 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Self-Supervised Hierarchical Metrical Structure Modeling
Oct 31, 2022
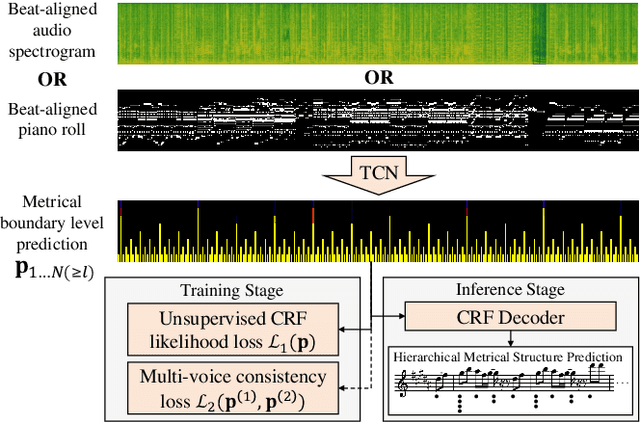


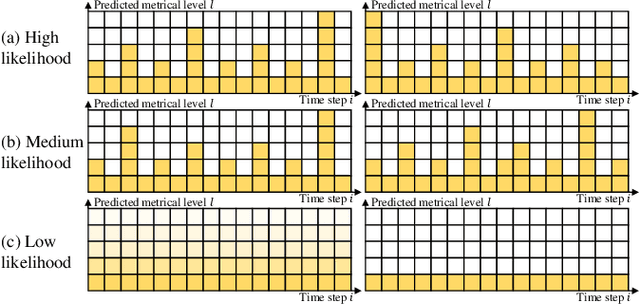
We propose a novel method to model hierarchical metrical structures for both symbolic music and audio signals in a self-supervised manner with minimal domain knowledge. The model trains and inferences on beat-aligned music signals and predicts an 8-layer hierarchical metrical tree from beat, measure to the section level. The training procedural does not require any hierarchical metrical labeling except for beats, purely relying on the nature of metrical regularity and inter-voice consistency as inductive biases. We show in experiments that the method achieves comparable performance with supervised baselines on multiple metrical structure analysis tasks on both symbolic music and audio signals. All demos, source code and pre-trained models are publicly available on GitHub.
Maths, Computation and Flamenco: overview and challenges
Sep 22, 2022Flamenco is a rich performance-oriented art music genre from Southern Spain which attracts a growing community of aficionados around the globe. Due to its improvisational and expressive nature, its unique musical characteristics, and the fact that the genre is largely undocumented, flamenco poses a number of interesting mathematical and computational challenges. Most existing approaches in Musical Information Retrieval (MIR) were developed in the context of popular or classical music and do often not generalize well to non-Western music traditions, in particular when the underlying music theoretical assumptions do not hold for these genres. Over the recent decade, a number of computational problems related to the automatic analysis of flamenco music have been defined and several methods addressing a variety of musical aspects have been proposed. This paper provides an overview of the challenges which arise in the context of computational analysis of flamenco music and outlines an overview of existing approaches.
