 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Music Genre Bars
Feb 27, 2021
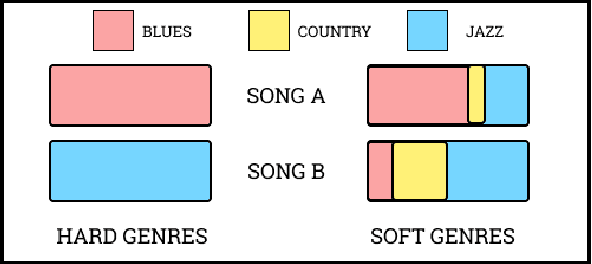
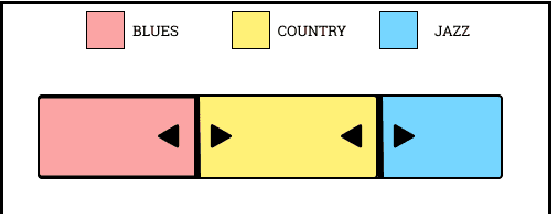

Music Genres, as a popular meta-data of music, are very useful to organize, explore or search music datasets. Soft music genres are weighted multiple-genre annotations to songs. In this initial work, we propose horizontally stacked bar charts to represent a music dataset annotated by these soft music genres. For this purpose, we take an example of a toy dataset consisting of songs labelled with help of three music genres; Blues, Jazz and Country. We demonstrate how such a stacked bar chart can be used as a slider for user-input in an interface. We implement this by embedding this genre bar in a streaming application prototype and show its utility in choosing playlists. We finally conclude by proposing further work and future explorations on our proposed preliminary research.
Track2Vec: fairness music recommendation with a GPU-free customizable-driven framework
Oct 29, 2022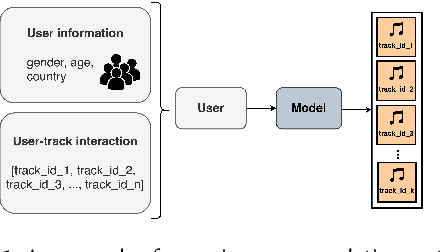
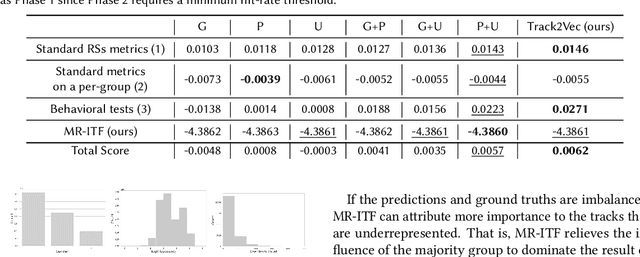
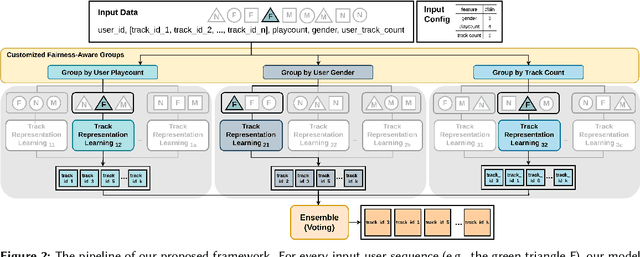

Recommendation systems have illustrated the significant progress made in characterizing users' preferences based on their past behaviors. Despite the effectiveness of recommending accurately, there exist several factors that are essential but unexplored for evaluating various facets of recommendation systems, e.g., fairness, diversity, and limited resources. To address these issues, we propose Track2Vec, a GPU-free customizable-driven framework for fairness music recommendation. In order to take both accuracy and fairness into account, our solution consists of three modules, a customized fairness-aware groups for modeling different features based on configurable settings, a track representation learning module for learning better user embedding, and an ensemble module for ranking the recommendation results from different track representation learning modules. Moreover, inspired by TF-IDF which has been widely used in natural language processing, we introduce a metric called Miss Rate - Inverse Ground Truth Frequency (MR-ITF) to measure the fairness. Extensive experiments demonstrate that our model achieves a 4th price ranking in a GPU-free environment on the leaderboard in the EvalRS @ CIKM 2022 challenge, which is superior to the official baseline by about 200% in terms of the official scores. In addition, the ablation study illustrates the necessity of ensembling each group to acquire both accurate and fair recommendations.
