 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Adaptive music: Automated music composition and distribution
Jul 25, 2020
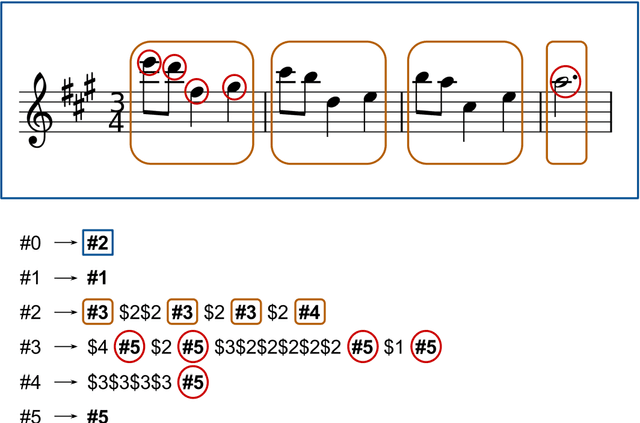


Creativity, or the ability to produce new useful ideas, is commonly associated to the human being, but there are many other examples in nature where this phenomenon can be observed. Inspired by this fact, in engineering and particularly in computational sciences, many different models have been developed to tackle a number of problems. Music, a form of art broadly present along the human history, is the main field addressed in this thesis, taking advantage of the kind of ideas that bring diversity and creativity to nature and computation. We present Melomics, an algorithmic composition method based on evolutionary search, with a genetic encoding of the solutions that are interpreted in a complex developmental process that leads to music in standard formats. This bioinspired compositional system has exhibited a highly creative power and versatility to produce music of different type, which in many occasions has proven to be indistinguishable from the music made by human composers. The system also has enabled the emergence of a set of completely novel applications: from effective tools that help anyone to easily obtain the precise music they need, to radically new uses like adaptive music for therapy, amusement or many other purposes. It is clear to us that there is yet much research to be done in this field and that countless and new unimaginable uses will derive from it.
Deep Augmented MUSIC Algorithm for Data-Driven DoA Estimation
Sep 22, 2021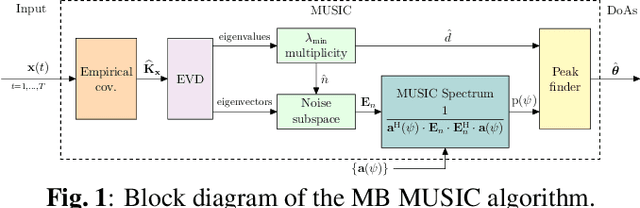
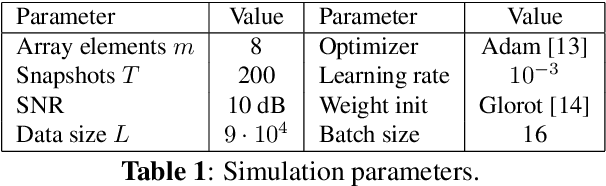
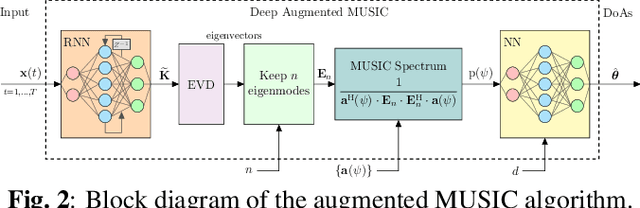
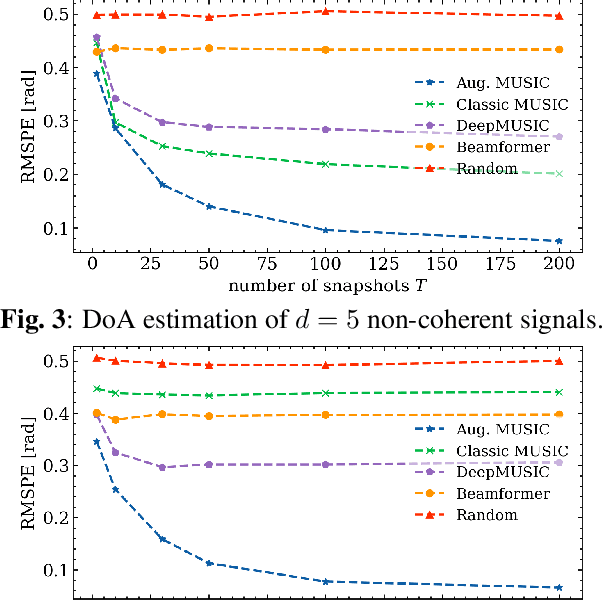
Direction of arrival (DoA) estimation is a crucial task in sensor array signal processing, giving rise to various successful model-based (MB) algorithms as well as recently developed data-driven (DD) methods. This paper introduces a new hybrid MB/DD DoA estimation architecture, based on the classical multiple signal classification (MUSIC) algorithm. Our approach augments crucial aspects of the original MUSIC structure with specifically designed neural architectures, allowing it to overcome certain limitations of the purely MB method, such as its inability to successfully localize coherent sources. The deep augmented MUSIC algorithm is shown to outperform its unaltered version with a superior resolution.
