 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Evaluating Music Recommendations with Binary Feedback for Multiple Stakeholders
Sep 16, 2021

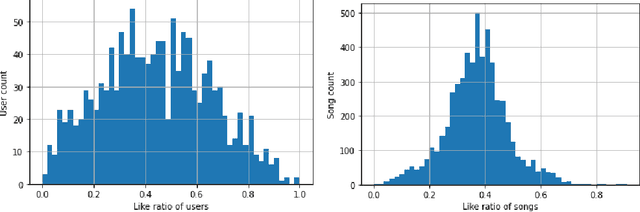
High quality user feedback data is essential to training and evaluating a successful music recommendation system, particularly one that has to balance the needs of multiple stakeholders. Most existing music datasets suffer from noisy feedback and self-selection biases inherent in the data collected by music platforms. Using the Piki Music dataset of 500k ratings collected over a two-year time period, we evaluate the performance of classic recommendation algorithms on three important stakeholders: consumers, well-known artists and lesser-known artists. We show that a matrix factorization algorithm trained on both likes and dislikes performs significantly better compared to one trained only on likes for all three stakeholders.
Personalized Popular Music Generation Using Imitation and Structure
May 10, 2021

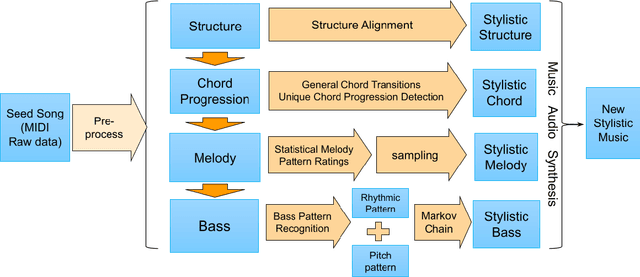

Many practices have been presented in music generation recently. While stylistic music generation using deep learning techniques has became the main stream, these models still struggle to generate music with high musicality, different levels of music structure, and controllability. In addition, more application scenarios such as music therapy require imitating more specific musical styles from a few given music examples, rather than capturing the overall genre style of a large data corpus. To address requirements that challenge current deep learning methods, we propose a statistical machine learning model that is able to capture and imitate the structure, melody, chord, and bass style from a given example seed song. An evaluation using 10 pop songs shows that our new representations and methods are able to create high-quality stylistic music that is similar to a given input song. We also discuss potential uses of our approach in music evaluation and music therapy.
PodcastMix: A dataset for separating music and speech in podcasts
Jul 15, 2022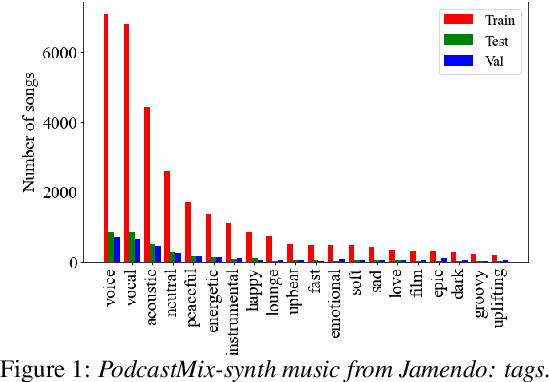
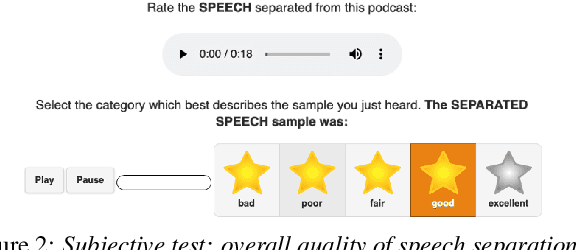
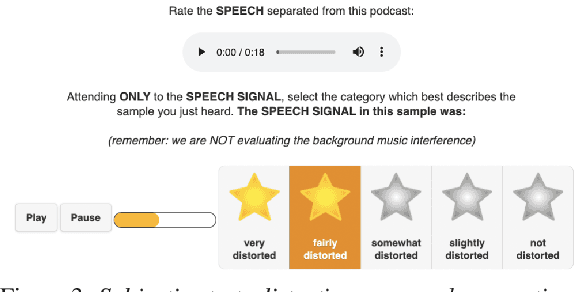
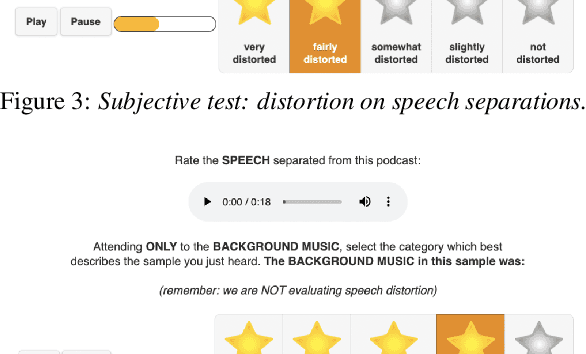
We introduce PodcastMix, a dataset formalizing the task of separating background music and foreground speech in podcasts. We aim at defining a benchmark suitable for training and evaluating (deep learning) source separation models. To that end, we release a large and diverse training dataset based on programatically generated podcasts. However, current (deep learning) models can incur into generalization issues, specially when trained on synthetic data. To target potential generalization issues, we release an evaluation set based on real podcasts for which we design objective and subjective tests. Out of our experiments with real podcasts, we find that current (deep learning) models may have generalization issues. Yet, these can perform competently, e.g., our best baseline separates speech with a mean opinion score of 3.84 (rating "overall separation quality" from 1 to 5). The dataset and baselines are accessible online.
