 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Rhythm is a Dancer: Music-Driven Motion Synthesis with Global Structure
Nov 23, 2021
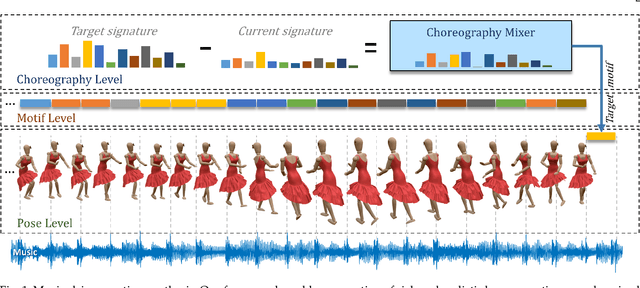
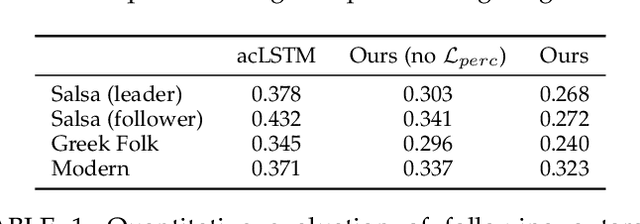
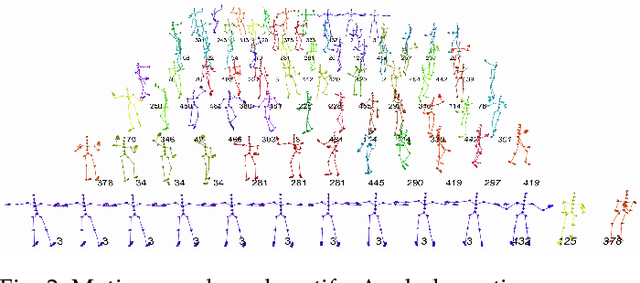
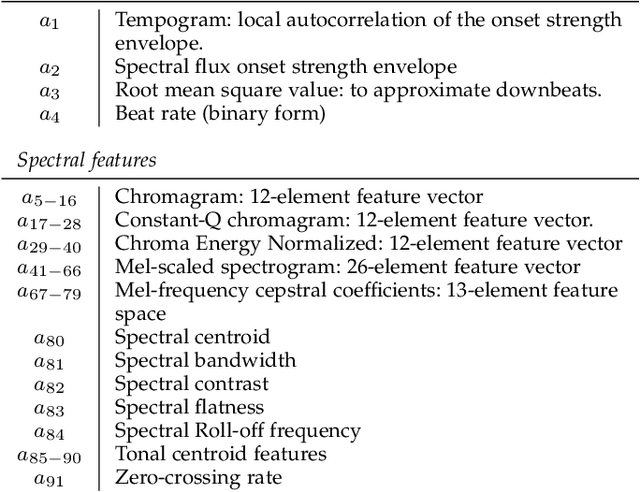
Synthesizing human motion with a global structure, such as a choreography, is a challenging task. Existing methods tend to concentrate on local smooth pose transitions and neglect the global context or the theme of the motion. In this work, we present a music-driven motion synthesis framework that generates long-term sequences of human motions which are synchronized with the input beats, and jointly form a global structure that respects a specific dance genre. In addition, our framework enables generation of diverse motions that are controlled by the content of the music, and not only by the beat. Our music-driven dance synthesis framework is a hierarchical system that consists of three levels: pose, motif, and choreography. The pose level consists of an LSTM component that generates temporally coherent sequences of poses. The motif level guides sets of consecutive poses to form a movement that belongs to a specific distribution using a novel motion perceptual-loss. And the choreography level selects the order of the performed movements and drives the system to follow the global structure of a dance genre. Our results demonstrate the effectiveness of our music-driven framework to generate natural and consistent movements on various dance types, having control over the content of the synthesized motions, and respecting the overall structure of the dance.
