 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild
Mar 25, 2024
We introduce VoiceCraft, a token infilling neural codec language model, that achieves state-of-the-art performance on both speech editing and zero-shot text-to-speech (TTS) on audiobooks, internet videos, and podcasts. VoiceCraft employs a Transformer decoder architecture and introduces a token rearrangement procedure that combines causal masking and delayed stacking to enable generation within an existing sequence. On speech editing tasks, VoiceCraft produces edited speech that is nearly indistinguishable from unedited recordings in terms of naturalness, as evaluated by humans; for zero-shot TTS, our model outperforms prior SotA models including VALLE and the popular commercial model XTTS-v2. Crucially, the models are evaluated on challenging and realistic datasets, that consist of diverse accents, speaking styles, recording conditions, and background noise and music, and our model performs consistently well compared to other models and real recordings. In particular, for speech editing evaluation, we introduce a high quality, challenging, and realistic dataset named RealEdit. We encourage readers to listen to the demos at https://jasonppy.github.io/VoiceCraft_web.
MusicRL: Aligning Music Generation to Human Preferences
Feb 06, 2024We propose MusicRL, the first music generation system finetuned from human feedback. Appreciation of text-to-music models is particularly subjective since the concept of musicality as well as the specific intention behind a caption are user-dependent (e.g. a caption such as "upbeat work-out music" can map to a retro guitar solo or a techno pop beat). Not only this makes supervised training of such models challenging, but it also calls for integrating continuous human feedback in their post-deployment finetuning. MusicRL is a pretrained autoregressive MusicLM (Agostinelli et al., 2023) model of discrete audio tokens finetuned with reinforcement learning to maximise sequence-level rewards. We design reward functions related specifically to text-adherence and audio quality with the help from selected raters, and use those to finetune MusicLM into MusicRL-R. We deploy MusicLM to users and collect a substantial dataset comprising 300,000 pairwise preferences. Using Reinforcement Learning from Human Feedback (RLHF), we train MusicRL-U, the first text-to-music model that incorporates human feedback at scale. Human evaluations show that both MusicRL-R and MusicRL-U are preferred to the baseline. Ultimately, MusicRL-RU combines the two approaches and results in the best model according to human raters. Ablation studies shed light on the musical attributes influencing human preferences, indicating that text adherence and quality only account for a part of it. This underscores the prevalence of subjectivity in musical appreciation and calls for further involvement of human listeners in the finetuning of music generation models.
Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives
Mar 15, 2024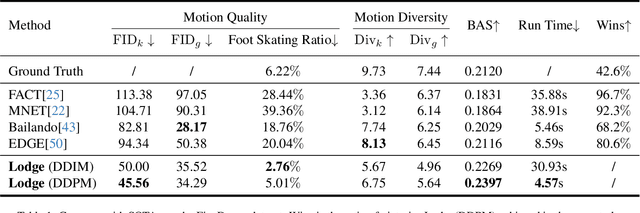
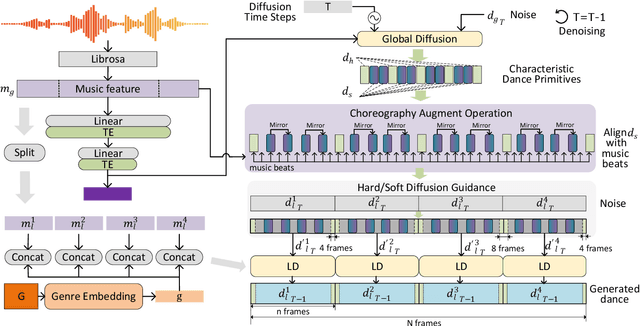
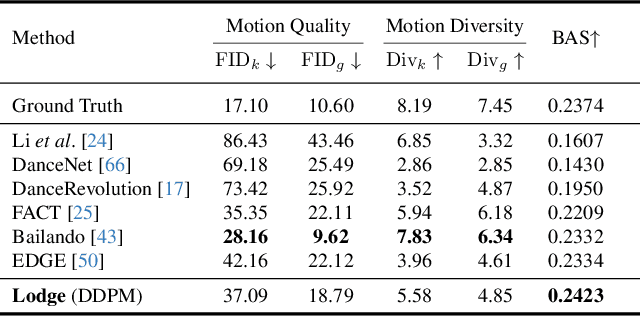
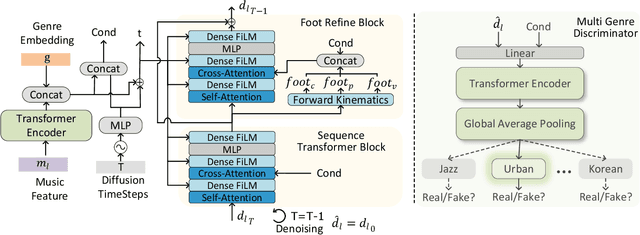
We propose Lodge, a network capable of generating extremely long dance sequences conditioned on given music. We design Lodge as a two-stage coarse to fine diffusion architecture, and propose the characteristic dance primitives that possess significant expressiveness as intermediate representations between two diffusion models. The first stage is global diffusion, which focuses on comprehending the coarse-level music-dance correlation and production characteristic dance primitives. In contrast, the second-stage is the local diffusion, which parallelly generates detailed motion sequences under the guidance of the dance primitives and choreographic rules. In addition, we propose a Foot Refine Block to optimize the contact between the feet and the ground, enhancing the physical realism of the motion. Our approach can parallelly generate dance sequences of extremely long length, striking a balance between global choreographic patterns and local motion quality and expressiveness. Extensive experiments validate the efficacy of our method.