Multi-Channel Automatic Music Transcription Using Tensor Algebra
Jul 23, 2021

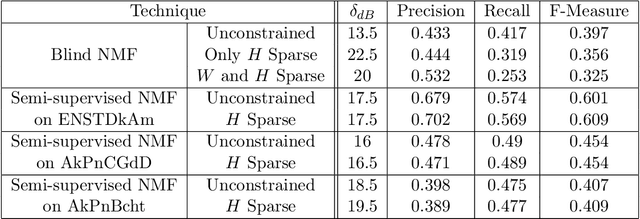
Music is an art, perceived in unique ways by every listener, coming from acoustic signals. In the meantime, standards as musical scores exist to describe it. Even if humans can make this transcription, it is costly in terms of time and efforts, even more with the explosion of information consecutively to the rise of the Internet. In that sense, researches are driven in the direction of Automatic Music Transcription. While this task is considered solved in the case of single notes, it is still open when notes superpose themselves, forming chords. This report aims at developing some of the existing techniques towards Music Transcription, particularly matrix factorization, and introducing the concept of multi-channel automatic music transcription. This concept will be explored with mathematical objects called tensors.
Melody Extraction from Polyphonic Music by Deep Learning Approaches: A Review
Feb 02, 2022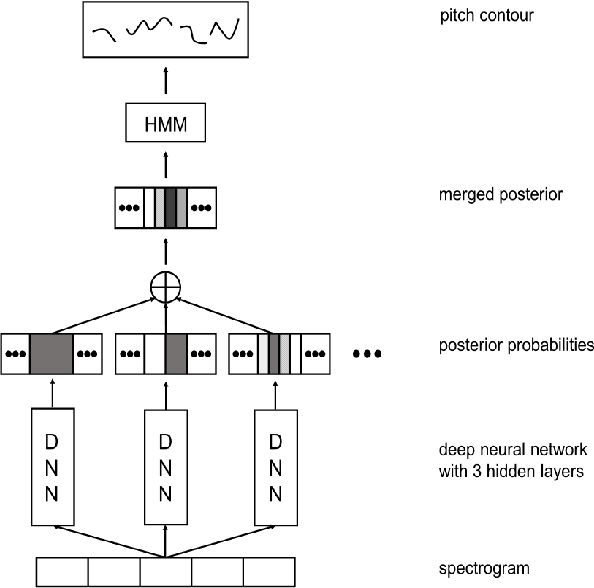
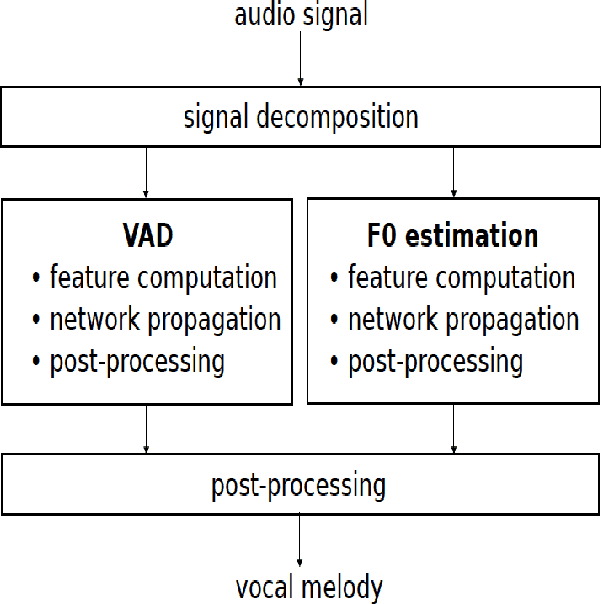
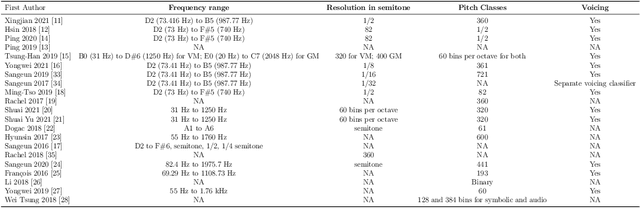
Melody extraction is a vital music information retrieval task among music researchers for its potential applications in education pedagogy and the music industry. Melody extraction is a notoriously challenging task due to the presence of background instruments. Also, often melodic source exhibits similar characteristics to that of the other instruments. The interfering background accompaniment with the vocals makes extracting the melody from the mixture signal much more challenging. Until recently, classical signal processing-based melody extraction methods were quite popular among melody extraction researchers. The ability of the deep learning models to model large-scale data and the ability of the models to learn automatic features by exploiting spatial and temporal dependencies inspired many researchers to adopt deep learning models for melody extraction. In this paper, an attempt has been made to review the up-to-date data-driven deep learning approaches for melody extraction from polyphonic music. The available deep models have been categorized based on the type of neural network used and the output representation they use for predicting