Explaining the Performance of Collaborative Filtering Methods With Optimal Data Characteristics
Mar 17, 2023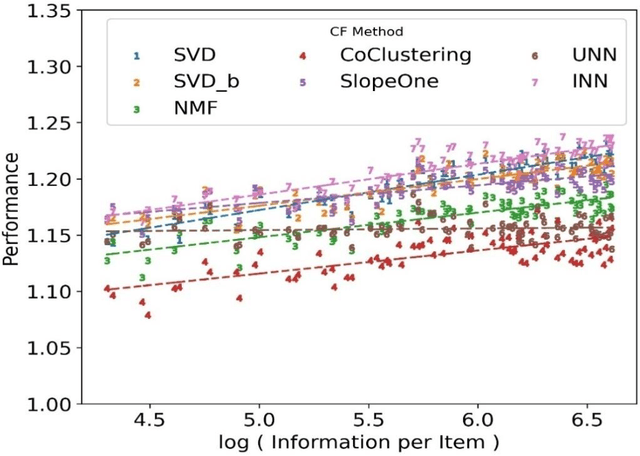
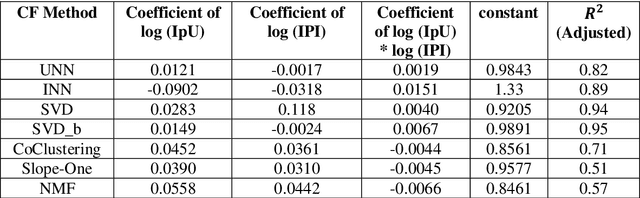
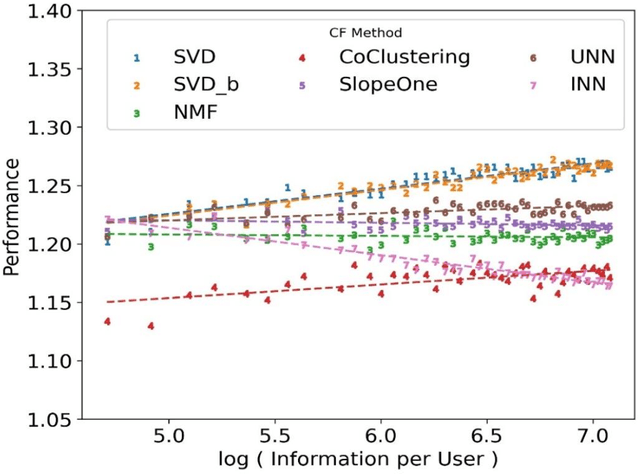
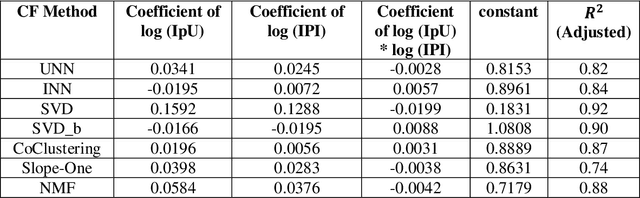
The performance of a Collaborative Filtering (CF) method is based on the properties of a User-Item Rating Matrix (URM). And the properties or Rating Data Characteristics (RDC) of a URM are constantly changing. Recent studies significantly explained the variation in the performances of CF methods resulted due to the change in URM using six or more RDC. Here, we found that the significant proportion of variation in the performances of different CF techniques can be accounted to two RDC only. The two RDC are the number of ratings per user or Information per User (IpU) and the number of ratings per item or Information per Item (IpI). And the performances of CF algorithms are quadratic to IpU (or IpI) for a square URM. The findings of this study are based on seven well-established CF methods and three popular public recommender datasets: 1M MovieLens, 25M MovieLens, and Yahoo! Music Rating datasets
