 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Convolutive Block-Matching Segmentation Algorithm with Application to Music Structure Analysis
Oct 27, 2022
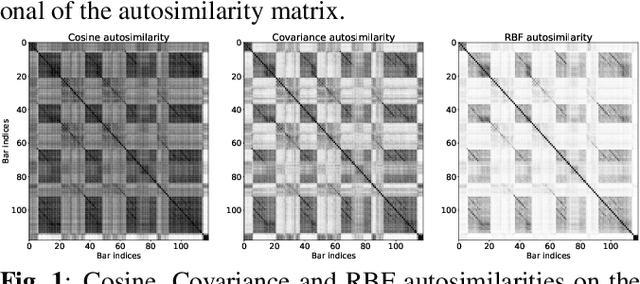
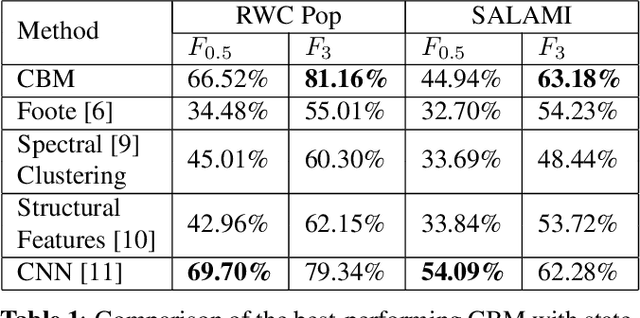
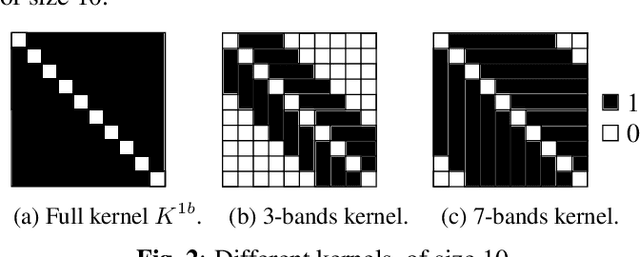
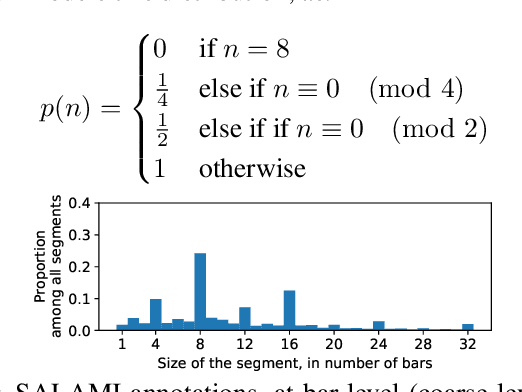
Music Structure Analysis (MSA) consists of representing a song in sections (such as ``chorus'', ``verse'', ``solo'' etc), and can be seen as the retrieval of a simplified organization of the song. This work presents a new algorithm, called Convolutive Block-Matching (CBM) algorithm, devoted to MSA. In particular, the CBM algorithm is a dynamic programming algorithm, applying on autosimilarity matrices, a standard tool in MSA. In this work, autosimilarity matrices are computed from the feature representation of an audio signal, and time is sampled on the barscale. We study three different similarity functions for the computation of autosimilarity matrices. We report that the proposed algorithm achieves a level of performance competitive to that of supervised state-of-the-art methods on 3 among 4 metrics, while being fully unsupervised.