Maximum Likelihood Alternating Summation for Multistatic Angle-based Multitarget Localization
Mar 20, 2024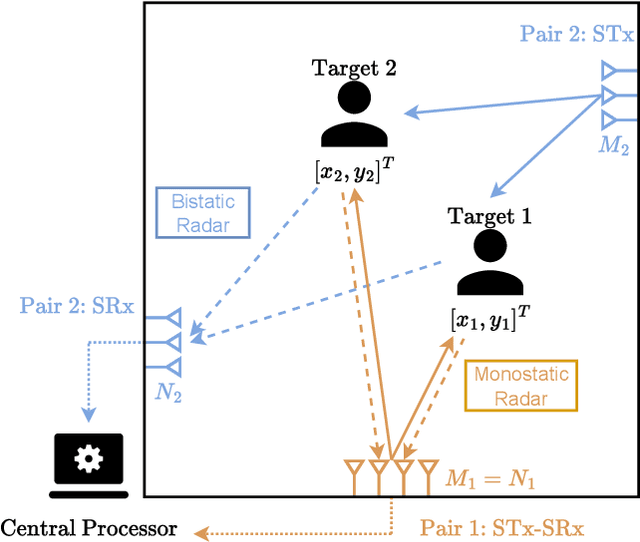
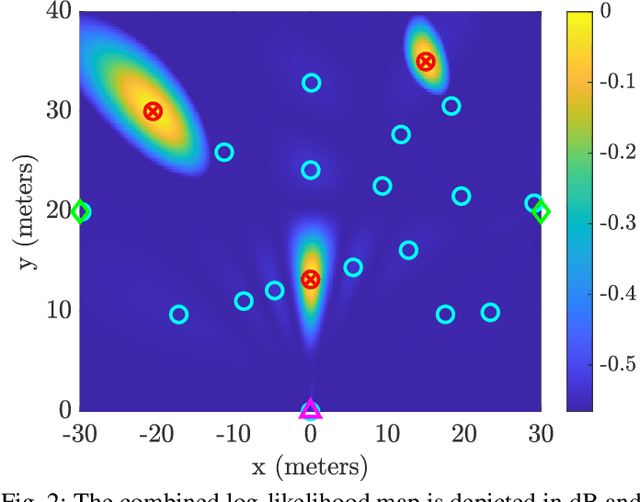
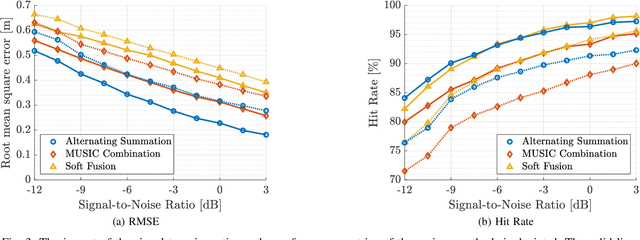
Recent advancements in Wi-Fi sensing have sparked interest in exploiting OFDM modulated communication signals for target detection and tracking. In this study, we address the angle-based localization of multiple targets using a multistatic OFDM radar. While the maximum likelihood approach optimally merges data from each radar pair comprised by the system, it entails a complex multi-dimensional search process. Leveraging pre-estimation of the targets' parameters obtained via the MUSIC algorithm, our method decouples this multi-dimensional search into a single two-dimensional estimator per target. The proposed alternating summation method allows the computation of a combined likelihood map aggregating contributions from each radar pair, enabling target detection via peak selection. Besides reducing computational complexity, the method effectively captures target interactions and accommodates varying radar pair localization abilities. Also, it requires transmitting only the estimated channel covariance matrices of each radar pair to the central processor. Numerical simulations demonstrate superior performance over existing approaches.
