 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Digital Audio Processing Tools for Music Corpus Studies
Nov 06, 2021
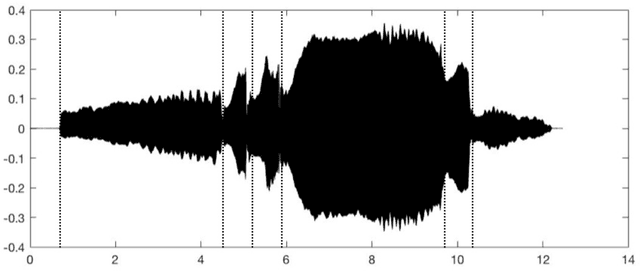
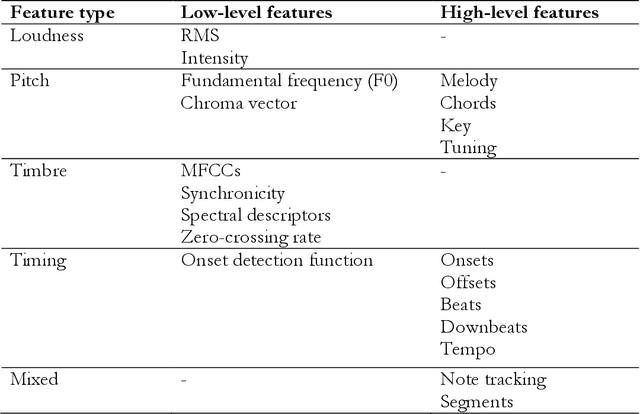
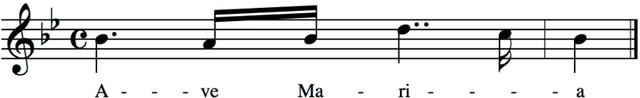
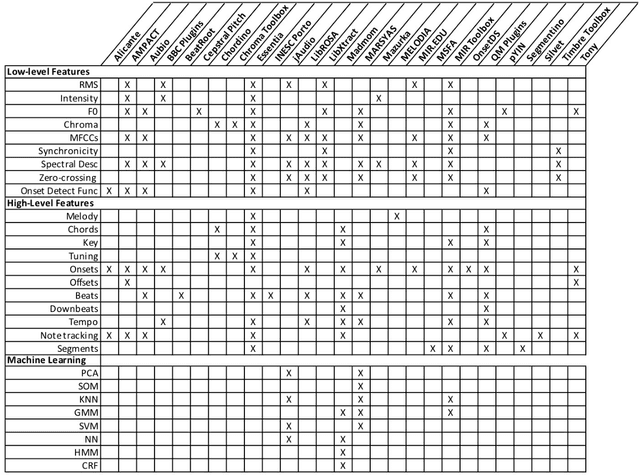
Digital audio processing tools offer music researchers the opportunity to examine both non-notated music and music as performance. This chapter summarises the types of information that can be extracted from audio as well as currently available audio tools for music corpus studies. The survey of extraction methods includes both a primer on signal processing and background theory on audio feature extraction. The survey of audio tools focuses on widely used tools, including both those with a graphical user interface, namely Audacity and Sonic Visualiser, and code-based tools written in the C/C++, Java, MATLAB, and Python computer programming languages.
A New Corpus for Computational Music Research and A Novel Method for Musical Structure Analysis
Aug 31, 2022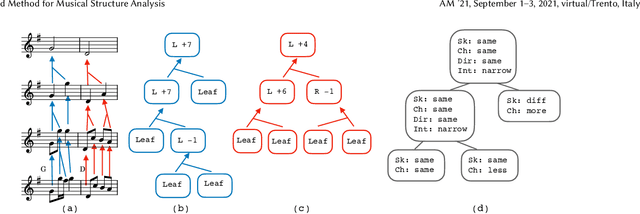

Computational models of music, while providing good descriptions of melodic development, still cannot fully grasp the general structure comprised of repetitions, transpositions, and reuse of melodic material. We present a corpus of strongly structured baroque allemandes, and describe a top-down approach to abstract the shared structure of their musical content using tree representations produced from pairwise differences between the Schenkerian-inspired analyses of each piece, thereby providing a rich hierarchical description of the corpus.