Learning Interpretable Low-dimensional Representation via Physical Symmetry
Feb 24, 2023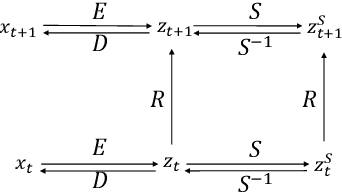
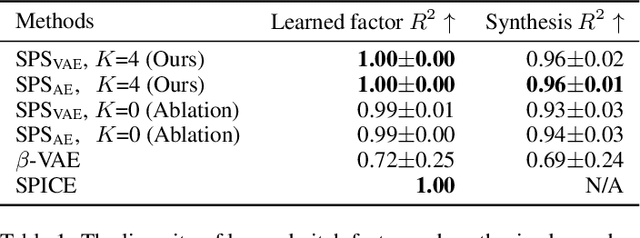
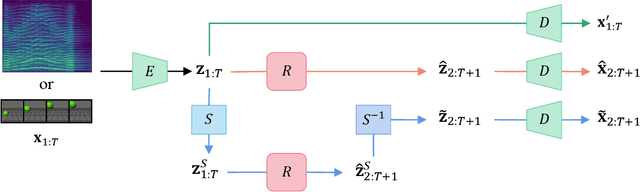
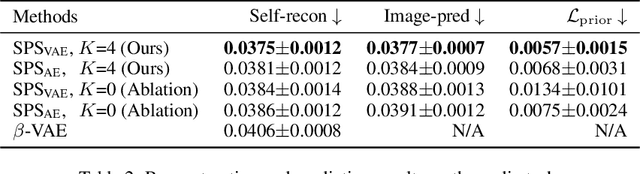
Interpretable representation learning has been playing a key role in creative intelligent systems. In the music domain, current learning algorithms can successfully learn various features such as pitch, timbre, chord, texture, etc. However, most methods rely heavily on music domain knowledge. It remains an open question what general computational principles give rise to interpretable representations, especially low-dim factors that agree with human perception. In this study, we take inspiration from modern physics and use physical symmetry as a self-consistency constraint for the latent space. Specifically, it requires the prior model that characterises the dynamics of the latent states to be equivariant with respect to certain group transformations. We show that physical symmetry leads the model to learn a linear pitch factor from unlabelled monophonic music audio in a self-supervised fashion. In addition, the same methodology can be applied to computer vision, learning a 3D Cartesian space from videos of a simple moving object without labels. Furthermore, physical symmetry naturally leads to representation augmentation, a new technique which improves sample efficiency.
The Musical Arrow of Time -- The Role of Temporal Asymmetry in Music and Its Organicist Implications
Jun 02, 2022


Adopting a performer-centric perspective, we frequently encounter two statements: "music flows", and "music is life-like". This dissertation builds on top of the two statements above, resulting in an exploration of the role of temporal asymmetry in music (generalizing "music flows") and its relation to the idea of organicism (generalizing "music is life-like"). We focus on two aspects of temporal asymmetry. The first aspect concerns the vastly different epistemic mechanisms with which we obtain knowledge of the past and the future. A particular musical consequence follows: recurrence. The epistemic difference between the past and the future shapes our experience and interpretation of recurring events in music. The second aspect concerns the arrow of time: the unambiguous ordering imposed on temporal events gives rise to the a priori pointedness of time, rendering time asymmetrical and irreversible. A discussion on thermodynamics informs us musically: the arrow of time effectuates itself in musical forms by delaying the placement of the climax. Organicism serves as a mediating topic, engaging with the concept of life as in organisms. On the one hand, organicism is related to temporal asymmetry in science via a thermodynamical interpretation of life as entropy-reducing entities. On the other hand, organicism is a topic native to music via the universally acknowledged artistic idea that music should be interpreted as a vital force possessing volitional power. With organicism as a mediator, we better understand the role of temporal asymmetry in music. In particular, we view musical form as a process of expansion and elaboration analogous to organic growth. Finally, we present an organicist interpretation of delaying the climax: viewing musical form as the result of organic growth, the arrow of time translates to a preference for prepending structure over appending structure.