Generalized Multi-Source Inference for Text Conditioned Music Diffusion Models
Mar 18, 2024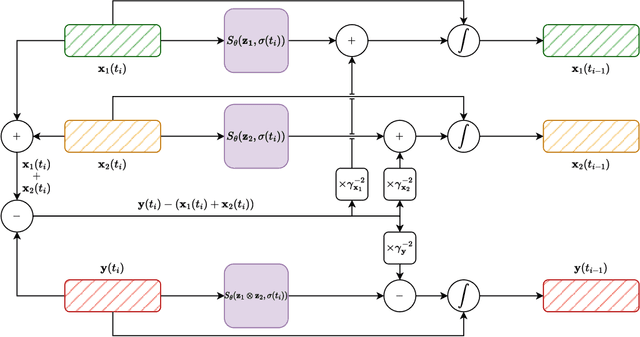
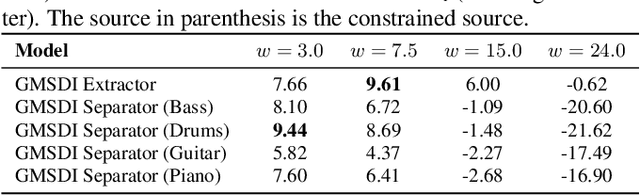
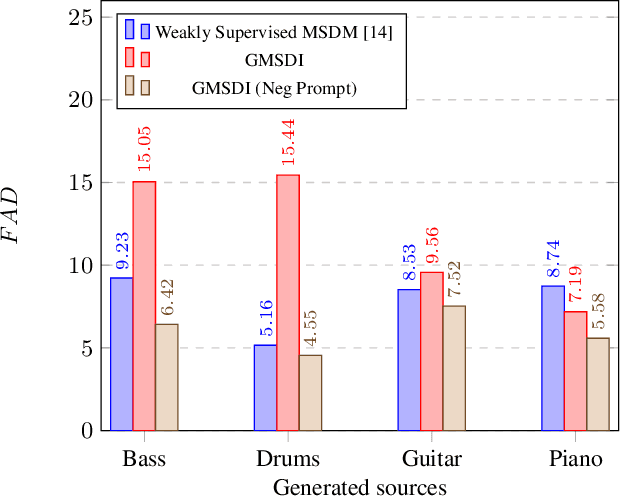
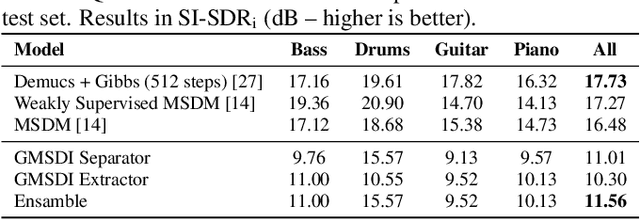
Multi-Source Diffusion Models (MSDM) allow for compositional musical generation tasks: generating a set of coherent sources, creating accompaniments, and performing source separation. Despite their versatility, they require estimating the joint distribution over the sources, necessitating pre-separated musical data, which is rarely available, and fixing the number and type of sources at training time. This paper generalizes MSDM to arbitrary time-domain diffusion models conditioned on text embeddings. These models do not require separated data as they are trained on mixtures, can parameterize an arbitrary number of sources, and allow for rich semantic control. We propose an inference procedure enabling the coherent generation of sources and accompaniments. Additionally, we adapt the Dirac separator of MSDM to perform source separation. We experiment with diffusion models trained on Slakh2100 and MTG-Jamendo, showcasing competitive generation and separation results in a relaxed data setting.
Leveraging Pre-Trained Autoencoders for Interpretable Prototype Learning of Music Audio
Feb 14, 2024We present PECMAE, an interpretable model for music audio classification based on prototype learning. Our model is based on a previous method, APNet, which jointly learns an autoencoder and a prototypical network. Instead, we propose to decouple both training processes. This enables us to leverage existing self-supervised autoencoders pre-trained on much larger data (EnCodecMAE), providing representations with better generalization. APNet allows prototypes' reconstruction to waveforms for interpretability relying on the nearest training data samples. In contrast, we explore using a diffusion decoder that allows reconstruction without such dependency. We evaluate our method on datasets for music instrument classification (Medley-Solos-DB) and genre recognition (GTZAN and a larger in-house dataset), the latter being a more challenging task not addressed with prototypical networks before. We find that the prototype-based models preserve most of the performance achieved with the autoencoder embeddings, while the sonification of prototypes benefits understanding the behavior of the classifier.