The HaMSE Ontology: Using Semantic Technologies to support Music Representation Interoperability and Musicological Analysis
Feb 11, 2022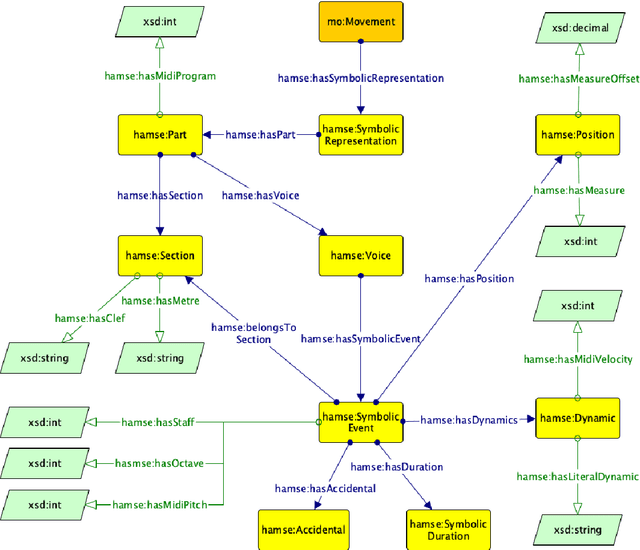
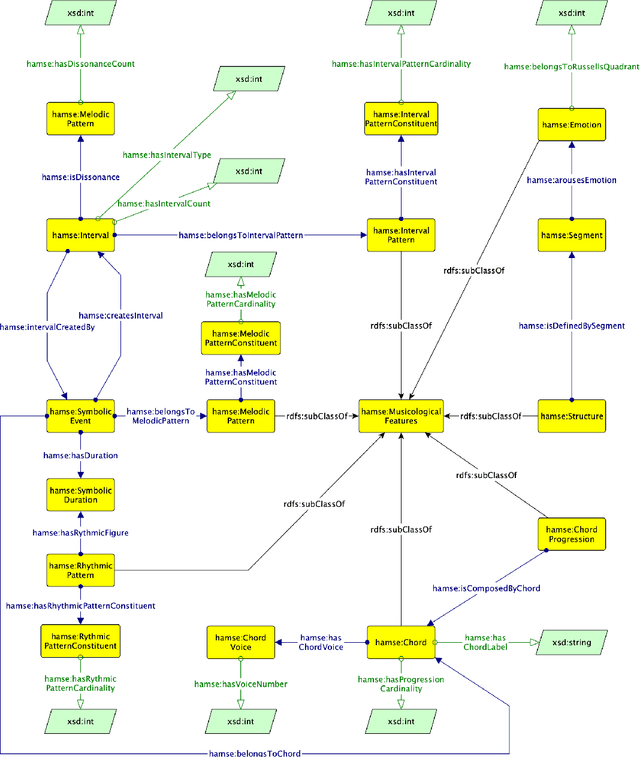
The use of Semantic Technologies - in particular the Semantic Web - has revealed to be a great tool for describing the cultural heritage domain and artistic practices. However, the panorama of ontologies for musicological applications seems to be limited and restricted to specific applications. In this research, we propose HaMSE, an ontology capable of describing musical features that can assist musicological research. More specifically, HaMSE proposes to address sues that have been affecting musicological research for decades: the representation of music and the relationship between quantitative and qualitative data. To do this, HaMSE allows the alignment between different music representation systems and describes a set of musicological features that can allow the music analysis at different granularity levels.
