 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Visualizing Ensemble Predictions of Music Mood
Dec 14, 2021
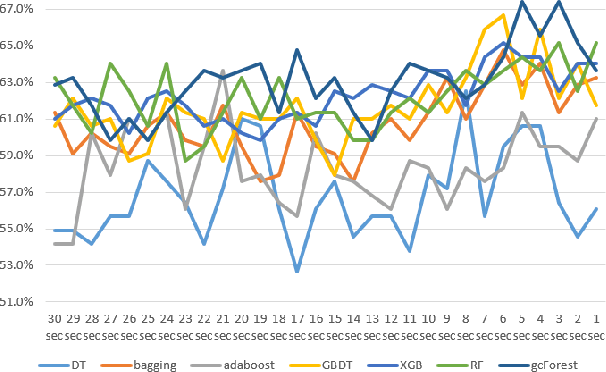
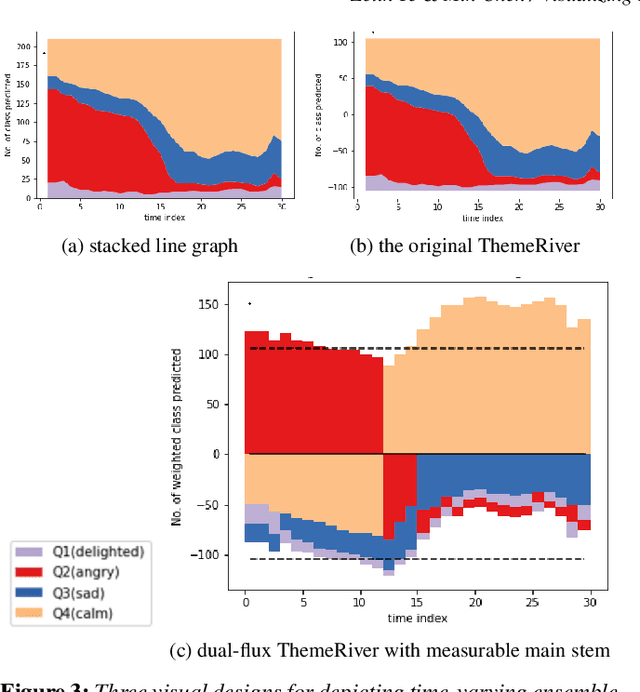
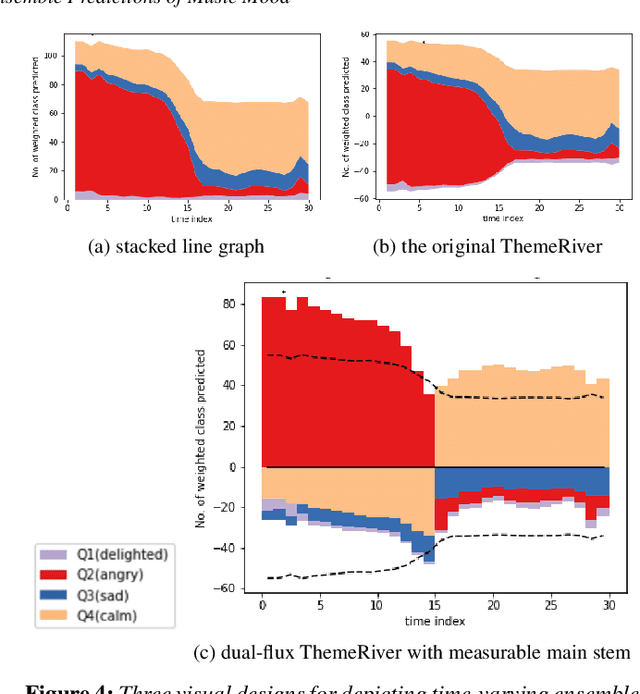
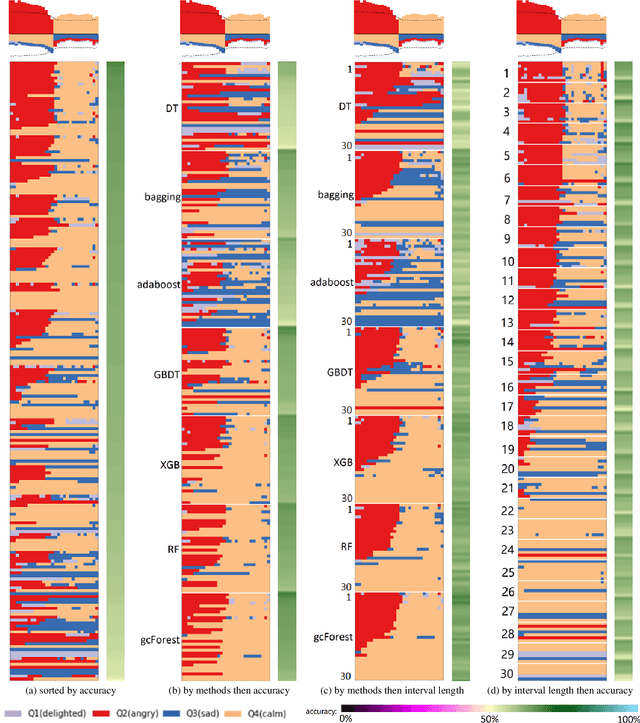
Music mood classification has been a challenging problem in comparison with some other classification problems (e.g., genre, composer, or period). One solution for addressing this challenging is to use an of ensemble machine learning models. In this paper, we show that visualization techniques can effectively convey the popular prediction as well as uncertainty at different music sections along the temporal axis, while enabling the analysis of individual ML models in conjunction with their application to different musical data. In addition to the traditional visual designs, such as stacked line graph, ThemeRiver, and pixel-based visualization, we introduced a new variant of ThemeRiver, called "dual-flux ThemeRiver", which allows viewers to observe and measure the most popular prediction more easily than stacked line graph and ThemeRiver. Testing indicates that visualizing ensemble predictions is helpful both in model-development workflows and for annotating music using model predictions.
Rock Guitar Tablature Generation via Natural Language Processing
Jan 12, 2023

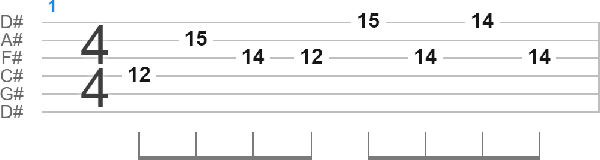
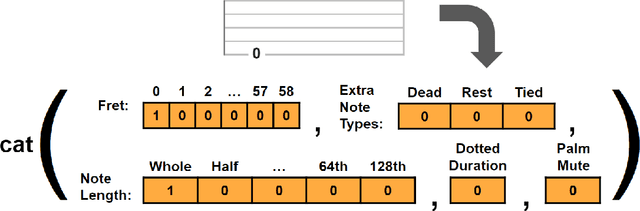
Deep learning has recently empowered and democratized generative modeling of images and text, with additional concurrent works exploring the possibility of generating more complex forms of data, such as audio. However, the high dimensionality, long-range dependencies, and lack of standardized datasets currently makes generative modeling of audio and music very challenging. We propose to model music as a series of discrete notes upon which we can use autoregressive natural language processing techniques for successful generative modeling. While previous