Audio-Visual Grouping Network for Sound Localization from Mixtures
Mar 29, 2023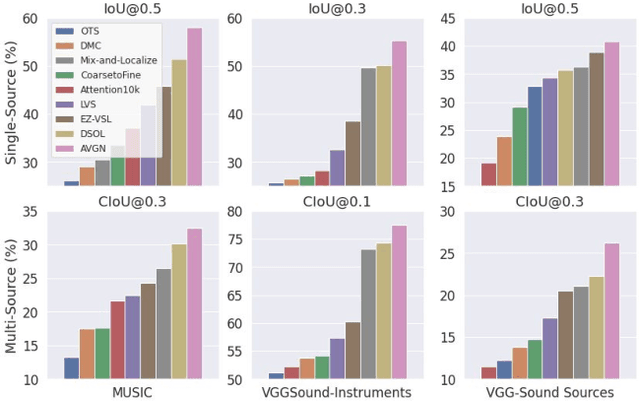
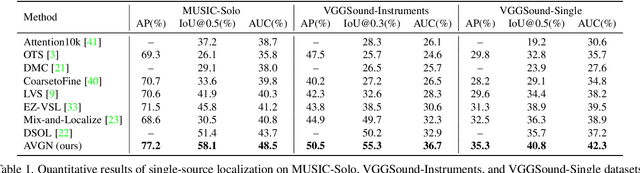
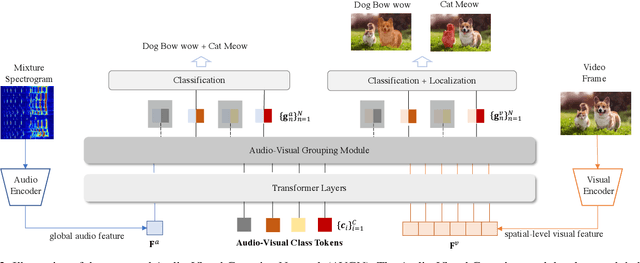
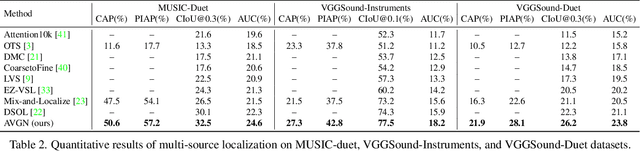
Sound source localization is a typical and challenging task that predicts the location of sound sources in a video. Previous single-source methods mainly used the audio-visual association as clues to localize sounding objects in each image. Due to the mixed property of multiple sound sources in the original space, there exist rare multi-source approaches to localizing multiple sources simultaneously, except for one recent work using a contrastive random walk in the graph with images and separated sound as nodes. Despite their promising performance, they can only handle a fixed number of sources, and they cannot learn compact class-aware representations for individual sources. To alleviate this shortcoming, in this paper, we propose a novel audio-visual grouping network, namely AVGN, that can directly learn category-wise semantic features for each source from the input audio mixture and image to localize multiple sources simultaneously. Specifically, our AVGN leverages learnable audio-visual class tokens to aggregate class-aware source features. Then, the aggregated semantic features for each source can be used as guidance to localize the corresponding visual regions. Compared to existing multi-source methods, our new framework can localize a flexible number of sources and disentangle category-aware audio-visual representations for individual sound sources. We conduct extensive experiments on MUSIC, VGGSound-Instruments, and VGG-Sound Sources benchmarks. The results demonstrate that the proposed AVGN can achieve state-of-the-art sounding object localization performance on both single-source and multi-source scenarios. Code is available at \url{https://github.com/stoneMo/AVGN}.
KUIELab-MDX-Net: A Two-Stream Neural Network for Music Demixing
Nov 24, 2021

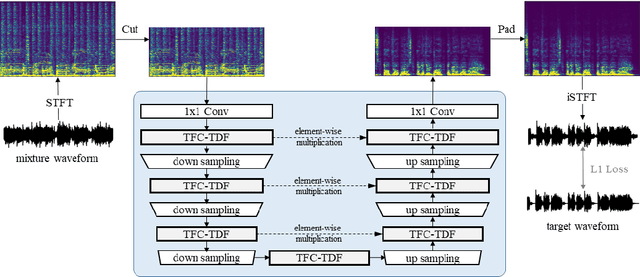
Recently, many methods based on deep learning have been proposed for music source separation. Some state-of-the-art methods have shown that stacking many layers with many skip connections improve the SDR performance. Although such a deep and complex architecture shows outstanding performance, it usually requires numerous computing resources and time for training and evaluation. This paper proposes a two-stream neural network for music demixing, called KUIELab-MDX-Net, which shows a good balance of performance and required resources. The proposed model has a time-frequency branch and a time-domain branch, where each branch separates stems, respectively. It blends results from two streams to generate the final estimation. KUIELab-MDX-Net took second place on leaderboard A and third place on leaderboard B in the Music Demixing Challenge at ISMIR 2021. This paper also summarizes experimental results on another benchmark, MUSDB18. Our source code is available online.
