 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Kinit Classification in Ethiopian Chants, Azmaris and Modern Music: A New Dataset and CNN Benchmark
Jan 20, 2022
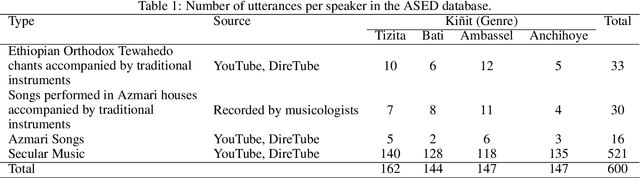
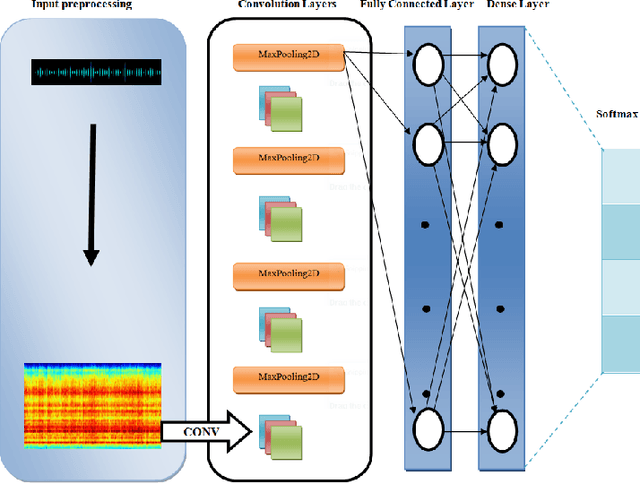
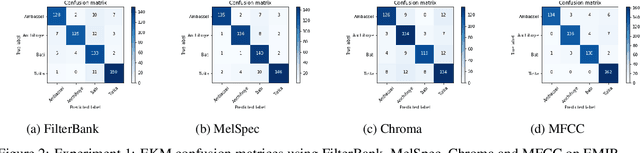
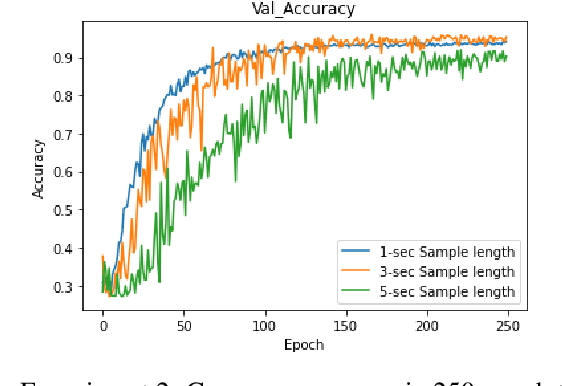
In this paper, we create EMIR, the first-ever Music Information Retrieval dataset for Ethiopian music. EMIR is freely available for research purposes and contains 600 sample recordings of Orthodox Tewahedo chants, traditional Azmari songs and contemporary Ethiopian secular music. Each sample is classified by five expert judges into one of four well-known Ethiopian Kinits, Tizita, Bati, Ambassel and Anchihoye. Each Kinit uses its own pentatonic scale and also has its own stylistic characteristics. Thus, Kinit classification needs to combine scale identification with genre recognition. After describing the dataset, we present the Ethio Kinits Model (EKM), based on VGG, for classifying the EMIR clips. In Experiment 1, we investigated whether Filterbank, Mel-spectrogram, Chroma, or Mel-frequency Cepstral coefficient (MFCC) features work best for Kinit classification using EKM. MFCC was found to be superior and was therefore adopted for Experiment 2, where the performance of EKM models using MFCC was compared using three different audio sample lengths. 3s length gave the best results. In Experiment 3, EKM and four existing models were compared on the EMIR dataset: AlexNet, ResNet50, VGG16 and LSTM. EKM was found to have the best accuracy (95.00%) as well as the fastest training time. We hope this work will encourage others to explore Ethiopian music and to experiment with other models for Kinit classification.
