 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Deep Performer: Score-to-Audio Music Performance Synthesis
Feb 12, 2022
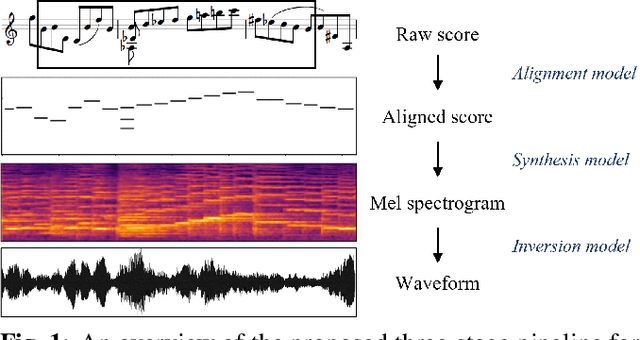

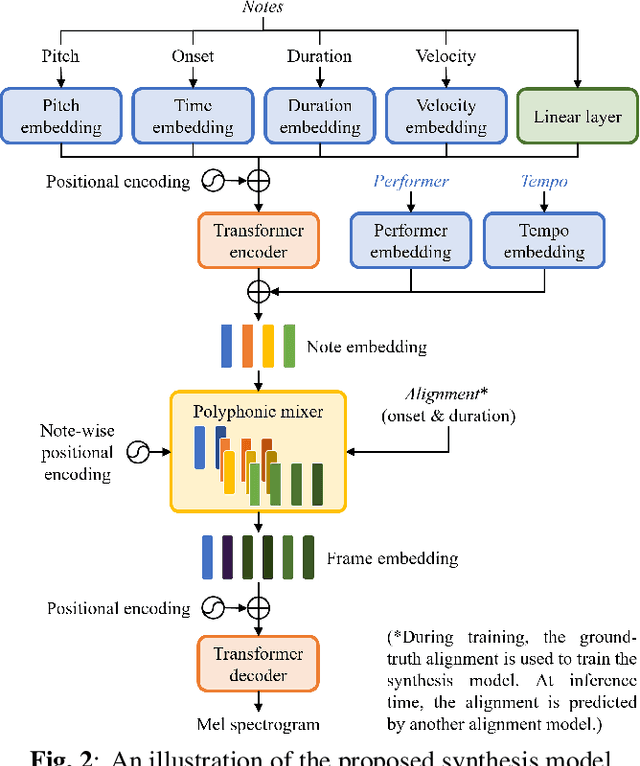

Music performance synthesis aims to synthesize a musical score into a natural performance. In this paper, we borrow recent advances in text-to-speech synthesis and present the Deep Performer -- a novel system for score-to-audio music performance synthesis. Unlike speech, music often contains polyphony and long notes. Hence, we propose two new techniques for handling polyphonic inputs and providing a fine-grained conditioning in a transformer encoder-decoder model. To train our proposed system, we present a new violin dataset consisting of paired recordings and scores along with estimated alignments between them. We show that our proposed model can synthesize music with clear polyphony and harmonic structures. In a listening test, we achieve competitive quality against the baseline model, a conditional generative audio model, in terms of pitch accuracy, timbre and noise level. Moreover, our proposed model significantly outperforms the baseline on an existing piano dataset in overall quality.
