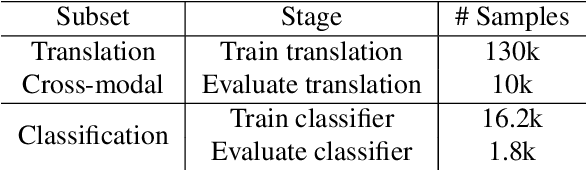
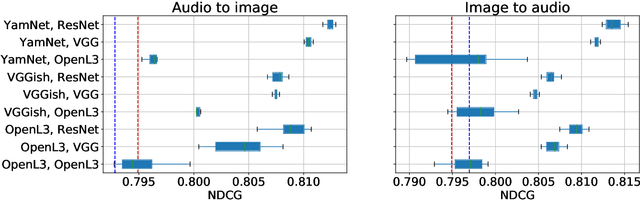
Music information is often conveyed or recorded across multiple data modalities including but not limited to audio, images, text and scores. However, music information retrieval research has almost exclusively focused on single modality recognition, requiring development of separate models for each modality. Some multi-modal works require multiple coexisting modalities given to the model as inputs, constraining the use of these models to the few cases where data from all modalities are available. To the best of our knowledge, no existing model has the ability to take inputs from varying modalities, e.g. images or sounds, and classify them into unified music categories. We explore the use of cross-modal retrieval as a pretext task to learn modality-agnostic representations, which can then be used as inputs to classifiers that are independent of modality. We select instrument classification as an example task for our study as both visual and audio components provide relevant semantic information. We train music instrument classifiers that can take both images or sounds as input, and perform comparably to sound-only or image-only classifiers. Furthermore, we explore the case when there is limited labeled data for a given modality, and the impact in performance by using labeled data from other modalities. We are able to achieve almost 70% of best performing system in a zero-shot setting. We provide a detailed analysis of experimental results to understand the potential and limitations of the approach, and discuss future steps towards modality-agnostic classifiers.
A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT
Mar 07, 2023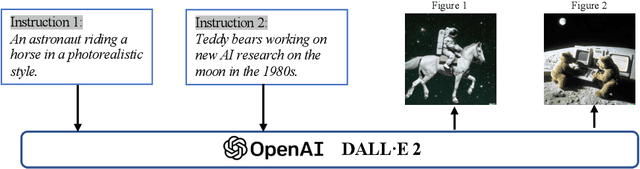
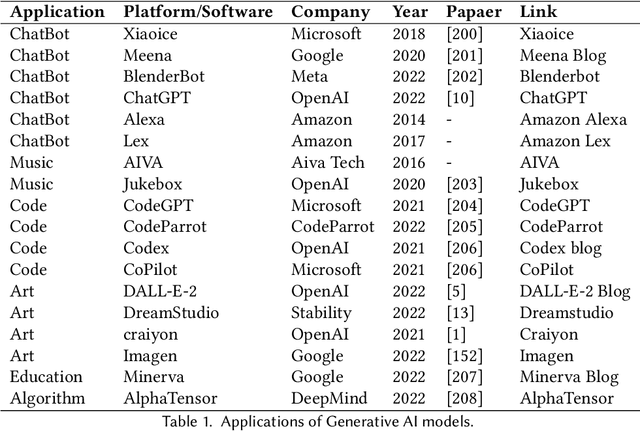
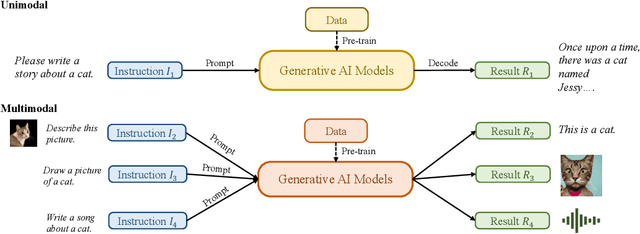
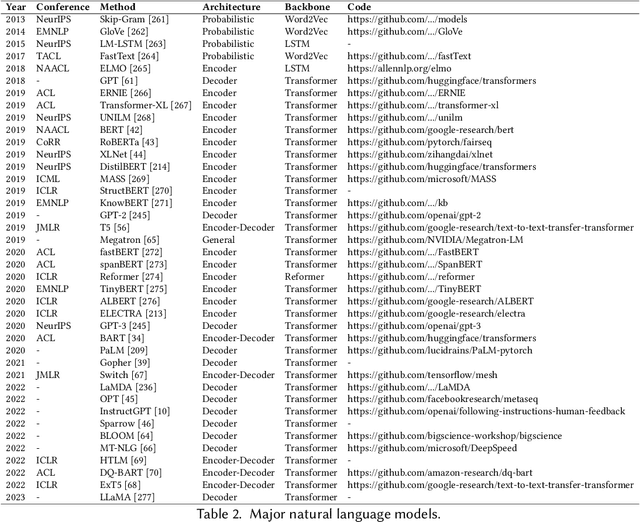
Recently, ChatGPT, along with DALL-E-2 and Codex,has been gaining significant attention from society. As a result, many individuals have become interested in related resources and are seeking to uncover the background and secrets behind its impressive performance. In fact, ChatGPT and other Generative AI (GAI) techniques belong to the category of Artificial Intelligence Generated Content (AIGC), which involves the creation of digital content, such as images, music, and natural language, through AI models. The goal of AIGC is to make the content creation process more efficient and accessible, allowing for the production of high-quality content at a faster pace. AIGC is achieved by extracting and understanding intent information from instructions provided by human, and generating the content according to its knowledge and the intent information. In recent years, large-scale models have become increasingly important in AIGC as they provide better intent extraction and thus, improved generation results. With the growth of data and the size of the models, the distribution that the model can learn becomes more comprehensive and closer to reality, leading to more realistic and high-quality content generation. This survey provides a comprehensive review on the history of generative models, and basic components, recent advances in AIGC from unimodal interaction and multimodal interaction. From the perspective of unimodality, we introduce the generation tasks and relative models of text and image. From the perspective of multimodality, we introduce the cross-application between the modalities mentioned above. Finally, we discuss the existing open problems and future challenges in AIGC.