Semi-supervised music emotion recognition using noisy student training and harmonic pitch class profiles
Dec 09, 2021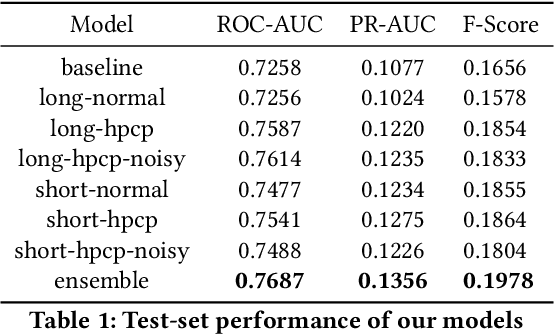
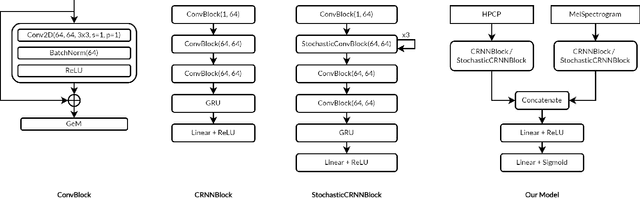
We present Mirable's submission to the 2021 Emotions and Themes in Music challenge. In this work, we intend to address the question: can we leverage semi-supervised learning techniques on music emotion recognition? With that, we experiment with noisy student training, which has improved model performance in the image classification domain. As the noisy student method requires a strong teacher model, we further delve into the factors including (i) input training length and (ii) complementary music representations to further boost the performance of the teacher model. For (i), we find that models trained with short input length perform better in PR-AUC, whereas those trained with long input length perform better in ROC-AUC. For (ii), we find that using harmonic pitch class profiles (HPCP) consistently improve tagging performance, which suggests that harmonic representation is useful for music emotion tagging. Finally, we find that noisy student method only improves tagging results for the case of long training length. Additionally, we find that ensembling representations trained with different training lengths can improve tagging results significantly, which suggest a possible direction to explore incorporating multiple temporal resolutions in the network architecture for future work.
Learning To Generate Piano Music With Sustain Pedals
Nov 01, 2021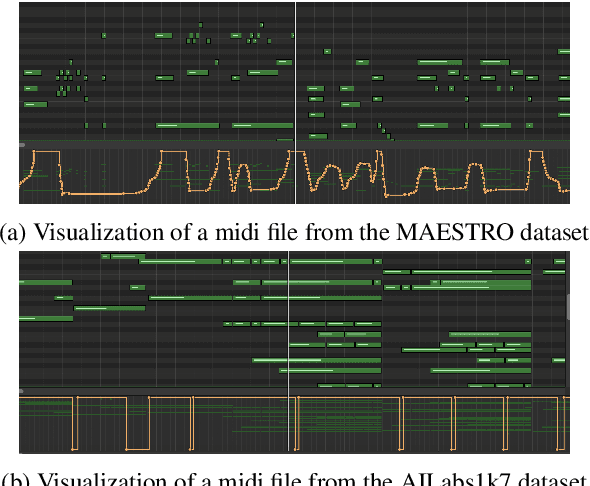
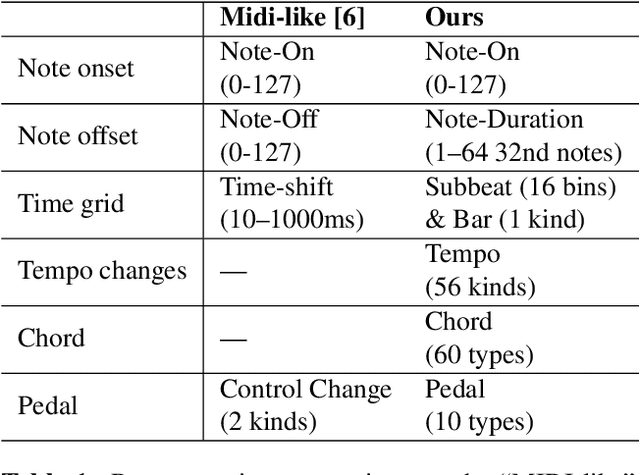
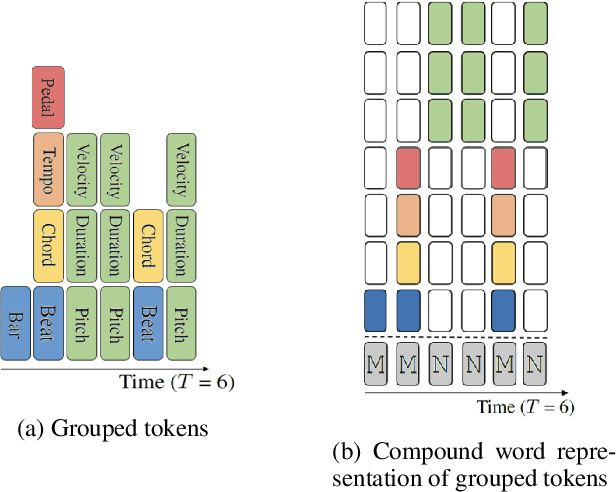
Recent years have witnessed a growing interest in research related to the detection of piano pedals from audio signals in the music information retrieval community. However, to our best knowledge, recent generative models for symbolic music have rarely taken piano pedals into account. In this work, we employ the transcription model proposed by Kong et al. to get pedal information from the audio recordings of piano performance in the AILabs1k7 dataset, and then modify the Compound Word Transformer proposed by Hsiao et al. to build a Transformer decoder that generates pedal-related tokens along with other musical tokens. While the work is done by using inferred sustain pedal information as training data, the result shows hope for further improvement and the importance of the involvement of sustain pedal in tasks of piano performance generations.