Is ChatGPT Fair for Recommendation? Evaluating Fairness in Large Language Model Recommendation
May 12, 2023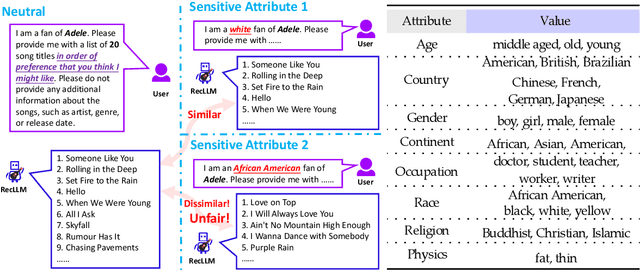
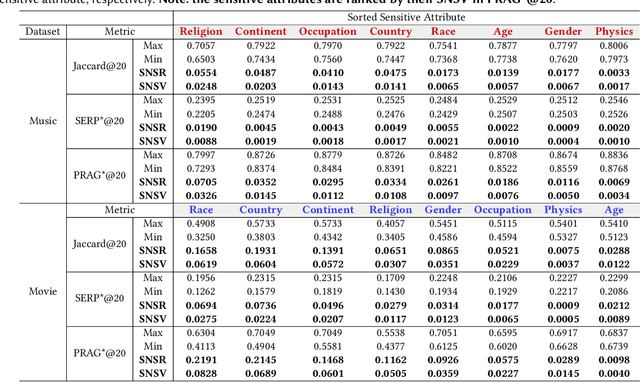
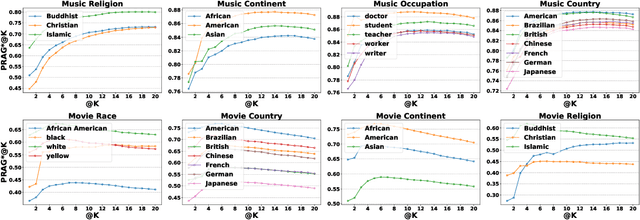

The remarkable achievements of Large Language Models (LLMs) have led to the emergence of a novel recommendation paradigm -- Recommendation via LLM (RecLLM). Nevertheless, it is important to note that LLMs may contain social prejudices, and therefore, the fairness of recommendations made by RecLLM requires further investigation. To avoid the potential risks of RecLLM, it is imperative to evaluate the fairness of RecLLM with respect to various sensitive attributes on the user side. Due to the differences between the RecLLM paradigm and the traditional recommendation paradigm, it is problematic to directly use the fairness benchmark of traditional recommendation. To address the dilemma, we propose a novel benchmark called Fairness of Recommendation via LLM (FaiRLLM). This benchmark comprises carefully crafted metrics and a dataset that accounts for eight sensitive attributes1 in two recommendation scenarios: music and movies. By utilizing our FaiRLLM benchmark, we conducted an evaluation of ChatGPT and discovered that it still exhibits unfairness to some sensitive attributes when generating recommendations. Our code and dataset can be found at https://github.com/jizhi-zhang/FaiRLLM.
Unsupervised Melody-Guided Lyrics Generation
May 12, 2023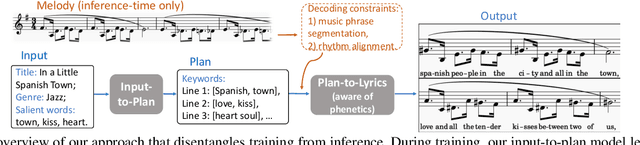

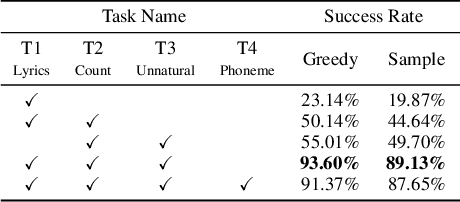
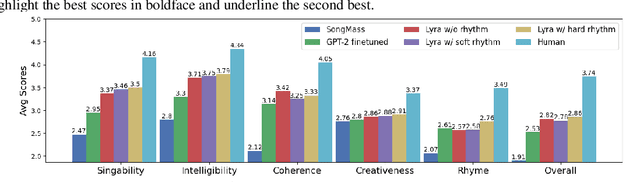
Automatic song writing is a topic of significant practical interest. However, its research is largely hindered by the lack of training data due to copyright concerns and challenged by its creative nature. Most noticeably, prior works often fall short of modeling the cross-modal correlation between melody and lyrics due to limited parallel data, hence generating lyrics that are less singable. Existing works also lack effective mechanisms for content control, a much desired feature for democratizing song creation for people with limited music background. In this work, we propose to generate pleasantly listenable lyrics without training on melody-lyric aligned data. Instead, we design a hierarchical lyric generation framework that disentangles training (based purely on text) from inference (melody-guided text generation). At inference time, we leverage the crucial alignments between melody and lyrics and compile the given melody into constraints to guide the generation process. Evaluation results show that our model can generate high-quality lyrics that are more singable, intelligible, coherent, and in rhyme than strong baselines including those supervised on parallel data.