Continuous descriptor-based control for deep audio synthesis
Feb 27, 2023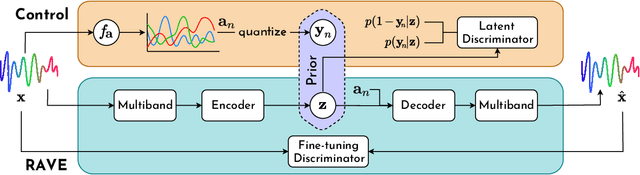

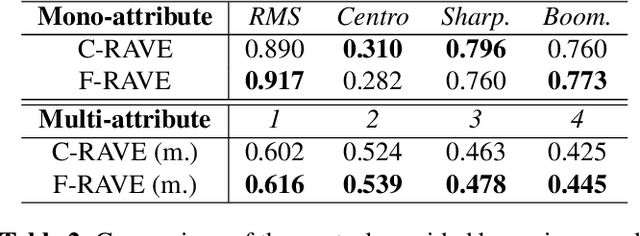
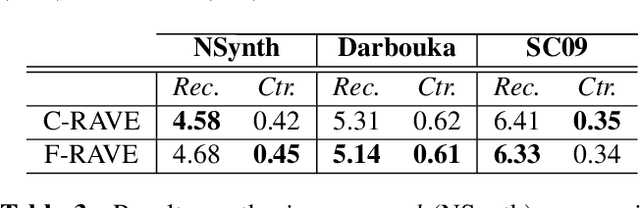
Despite significant advances in deep models for music generation, the use of these techniques remains restricted to expert users. Before being democratized among musicians, generative models must first provide expressive control over the generation, as this conditions the integration of deep generative models in creative workflows. In this paper, we tackle this issue by introducing a deep generative audio model providing expressive and continuous descriptor-based control, while remaining lightweight enough to be embedded in a hardware synthesizer. We enforce the controllability of real-time generation by explicitly removing salient musical features in the latent space using an adversarial confusion criterion. User-specified features are then reintroduced as additional conditioning information, allowing for continuous control of the generation, akin to a synthesizer knob. We assess the performance of our method on a wide variety of sounds including instrumental, percussive and speech recordings while providing both timbre and attributes transfer, allowing new ways of generating sounds.
Relating Human Perception of Musicality to Prediction in a Predictive Coding Model
Oct 29, 2022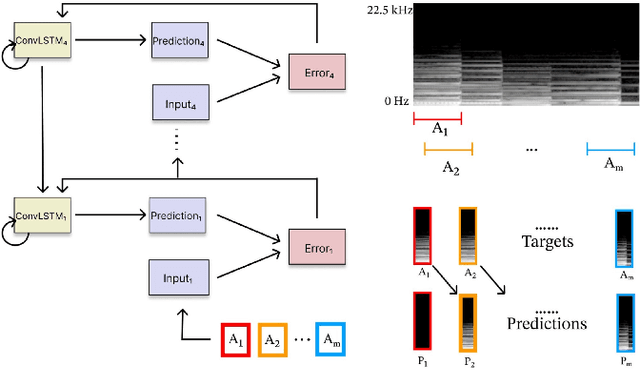
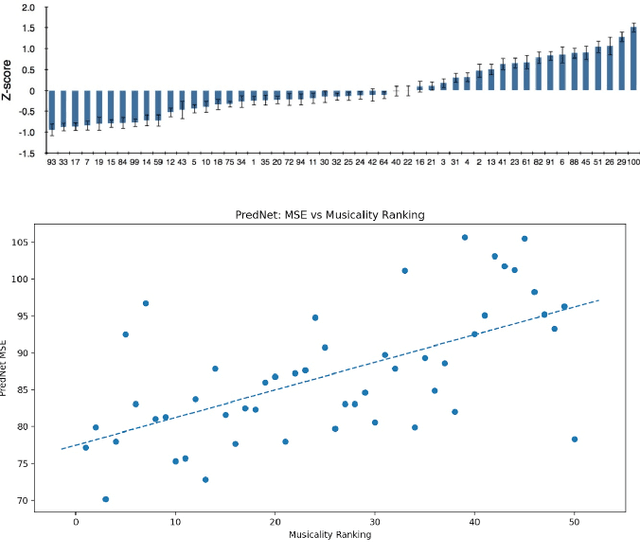
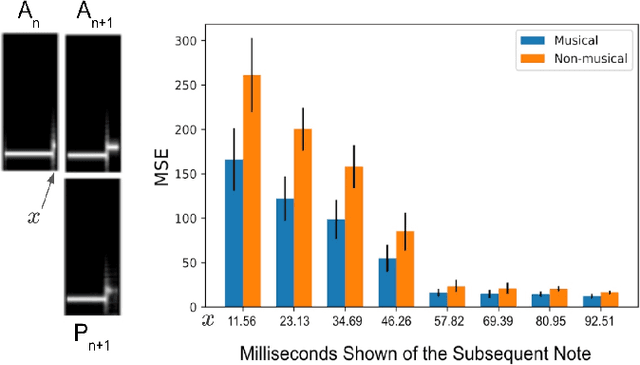
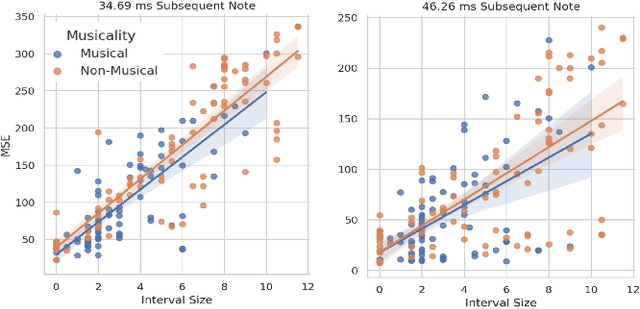
We explore the use of a neural network inspired by predictive coding for modeling human music perception. This network was developed based on the computational neuroscience theory of recurrent interactions in the hierarchical visual cortex. When trained with video data using self-supervised learning, the model manifests behaviors consistent with human visual illusions. Here, we adapt this network to model the hierarchical auditory system and investigate whether it will make similar choices to humans regarding the musicality of a set of random pitch sequences. When the model is trained with a large corpus of instrumental classical music and popular melodies rendered as mel spectrograms, it exhibits greater prediction errors for