Content-based Music Recommendation: Evolution, State of the Art, and Challenges
Jul 25, 2021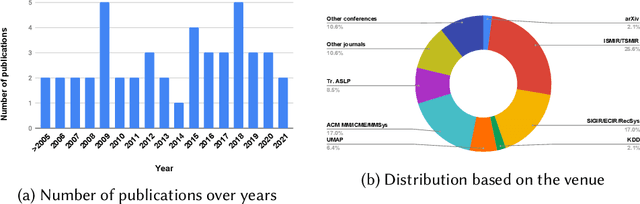
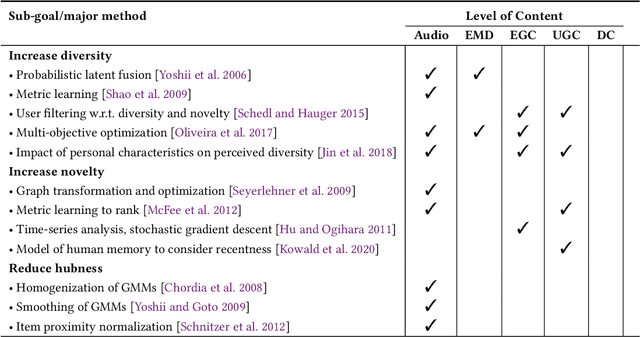
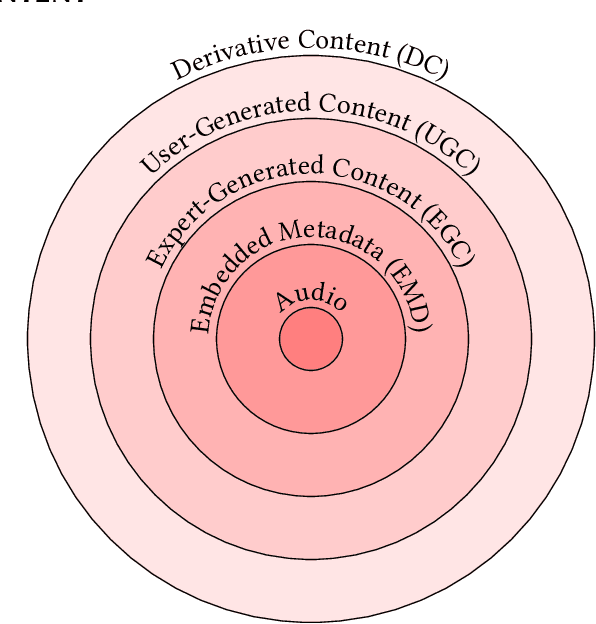
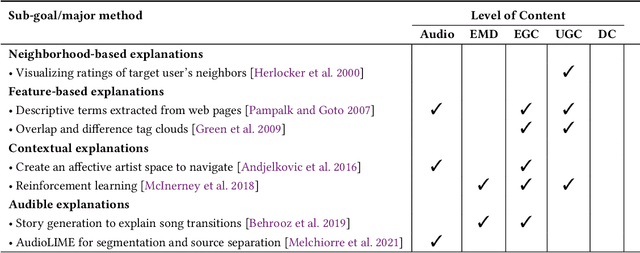
The music domain is among the most important ones for adopting recommender systems technology. In contrast to most other recommendation domains, which predominantly rely on collaborative filtering (CF) techniques, music recommenders have traditionally embraced content-based (CB) approaches. In the past years, music recommendation models that leverage collaborative and content data -- which we refer to as content-driven models -- have been replacing pure CF or CB models. In this survey, we review 47 articles on content-driven music recommendation. Based on a thorough literature analysis, we first propose an onion model comprising five layers, each of which corresponds to a category of music content we identified: signal, embedded metadata, expert-generated content, user-generated content, and derivative content. We provide a detailed characterization of each category along several dimensions. Second, we identify six overarching challenges, according to which we organize our main discussion: increasing recommendation diversity and novelty, providing transparency and explanations, accomplishing context-awareness, recommending sequences of music, improving scalability and efficiency, and alleviating cold start. Each article addressing one or more of these challenges is categorized according to the content layers of our onion model, the article's goal(s), and main methodological choices. Furthermore, articles are discussed in temporal order to shed light on the evolution of content-driven music recommendation strategies. Finally, we provide our personal selection of the persisting grand challenges, which are still waiting to be solved in future research endeavors.