FIGARO: Generating Symbolic Music with Fine-Grained Artistic Control
Jan 26, 2022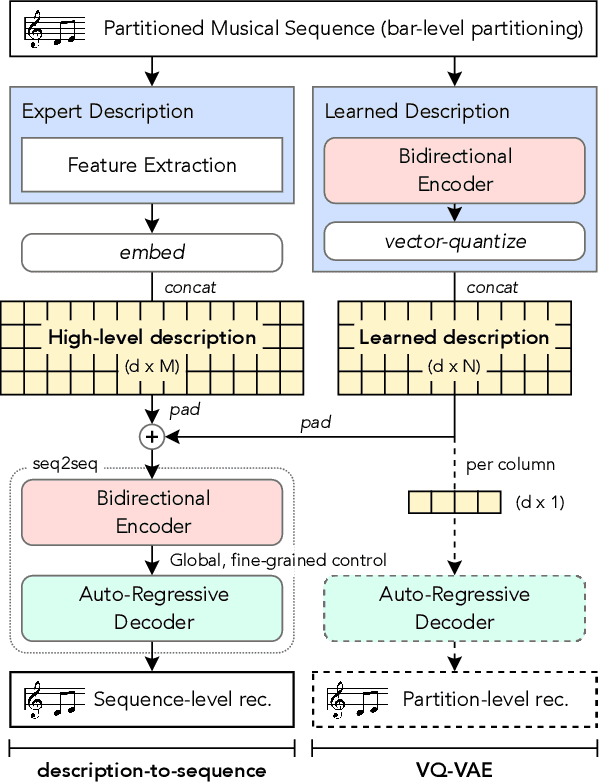

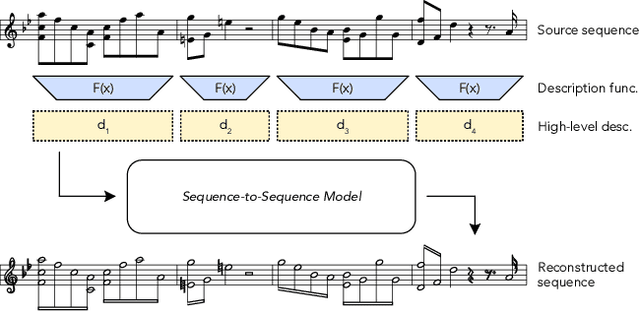
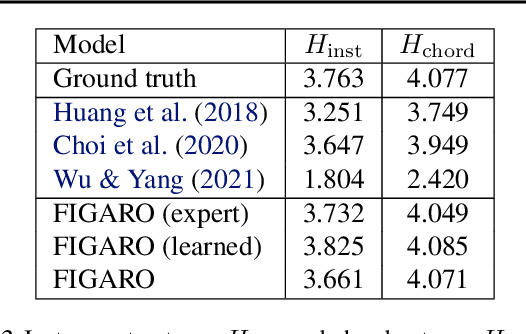
Generating music with deep neural networks has been an area of active research in recent years. While the quality of generated samples has been steadily increasing, most methods are only able to exert minimal control over the generated sequence, if any. We propose the self-supervised \emph{description-to-sequence} task, which allows for fine-grained controllable generation on a global level by extracting high-level features about the target sequence and learning the conditional distribution of sequences given the corresponding high-level description in a sequence-to-sequence modelling setup. We train FIGARO (FIne-grained music Generation via Attention-based, RObust control) by applying \emph{description-to-sequence} modelling to symbolic music. By combining learned high level features with domain knowledge, which acts as a strong inductive bias, the model achieves state-of-the-art results in controllable symbolic music generation and generalizes well beyond the training distribution.