Mostra: A Flexible Balancing Framework to Trade-off User, Artist and Platform Objectives for Music Sequencing
Apr 22, 2022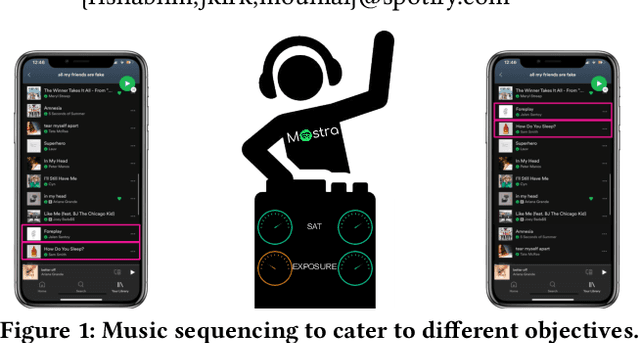
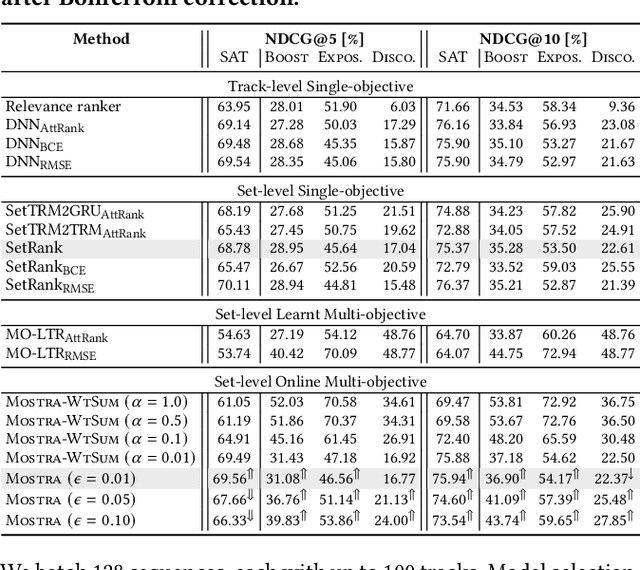

We consider the task of sequencing tracks on music streaming platforms where the goal is to maximise not only user satisfaction, but also artist- and platform-centric objectives, needed to ensure long-term health and sustainability of the platform. Grounding the work across four objectives: Sat, Discovery, Exposure and Boost, we highlight the need and the potential to trade-off performance across these objectives, and propose Mostra, a Set Transformer-based encoder-decoder architecture equipped with submodular multi-objective beam search decoding. The proposed model affords system designers the power to balance multiple goals, and dynamically control the impact on one objective to satisfy other objectives. Through extensive experiments on data from a large-scale music streaming platform, we present insights on the trade-offs that exist across different objectives, and demonstrate that the proposed framework leads to a superior, just-in-time balancing across the various metrics of interest.
Barwise Compression Schemes for Audio-Based Music Structure Analysis
Feb 10, 2022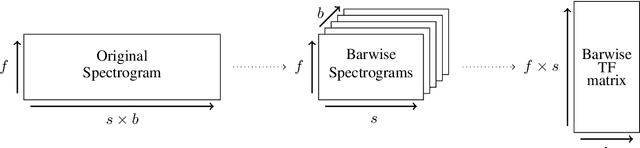
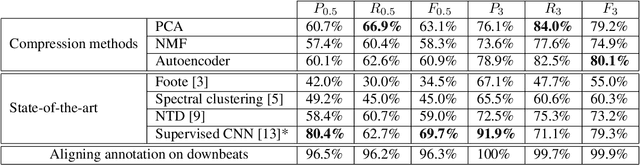
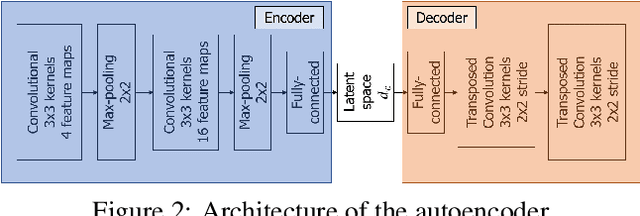
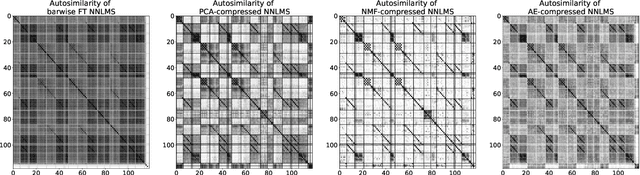
Music Structure Analysis (MSA) consists in segmenting a music piece in several distinct sections. We approach MSA within a compression framework, under the hypothesis that the structure is more easily revealed by a simplified representation of the original content of the song. More specifically, under the hypothesis that MSA is correlated with similarities occurring at the bar scale, linear and non-linear compression schemes can be applied to barwise audio signals. Compressed representations capture the most salient components of the different bars in the song and are then used to infer the song structure using a dynamic programming algorithm. This work explores both low-rank approximation models such as Principal Component Analysis or Nonnegative Matrix Factorization and "piece-specific" Auto-Encoding Neural Networks, with the objective to learn latent representations specific to a given song. Such approaches do not rely on supervision nor annotations, which are well-known to be tedious to collect and possibly ambiguous in MSA description. In our experiments, several unsupervised compression schemes achieve a level of performance comparable to that of state-of-the-art supervised methods (for 3s tolerance) on the RWC-Pop dataset, showcasing the importance of the barwise compression processing for MSA.