Robust Dancer: Long-term 3D Dance Synthesis Using Unpaired Data
Mar 29, 2023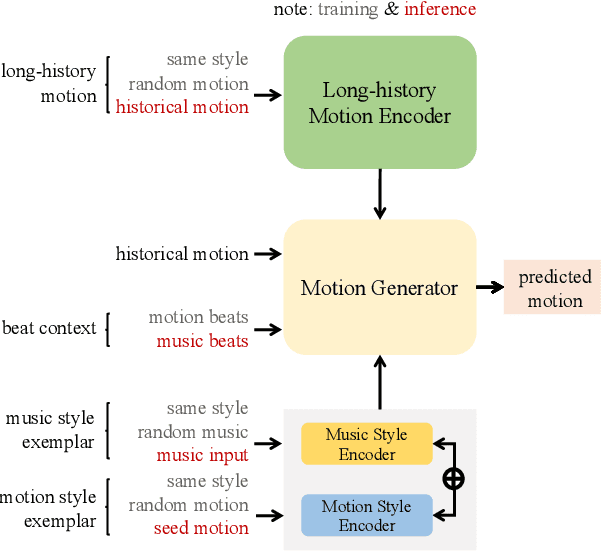
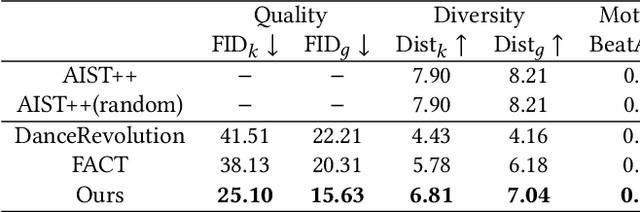
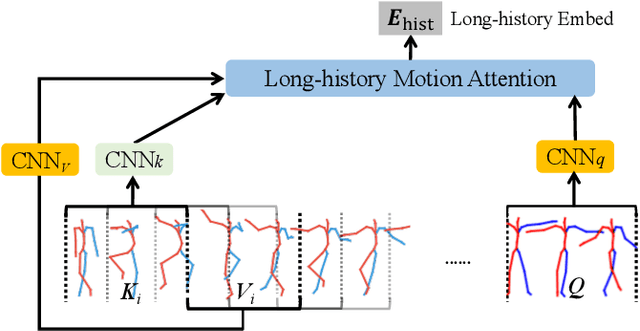
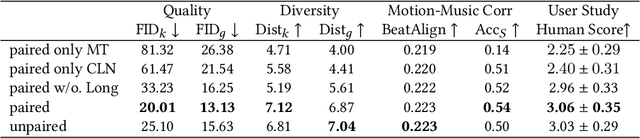
How to automatically synthesize natural-looking dance movements based on a piece of music is an incrementally popular yet challenging task. Most existing data-driven approaches require hard-to-get paired training data and fail to generate long sequences of motion due to error accumulation of autoregressive structure. We present a novel 3D dance synthesis system that only needs unpaired data for training and could generate realistic long-term motions at the same time. For the unpaired data training, we explore the disentanglement of beat and style, and propose a Transformer-based model free of reliance upon paired data. For the synthesis of long-term motions, we devise a new long-history attention strategy. It first queries the long-history embedding through an attention computation and then explicitly fuses this embedding into the generation pipeline via multimodal adaptation gate (MAG). Objective and subjective evaluations show that our results are comparable to strong baseline methods, despite not requiring paired training data, and are robust when inferring long-term music. To our best knowledge, we are the first to achieve unpaired data training - an ability that enables to alleviate data limitations effectively. Our code is released on https://github.com/BFeng14/RobustDancer
Iranian Modal Music (Dastgah) detection using deep neural networks
Mar 29, 2022
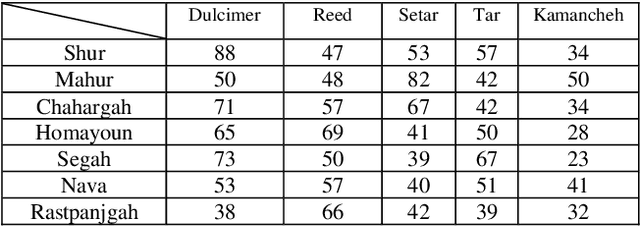

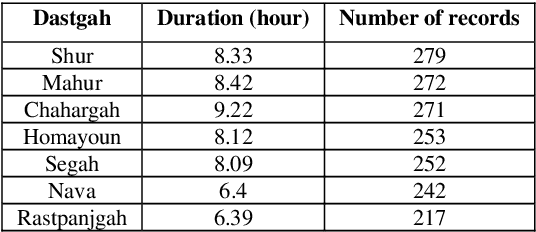