works used similar pipelines on data such as sheet music and MIDI, we aim to extend such approaches to the under-studied medium of guitar tablature. Specifically, we develop the first work to our knowledge that models one specific genre as guitar tablature: heavy rock. Unlike other works in guitar tablature generation, we have a freely available public demo at https://huggingface.co/spaces/josuelmet/Metal_Music_Interpolator
Enhancing Affective Representations of Music-Induced EEG through Multimodal Supervision and latent Domain Adaptation
Feb 20, 2022


The study of Music Cognition and neural responses to music has been invaluable in understanding human emotions. Brain signals, though, manifest a highly complex structure that makes processing and retrieving meaningful features challenging, particularly of abstract constructs like affect. Moreover, the performance of learning models is undermined by the limited amount of available neuronal data and their severe inter-subject variability. In this paper we extract efficient, personalized affective representations from EEG signals during music listening. To this end, we employ music signals as a supervisory modality to EEG, aiming to project their semantic correspondence onto a common representation space. We utilize a bi-modal framework by combining an LSTM-based attention model to process EEG and a pre-trained model for music tagging, along with a reverse domain discriminator to align the distributions of the two modalities, further constraining the learning process with emotion tags. The resulting framework can be utilized for emotion recognition both directly, by performing supervised predictions from either modality, and indirectly, by providing relevant music samples to EEG input queries. The experimental findings show the potential of enhancing neuronal data through stimulus information for recognition purposes and yield insights into the distribution and temporal variance of music-induced affective features.