Analyzing Images for Music Recommendation
May 15, 2021
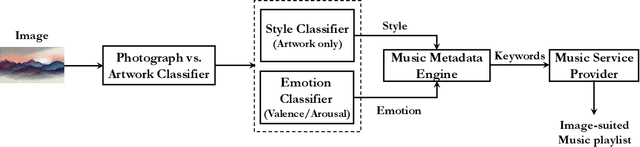


Experiencing images with suitable music can greatly enrich the overall user experience. The proposed image analysis method treats an artwork image differently from a photograph image. Automatic image classification is performed using deep-learning based models. An illustrative analysis showcasing the ability of our deep-models to inherently learn and utilize perceptually relevant features when classifying artworks is also presented. The Mean Opinion Score (MOS) obtained from subjective assessments of the respective image and recommended music pairs supports the effectiveness of our approach.
MusicNet: Compact Convolutional Neural Network for Real-time Background Music Detection
Oct 08, 2021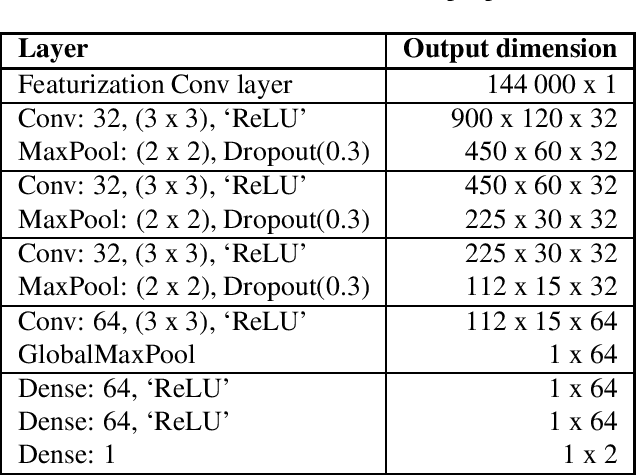
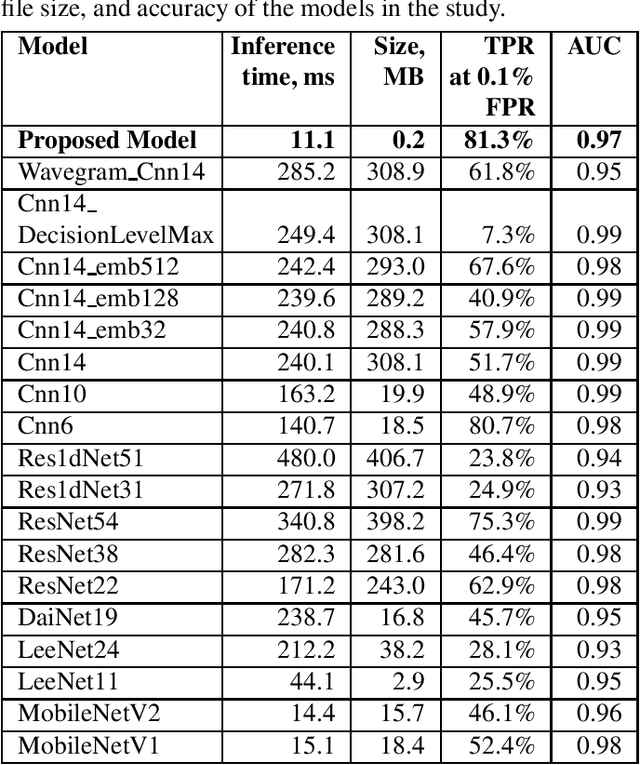
With the recent growth of remote and hybrid work, online meetings often encounter challenging audio contexts such as background noise, music, and echo. Accurate real-time detection of music events can help to improve the user experience in such scenarios, e.g., by switching to high-fidelity music-specific codec or selecting the optimal noise suppression model. In this paper, we present MusicNet -- a compact high-performance model for detecting background music in the real-time communications pipeline. In online video meetings, which is our main use case, music almost always co-occurs with speech and