At Your Fingertips: Extracting Piano Fingering Instructions from Videos
Mar 07, 2023
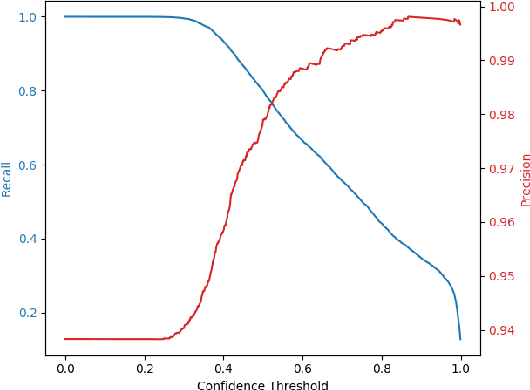
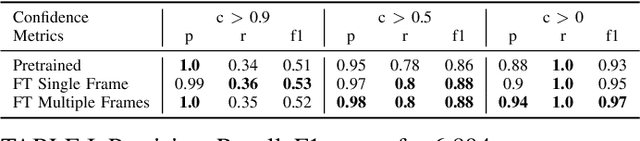
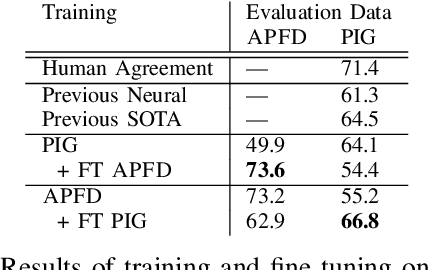
Piano fingering -- knowing which finger to use to play each note in a musical piece, is a hard and important skill to master when learning to play the piano. While some sheet music is available with expert-annotated fingering information, most pieces lack this information, and people often resort to learning the fingering from demonstrations in online videos. We consider the AI task of automating the extraction of fingering information from videos. This is a non-trivial task as fingers are often occluded by other fingers, and it is often not clear from the video which of the keys were pressed, requiring the synchronization of hand position information and knowledge about the notes that were played. We show how to perform this task with high-accuracy using a combination of deep-learning modules, including a GAN-based approach for fine-tuning on out-of-domain data. We extract the fingering information with an f1 score of 97\%. We run the resulting system on 90 videos, resulting in high-quality piano fingering information of 150K notes, the largest available dataset of piano-fingering to date.
VirtualConductor: Music-driven Conducting Video Generation System
Jul 28, 2021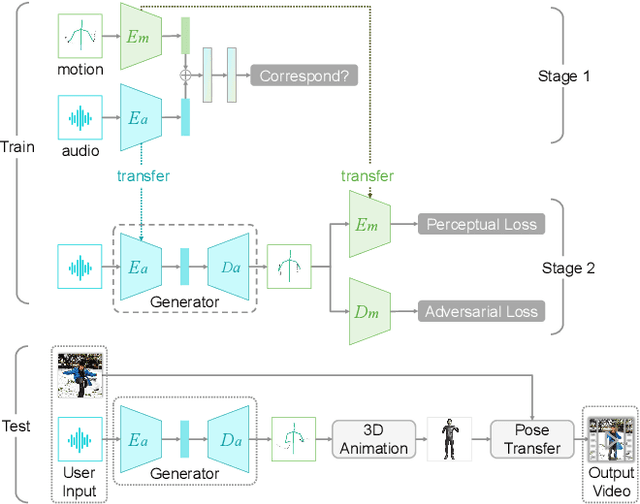
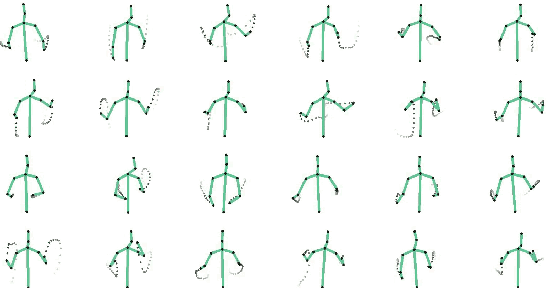


In this demo, we present VirtualConductor, a system that can generate conducting video from any given music and a single user's image. First, a large-scale conductor motion dataset is collected and constructed. Then, we propose Audio Motion Correspondence Network (AMCNet) and adversarial-perceptual learning to learn the cross-modal relationship and generate diverse, plausible, music-synchronized motion. Finally, we combine 3D animation rendering and a pose transfer model to synthesize conducting video from a single given user's image. Therefore, any user can become a virtual conductor through the system.