random pitch sequences that are rated less musical by human subjects. We found that the prediction error depends on the amount of information regarding the subsequent note, the pitch interval, and the temporal context. Our findings suggest that predictability is correlated with human perception of musicality and that a predictive coding neural network trained on music can be used to characterize the features and motifs contributing to human perception of music.
Predicting Music Relistening Behavior Using the ACT-R Framework
Aug 05, 2021
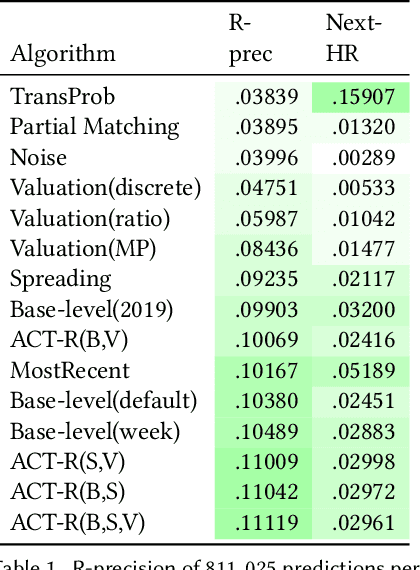
Providing suitable recommendations is of vital importance to improve the user satisfaction of music recommender systems. Here, users often listen to the same track repeatedly and appreciate recommendations of the same song multiple times. Thus, accounting for users' relistening behavior is critical for music recommender systems. In this paper, we describe a psychology-informed approach to model and predict music relistening behavior that is inspired by studies in music psychology, which relate music preferences to human memory. We adopt a well-established psychological theory of human cognition that models the operations of human memory, i.e., Adaptive Control of Thought-Rational (ACT-R). In contrast to prior work, which uses only the base-level component of ACT-R, we utilize five components of ACT-R, i.e., base-level, spreading, partial matching, valuation, and noise, to investigate the effect of five factors on music relistening behavior: (i) recency and frequency of prior exposure to tracks, (ii) co-occurrence of tracks, (iii) the similarity between tracks, (iv) familiarity with tracks, and (v) randomness in behavior. On a dataset of 1.7 million listening events from Last.fm, we evaluate the performance of our approach by sequentially predicting the next track(s) in user sessions. We find that recency and frequency of prior exposure to tracks is an effective predictor of relistening behavior. Besides, considering the co-occurrence of tracks and familiarity with tracks further improves performance in terms of R-precision. We hope that our work inspires future research on the merits of considering cognitive aspects of memory retrieval to model and predict complex user behavior.