Improving Self-Supervised Learning for Audio Representations by Feature Diversity and Decorrelation
Mar 07, 2023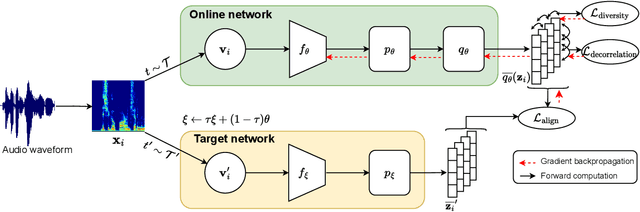
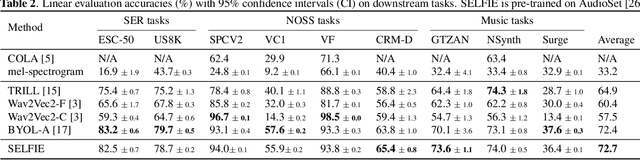
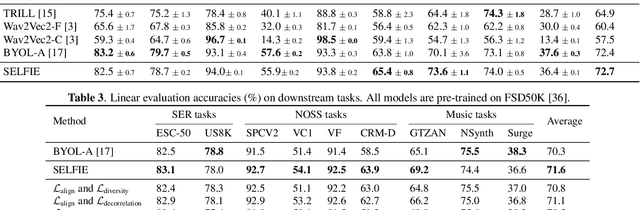
Self-supervised learning (SSL) has recently shown remarkable results in closing the gap between supervised and unsupervised learning. The idea is to learn robust features that are invariant to distortions of the input data. Despite its success, this idea can suffer from a collapsing issue where the network produces a constant representation. To this end, we introduce SELFIE, a novel Self-supervised Learning approach for audio representation via Feature Diversity and Decorrelation. SELFIE avoids the collapsing issue by ensuring that the representation (i) maintains a high diversity among embeddings and (ii) decorrelates the dependencies between dimensions. SELFIE is pre-trained on the large-scale AudioSet dataset and its embeddings are validated on nine audio downstream tasks, including speech, music, and sound event recognition. Experimental results show that SELFIE outperforms existing SSL methods in several tasks.
MT3: Multi-Task Multitrack Music Transcription
Nov 10, 2021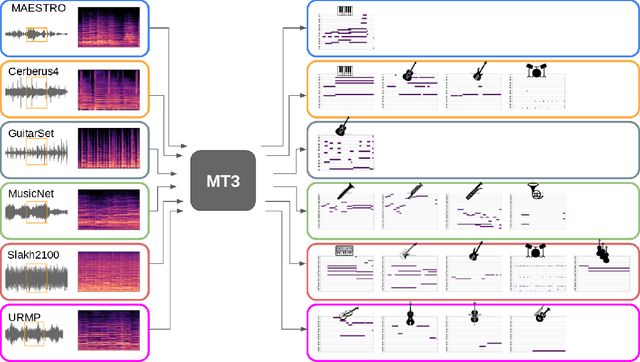

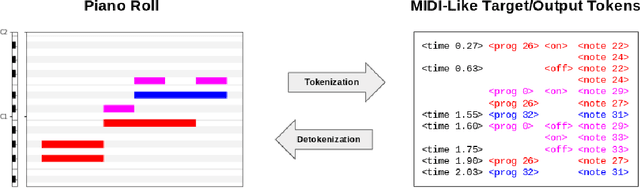
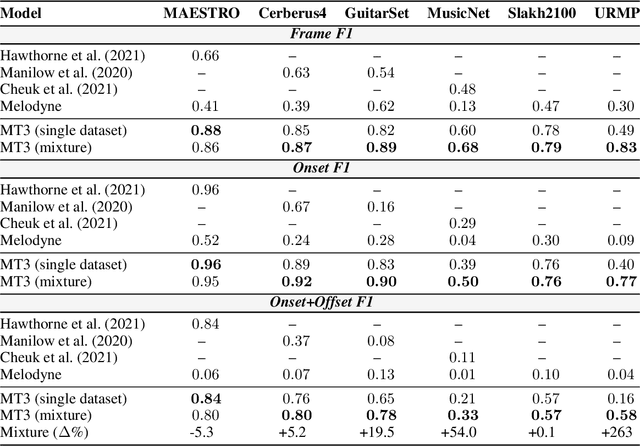
Automatic Music Transcription (AMT), inferring musical notes from raw audio, is a challenging task at the core of music understanding. Unlike Automatic Speech Recognition (ASR), which typically focuses on the words of a single speaker, AMT often requires transcribing multiple instruments simultaneously, all while preserving fine-scale pitch and timing information. Further, many AMT datasets are "low-resource", as even expert musicians find music transcription difficult and time-consuming. Thus, prior work has focused on task-specific architectures, tailored to the individual instruments of each task. In this work, motivated by the promising results of sequence-to-sequence transfer learning for low-resource Natural Language Processing (NLP), we demonstrate that a general-purpose Transformer model can perform multi-task AMT, jointly transcribing arbitrary combinations of musical instruments across several transcription datasets. We show this unified training framework achieves high-quality transcription results across a range of datasets, dramatically improving performance for low-resource instruments (such as guitar), while preserving strong performance for abundant instruments (such as piano). Finally, by expanding the scope of AMT, we expose the need for more consistent evaluation metrics and better dataset alignment, and provide a strong baseline for this new direction of multi-task AMT.
