 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Automated Time-frequency Domain Audio Crossfades using Graph Cuts
Jan 31, 2023
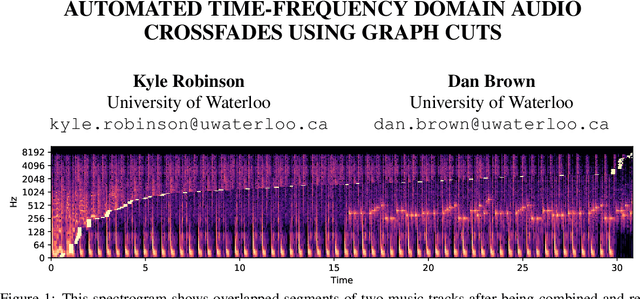
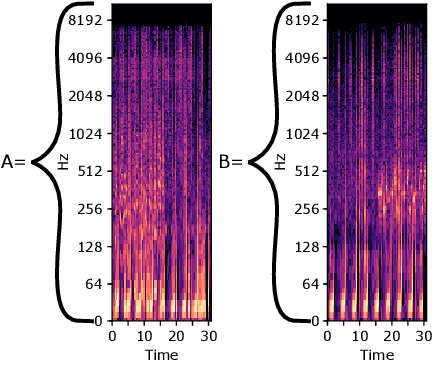
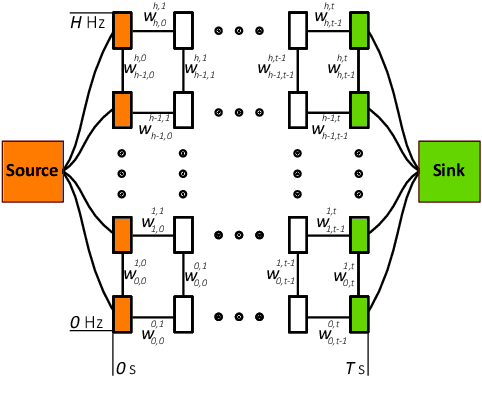
The problem of transitioning smoothly from one audio clip to another arises in many music consumption scenarios, especially as music consumption has moved from professionally curated and live-streamed radios to personal playback devices and services. we present the first steps toward a new method of automatically transitioning from one audio clip to another by discretizing the frequency spectrum into bins and then finding transition times for each bin. We phrase the problem as one of graph flow optimization; specifically min-cut/max-flow.
InverseMV: Composing Piano Scores with a Convolutional Video-Music Transformer
Dec 31, 2021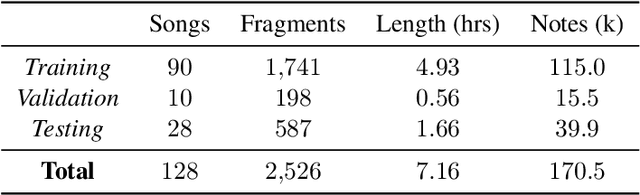
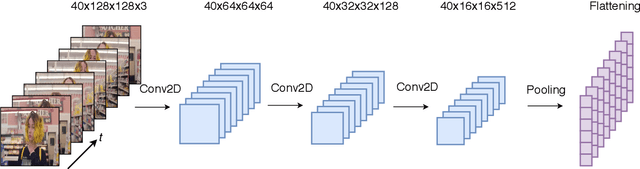
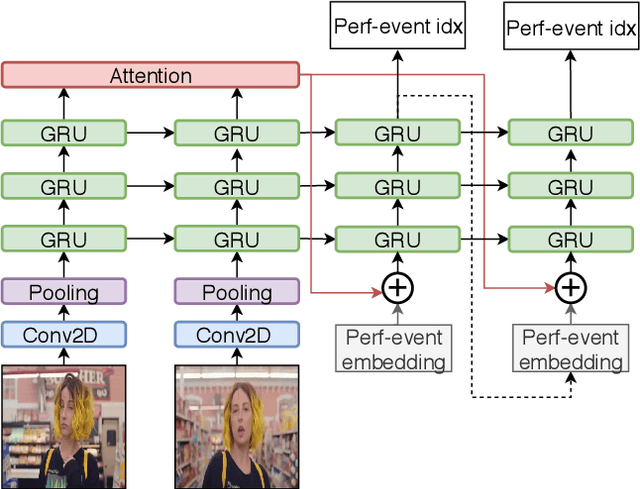
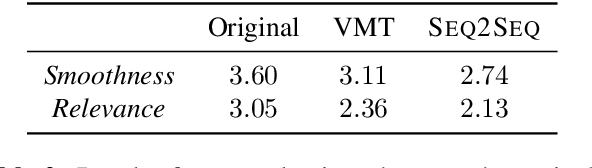
Many social media users prefer consuming content in the form of videos rather than text. However, in order for content creators to produce videos with a high click-through rate, much editing is needed to match the footage to the music. This posts additional challenges for more amateur video makers. Therefore, we propose a novel attention-based model VMT (Video-Music Transformer) that automatically generates piano scores from video frames. Using music generated from models also prevent potential copyright infringements that often come with using existing music. To the best of our knowledge, there is no work besides the proposed VMT that aims to compose music for video. Additionally, there lacks a dataset with aligned video and