Music-to-Dance Generation with Optimal Transport
Dec 03, 2021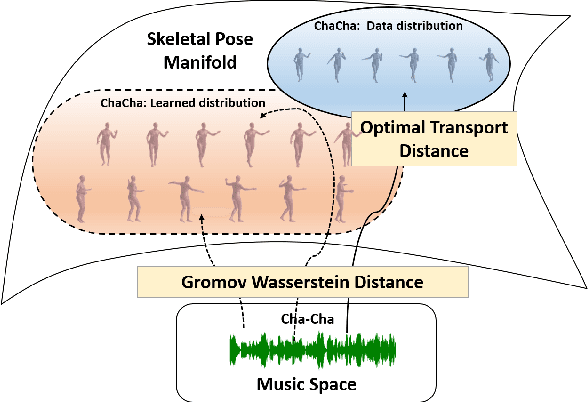
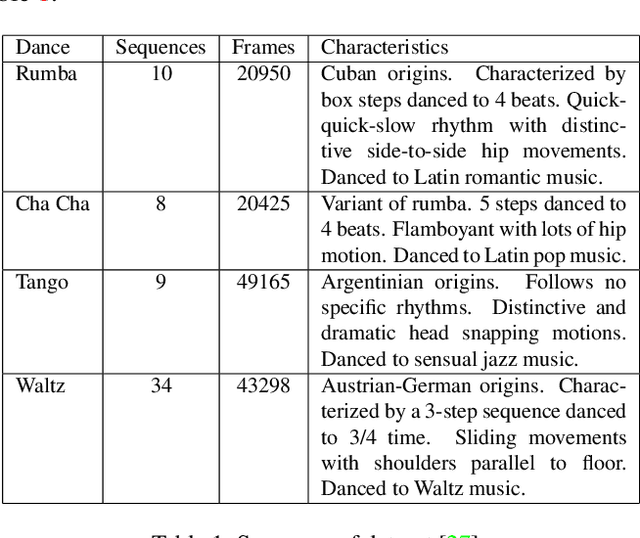
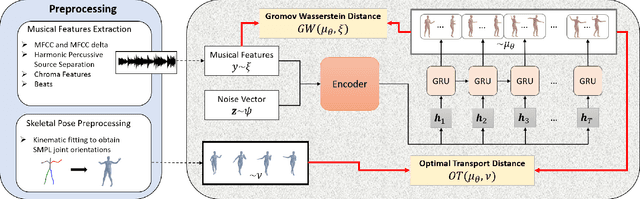
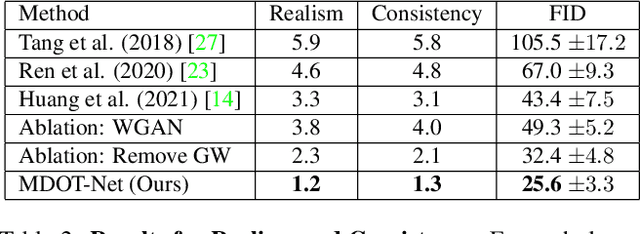
Dance choreography for a piece of music is a challenging task, having to be creative in presenting distinctive stylistic dance elements while taking into account the musical theme and rhythm. It has been tackled by different approaches such as similarity retrieval, sequence-to-sequence modeling and generative adversarial networks, but their generated dance sequences are often short of motion realism, diversity and music consistency. In this paper, we propose a Music-to-Dance with Optimal Transport Network (MDOT-Net) for learning to generate 3D dance choreographs from music. We introduce an optimal transport distance for evaluating the authenticity of the generated dance distribution and a Gromov-Wasserstein distance to measure the correspondence between the dance distribution and the input music. This gives a well defined and non-divergent training objective that mitigates the limitation of standard GAN training which is frequently plagued with instability and divergent generator loss issues. Extensive experiments demonstrate that our MDOT-Net can synthesize realistic and diverse dances which achieve an organic unity with the input music, reflecting the shared intentionality and matching the rhythmic articulation.
Diversity in the Music Listening Experience: Insights from Focus Group Interviews
Jan 25, 2022Music listening in today's digital spaces is highly characterized by the availability of huge music catalogues, accessible by people all over the world. In this scenario, recommender systems are designed to guide listeners in finding tracks and artists that best fit their requests, having therefore the power to influence the diversity of the music they listen to. Albeit several works have proposed new techniques for developing diversity-aware recommendations, little is known about how people perceive diversity while interacting with music recommendations. In this study, we interview several listeners about the role that diversity plays in their listening experience, trying to get a better understanding of how they interact with music recommendations. We recruit the listeners among the participants of a previous quantitative study, where they were confronted with the notion of diversity when asked to identify, from a series of electronic music lists, the most diverse ones according to their beliefs. As a follow-up, in this qualitative study we carry out semi-structured interviews to understand how listeners may assess the diversity of a music list and to investigate their experiences with music recommendation diversity. We report here our main findings on 1) what can influence the diversity assessment of tracks and artists' music lists, and 2) which factors can characterize listeners' interaction with music recommendation diversity.