LyricJam Sonic: A Generative System for Real-Time Composition and Musical Improvisation
Oct 27, 2022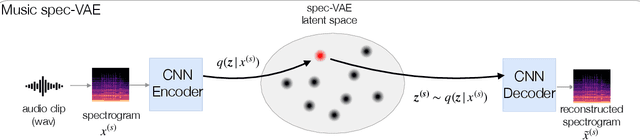

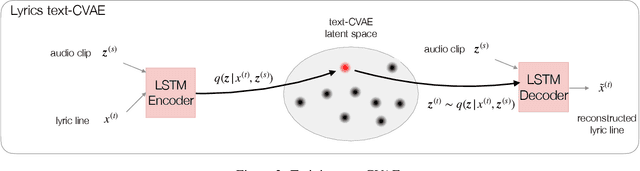
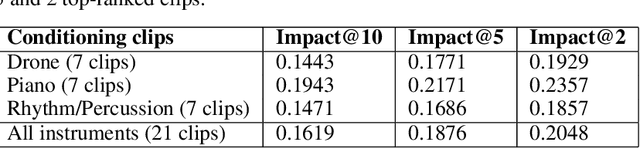
Electronic music artists and sound designers have unique workflow practices that necessitate specialized approaches for developing music information retrieval and creativity support tools. Furthermore, electronic music instruments, such as modular synthesizers, have near-infinite possibilities for sound creation and can be combined to create unique and complex audio paths. The process of discovering interesting sounds is often serendipitous and impossible to replicate. For this reason, many musicians in electronic genres record audio output at all times while they work in the studio. Subsequently, it is difficult for artists to rediscover audio segments that might be suitable for use in their compositions from thousands of hours of recordings. In this paper, we describe LyricJam Sonic -- a novel creative tool for musicians to rediscover their previous recordings, re-contextualize them with other recordings, and create original live music compositions in real-time. A bi-modal AI-driven approach uses generated lyric lines to find matching audio clips from the artist's past studio recordings, and uses them to generate new lyric lines, which in turn are used to find other clips, thus creating a continuous and evolving stream of music and lyrics. The intent is to keep the artists in a state of creative flow conducive to music creation rather than taking them into an analytical/critical state of deliberately searching for past audio segments. The system can run in either a fully autonomous mode without user input, or in a live performance mode, where the artist plays live music, while the system "listens" and creates a continuous stream of music and lyrics in response.
Learning to Generate Music With Sentiment
Mar 09, 2021
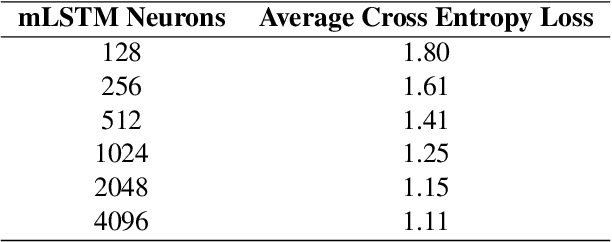
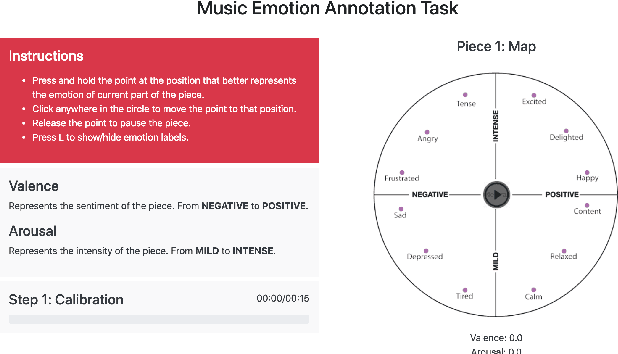
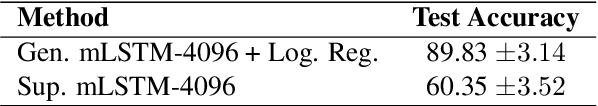
Deep Learning models have shown very promising results in automatically composing polyphonic music pieces. However, it is very hard to control such models in order to guide the compositions towards a desired goal. We are interested in controlling a model to automatically generate music with a given sentiment. This paper presents a generative Deep Learning model that can be directed to compose music with a given sentiment. Besides music generation, the same model can be used for sentiment analysis of symbolic music. We evaluate the accuracy of the model in classifying sentiment of symbolic music using a new dataset of video game soundtracks. Results show that our model is able to obtain good prediction accuracy. A user study shows that human subjects agreed that the generated music has the intended sentiment, however negative pieces can be ambiguous.