symbolic music. We release a new dataset composed of over 7 hours of piano scores with fine alignment between pop music videos and MIDI files. We conduct experiments with human evaluation on VMT, SeqSeq model (our baseline), and the original piano version soundtrack. VMT achieves consistent improvements over the baseline on music smoothness and video relevance. In particular, with the relevance scores and our case study, our model has shown the capability of multimodality on frame-level actors' movement for music generation. Our VMT model, along with the new dataset, presents a promising research direction toward composing the matching soundtrack for videos. We have released our code at https://github.com/linchintung/VMT
Soft Dynamic Time Warping for Multi-Pitch Estimation and Beyond
Apr 11, 2023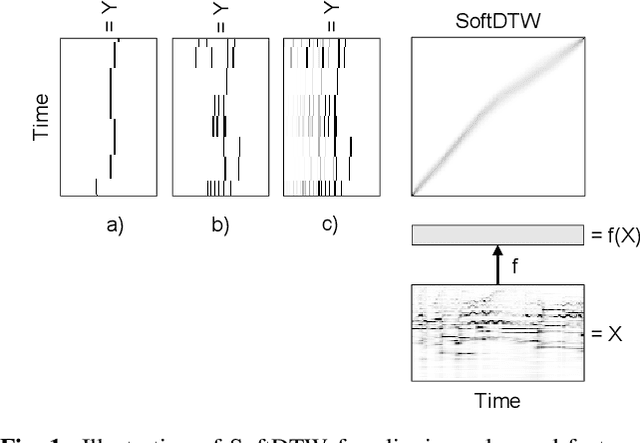
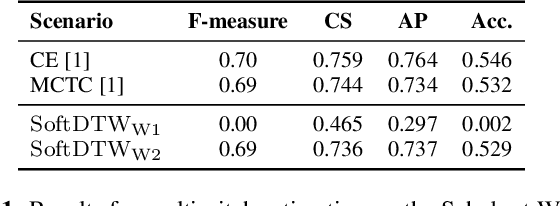
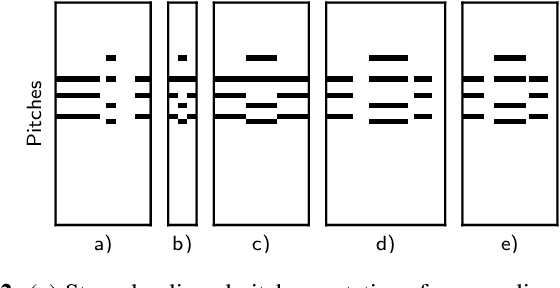
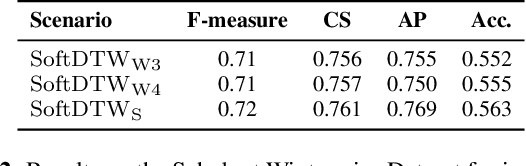
Many tasks in music information retrieval (MIR) involve weakly aligned data, where exact temporal correspondences are unknown. The connectionist temporal classification (CTC) loss is a standard technique to learn feature representations based on weakly aligned training data. However, CTC is limited to discrete-valued target sequences and can be difficult to extend to multi-label problems. In this article, we show how soft dynamic time warping (SoftDTW), a differentiable variant of classical DTW, can be used as an alternative to CTC. Using multi-pitch estimation as an example scenario, we show that SoftDTW yields results on par with a state-of-the-art multi-label extension of CTC. In addition to being more elegant in terms of its algorithmic formulation, SoftDTW naturally extends to real-valued target sequences.