Symbolic music generation conditioned on continuous-valued emotions
Mar 30, 2022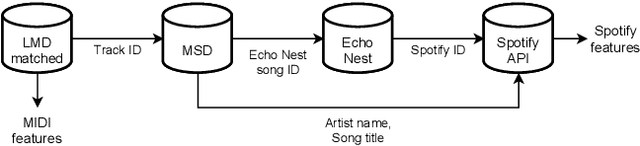
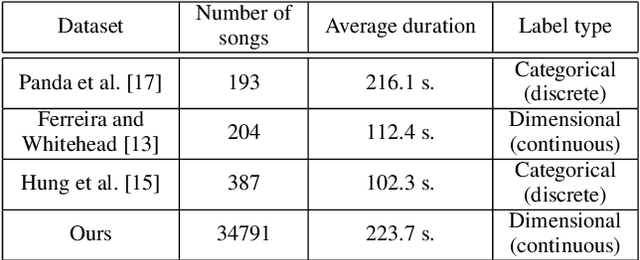
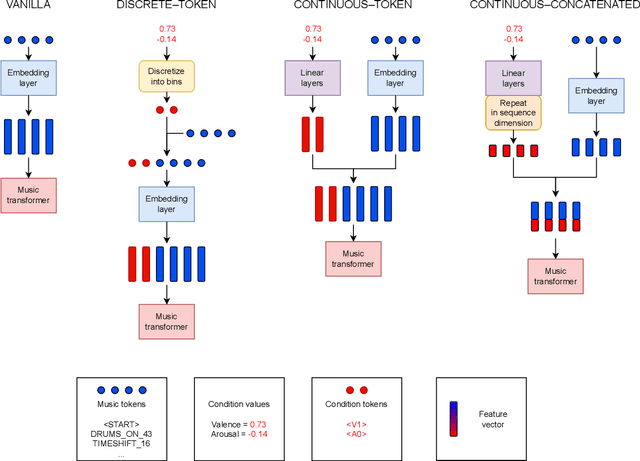
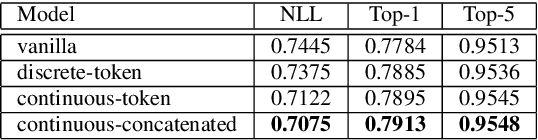
In this paper we present a new approach for the generation of multi-instrument symbolic music driven by musical emotion. The principal novelty of our approach centres on conditioning a state-of-the-art transformer based on continuous-valued valence and arousal labels. In addition, we provide a new large-scale dataset of symbolic music paired with emotion labels in terms of valence and arousal. We evaluate our approach in a quantitative manner in two ways, first by measuring its note prediction accuracy, and second via a regression task in the valence-arousal plane. Our results demonstrate that our proposed approaches outperform conditioning using control tokens which is representative of the current state of the art.
Inductive Matrix Completion and Root-MUSIC-Based Channel Estimation for Intelligent Reflecting Surface (IRS)-Aided Hybrid MIMO Systems
Sep 15, 2022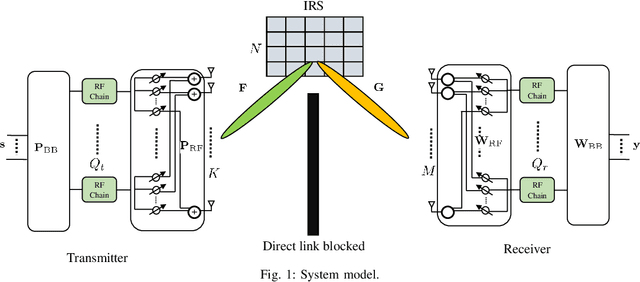
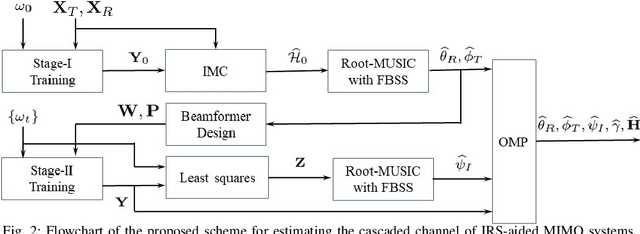
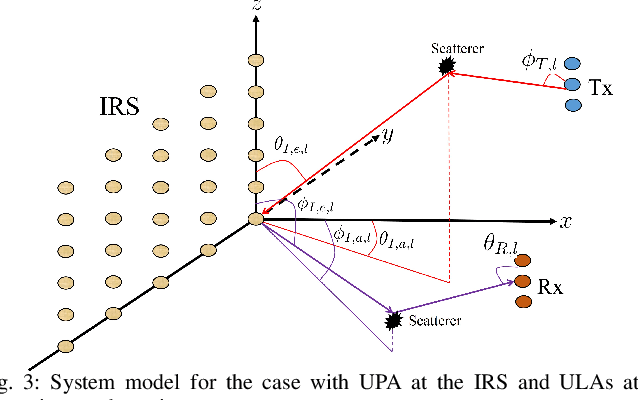
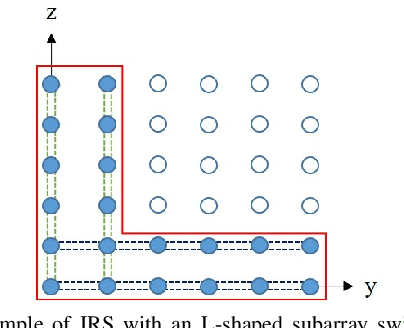
This paper studies the estimation of cascaded channels in passive intelligent reflective surface (IRS)- aided multiple-input multiple-output (MIMO) systems employing hybrid precoders and combiners. We propose a low-complexity solution that estimates the channel parameters progressively. The