melody. Further, the architectures of the 25 melody extraction models are briefly presented. The loss functions used to optimize the model parameters of the melody extraction models are broadly categorized into four categories and briefly describe the loss functions used by various melody extraction models. Also, the various input representations adopted by the melody extraction models and the parameter settings are deeply described. A section describing the explainability of the block-box melody extraction deep neural networks is included. The performance of 25 melody extraction methods is compared. The possible future directions to explore/improve the melody extraction methods are also presented in the paper.
Crossword: A Semantic Approach to Data Compression via Masking
Apr 03, 2023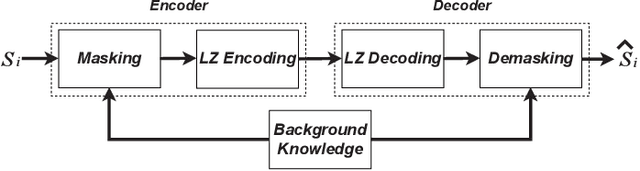
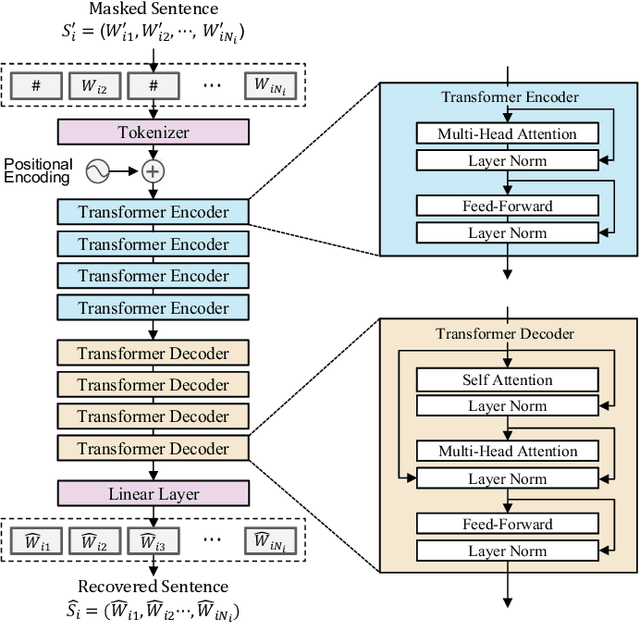
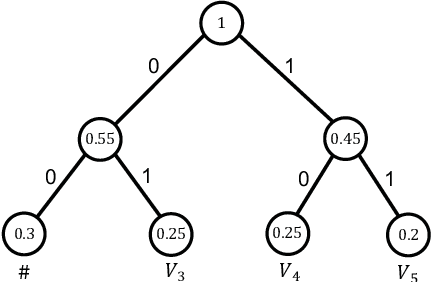
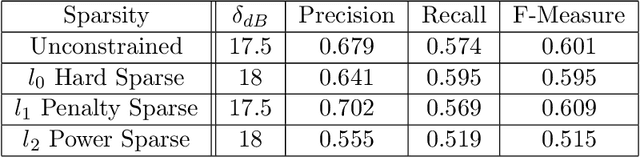
The traditional methods for data compression are typically based on the symbol-level statistics, with the information source modeled as a long sequence of i.i.d. random variables or a stochastic process, thus establishing the fundamental limit as entropy for lossless compression and as mutual information for lossy compression. However, the source (including text, music, and speech) in the real world is often statistically ill-defined because of its close connection to human perception, and thus the model-driven approach can be quite suboptimal. This study places careful emphasis on English text and exploits its semantic aspect to enhance the compression efficiency further. The main idea stems from the puzzle crossword, observing that the hidden words can still be precisely reconstructed so long as some key letters are provided. The proposed masking-based strategy resembles the above game. In a nutshell, the encoder evaluates the semantic importance of each word according to the semantic loss and then masks the minor ones, while the decoder aims to recover the masked words from the semantic context by means of the Transformer. Our experiments show that the proposed semantic approach can achieve much higher compression efficiency than the traditional methods such as Huffman code and UTF-8 code, while preserving the meaning in the target text to a great extent.