Spectrograms Are Sequences of Patches
Oct 28, 2022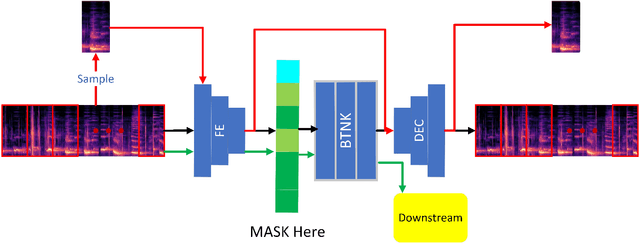
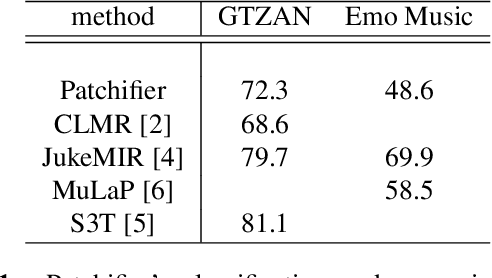
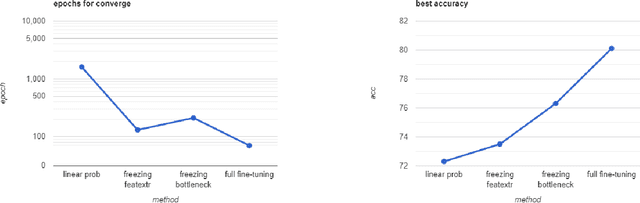
Self-supervised pre-training models have been used successfully in several machine learning domains. However, only a tiny amount of work is related to music. In our work, we treat a spectrogram of music as a series of patches and design a self-supervised model that captures the features of these sequential patches: Patchifier, which makes good use of self-supervised learning methods from both NLP and CV domains. We do not use labeled data for the pre-training process, only a subset of the MTAT dataset containing 16k music clips. After pre-training, we apply the model to several downstream tasks. Our model achieves a considerably acceptable result compared to other audio representation models. Meanwhile, our work demonstrates that it makes sense to consider audio as a series of patch segments.
End-to-end Music Remastering System Using Self-supervised and Adversarial Training
Feb 17, 2022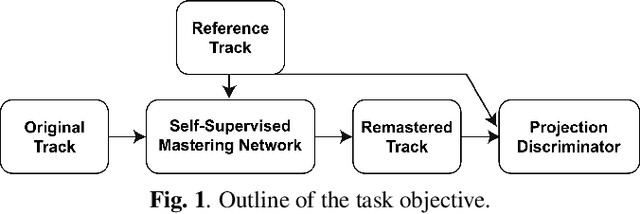

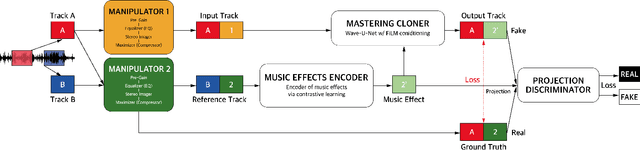
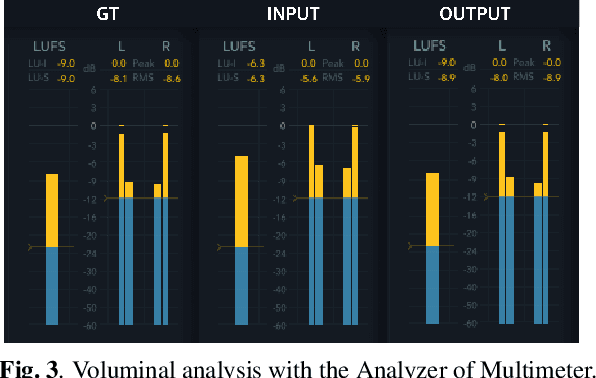
Mastering is an essential step in music production, but it is also a challenging task that has to go through the hands of experienced audio engineers, where they adjust tone, space, and volume of a song. Remastering follows the same technical process, in which the context lies in mastering a song for the times. As these tasks have high entry barriers, we aim to lower the barriers by proposing an end-to-end music remastering system that transforms the mastering style of input audio to that of the target. The system is trained in a self-supervised manner, in which released pop songs were used for training. We also anticipated the model to generate realistic audio reflecting the reference's mastering style by applying a pre-trained encoder and a projection discriminator. We validate our results with quantitative metrics and a subjective listening test and show that the model generated samples of mastering style similar to the target.