Efficiency 360: Efficient Vision Transformers
Feb 23, 2023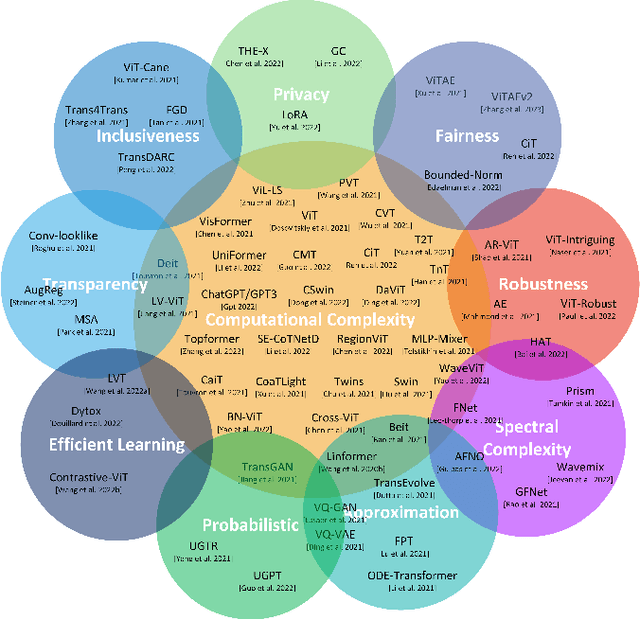
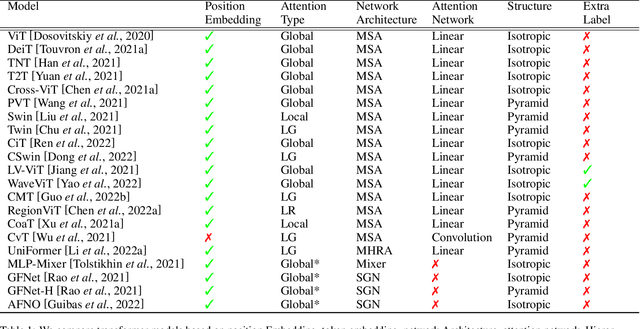
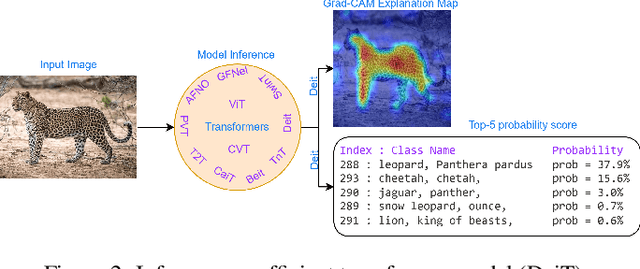
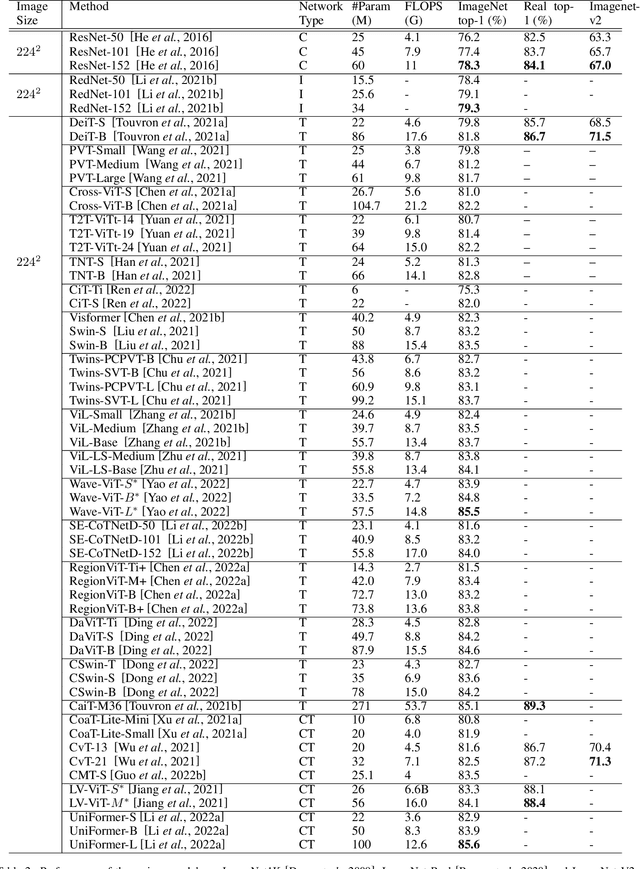
Transformers are widely used for solving tasks in natural language processing, computer vision, speech, and music domains. In this paper, we talk about the efficiency of transformers in terms of memory (the number of parameters), computation cost (number of floating points operations), and performance of models, including accuracy, the robustness of the model, and fair \& bias-free features. We mainly discuss the vision transformer for the image classification task. Our contribution is to introduce an efficient 360 framework, which includes various aspects of the vision transformer, to make it more efficient for industrial applications. By considering those applications, we categorize them into multiple dimensions such as privacy, robustness, transparency, fairness, inclusiveness, continual learning, probabilistic models, approximation, computational complexity, and spectral complexity. We compare various vision transformer models based on their performance, the number of parameters, and the number of floating point operations (FLOPs) on multiple datasets.
Rhythm is a Dancer: Music-Driven Motion Synthesis with Global Structure
Nov 23, 2021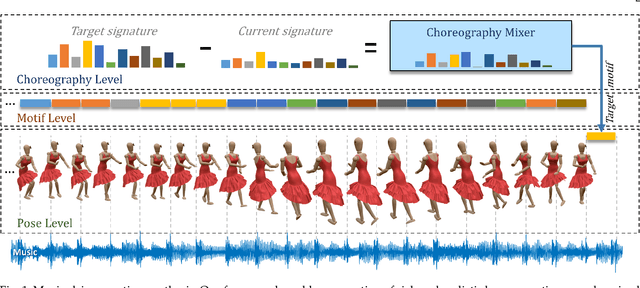