background noises, making the accurate classification quite challenging. The proposed model is a binary classifier that consists of a compact convolutional neural network core preceded by an in-model featurization layer. It takes 9 seconds of raw audio as input and does not require any model-specific featurization on the client. We train our model on a balanced subset of the AudioSet data and use 1000 crowd-sourced real test clips to validate the model. Finally, we compare MusicNet performance to 20 other state-of-the-art models. Our classifier gives a true positive rate of 81.3% at a 0.1% false positive rate, which is significantly better than any other model in the study. Our model is also 10x smaller and has 4x faster inference than the comparable baseline.
At Your Fingertips: Extracting Piano Fingering Instructions from Videos
Mar 07, 2023
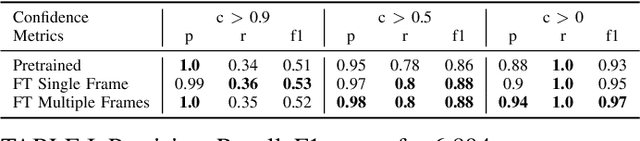
Piano fingering -- knowing which finger to use to play each note in a musical piece, is a hard and important skill to master when learning to play the piano. While some sheet music is available with expert-annotated fingering information, most pieces lack this information, and people often resort to learning the fingering from demonstrations in online videos. We consider the AI task of automating the extraction of fingering information from videos. This is a non-trivial task as fingers are often occluded by other fingers, and it is often not clear from the video which of the keys were