Multi-Source Contrastive Learning from Musical Audio
Feb 14, 2023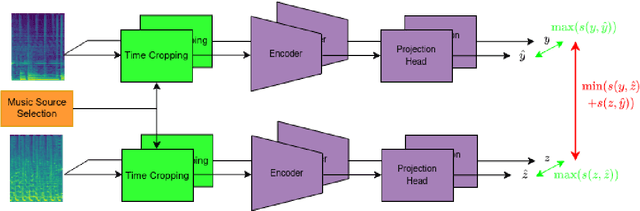
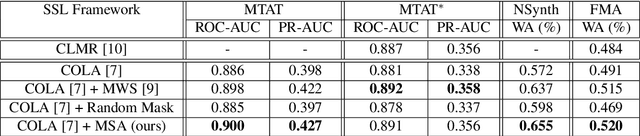
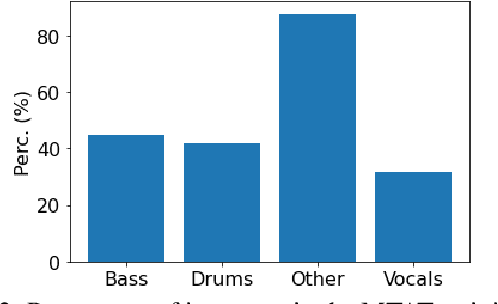
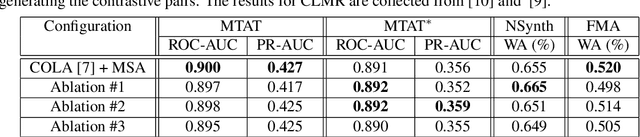
Contrastive learning constitutes an emerging branch of self-supervised learning that leverages large amounts of unlabeled data, by learning a latent space, where pairs of different views of the same sample are associated. In this paper, we propose musical source association as a pair generation strategy in the context of contrastive music representation learning. To this end, we modify COLA, a widely used contrastive learning audio framework, to learn to associate a song excerpt with a stochastically selected and automatically extracted vocal or instrumental source. We further introduce a novel modification to the contrastive loss to incorporate information about the existence or absence of specific sources. Our experimental evaluation in three different downstream tasks (music auto-tagging, instrument classification and music genre classification) using the publicly available Magna-Tag-A-Tune (MTAT) as a source dataset yields competitive results to existing literature methods, as well as faster network convergence. The results also show that this pre-training method can be steered towards specific features, according to the selected musical source, while also being dependent on the quality of the separated sources.
Music Classification: Beyond Supervised Learning, Towards Real-world Applications
Dec 03, 2021Music classification is a music information retrieval (MIR) task to classify music items to labels such as genre, mood, and instruments. It is also closely related to other concepts such as music similarity and musical preference. In this tutorial, we put our focus on two directions - the recent training schemes beyond supervised learning and the successful application of music classification models. The target audience for this web book is researchers and practitioners who are interested in state-of-the-art music classification research and building real-world applications. We assume the audience is familiar with the basic machine learning concepts. In this book, we present three lectures as follows: 1. Music classification overview: Task definition, applications, existing approaches, datasets, 2. Beyond supervised learning: Semi- and self-supervised learning for music classification, 3. Towards real-world applications: Less-discussed, yet important research issues in practice.