Visualizing Ensemble Predictions of Music Mood
Dec 14, 2021
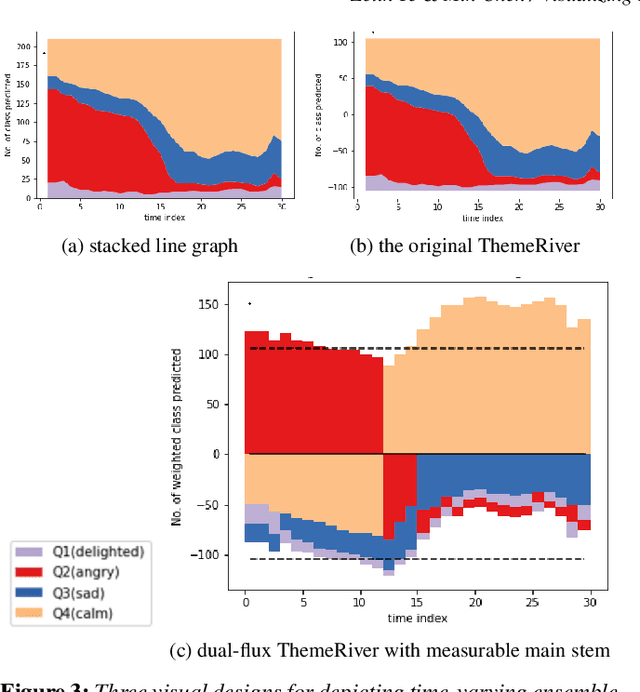
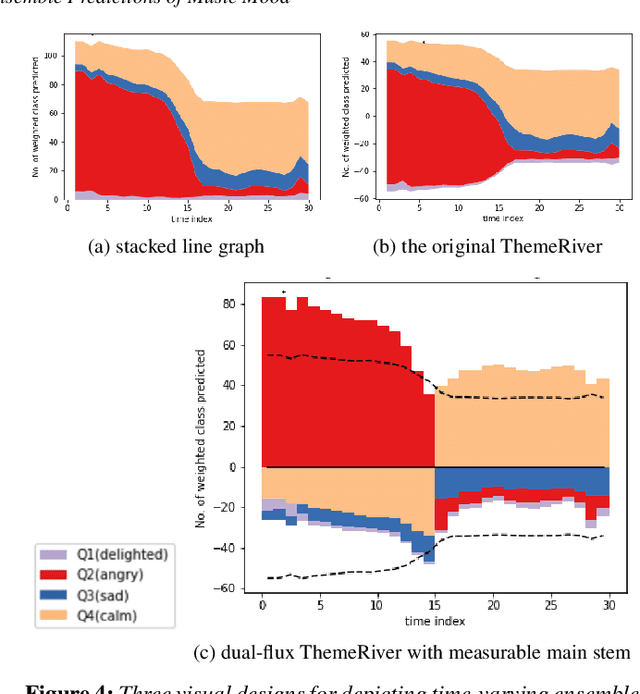
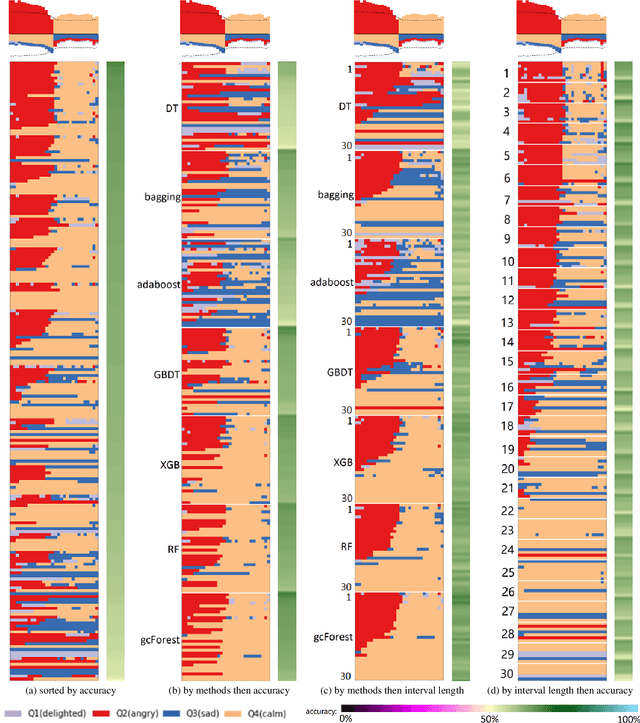
Music mood classification has been a challenging problem in comparison with some other classification problems (e.g., genre, composer, or period). One solution for addressing this challenging is to use an of ensemble machine learning models. In this paper, we show that visualization techniques can effectively convey the popular prediction as well as uncertainty at different music sections along the temporal axis, while enabling the analysis of individual ML models in conjunction with their application to different musical data. In addition to the traditional visual designs, such as stacked line graph, ThemeRiver, and pixel-based visualization, we introduced a new variant of ThemeRiver, called "dual-flux ThemeRiver", which allows viewers to observe and measure the most popular prediction more easily than stacked line graph and ThemeRiver. Testing indicates that visualizing ensemble predictions is helpful both in model-development workflows and for annotating music using model predictions.