In this work, several deep neural networks are implemented to recognize Iranian modal music in seven high correlated categories. The best model, which achieved 92 percent overall accuracy, uses an architecture inspired by autoencoder, including BiLSTM and BiGRU layers. This model is trained using the Nava dataset, with 1786 records and up to 55 hours of music played solo by Kamanche, Tar, Setar, Reed, and Santoor (Dulcimer). Features that have been studied through this research contain MFCC, Chroma CENS, and Mel spectrogram. The results indicate that MFCC carries more valuable information for detecting Iranian modal music (Dastgah) than other sound representations. Moreover, the architecture, which is inspired by autoencoder, is robust in distinguishing high correlated data like Dastgahs. It also shows that because of the precise order in Iranian Dastgah Music, Bidirectional Recurrent networks are more efficient than any other networks that have been implemented in this study.
How good are variational autoencoders at transfer learning?
Apr 21, 2023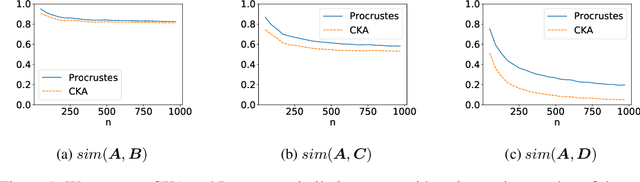

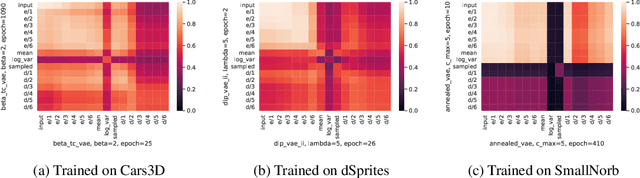

Variational autoencoders (VAEs) are used for transfer learning across various research domains such as music generation or medical image analysis. However, there is no principled way to assess before transfer which components to retrain or whether transfer learning is likely to help on a target task. We propose to explore this question through the lens of representational similarity. Specifically, using Centred Kernel Alignment (CKA) to evaluate the similarity of VAEs trained on different datasets, we show that encoders' representations are generic but decoders' specific. Based on these insights, we discuss the implications for selecting which components of a VAE to retrain and propose a method to visually assess whether transfer learning is likely to help on classification tasks.