Enhancing Audio Perception of Music By AI Picked Room Acoustics
Aug 16, 2022
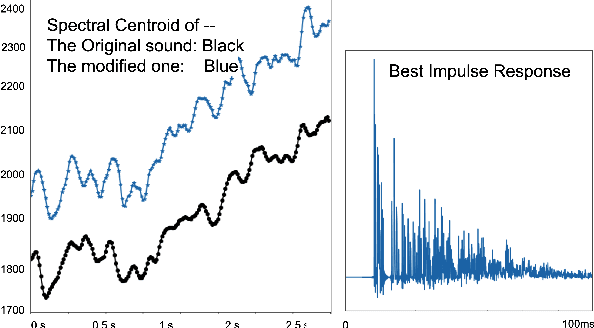
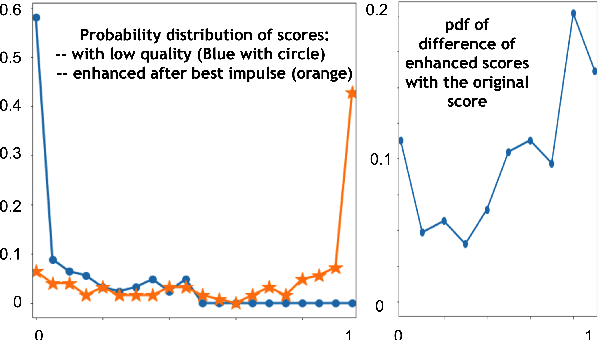
Every sound that we hear is the result of successive convolutional operations (e.g. room acoustics, microphone characteristics, resonant properties of the instrument itself, not to mention characteristics and limitations of the sound reproduction system). In this work we seek to determine the best room in which to perform a particular piece using AI. Additionally, we use room acoustics as a way to enhance the perceptual qualities of a given sound. Historically, rooms (particularly Churches and concert halls) were designed to host and serve specific musical functions. In some cases the architectural acoustical qualities enhanced the music performed there. We try to mimic this, as a first step, by designating room impulse responses that would correlate to producing enhanced sound quality for particular music. A convolutional architecture is first trained to take in an audio sample and mimic the ratings of experts with about 78 % accuracy for various instrument families and notes for perceptual qualities. This gives us a scoring function for any audio sample which can rate the perceptual pleasantness of a note automatically. Now, via a library of about 60,000 synthetic impulse responses mimicking all kinds of room, materials, etc, we use a simple convolution operation, to transform the sound as if it was played in a particular room. The perceptual evaluator is used to rank the musical sounds, and yield the "best room or the concert hall" to play a sound. As a byproduct it can also use room acoustics to turn a poor quality sound into a "good" sound.