GCNSLIM: Graph Convolutional Network with Sparse Linear Methods for E-government Service Recommendation
May 15, 2023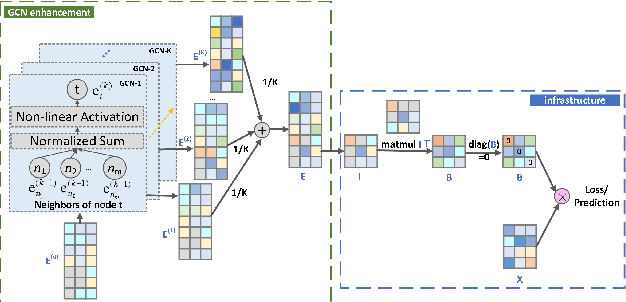

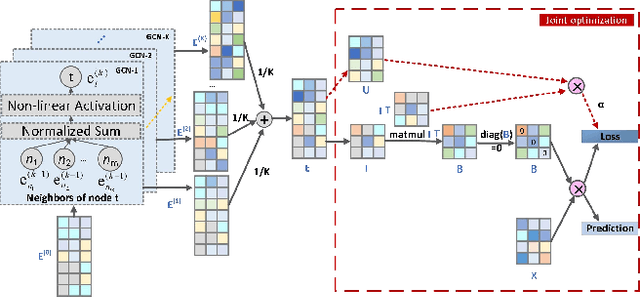
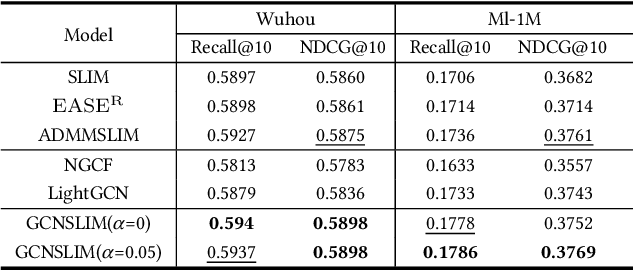
Graph Convolutional Networks have made significant strides in Collabora-tive Filtering recommendations. However, existing GCN-based CF methods are mainly based on matrix factorization and incorporate some optimization tech-niques to enhance performance, which are not enough to handle the complexities of diverse real-world recommendation scenarios. E-government service recommendation is a crucial area for recommendation re-search as it involves rigid aspects of people's lives. However, it has not received ad-equate attention in comparison to other recommendation scenarios like news and music recommendation. We empirically find that when existing GCN-based CF methods are directly applied to e-government service recommendation, they are limited by the MF framework and showing poor performance. This is because MF's equal treatment of users and items is not appropriate for scenarios where the number of users and items is unbalanced. In this work, we propose a new model, GCNSLIM, which combines GCN and sparse linear methods instead of combining GCN and MF to accommodate e-government service recommendation. In particular, GCNSLIM explicitly injects high-order collaborative signals obtained from multi-layer light graph convolutions into the item similarity matrix in the SLIM frame-work, effectively improving the recommendation accuracy. In addition, we propose two optimization measures, removing layer 0 embedding and adding nonlinear acti-vation, to further adapt to the characteristics of e-government service recommenda-tion scenarios. Furthermore, we propose a joint optimization mode to adapt to more diverse recommendation scenarios. We conduct extensive experiments on a real e-government service dataset and a common public dataset and demonstrate the ef-fectiveness of GCNSLIM in recommendation accuracy and operational performance.