pressed, requiring the synchronization of hand position information and knowledge about the notes that were played. We show how to perform this task with high-accuracy using a combination of deep-learning modules, including a GAN-based approach for fine-tuning on out-of-domain data. We extract the fingering information with an f1 score of 97\%. We run the resulting system on 90 videos, resulting in high-quality piano fingering information of 150K notes, the largest available dataset of piano-fingering to date.
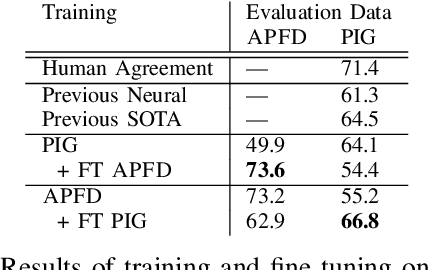
Kinit Classification in Ethiopian Chants, Azmaris and Modern Music: A New Dataset and CNN Benchmark
Jan 20, 2022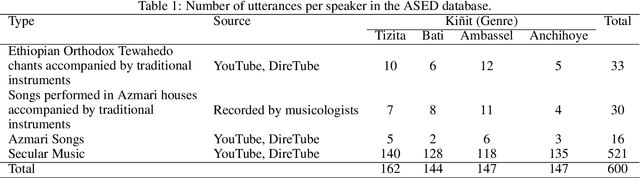
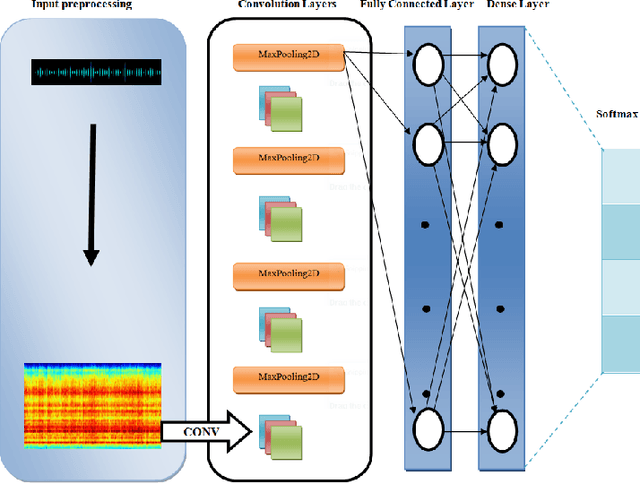
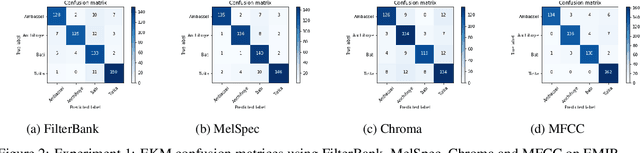
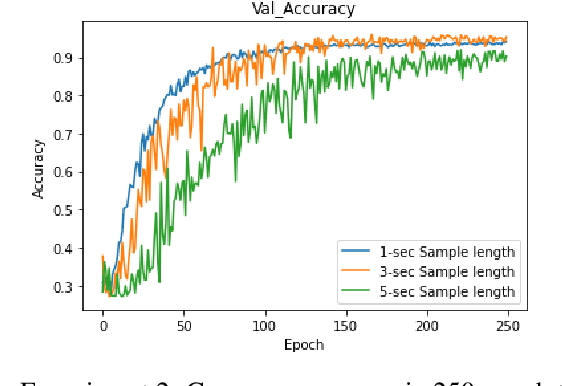
In this paper, we create EMIR, the first-ever Music Information Retrieval dataset for Ethiopian music. EMIR is freely available for research purposes and contains 600 sample recordings of Orthodox Tewahedo chants, traditional Azmari songs and contemporary Ethiopian secular music. Each sample is classified by five expert judges into one of four well-known Ethiopian Kinits, Tizita, Bati, Ambassel and Anchihoye. Each Kinit uses its own pentatonic scale and also has its own stylistic characteristics. Thus, Kinit classification needs to combine scale identification with genre recognition. After describing the dataset, we present the Ethio Kinits Model (EKM), based