Sonus Texere! Automated Dense Soundtrack Construction for Books using Movie Adaptations
Dec 02, 2022
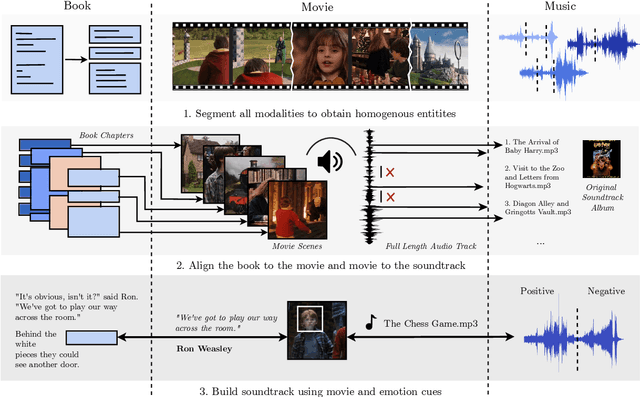

Reading, much like music listening, is an immersive experience that transports readers while taking them on an emotional journey. Listening to complementary music has the potential to amplify the reading experience, especially when the music is stylistically cohesive and emotionally relevant. In this paper, we propose the first fully automatic method to build a dense soundtrack for books, which can play high-quality instrumental music for the entirety of the reading duration. Our work employs a unique text processing and music weaving pipeline that determines the context and emotional composition of scenes in a chapter. This allows our method to identify and play relevant excerpts from the soundtrack of the book's movie adaptation. By relying on the movie composer's craftsmanship, our book soundtracks include expert-made motifs and other scene-specific musical characteristics. We validate the design decisions of our approach through a perceptual study. Our readers note that the book soundtrack greatly enhanced their reading experience, due to high immersiveness granted via uninterrupted and style-consistent music, and a heightened emotional state attained via high precision emotion and scene context recognition.
Bach Style Music Authoring System based on Deep Learning
Oct 06, 2021

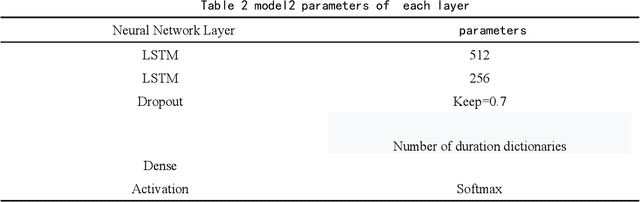
With the continuous improvement in various aspects in the field of artificial intelligence, the momentum of artificial intelligence with deep learning capabilities into the field of music is coming. The research purpose of this paper is to design a Bach style music authoring system based on deep learning. We use a LSTM neural network to train serialized and standardized music feature data. By repeated experiments, we find the optimal LSTM model which can generate imitation of Bach music. Finally the generated music is comprehensively evaluated in the form of online audition and Turing test. The repertoires which the music generation system constructed in this article are very close to the style of Bach's original music, and it is relatively difficult for ordinary people to distinguish the musics Bach authored and AI created.