MusIAC: An extensible generative framework for Music Infilling Applications with multi-level Control
Feb 11, 2022
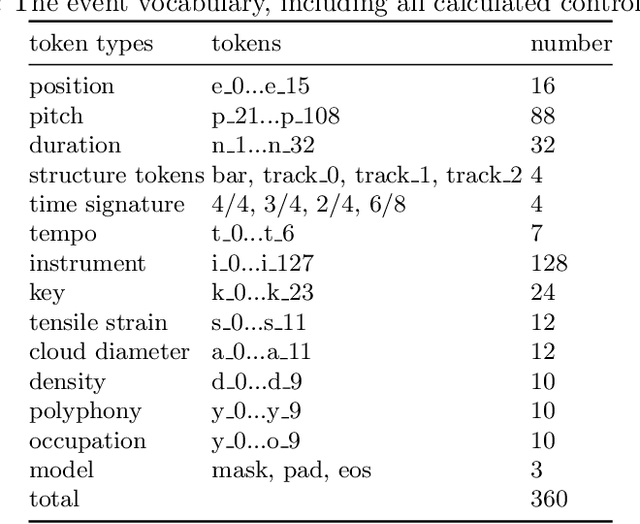


We present a novel music generation framework for music infilling, with a user friendly interface. Infilling refers to the task of generating musical sections given the surrounding multi-track music. The proposed transformer-based framework is extensible for new control tokens as the added music control tokens such as tonal tension per bar and track polyphony level in this work. We explore the effects of including several musically meaningful control tokens, and evaluate the results using objective metrics related to pitch and rhythm. Our results demonstrate that adding additional control tokens helps to generate music with stronger stylistic similarities to the original music. It also provides the user with more control to change properties like the music texture and tonal tension in each bar compared to previous research which only provided control for track density. We present the model in a Google Colab notebook to enable interactive generation.
An Analysis of Classification Approaches for Hit Song Prediction using Engineered Metadata Features with Lyrics and Audio Features
Jan 31, 2023

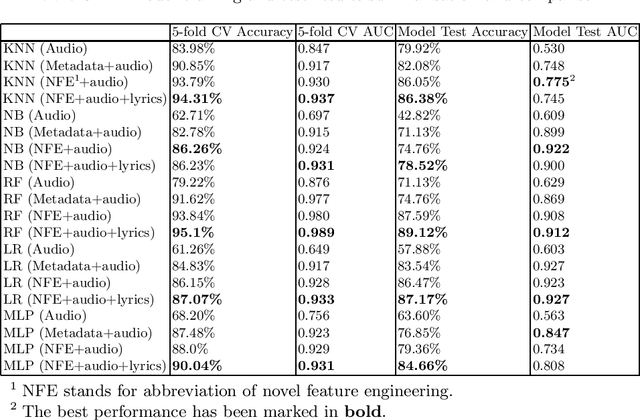
Hit song prediction, one of the emerging fields in music information retrieval (MIR), remains a considerable challenge. Being able to understand what makes a given song a hit is clearly beneficial to the whole music industry. Previous approaches to hit song prediction have focused on using audio features of a record. This study aims to improve the prediction result of the top 10 hits among Billboard Hot 100 songs using more alternative metadata, including song audio features provided by Spotify, song lyrics, and novel metadata-based features (title topic, popularity continuity and genre class). Five machine learning approaches are applied, including: k-nearest neighbours, Naive Bayes, Random Forest, Logistic Regression and Multilayer Perceptron. Our results show that Random Forest (RF) and Logistic Regression (LR) with all features (including novel features, song audio features and lyrics features) outperforms other models, achieving 89.1% and 87.2% accuracy, and 0.91 and 0.93 AUC, respectively. Our findings also demonstrate the utility of our novel music metadata features, which contributed most to the models' discriminative performance.
Multimodal Lyrics-Rhythm Matching
Jan 06, 2023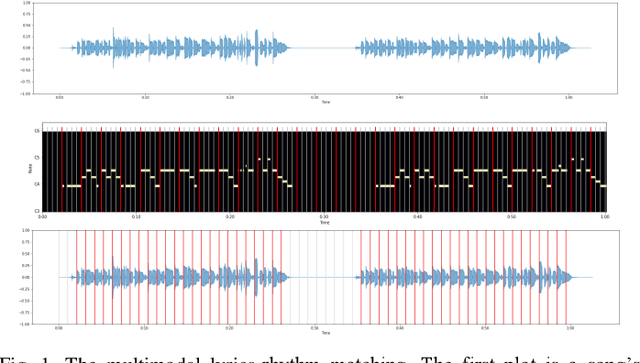
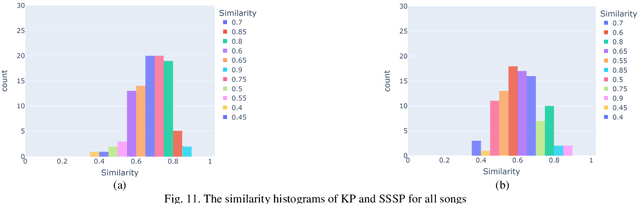

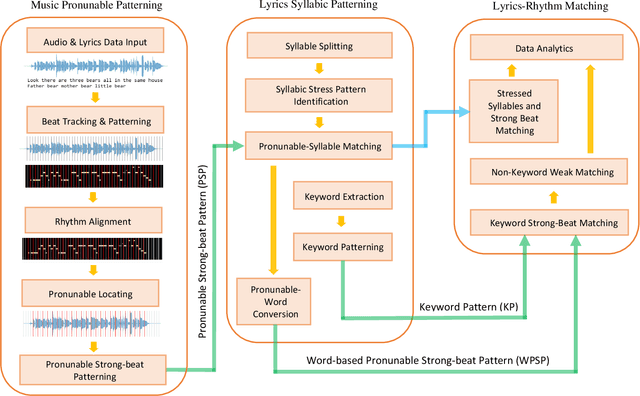