Music Demixing Challenge at ISMIR 2021
Aug 31, 2021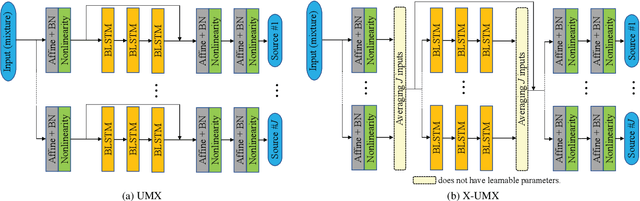
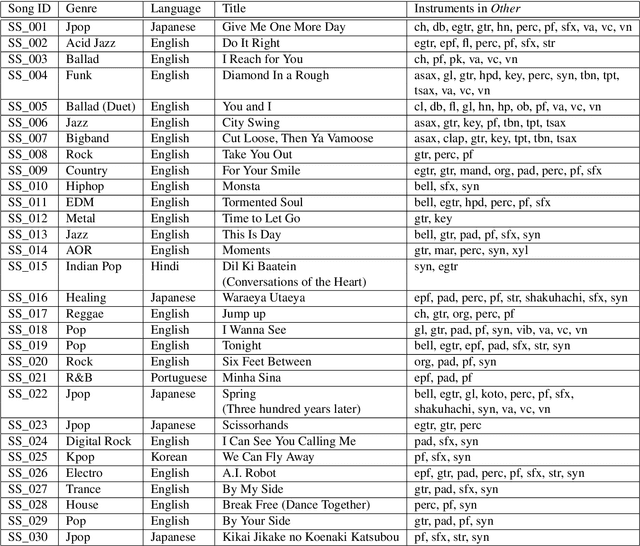
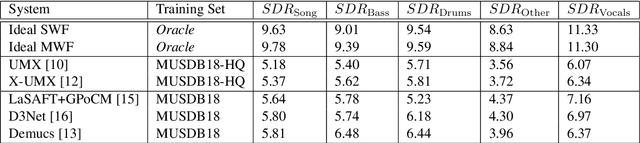
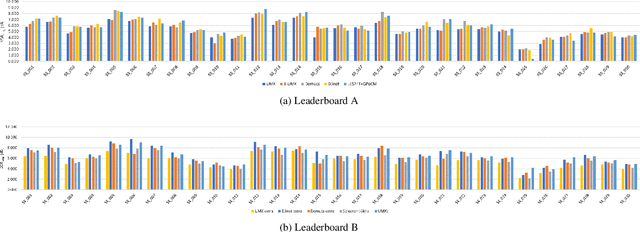
Music source separation has been intensively studied in the last decade and tremendous progress with the advent of deep learning could be observed. Evaluation campaigns such as MIREX or SiSEC connected state-of-the-art models and corresponding papers, which can help researchers integrate the best practices into their models. In recent years, however, it has become increasingly difficult to measure real-world performance as the music separation community had to rely on a limited amount of test data and was biased towards specific genres and mixing styles. To address these issues, we designed the Music Demixing (MDX) Challenge on a crowd-based machine learning competition platform where the task is to separate stereo songs into four instrument stems (Vocals, Drums, Bass, Other). The main differences compared with the past challenges are 1) the competition is designed to more easily allow machine learning practitioners from other disciplines to participate and 2) evaluation is done on a hidden test set created by music professionals dedicated exclusively to the challenge to assure the transparency of the challenge, i.e., the test set is not included in the training set. In this paper, we provide the details of the datasets, baselines, evaluation metrics, evaluation results, and technical challenges for future competitions.