Support the Underground: Characteristics of Beyond-Mainstream Music Listeners
Feb 24, 2021
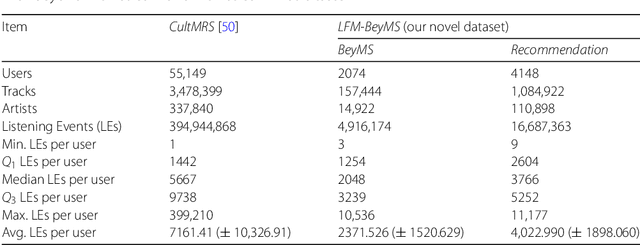
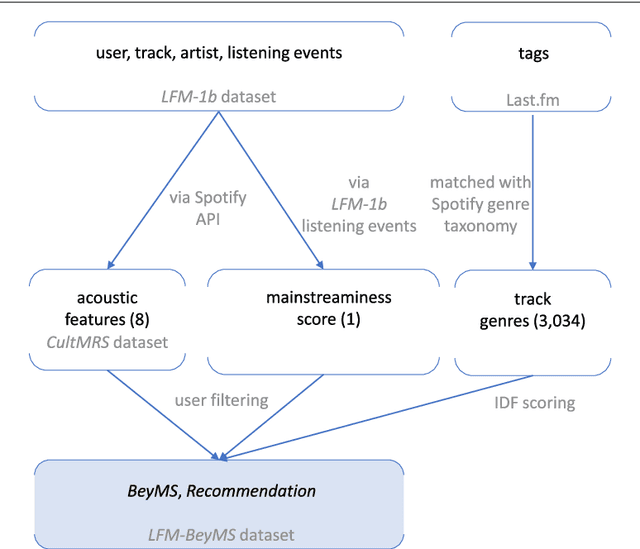

Music recommender systems have become an integral part of music streaming services such as Spotify and Last.fm to assist users navigating the extensive music collections offered by them. However, while music listeners interested in mainstream music are traditionally served well by music recommender systems, users interested in music beyond the mainstream (i.e., non-popular music) rarely receive relevant recommendations. In this paper, we study the characteristics of beyond-mainstream music and music listeners and analyze to what extent these characteristics impact the quality of music recommendations provided. Therefore, we create a novel dataset consisting of Last.fm listening histories of several thousand beyond-mainstream music listeners, which we enrich with additional metadata describing music tracks and music listeners. Our analysis of this dataset shows four subgroups within the group of beyond-mainstream music listeners that differ not only with respect to their preferred music but also with their demographic characteristics. Furthermore, we evaluate the quality of music recommendations that these subgroups are provided with four different recommendation algorithms where we find significant differences between the groups. Specifically, our results show a positive correlation between a subgroup's openness towards music listened to by members of other subgroups and recommendation accuracy. We believe that our findings provide valuable insights for developing improved user models and recommendation approaches to better serve beyond-mainstream music listeners.