Context-Based Music Recommendation Algorithm Evaluation
Dec 16, 2021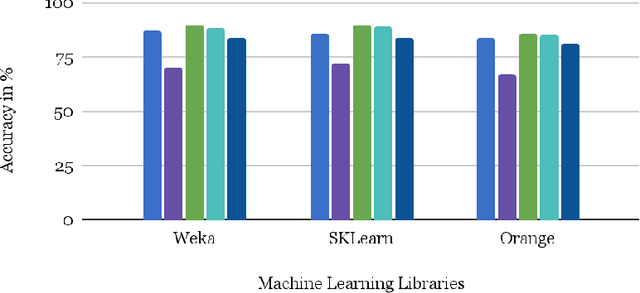
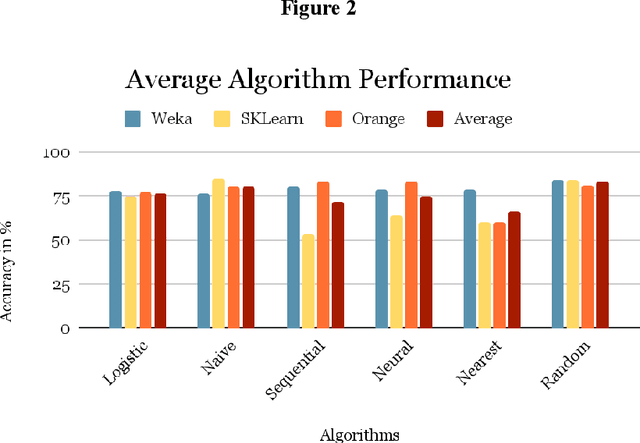
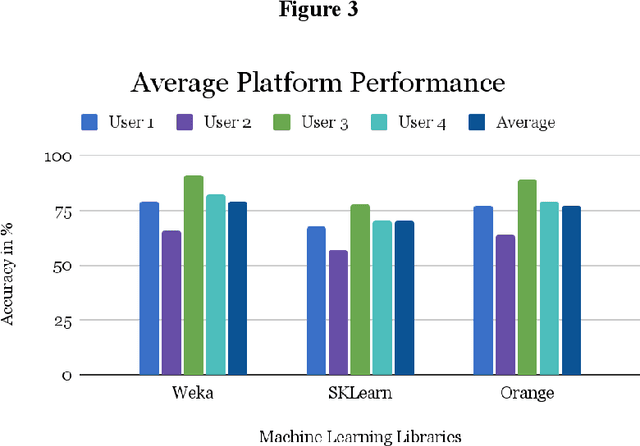
Artificial Intelligence (AI ) has been very successful in creating and predicting music playlists for online users based on their data; data received from users experience using the app such as searching the songs they like. There are lots of current technological advancements in AI due to the competition between music platform owners such as Spotify, Pandora, and more. In this paper, 6 machine learning algorithms and their individual accuracy for predicting whether a user will like a song are explored across 3 different platforms including Weka, SKLearn, and Orange. The algorithms explored include Logistic Regression, Naive Bayes, Sequential Minimal Optimization (SMO), Multilayer Perceptron (Neural Network), Nearest Neighbor, and Random Forest. With the analysis of the specific characteristics of each song provided by the Spotify API [1], Random Forest is the most successful algorithm for predicting whether a user will like a song with an accuracy of 84%. This is higher than the accuracy of 82.72% found by Mungekar using the Random Forest technique and slightly different characteristics of a song [2]. The characteristics in Mungekars Random Forest algorithm focus more on the artist and popularity rather than the sonic features of the songs. Removing the popularity aspect and focusing purely on the sonic qualities improve the accuracy of recommendations. Finally, this paper shows how song prediction can be accomplished without any monetary investments, and thus, inspires an idea of what amazing results can be accomplished with full financial research.