Bach Style Music Authoring System based on Deep Learning
Oct 06, 2021

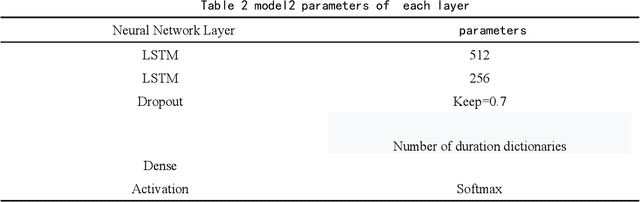
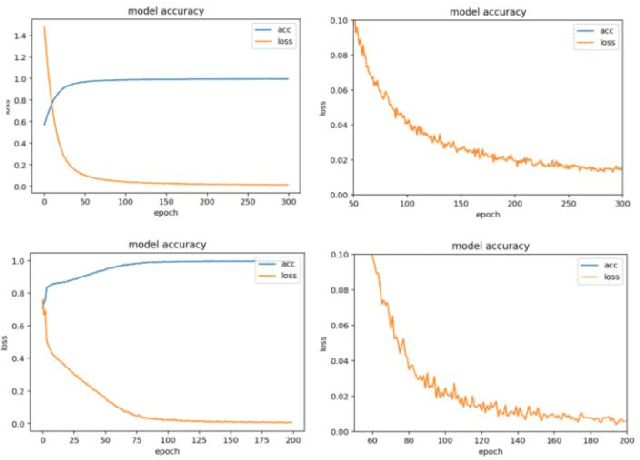
With the continuous improvement in various aspects in the field of artificial intelligence, the momentum of artificial intelligence with deep learning capabilities into the field of music is coming. The research purpose of this paper is to design a Bach style music authoring system based on deep learning. We use a LSTM neural network to train serialized and standardized music feature data. By repeated experiments, we find the optimal LSTM model which can generate imitation of Bach music. Finally the generated music is comprehensively evaluated in the form of online audition and Turing test. The repertoires which the music generation system constructed in this article are very close to the style of Bach's original music, and it is relatively difficult for ordinary people to distinguish the musics Bach authored and AI created.
Enhancing Affective Representations of Music-Induced EEG through Multimodal Supervision and latent Domain Adaptation
Feb 20, 2022


The study of Music Cognition and neural responses to music has been invaluable in understanding human emotions. Brain signals, though, manifest a highly complex structure that makes processing and retrieving meaningful features challenging, particularly of abstract constructs like affect. Moreover, the performance of learning models is undermined by the limited amount of available neuronal data and their severe inter-subject variability. In this paper we extract efficient, personalized affective representations from EEG signals during music listening. To this end, we employ music signals as a supervisory modality to EEG, aiming to project their semantic correspondence onto a common representation space. We utilize a bi-modal framework by combining an LSTM-based attention model to process EEG and a pre-trained model for music tagging, along with a reverse domain discriminator to align the distributions of the two modalities, further constraining the learning process with emotion tags. The resulting framework can be utilized for emotion recognition both directly, by performing supervised predictions from either modality, and indirectly, by providing relevant music samples to EEG input queries. The experimental findings show the potential of enhancing neuronal data through stimulus information for recognition purposes and yield insights into the distribution and temporal variance of music-induced affective features.
Unsupervised Learning of Deep Features for Music Segmentation
Aug 30, 2021
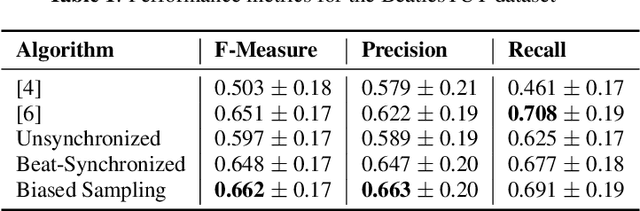

Music segmentation refers to the dual problem of identifying boundaries between, and labeling, distinct music segments, e.g., the chorus, verse, bridge etc. in popular music. The performance of a range of music segmentation algorithms has been shown to be dependent on the audio features chosen to represent the audio. Some approaches have proposed learning feature transformations from music segment annotation data, although, such data is time consuming or expensive to create and as such these approaches are likely limited by the size of their datasets. While annotated music segmentation data is a scarce resource, the amount of available music audio is much greater. In the neighboring field of semantic audio unsupervised deep learning has shown promise in improving the performance of solutions to the query-by-example and sound classification tasks. In this work, unsupervised training of deep feature embeddings using convolutional neural networks (CNNs) is explored for music segmentation. The proposed techniques exploit only the time proximity of audio features that is implicit in any audio timeline. Employing these embeddings in a classic music segmentation algorithm is shown not only to significantly improve the performance of this algorithm, but obtain state of the art performance in unsupervised music segmentation.