on VGG, for classifying the EMIR clips. In Experiment 1, we investigated whether Filterbank, Mel-spectrogram, Chroma, or Mel-frequency Cepstral coefficient (MFCC) features work best for Kinit classification using EKM. MFCC was found to be superior and was therefore adopted for Experiment 2, where the performance of EKM models using MFCC was compared using three different audio sample lengths. 3s length gave the best results. In Experiment 3, EKM and four existing models were compared on the EMIR dataset: AlexNet, ResNet50, VGG16 and LSTM. EKM was found to have the best accuracy (95.00%) as well as the fastest training time. We hope this work will encourage others to explore Ethiopian music and to experiment with other models for Kinit classification.
Differential Music: Automated Music Generation Using LSTM Networks with Representation Based on Melodic and Harmonic Intervals
Aug 23, 2021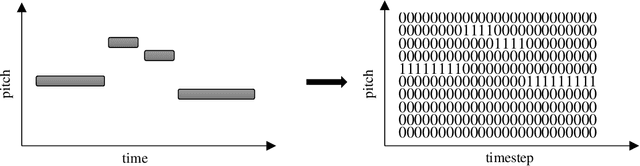

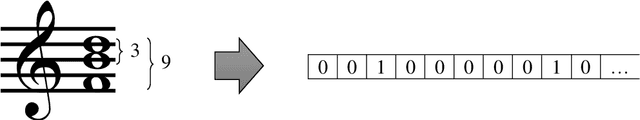
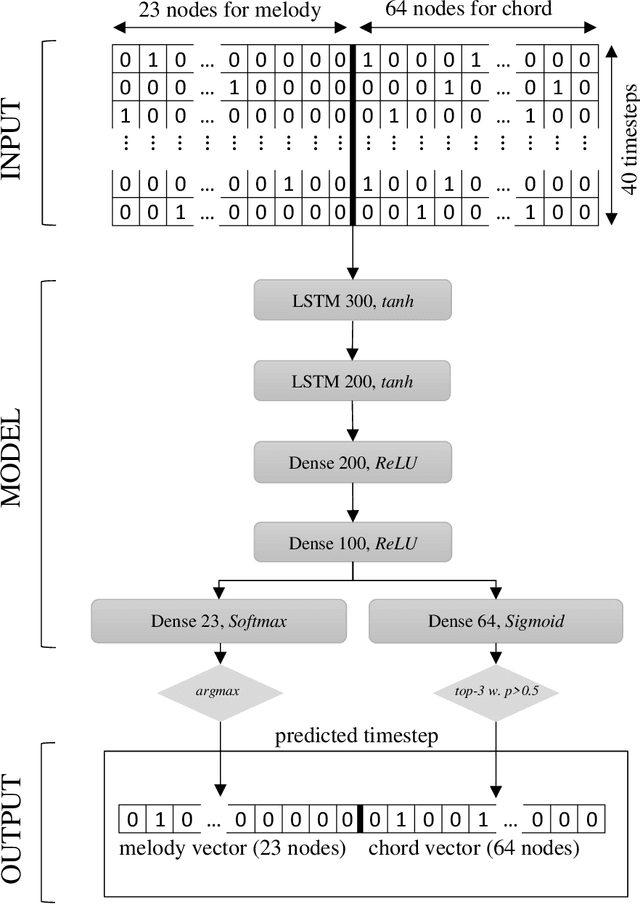
This paper presents a generative AI model for automated music composition with LSTM networks that takes a novel approach at encoding musical information which is based on movement in music rather than absolute pitch. Melodies are encoded as a series of intervals rather than a series of pitches, and chords are encoded as the set of intervals that each chord note makes with the melody at each timestep. Experimental results show promise as they sound musical