angles of departure (AoDs) and angles of arrival (AoAs) at the transmitter and receiver, respectively, are first estimated using inductive matrix completion (IMC) followed by root-MUSIC based super-resolution spectrum estimation. Forward-backward spatial smoothing (FBSS) is applied to address the coherence issue. Using the estimated AoAs and AoDs, the training precoders and combiners are then optimized and the angle differences between the AoAs and AoDs at the IRS are estimated using the least squares (LS) method followed by FBSS and the root-MUSIC algorithm. Finally, the composite path gains of the cascaded channel are estimated using on-grid sparse recovery with a small-size dictionary. The simulation results suggest that the proposed estimator can achieve improved channel parameter estimation performance with lower complexity as compared to several recently reported alternatives, thanks to the exploitation of the knowledge of the array responses and low-rankness of the channel using low-complexity algorithms at all the stages.
A Rapid Power-iterative Root-MUSIC Estimator for Massive/Ultra-massive MIMO Receiver
May 16, 2022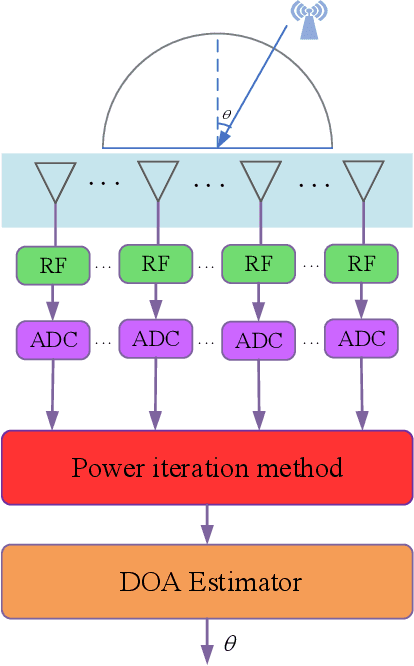
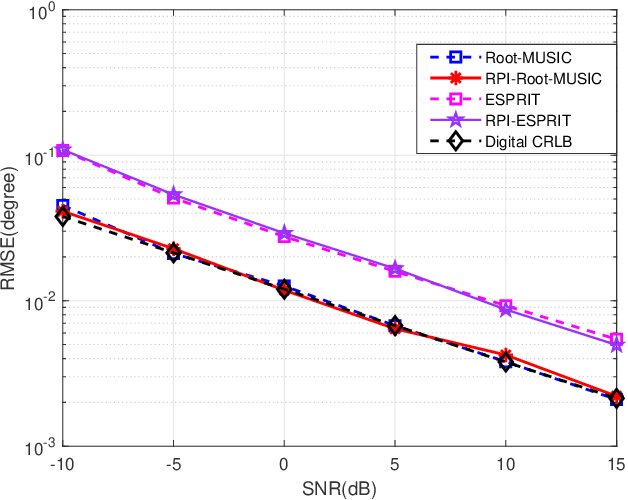
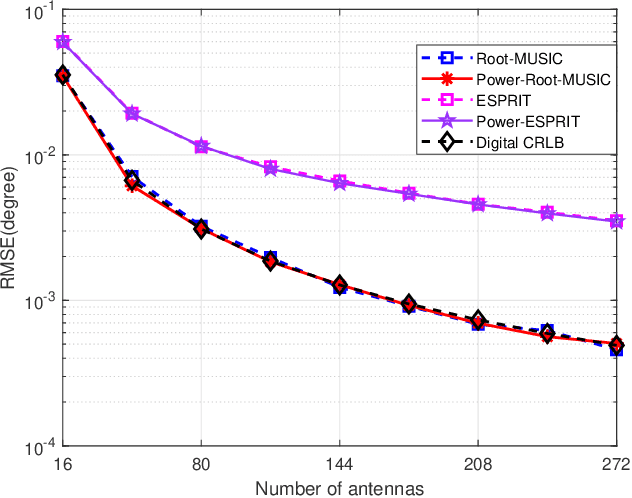
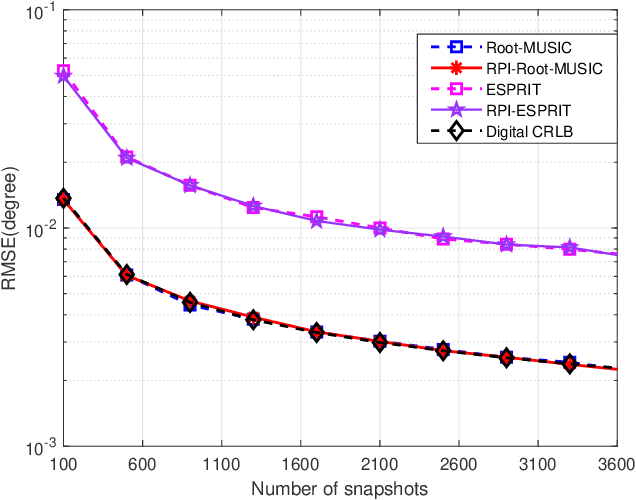
For a passive direction of arrival (DOA) measurement system using massive multiple input multiple output (MIMO), the complexity of the covariance matrix decompositionbased DOA measurement method is extremely high. To significantly reduce the computational complexity, two