ByteComposer: a Human-like Melody Composition Method based on Language Model Agent
Mar 07, 2024Large Language Models (LLM) have shown encouraging progress in multimodal understanding and generation tasks. However, how to design a human-aligned and interpretable melody composition system is still under-explored. To solve this problem, we propose ByteComposer, an agent framework emulating a human's creative pipeline in four separate steps : "Conception Analysis - Draft Composition - Self-Evaluation and Modification - Aesthetic Selection". This framework seamlessly blends the interactive and knowledge-understanding features of LLMs with existing symbolic music generation models, thereby achieving a melody composition agent comparable to human creators. We conduct extensive experiments on GPT4 and several open-source large language models, which substantiate our framework's effectiveness. Furthermore, professional music composers were engaged in multi-dimensional evaluations, the final results demonstrated that across various facets of music composition, ByteComposer agent attains the level of a novice melody composer.
Large-Scale Label Interpretation Learning for Few-Shot Named Entity Recognition
Mar 21, 2024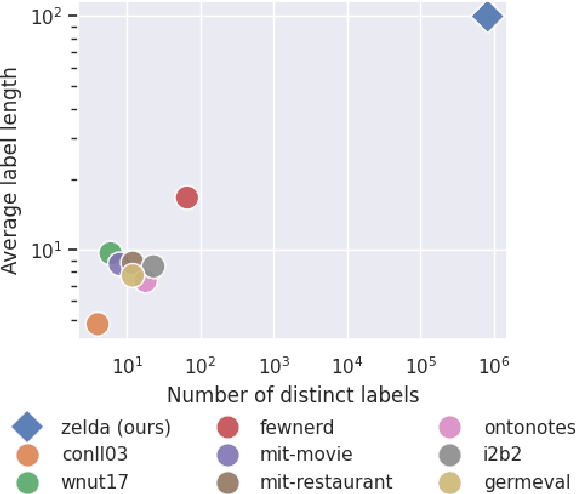
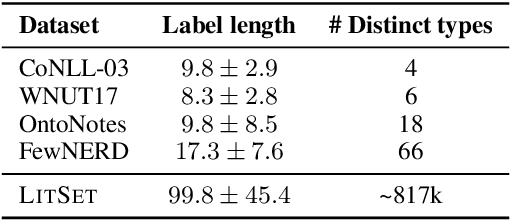
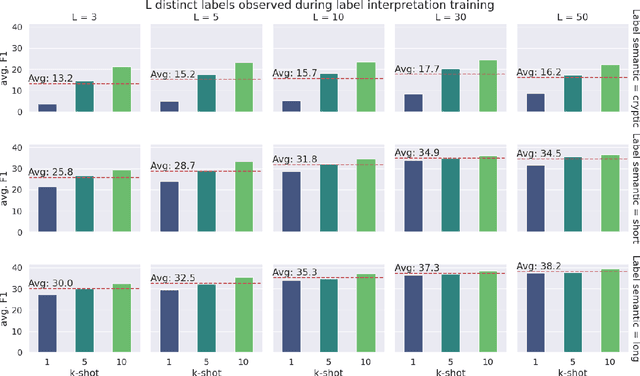
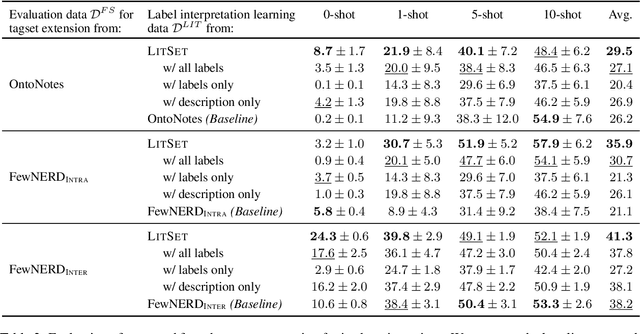
Few-shot named entity recognition (NER) detects named entities within text using only a few annotated examples. One promising line of research is to leverage natural language descriptions of each entity type: the common label PER might, for example, be verbalized as ''person entity.'' In an initial label interpretation learning phase, the model learns to interpret such verbalized descriptions of entity types. In a subsequent few-shot tagset extension phase, this model is then given a description of a previously unseen entity type (such as ''music album'') and optionally a few training examples to perform few-shot NER for this type. In this paper, we systematically explore the impact of a strong semantic prior to interpret verbalizations of new entity types by massively scaling up the number and granularity of entity types used for label interpretation learning. To this end, we leverage an entity linking benchmark to create a dataset with orders of magnitude of more distinct entity types and descriptions as currently used datasets. We find that this increased signal yields strong results in zero- and few-shot NER in in-domain, cross-domain, and even cross-lingual settings. Our findings indicate significant potential for improving few-shot NER through heuristical data-based optimization.