Cross-modal Music Emotion Recognition Using Composite Loss-based Embeddings
Dec 14, 2021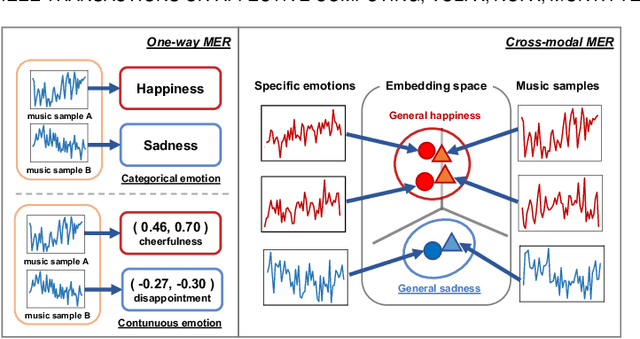
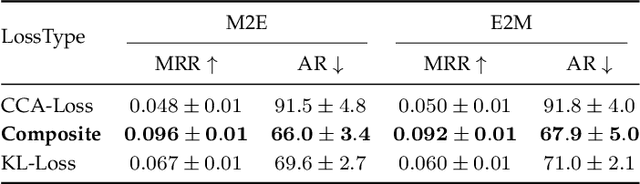
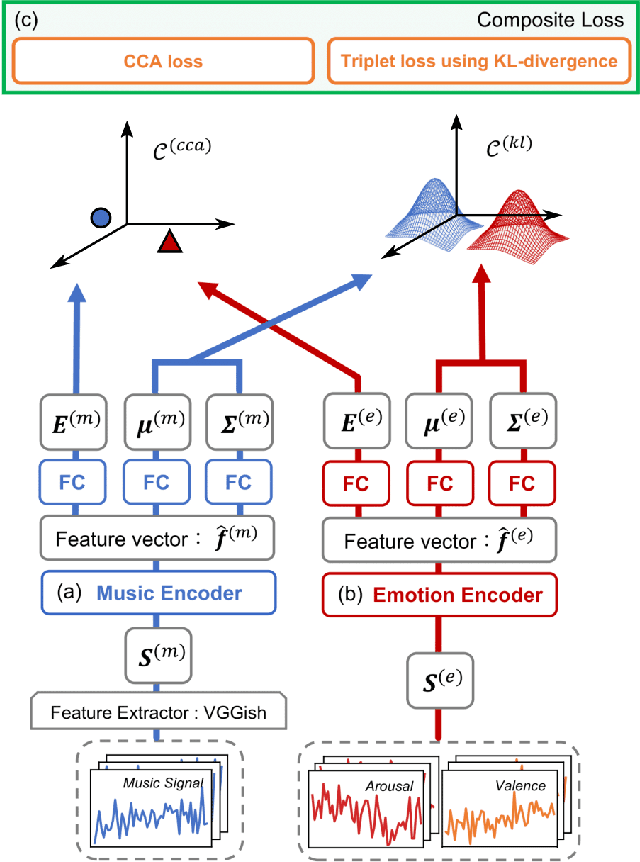
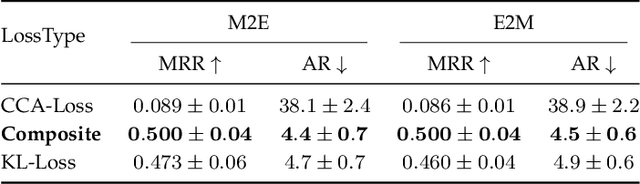
Most music emotion recognition approaches use one-way classification or regression that estimates a general emotion from a distribution of music samples, but without considering emotional variations (e.g., happiness can be further categorised into much, moderate or little happiness). We propose a cross-modal music emotion recognition approach that associates music samples with emotions in a common space by considering both of their general and specific characteristics. Since the association of music samples with emotions is uncertain due to subjective human perceptions, we compute composite loss-based embeddings obtained to maximise two statistical characteristics, one being the correlation between music samples and emotions based on canonical correlation analysis, and the other being a probabilistic similarity between a music sample and an emotion with KL-divergence. Experiments on two benchmark datasets demonstrate the superiority of our approach over one-way baselines. In addition, detailed analysis show that our approach can accomplish robust cross-modal music emotion recognition that not only identifies music samples matching with a specific emotion but also detects emotions expressed in a certain music sample.