A2D: Anywhere Anytime Drumming
Apr 04, 2023
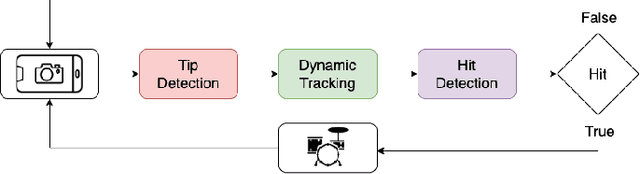
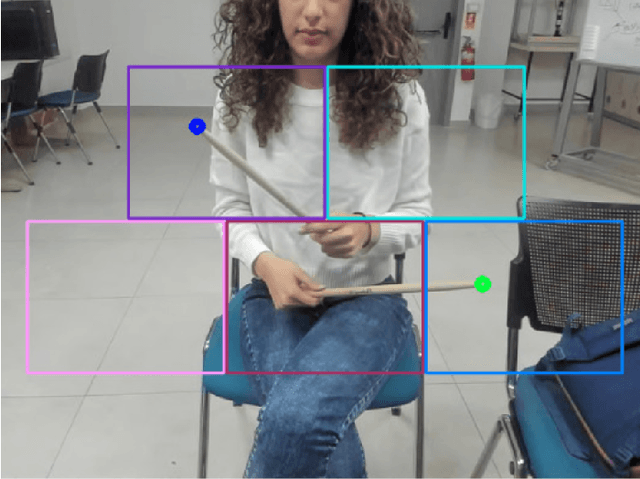

The drum kit, which has only been around for around 100 years, is a popular instrument in many music genres such as pop, rock, and jazz. However, the road to owning a kit is expensive, both financially and space-wise. Also, drums are more difficult to move around compared to other instruments, as they do not fit into a single bag. We propose a no-drums approach that uses only two sticks and a smartphone or a webcam to provide an air-drumming experience. The detection algorithm combines deep learning tools with tracking methods for an enhanced user experience. Based on both quantitative and qualitative testing with humans-in-the-loop, we show that our system has zero misses for beginner level play and negligible misses for advanced level play. Additionally, our limited human trials suggest potential directions for future research.
Flat latent manifolds for music improvisation between human and machine
Feb 23, 2022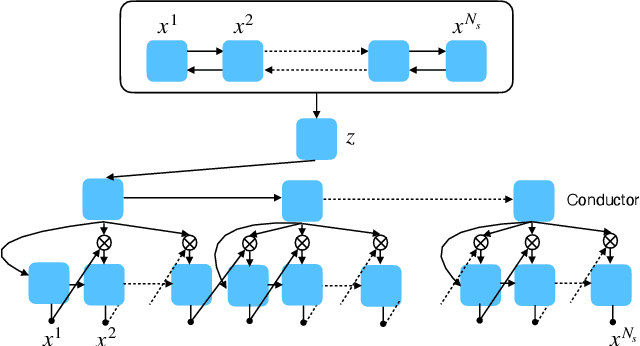
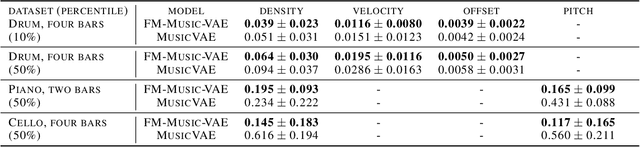
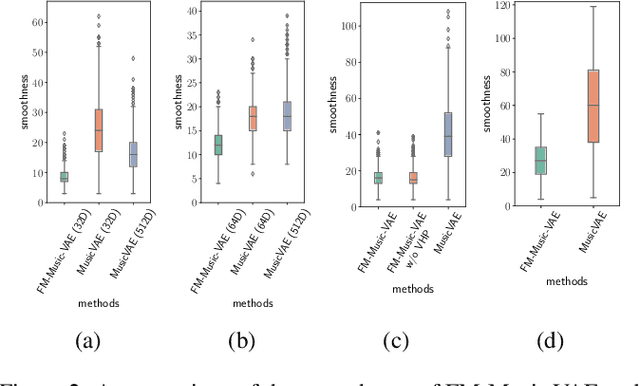
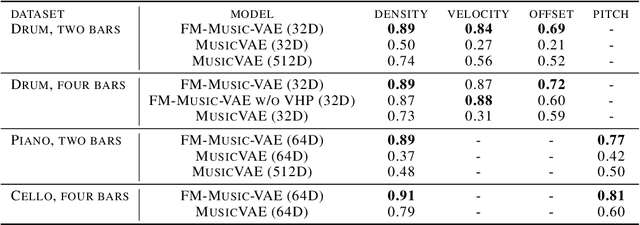
The use of machine learning in artistic music generation leads to controversial discussions of the quality of art, for which objective quantification is nonsensical. We therefore consider a music-generating algorithm as a counterpart to a human musician, in a setting where reciprocal improvisation is to lead to new experiences, both for the musician and the audience. To obtain this behaviour, we resort to the framework of recurrent Variational Auto-Encoders (VAE) and learn to generate music, seeded by a human musician. In the learned model, we generate novel musical sequences by interpolation in latent space. Standard VAEs however do not guarantee any form of smoothness