Dance2Music: Automatic Dance-driven Music Generation
Jul 20, 2021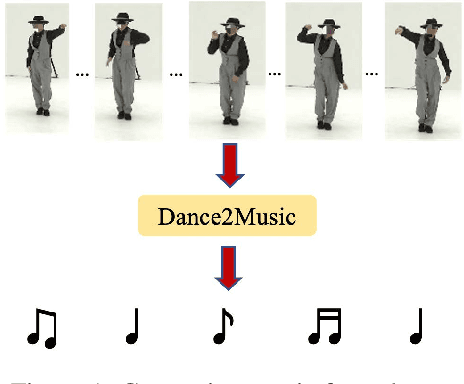
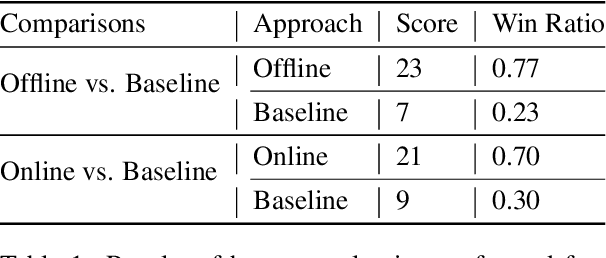

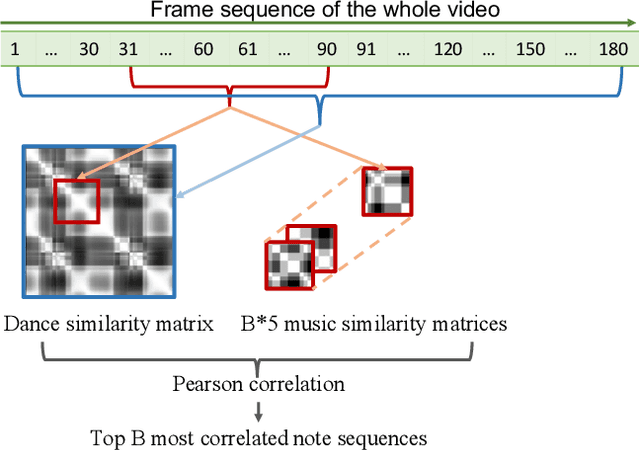
Dance and music typically go hand in hand. The complexities in dance, music, and their synchronisation make them fascinating to study from a computational creativity perspective. While several works have looked at generating dance for a given music, automatically generating music for a given dance remains under-explored. This capability could have several creative expression and entertainment applications. We present some early explorations in this direction. We present a search-based offline approach that generates music after processing the entire dance video and an online approach that uses a deep neural network to generate music on-the-fly as the video proceeds. We compare these approaches to a strong heuristic baseline via human studies and present our findings. We have integrated our online approach in a live demo! A video of the demo can be found here: https://sites.google.com/view/dance2music/live-demo.