Multiple Hankel matrix rank minimization for audio inpainting
Mar 31, 2023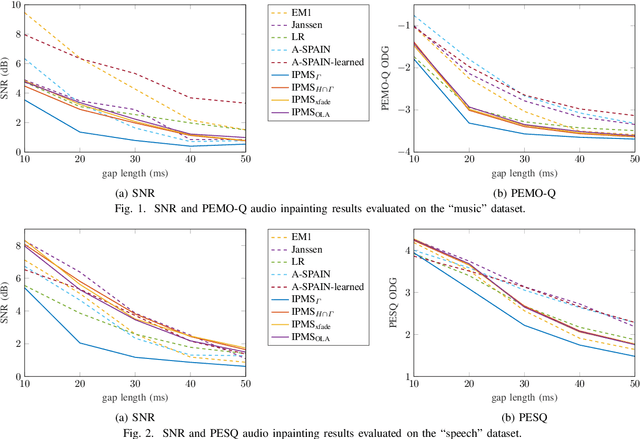

Sasaki et al. (2018) presented an efficient audio declipping algorithm, based on the properties of Hankel-structured matrices constructed from time-domain signal blocks. We adapt their approach to solve the audio inpainting problem, where samples are missing in the signal. We analyze the algorithm and provide modifications, some of them leading to an improved performance. Overall, it turns out that the new algorithms perform reasonably well for speech signals but they are not competitive in the case of music signals.
Probability of Resolution of MUSIC and g-MUSIC: An Asymptotic Approach
Jun 16, 2021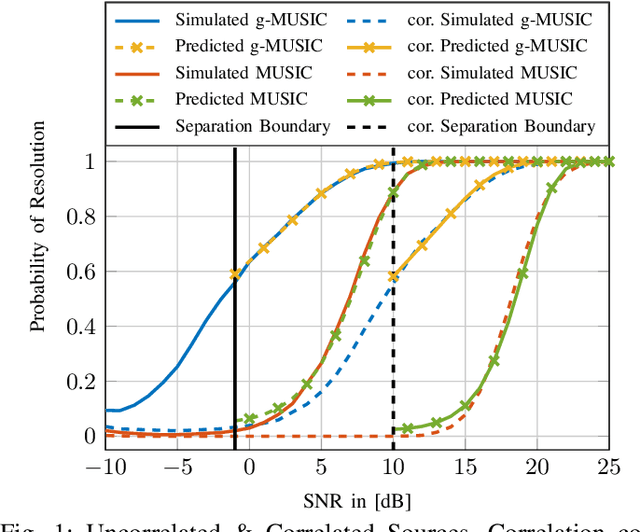
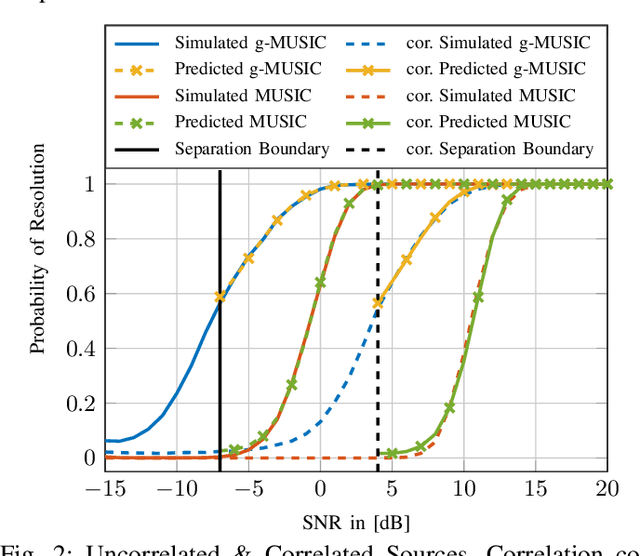
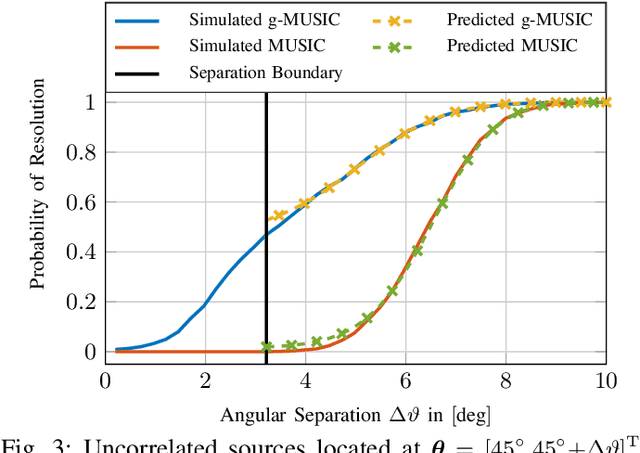
In this article, the outlier production mechanism of the conventional Multiple Signal Classification (MUSIC) and the g-MUSIC Direction-of-Arrival (DoA) estimation technique is investigated using tools from Random Matrix Theory (RMT). A general Central Limit Theorem (CLT) is derived that allows to analyze the asymptotic stochastic behavior of eigenvector-based cost functions in the asymptotic regime where the number of snapshots and the number of antennas increase without bound at the same rate. Furthermore, this CLT is used to provide an accurate prediction of the resolution capabilities