Armor: A Benchmark for Meta-evaluation of Artificial Music
Aug 30, 2021Objective evaluation (OE) is essential to artificial music, but it's often very hard to determine the quality of OEs. Hitherto, subjective evaluation (SE) remains reliable and prevailing but suffers inevitable disadvantages that OEs may overcome. Therefore, a meta-evaluation system is necessary for designers to test the effectiveness of OEs. In this paper, we present Armor, a complex and cross-domain benchmark dataset that serves for this purpose. Since OEs should correlate with human judgment, we provide music as test cases for OEs and human judgment scores as touchstones. We also provide two meta-evaluation scenarios and their corresponding testing methods to assess the effectiveness of OEs. To the best of our knowledge, Armor is the first comprehensive and rigorous framework that future works could follow, take example by, and improve upon for the task of evaluating computer-generated music and the field of computational music as a whole. By analyzing different OE methods on our dataset, we observe that there is still a huge gap between SE and OE, meaning that hard-coded algorithms are far from catching human's judgment to the music.
Unsupervised vocal dereverberation with diffusion-based generative models
Nov 08, 2022
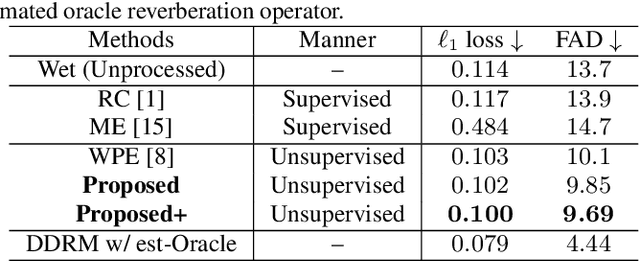
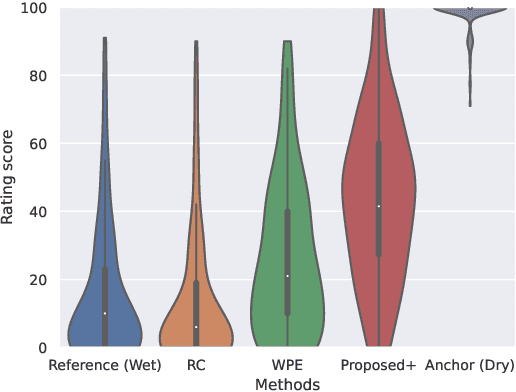
Removing reverb from reverberant music is a necessary technique to clean up audio for downstream music manipulations. Reverberation of music contains two categories, natural reverb, and artificial reverb. Artificial reverb has a wider diversity than natural reverb due to its various parameter setups and reverberation types. However, recent supervised dereverberation methods may fail because they rely on sufficiently diverse and numerous pairs of reverberant observations and retrieved data for training in order to be generalizable to unseen observations during inference. To resolve these problems, we propose an unsupervised method that can remove a general kind of artificial reverb for music without requiring pairs of data for training. The proposed method is based on diffusion models, where it initializes the unknown reverberation operator with a conventional signal processing technique and simultaneously refines the estimate with the help of diffusion models. We show through objective and perceptual evaluations that our method outperforms the current leading vocal dereverberation benchmarks.