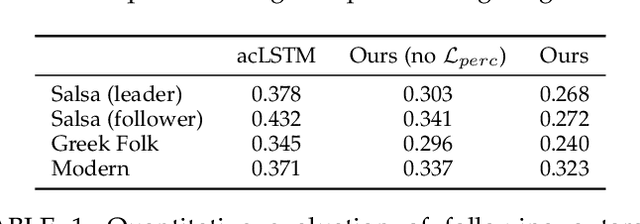
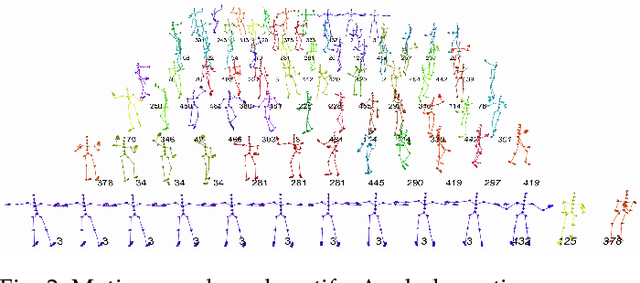
Synthesizing human motion with a global structure, such as a choreography, is a challenging task. Existing methods tend to concentrate on local smooth pose transitions and neglect the global context or the theme of the motion. In this work, we present a music-driven motion synthesis framework that generates long-term sequences of human motions which are synchronized with the input beats, and jointly form a global structure that respects a specific dance genre. In addition, our framework enables generation of diverse motions that are controlled by the content of the music, and not only by the beat. Our music-driven dance synthesis framework is a hierarchical system that consists of three levels: pose, motif, and choreography. The pose level consists of an LSTM component that generates temporally coherent sequences of poses. The motif level guides sets of consecutive poses to form a movement that belongs to a specific distribution using a novel motion perceptual-loss. And the choreography level selects the order of the performed movements and drives the system to follow the global structure of a dance genre. Our results demonstrate the effectiveness of our music-driven framework to generate natural and consistent movements on various dance types, having control over the content of the synthesized motions, and respecting the overall structure of the dance.