and tonal. There are also weaknesses to this method, mainly excessive modulations in the compositions, but that is expected from the nature of the encoding. This issue is discussed later in the paper and is a potential topic for future work.
1D CNN Architectures for Music Genre Classification
May 15, 2021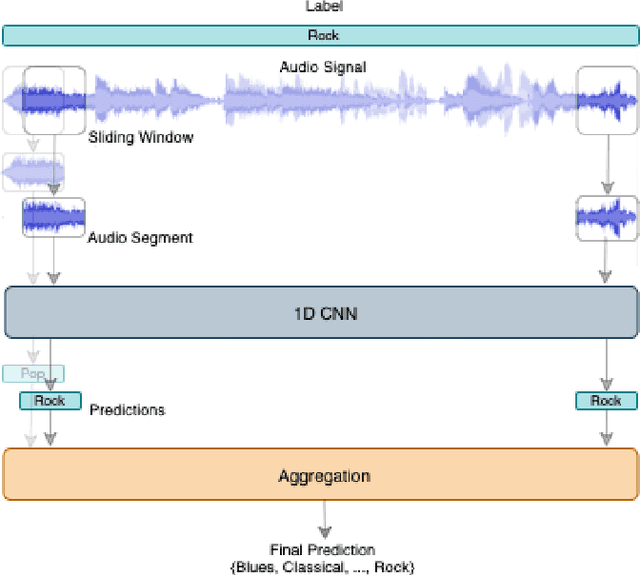
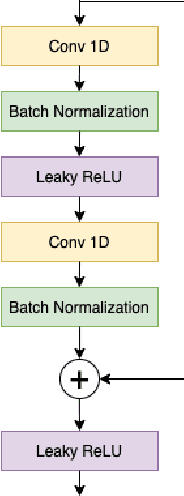
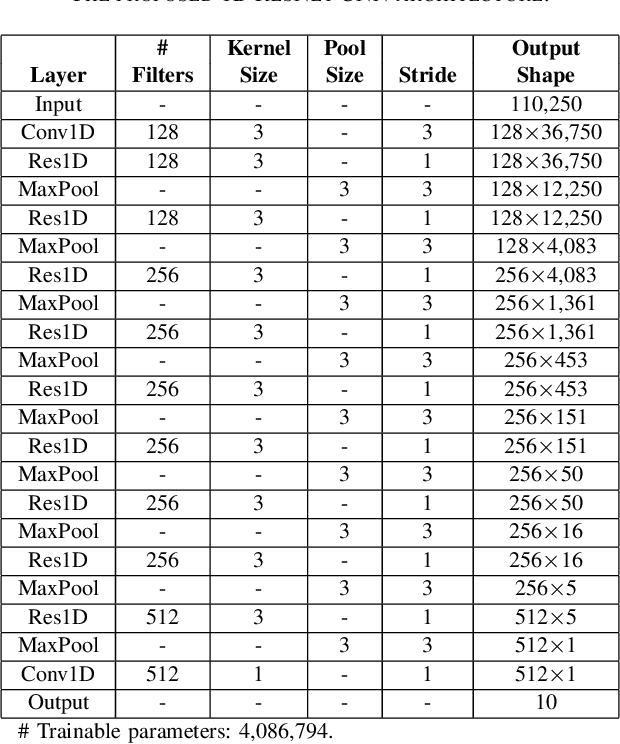
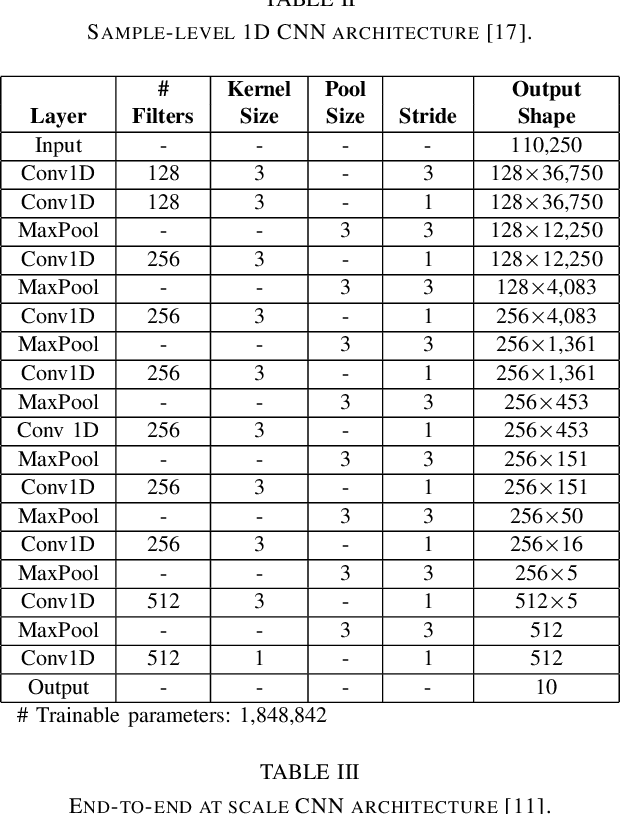
This paper proposes a 1D residual convolutional neural network (CNN) architecture for music genre classification and compares it with other recent 1D CNN architectures. The 1D CNNs learn a representation and a discriminant directly from the raw audio signal. Several convolutional layers capture the time-frequency characteristics of the audio signal and learn various filters relevant to the music genre recognition task. The proposed approach splits the audio signal into overlapped segments using a sliding window to comply with the fixed-length input constraint of the 1D CNNs. As a result, music genre classification can be carried out on a single audio segment or on the aggregation of the predictions on several audio segments, which improves the final accuracy. The performance of the proposed 1D residual CNN is assessed on a public dataset of 1,000 audio clips. The experimental results have shown that it achieves 80.93% of mean accuracy in classifying music genres and outperforms other 1D CNN architectures.