Despite the recent increase in research on artificial intelligence for music, prominent correlations between key components of lyrics and rhythm such as keywords, stressed syllables, and strong beats are not frequently studied. Ths is likely due to challenges such as audio misalignment, inaccuracies in syllabic identification, and most importantly, the need for cross-disciplinary knowledge. To address this lack of research, we propose a novel multimodal lyrics-rhythm matching approach in this paper that specifically matches key components of lyrics and music with each other without any language limitations. We use audio instead of sheet music with readily available metadata, which creates more challenges yet increases the application flexibility of our method. Furthermore, our approach creatively generates several patterns involving various multimodalities, including music strong beats, lyrical syllables, auditory changes in a singer's pronunciation, and especially lyrical keywords, which are utilized for matching key lyrical elements with key rhythmic elements. This advantageous approach not only provides a unique way to study auditory lyrics-rhythm correlations including efficient rhythm-based audio alignment algorithms, but also bridges computational linguistics with music as well as music cognition. Our experimental results reveal an 0.81 probability of matching on average, and around 30% of the songs have a probability of 0.9 or higher of keywords landing on strong beats, including 12% of the songs with a perfect landing. Also, the similarity metrics are used to evaluate the correlation between lyrics and rhythm. It shows that nearly 50% of the songs have 0.70 similarity or higher. In conclusion, our approach contributes significantly to the lyrics-rhythm relationship by computationally unveiling insightful correlations.
Comparing the Accuracy of Deep Neural Networks (DNN) and Convolutional Neural Network (CNN) in Music Genre Recognition (MGR): Experiments on Kurdish Music
Nov 22, 2021

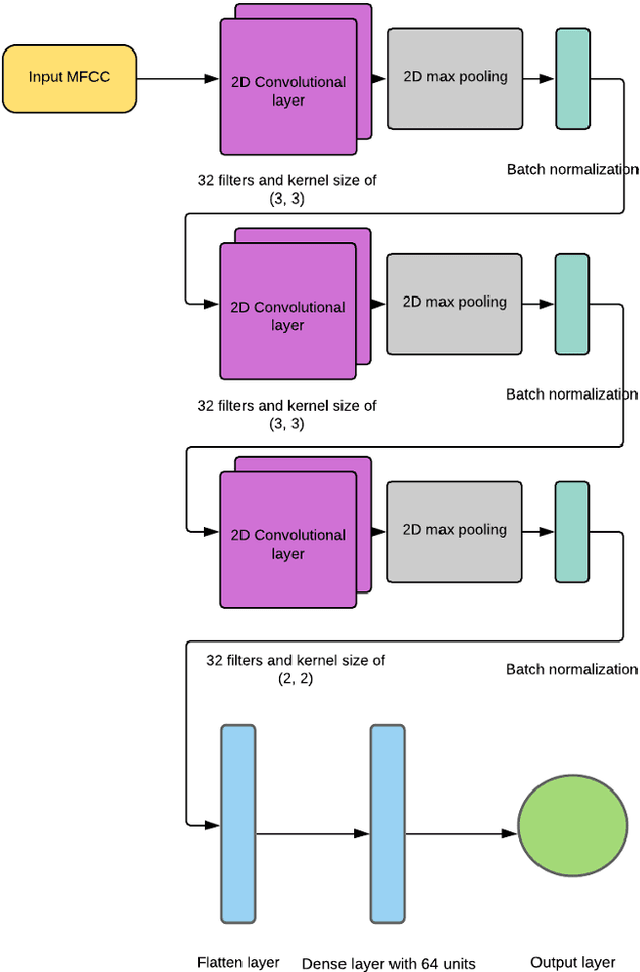

Musicologists use various labels to classify similar music styles under a shared title. But, non-specialists may categorize music differently. That could be through finding patterns in harmony, instruments, and form of the music. People usually identify a music genre solely by listening, but now computers and Artificial Intelligence (AI) can automate this process. The work on applying AI in the classification of types of music has been growing recently, but there is no evidence of such research on the Kurdish music genres. In this research, we developed a dataset that contains 880 samples from eight different Kurdish music genres. We evaluated two machine learning approaches, a Deep Neural Network (DNN) and a Convolutional Neural Network (CNN), to recognize the genres. The results showed that the CNN model outperformed the DNN by achieving 92% versus 90% accuracy.