strategies are proposed. Firstly, a rapid power-iterative estimation of signal parameters via rotational invariance technique (RPI-ESPRIT) method is proposed, which not only reduces the complexity but also achieves good directional measurement results. However, the general complexity is still high. In order to further the complexity, a rapid power-iterative root Multiple Signal Classification (RPIRoot-MUSIC) method is proposed. Simulation results show that the two proposed methods outperform the classical DOA estimation method in terms of computational complexity. In particular, the lowest complexity achieved by the RPI-Root-MUSIC method is about two-order-magnitude lower than that of Root-MUSIC in terms of FLOP. In addition, it is verified that the initial vector and relative error have a substantial effect on the performance of computational complexity.
A New Corpus for Computational Music Research and A Novel Method for Musical Structure Analysis
Aug 31, 2022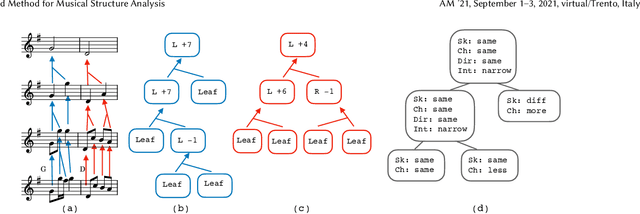

Computational models of music, while providing good descriptions of melodic development, still cannot fully grasp the general structure comprised of repetitions, transpositions, and reuse of melodic material. We present a corpus of strongly structured baroque allemandes, and describe a top-down approach to abstract the shared structure of their musical content using tree representations produced from pairwise differences between the Schenkerian-inspired analyses of each piece, thereby providing a rich hierarchical description of the corpus.