Efficiency 360: Efficient Vision Transformers
Feb 17, 2023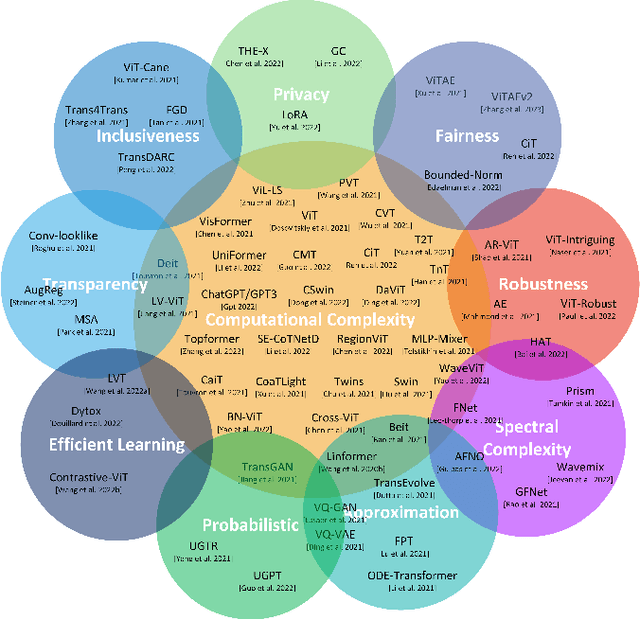
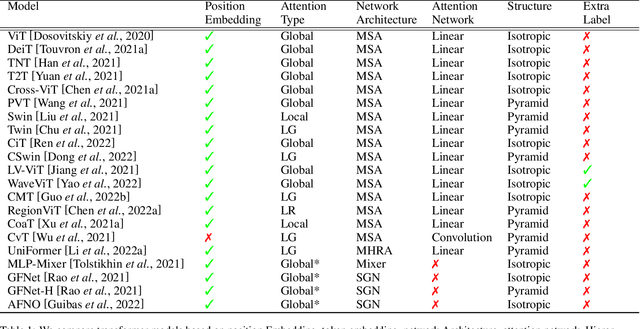
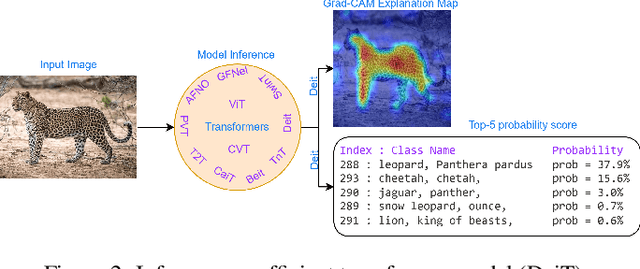
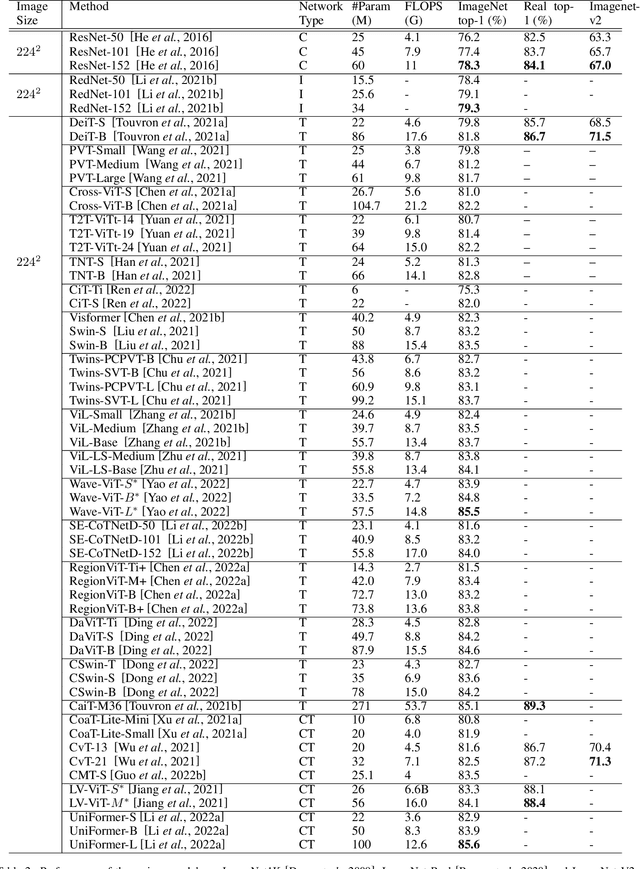
Transformers are widely used for solving tasks in natural language processing, computer vision, speech, and music domains. In this paper, we talk about the efficiency of transformers in terms of memory (the number of parameters), computation cost (number of floating points operations), and performance of models, including accuracy, the robustness of the model, and fair \& bias-free features. We mainly discuss the vision transformer for the image classification task. Our contribution is to introduce an efficient 360 framework, which includes various aspects of the vision transformer, to make it more efficient for industrial applications. By considering those applications, we categorize them into multiple dimensions such as privacy, robustness, transparency, fairness, inclusiveness, continual learning, probabilistic models, approximation, computational complexity, and spectral complexity. We compare various vision transformer models based on their performance, the number of parameters, and the number of floating point operations (FLOPs) on multiple datasets.