GCNSLIM: Graph Convolutional Network with Sparse Linear Methods for E-government Service Recommendation
May 15, 2023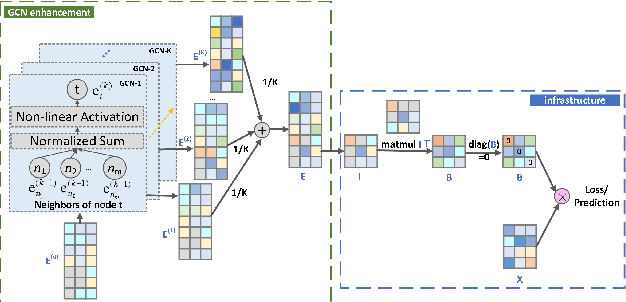

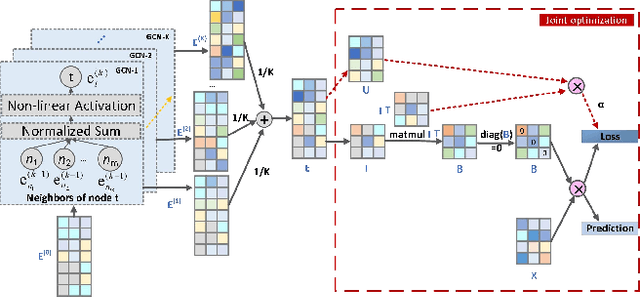
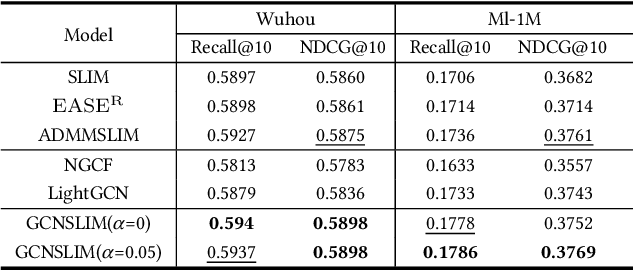
Graph Convolutional Networks have made significant strides in Collabora-tive Filtering recommendations. However, existing GCN-based CF methods are mainly based on matrix factorization and incorporate some optimization tech-niques to enhance performance, which are not enough to handle the complexities of diverse real-world recommendation scenarios. E-government service recommendation is a crucial area for recommendation re-search as it involves rigid aspects of people's lives. However, it has not received ad-equate attention in comparison to other recommendation scenarios like news and music recommendation. We empirically find that when existing GCN-based CF methods are directly applied to e-government service recommendation, they are limited by the MF framework and showing poor performance. This is because MF's equal treatment of users and items is not appropriate for scenarios where the number of users and items is unbalanced. In this work, we propose a new model, GCNSLIM, which combines GCN and sparse linear methods instead of combining GCN and MF to accommodate e-government service recommendation. In particular, GCNSLIM explicitly injects high-order collaborative signals obtained from multi-layer light graph convolutions into the item similarity matrix in the SLIM frame-work, effectively improving the recommendation accuracy. In addition, we propose two optimization measures, removing layer 0 embedding and adding nonlinear acti-vation, to further adapt to the characteristics of e-government service recommenda-tion scenarios. Furthermore, we propose a joint optimization mode to adapt to more diverse recommendation scenarios. We conduct extensive experiments on a real e-government service dataset and a common public dataset and demonstrate the ef-fectiveness of GCNSLIM in recommendation accuracy and operational performance.