Capturing Cancer as Music: Cancer Mechanisms Expressed through Musification
Feb 09, 2024The development of cancer is difficult to express on a simple and intuitive level due to its complexity. Since cancer is so widespread, raising public awareness about its mechanisms can help those affected cope with its realities, as well as inspire others to make lifestyle adjustments and screen for the disease. Unfortunately, studies have shown that cancer literature is too technical for the general public to understand. We found that musification, the process of turning data into music, remains an unexplored avenue for conveying this information. We explore the pedagogical effectiveness of musification through the use of an algorithm that manipulates a piece of music in a manner analogous to the development of cancer. We conducted two lab studies and found that our approach is marginally more effective at promoting cancer literacy when accompanied by a text-based article than text-based articles alone.
Harmonious Group Choreography with Trajectory-Controllable Diffusion
Mar 10, 2024
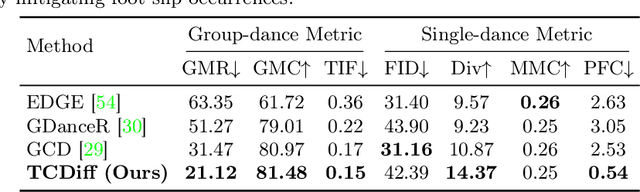
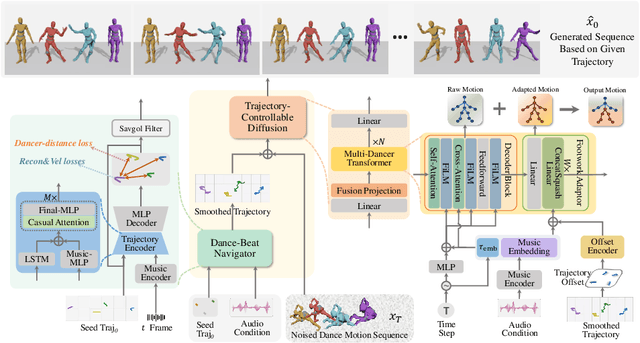
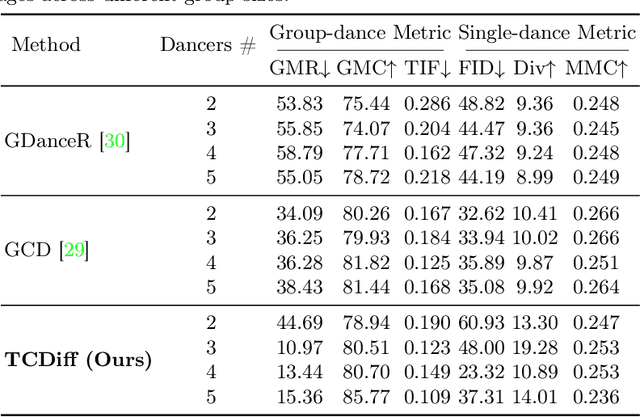
Creating group choreography from music has gained attention in cultural entertainment and virtual reality, aiming to coordinate visually cohesive and diverse group movements. Despite increasing interest, recent works face challenges in achieving aesthetically appealing choreography, primarily for two key issues: multi-dancer collision and single-dancer foot slide. To address these issues, we propose a Trajectory-Controllable Diffusion (TCDiff), a novel approach that harnesses non-overlapping trajectories to facilitate coherent dance movements. Specifically, to tackle dancer collisions, we introduce a Dance-Beat Navigator capable of generating trajectories for multiple dancers based on the music, complemented by a Distance-Consistency loss to maintain appropriate spacing among trajectories within a reasonable threshold. To mitigate foot sliding, we present a Footwork Adaptor that utilizes trajectory displacement from adjacent frames to enable flexible footwork, coupled with a Relative Forward-Kinematic loss to adjust the positioning of individual dancers' root nodes and joints. Extensive experiments demonstrate that our method achieves state-of-the-art results.