Show Me the Instruments: Musical Instrument Retrieval from Mixture Audio
Nov 15, 2022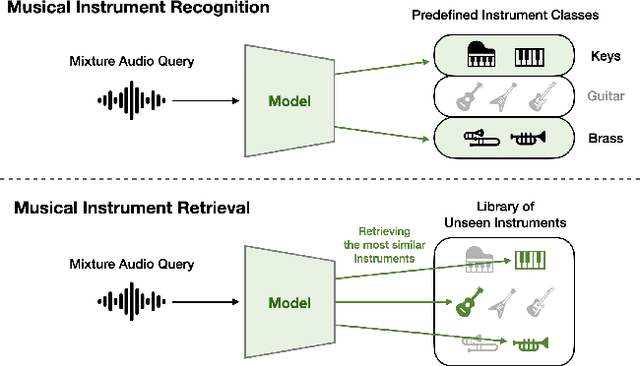
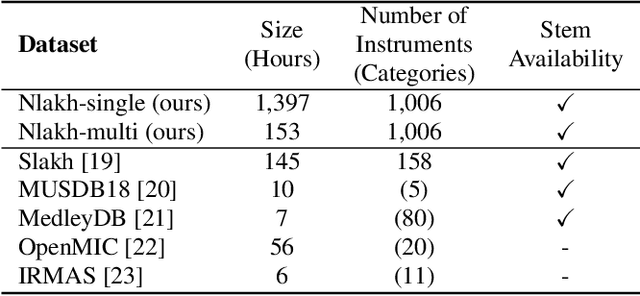
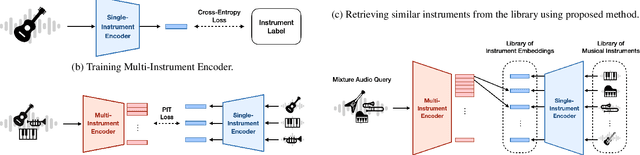
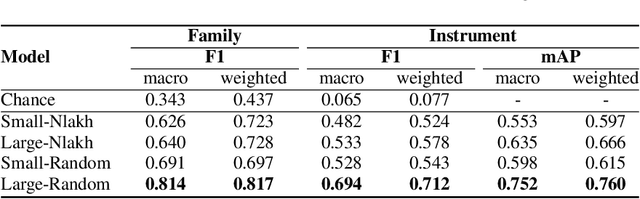
As digital music production has become mainstream, the selection of appropriate virtual instruments plays a crucial role in determining the quality of music. To search the musical instrument samples or virtual instruments that make one's desired sound, music producers use their ears to listen and compare each instrument sample in their collection, which is time-consuming and inefficient. In this paper, we call this task as Musical Instrument Retrieval and propose a method for retrieving desired musical instruments using reference music mixture as a query. The proposed model consists of the Single-Instrument Encoder and the Multi-Instrument Encoder, both based on convolutional neural networks. The Single-Instrument Encoder is trained to classify the instruments used in single-track audio, and we take its penultimate layer's activation as the instrument embedding. The Multi-Instrument Encoder is trained to estimate multiple instrument embeddings using the instrument embeddings computed by the Single-Instrument Encoder as a set of target embeddings. For more generalized training and realistic evaluation, we also propose a new dataset called Nlakh. Experimental results showed that the Single-Instrument Encoder was able to learn the mapping from the audio signal of unseen instruments to the instrument embedding space and the Multi-Instrument Encoder was able to extract multiple embeddings from the mixture of music and retrieve the desired instruments successfully. The code used for the experiment and audio samples are available at: https://github.com/minju0821/musical_instrument_retrieval
BumbleBee: A Transformer for Music
Jul 07, 2021
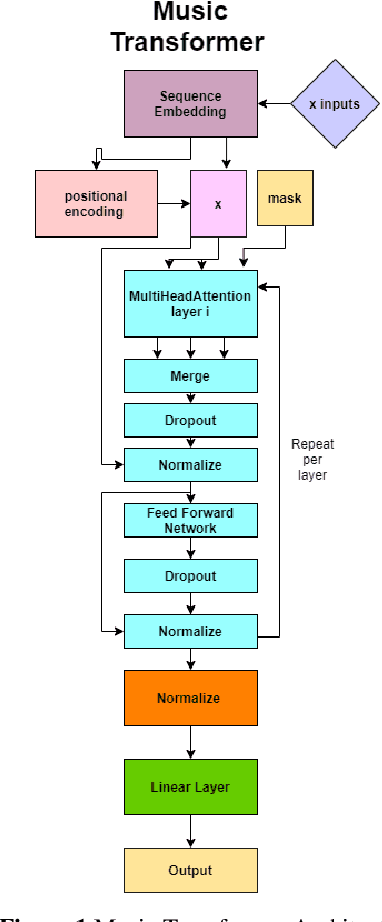

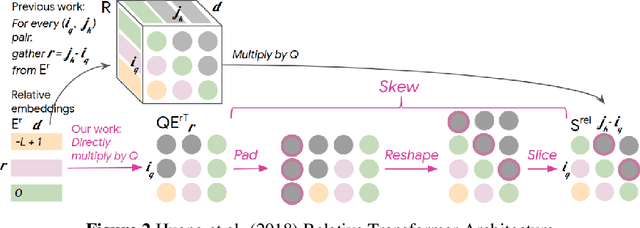
We will introduce BumbleBee, a transformer model that will generate MIDI music data . We will tackle the issue of transformers applied to long sequences by implementing a longformer generative model that uses dilating sliding windows to compute the attention layers. We will compare our results to that of the music transformer and Long-Short term memory (LSTM) to benchmark our results. This analysis will be performed using piano MIDI files, in particular , the JSB Chorales dataset that has already been used for other research works (Huang et al., 2018)