FIGARO: Generating Symbolic Music with Fine-Grained Artistic Control
Feb 01, 2022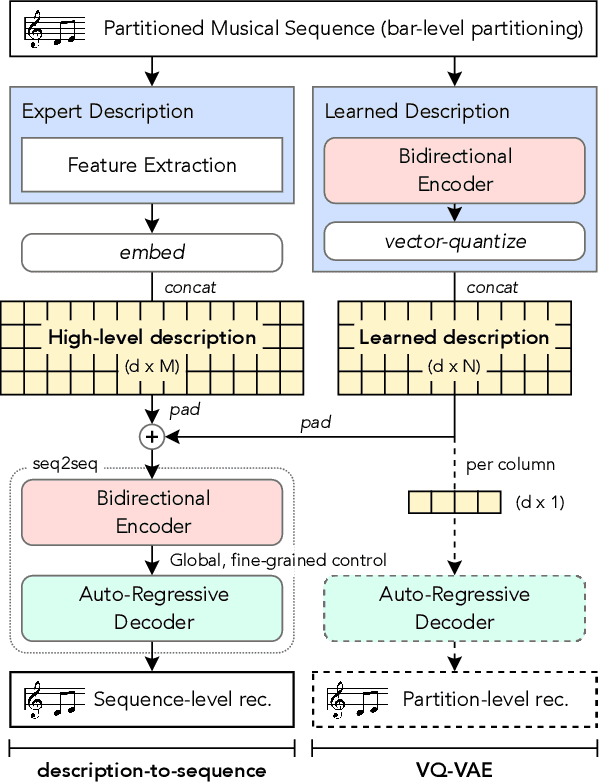

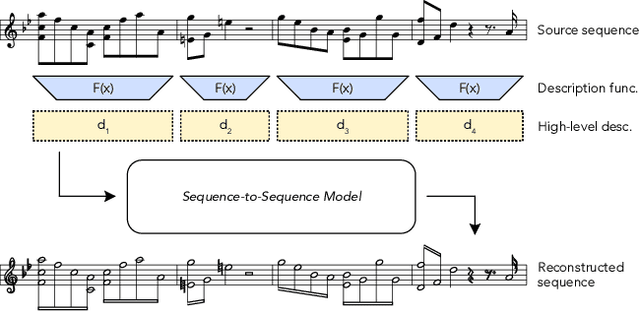
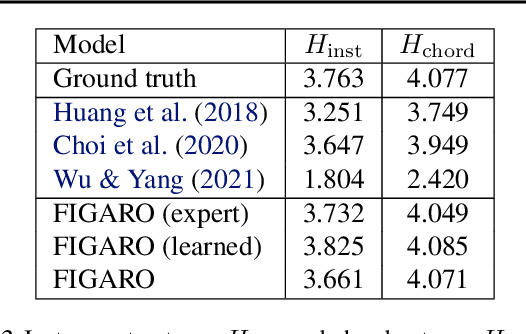
Generating music with deep neural networks has been an area of active research in recent years. While the quality of generated samples has been steadily increasing, most methods are only able to exert minimal control over the generated sequence, if any. We propose the self-supervised description-to-sequence task, which allows for fine-grained controllable generation on a global level. We do so by extracting high-level features about the target sequence and learning the conditional distribution of sequences given the corresponding high-level description in a sequence-to-sequence modelling setup. We train FIGARO (FIne-grained music Generation via Attention-based, RObust control) by applying description-to-sequence modelling to symbolic music. By combining learned high level features with domain knowledge, which acts as a strong inductive bias, the model achieves state-of-the-art results in controllable symbolic music generation and generalizes well beyond the training distribution.