of the MUSIC and the g-MUSIC DoA estimation method. The finite dimensional distribution of the MUSIC and the g-MUSIC cost function is shown to be asymptotically jointly Gaussian distributed in the asymptotic regime.
Low Complexity Iterative 2D DOA Estimation in MIMO Systems
Mar 15, 2023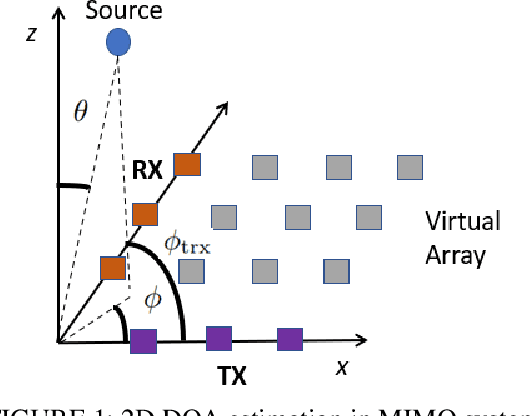
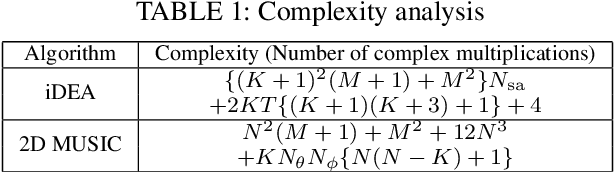
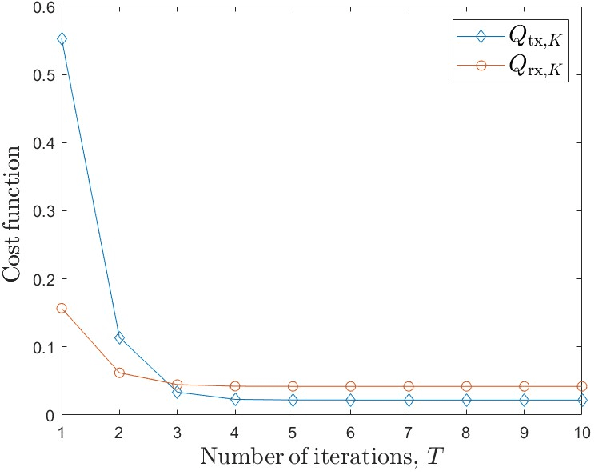
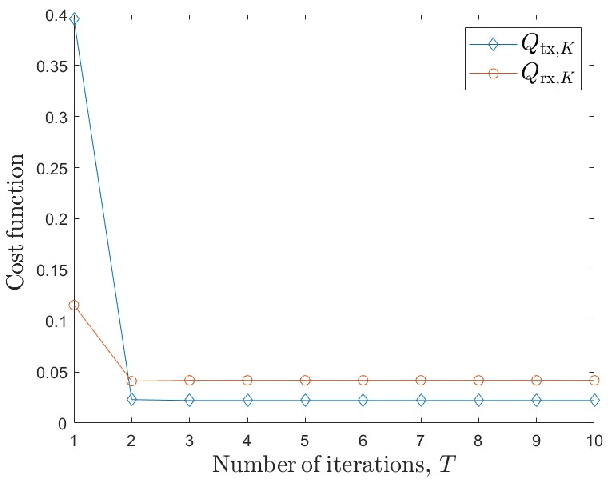
Multiple-input multiple-output (MIMO) systems play an essential role in direction-of-arrival (DOA) estimation. A large number of antennas used in a MIMO system imposes a huge complexity burden on the popular DOA estimation algorithms, such as MUSIC and ESPRIT due to the implementation of eigenvalue decomposition. This renders those algorithms impractical in applications requiring quick DOA estimation. Consequently, we theoretically derive several useful noise subspace vectors when the number of signal sources is less than the number of elements in both the transmitter and receiver sides. Those noise subspace vectors are then utilized to formulate a 2D-constrained minimization problem, solved iteratively to obtain the DOAs of all the sources in a scene. The convergence of the proposed iterative algorithm has been mathematically as well as numerically demonstrated. Depending on the number of iterations, our algorithm can provide significant complexity gain over the existing high-resolution 2D DOA estimation algorithms in MIMO systems, such as MUSIC, while exhibiting comparable performance for a moderate to high signal-to-noise ratio (SNR).