Music Source Separation with Generative Flow
Apr 26, 2022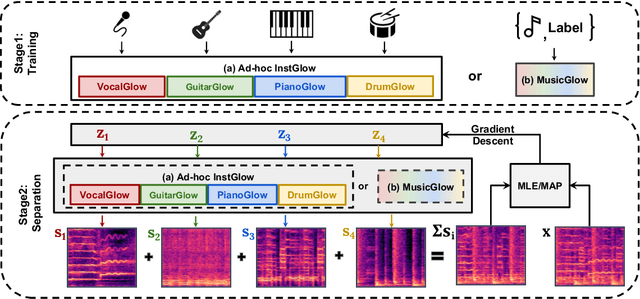
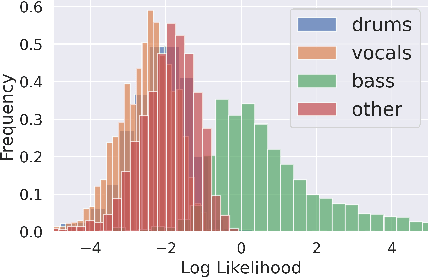
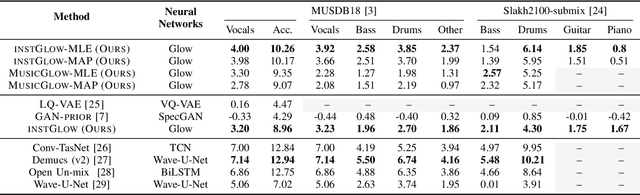
Full supervision models for source separation are trained on mixture-source parallel data and have achieved superior performance in recent years. However, large-scale and naturally mixed parallel training data are difficult to obtain for music, and such models are difficult to adapt to mixtures with new sources. Source-only supervision models, in contrast, only require clean sources for training; They learn source models and then apply these models to separate the mixture.
Digital Audio Processing Tools for Music Corpus Studies
Nov 09, 2021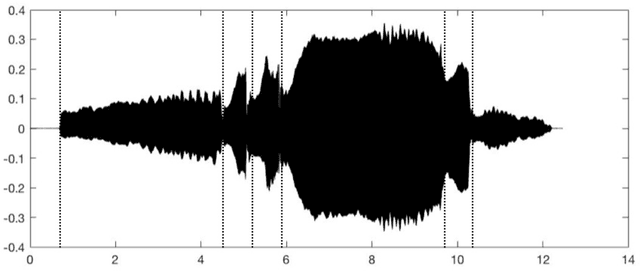
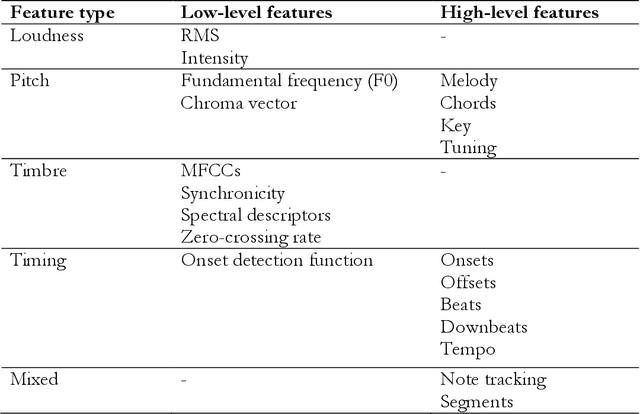
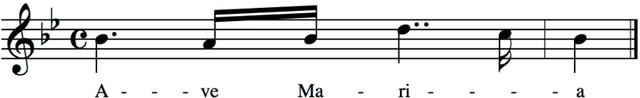
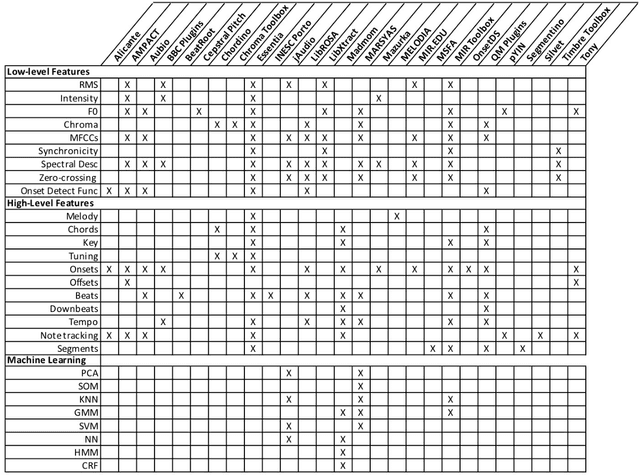
Digital audio processing tools offer music researchers the opportunity to examine both non-notated music and music as performance. This chapter summarises the types of information that can be extracted from audio as well as currently available audio tools for music corpus studies. The survey of extraction methods includes both a primer on signal processing and background theory on audio feature extraction. The survey of audio tools focuses on widely used tools, including both those with a graphical user interface, namely Audacity and Sonic Visualiser, and code-based tools written in the C/C++, Java, MATLAB, and Python computer programming languages.