in their latent representation. This translates into abrupt changes in the generated music sequences. To overcome these limitations, we regularise the decoder and endow the latent space with a flat Riemannian manifold, i.e., a manifold that is isometric to the Euclidean space. As a result, linearly interpolating in the latent space yields realistic and smooth musical changes that fit the type of machine--musician interactions we aim for. We provide empirical evidence for our method via a set of experiments on music datasets and we deploy our model for an interactive jam session with a professional drummer. The live performance provides qualitative evidence that the latent representation can be intuitively interpreted and exploited by the drummer to drive the interplay. Beyond the musical application, our approach showcases an instance of human-centred design of machine-learning models, driven by interpretability and the interaction with the end user.
Unsupervised Learning of Deep Features for Music Segmentation
Aug 30, 2021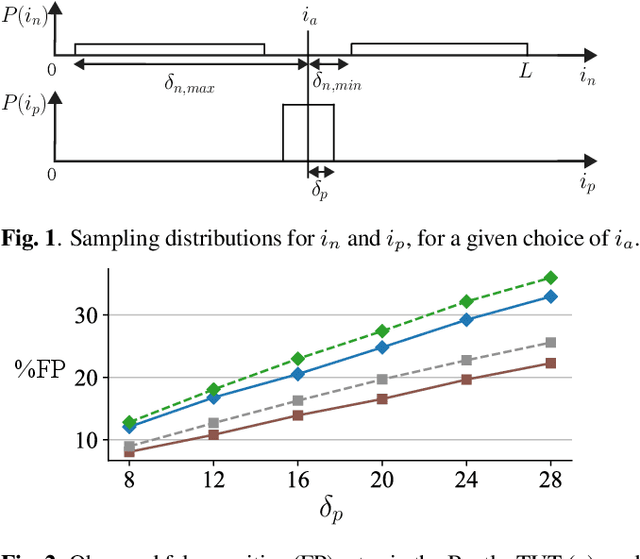
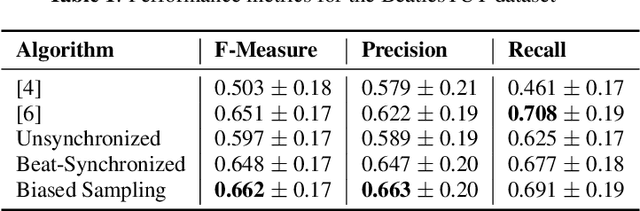

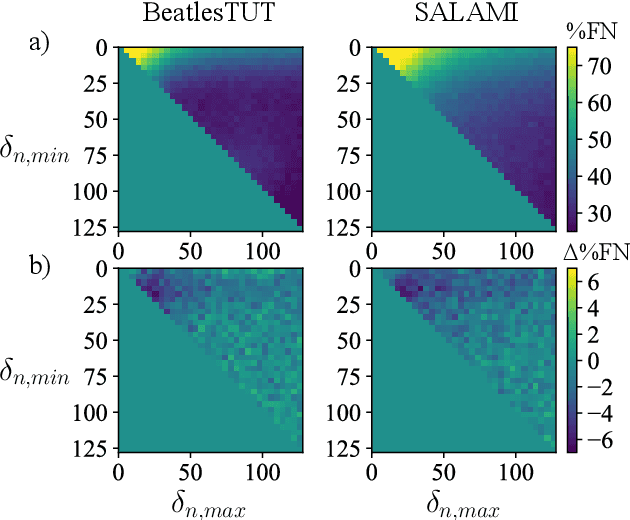
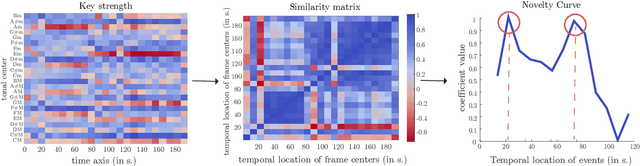
Music segmentation refers to the dual problem of identifying boundaries between, and labeling, distinct music segments, e.g., the chorus, verse, bridge etc. in popular music. The performance of a range of music segmentation algorithms has been shown to be dependent on the audio features chosen to represent the audio. Some approaches have proposed learning feature transformations from music segment annotation data, although, such data is time consuming or expensive to create and as such these approaches are likely limited by the size of their datasets. While annotated music segmentation data is a scarce resource, the amount of available music audio is much greater. In the neighboring