Quantum Computer Music: Foundations and Initial Experiments
Oct 24, 2021
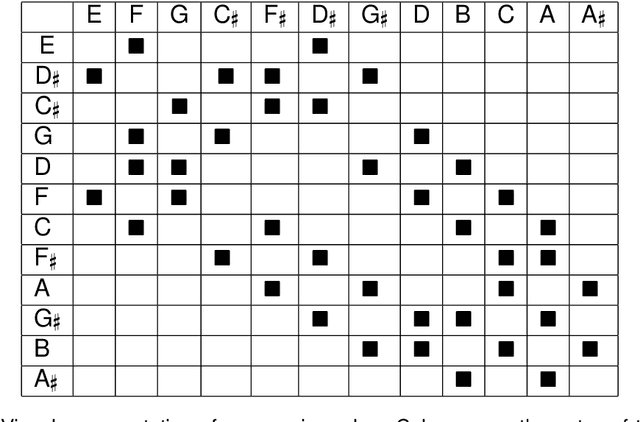

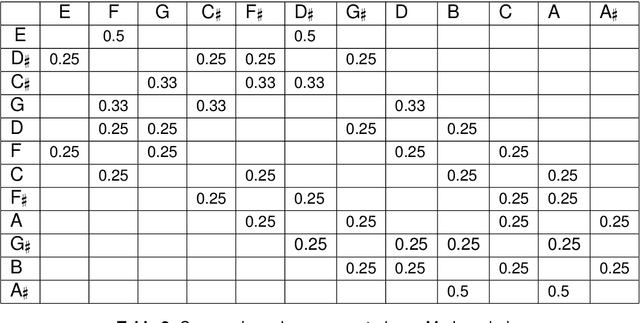
Quantum computing is a nascent technology, which is advancing rapidly. There is a long history of research into using computers for music. Nowadays computers are absolutely essential for the music economy. Thus, it is very likely that quantum computers will impact the music industry in time to come. This chapter lays the foundations of the new field of 'Quantum Computer Music'. It begins with an introduction to algorithmic computer music and methods to program computers to generate music, such as Markov chains and random walks. Then, it presents quantum computing versions of those methods. The discussions are supported by detailed explanations of quantum computing concepts and walk-through examples. A bespoke generative music algorithm is presented, the Basak-Miranda algorithm, which leverages a property of quantum mechanics known as constructive and destructive interference to operate a musical Markov chain. An Appendix introducing the fundamentals of quantum computing deemed necessary to understand the chapter and a link to access Jupyter Notebooks with examples are also provided.