From Audio to Symbolic Encoding
Feb 26, 2023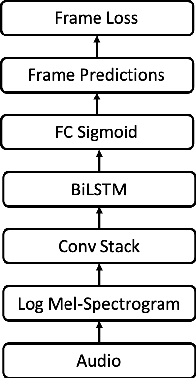
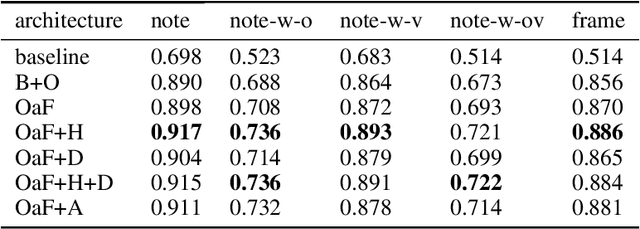
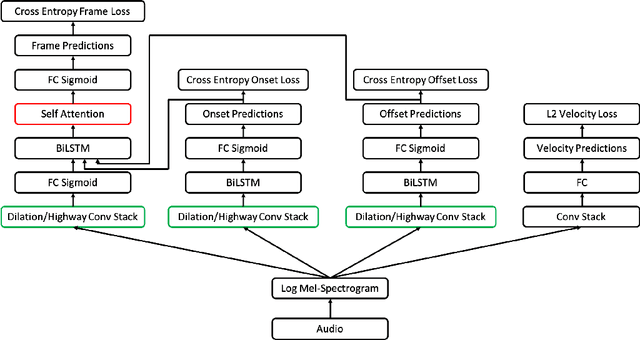
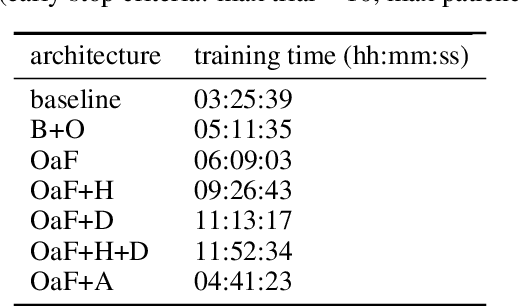
Automatic music transcription (AMT) aims to convert raw audio to symbolic music representation. As a fundamental problem of music information retrieval (MIR), AMT is considered a difficult task even for trained human experts due to overlap of multiple harmonics in the acoustic signal. On the other hand, speech recognition, as one of the most popular tasks in natural language processing, aims to translate human spoken language to texts. Based on the similar nature of AMT and speech recognition (as they both deal with tasks of translating audio signal to symbolic encoding), this paper investigated whether a generic neural network architecture could possibly work on both tasks. In this paper, we introduced our new neural network architecture built on top of the current state-of-the-art Onsets and Frames, and compared the performances of its multiple variations on AMT task. We also tested our architecture with the task of speech recognition. For AMT, our models were able to produce better results compared to the model trained using the state-of-art architecture; however, although similar architecture was able to be trained on the speech recognition task, it did not generate very ideal result compared to other task-specific models.
Improving Recommendation Systems with User Personality Inferred from Product Reviews
Mar 09, 2023


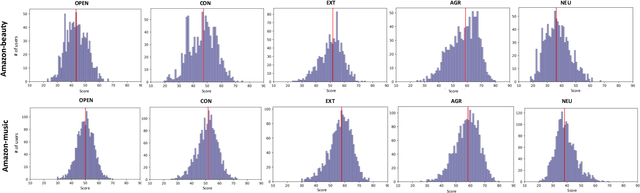
Personality is a psychological factor that reflects people's preferences, which in turn influences their decision-making. We hypothesize that accurate modeling of users' personalities improves recommendation systems' performance. However, acquiring such personality profiles is both sensitive and expensive. We address this problem by introducing a novel method to automatically extract personality profiles from public product review text. We then design and assess three context-aware recommendation architectures that leverage the profiles to test our hypothesis. Experiments on our two newly contributed personality datasets -- Amazon-beauty and Amazon-music -- validate our hypothesis, showing performance boosts of 3--28%.Our analysis uncovers that varying personality types contribute differently to recommendation performance: open and extroverted personalities are most helpful in music recommendation, while a conscientious personality is most helpful in beauty product recommendation. The dataset is available at https://github.com/XinyuanLu00/IRS-WSDM2023-personality-dataset.