field of semantic audio unsupervised deep learning has shown promise in improving the performance of solutions to the query-by-example and sound classification tasks. In this work, unsupervised training of deep feature embeddings using convolutional neural networks (CNNs) is explored for music segmentation. The proposed techniques exploit only the time proximity of audio features that is implicit in any audio timeline. Employing these embeddings in a classic music segmentation algorithm is shown not only to significantly improve the performance of this algorithm, but obtain state of the art performance in unsupervised music segmentation.
Universal Source Separation with Weakly Labelled Data
May 11, 2023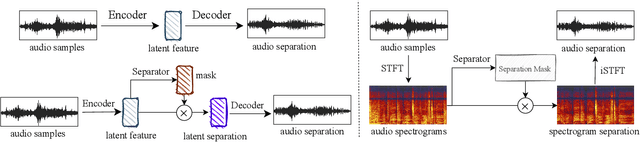
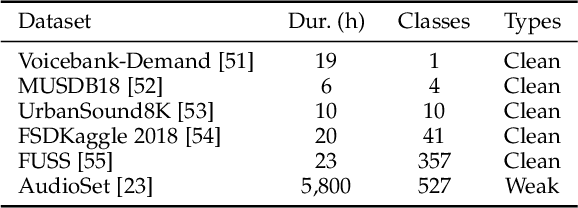
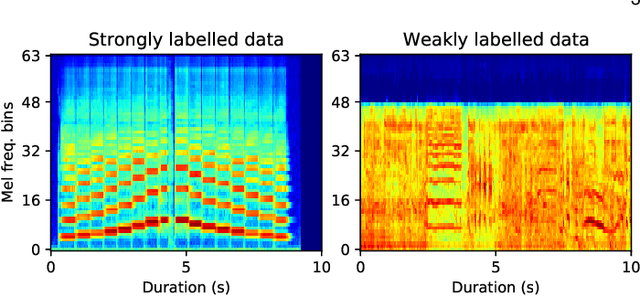

Universal source separation (USS) is a fundamental research task for computational auditory scene analysis, which aims to separate mono recordings into individual source tracks. There are three potential challenges awaiting the solution to the audio source separation task. First, previous audio source separation systems mainly focus on separating one or a limited number of specific sources. There is a lack of research on building a unified system that can separate arbitrary sources via a single model. Second, most previous systems require clean source data to train a separator, while clean source data are scarce. Third, there is a lack of USS system that can automatically detect and separate active sound classes in a hierarchical level. To use large-scale weakly labeled/unlabeled audio data for audio source separation, we propose a universal audio source separation framework containing: 1) an audio tagging model trained on weakly labeled data as a query net; and 2) a conditional source separation model that takes query net outputs as conditions