Flat latent manifolds for music improvisation between human and machine
Feb 23, 2022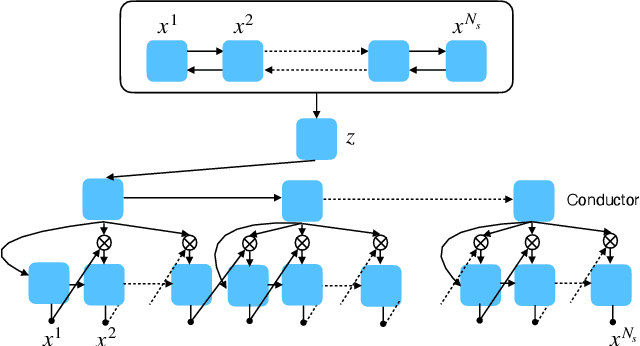
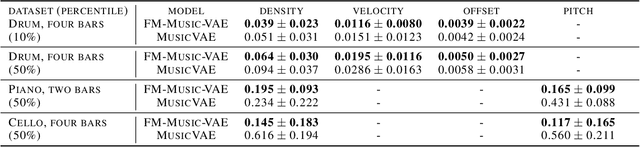
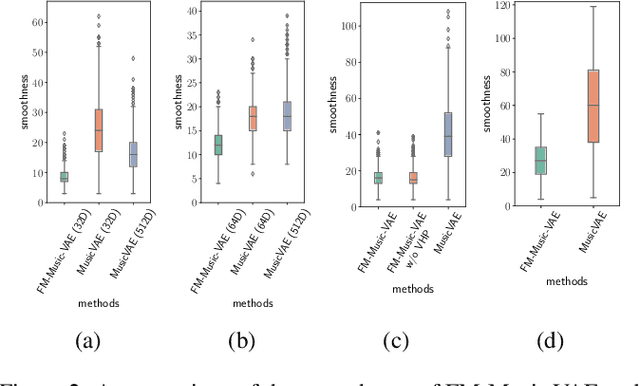
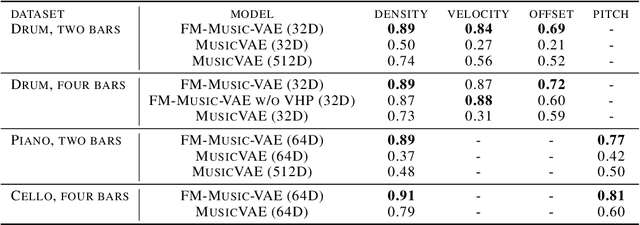
The use of machine learning in artistic music generation leads to controversial discussions of the quality of art, for which objective quantification is nonsensical. We therefore consider a music-generating algorithm as a counterpart to a human musician, in a setting where reciprocal improvisation is to lead to new experiences, both for the musician and the audience. To obtain this behaviour, we resort to the framework of recurrent Variational Auto-Encoders (VAE) and learn to generate music, seeded by a human musician. In the learned model, we generate novel musical sequences by interpolation in latent space. Standard VAEs however do not guarantee any form of smoothness in their latent representation. This translates into abrupt changes in the generated music sequences. To overcome these limitations, we regularise the decoder and endow the latent space with a flat Riemannian manifold, i.e., a manifold that is isometric to the Euclidean space. As a result, linearly interpolating in the latent space yields realistic and smooth musical changes that fit the type of machine--musician interactions we aim for. We provide empirical evidence for our method via a set of experiments on music datasets and we deploy our model for an interactive jam session with a professional drummer. The live performance provides qualitative evidence that the latent representation can be intuitively interpreted and exploited by the drummer to drive the interplay. Beyond the musical application, our approach showcases an instance of human-centred design of machine-learning models, driven by interpretability and the interaction with the end user.
Rock Guitar Tablature Generation via Natural Language Processing
Jan 12, 2023

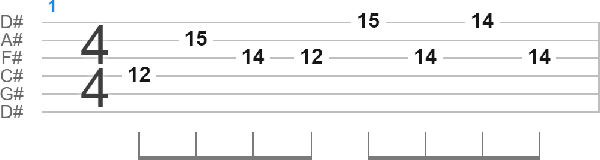
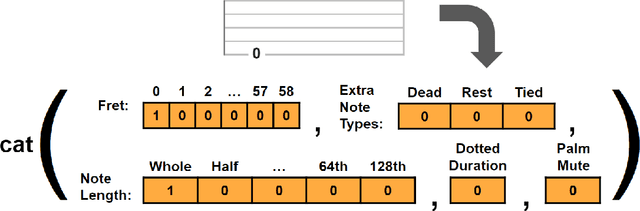
Deep learning has recently empowered and democratized generative modeling of images and text, with additional concurrent works exploring the possibility of generating more complex forms of data, such as audio. However, the high dimensionality, long-range dependencies, and lack of standardized datasets currently makes generative modeling of audio and music very challenging. We propose to model music as a series of discrete notes upon which we can use autoregressive natural language processing techniques for successful generative modeling. While previous works used similar pipelines on data such as sheet music and MIDI, we aim to extend such approaches to the under-studied medium of guitar tablature. Specifically, we develop the first work to our knowledge that models one specific genre as guitar tablature: heavy rock. Unlike other works in guitar tablature generation, we have a freely available public demo at https://huggingface.co/spaces/josuelmet/Metal_Music_Interpolator