to separate arbitrary sound sources. We investigate various query nets, source separation models, and training strategies and propose a hierarchical USS strategy to automatically detect and separate sound classes from the AudioSet ontology. By solely leveraging the weakly labelled AudioSet, our USS system is successful in separating a wide variety of sound classes, including sound event separation, music source separation, and speech enhancement. The USS system achieves an average signal-to-distortion ratio improvement (SDRi) of 5.57 dB over 527 sound classes of AudioSet; 10.57 dB on the DCASE 2018 Task 2 dataset; 8.12 dB on the MUSDB18 dataset; an SDRi of 7.28 dB on the Slakh2100 dataset; and an SSNR of 9.00 dB on the voicebank-demand dataset. We release the source code at https://github.com/bytedance/uss
Dance2Music: Automatic Dance-driven Music Generation
Jul 20, 2021
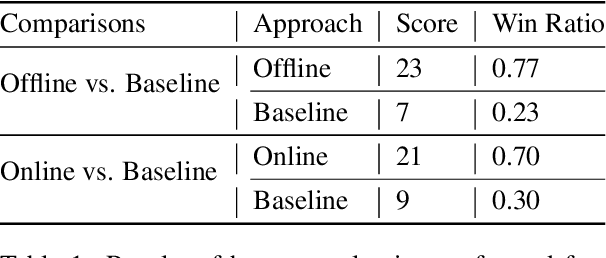

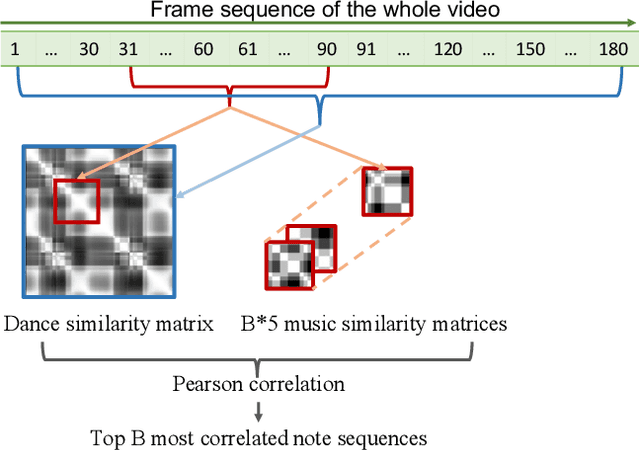
Dance and music typically go hand in hand. The complexities in dance, music, and their synchronisation make them fascinating to study from a computational creativity perspective. While several works have looked at generating dance for a given music, automatically generating music for a given dance remains under-explored. This capability could have several creative expression and entertainment applications. We present some early explorations in this direction. We present a search-based offline approach that generates music after processing the entire dance video and an online approach that uses a deep neural network to generate music on-the-fly as the video proceeds. We compare these approaches to a strong heuristic baseline via human studies and present our findings. We have integrated our online approach in a live demo! A video of the demo can be found here: https://sites.google.com/view/dance2music/live-demo.