 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Improving Recommendation Systems with User Personality Inferred from Product Reviews
Mar 21, 2023



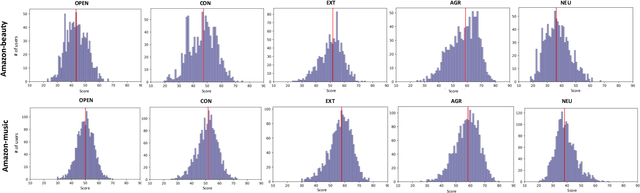
Personality is a psychological factor that reflects people's preferences, which in turn influences their decision-making. We hypothesize that accurate modeling of users' personalities improves recommendation systems' performance. However, acquiring such personality profiles is both sensitive and expensive. We address this problem by introducing a novel method to automatically extract personality profiles from public product review text. We then design and assess three context-aware recommendation architectures that leverage the profiles to test our hypothesis. Experiments on our two newly contributed personality datasets -- Amazon-beauty and Amazon-music -- validate our hypothesis, showing performance boosts of 3--28%.Our analysis uncovers that varying personality types contribute differently to recommendation performance: open and extroverted personalities are most helpful in music recommendation, while a conscientious personality is most helpful in beauty product recommendation.
Target-Aware Spatio-Temporal Reasoning via Answering Questions in Dynamics Audio-Visual Scenarios
May 21, 2023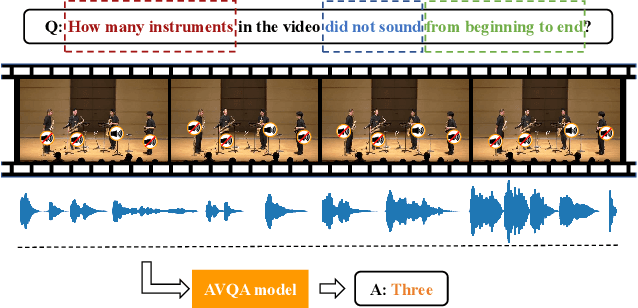

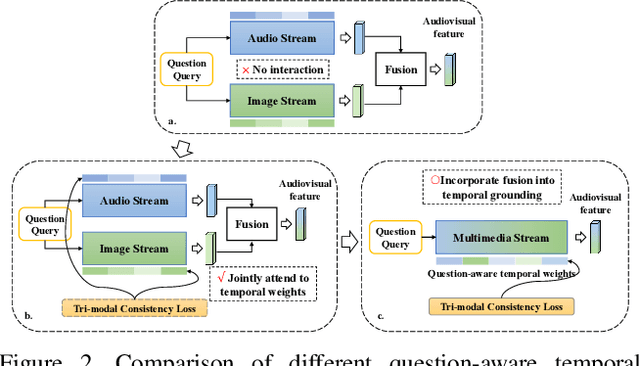

Audio-visual question answering (AVQA) is a challenging task that requires multistep spatio-temporal reasoning over multimodal contexts. To achieve scene understanding ability similar to humans, the AVQA task presents specific challenges, including effectively fusing audio and visual information and capturing question-relevant audio-visual features while maintaining temporal synchronization. This paper proposes a Target-aware Joint Spatio-Temporal Grounding Network for AVQA to address these challenges. The proposed approach has two main components: the Target-aware Spatial Grounding module, the Tri-modal consistency loss and corresponding Joint audio-visual temporal grounding module. The Target-aware module enables the model to focus on audio-visual cues relevant to the inquiry subject by exploiting the explicit semantics of text modality. The Tri-modal consistency loss facilitates the interaction between audio and video during question-aware temporal grounding and incorporates fusion within a simpler single-stream architecture. Experimental results on the MUSIC-AVQA dataset demonstrate the effectiveness and superiority of the proposed method over existing state-of-the-art methods. Our code will be availiable soon.
Ripple Knowledge Graph Convolutional Networks For Recommendation Systems
May 02, 2023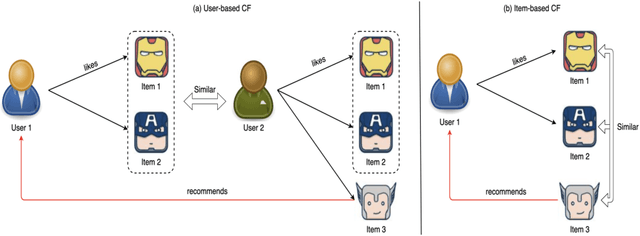

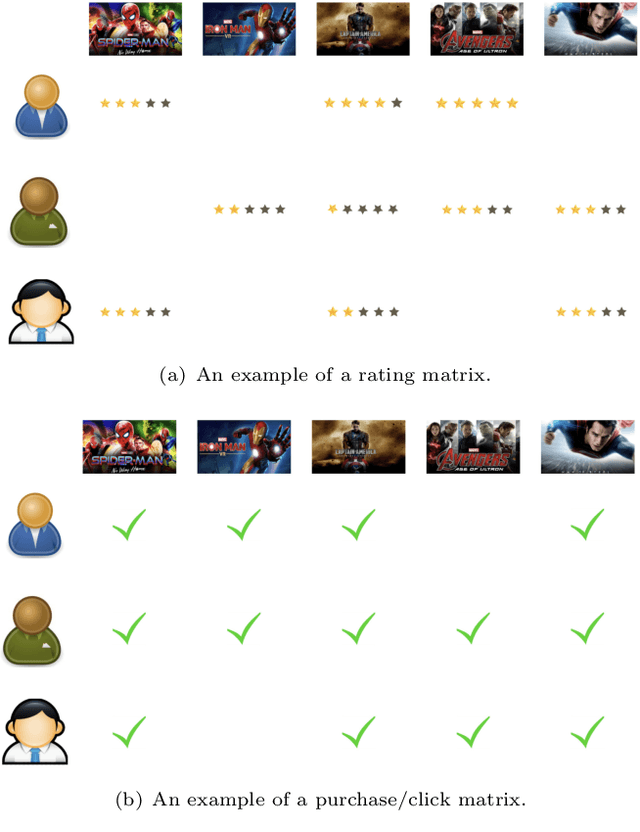
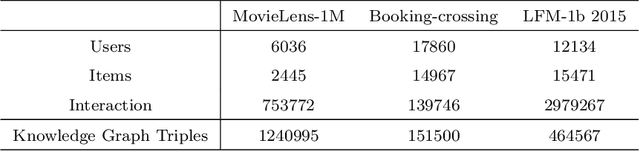
Using knowledge graphs to assist deep learning models in making recommendation decisions has recently been proven to effectively improve the model's interpretability and accuracy. This paper introduces an end-to-end deep learning model, named RKGCN, which dynamically analyses each user's preferences and makes a recommendation of suitable items. It combines knowledge graphs on both the item side and user side to enrich their representations to maximize the utilization of the abundant information in knowledge graphs. RKGCN is able to offer more personalized and relevant recommendations in three different scenarios. The experimental results show the superior effectiveness of our model over 5 baseline models on three real-world datasets including movies, books, and music.
Evaluating Deep Music Generation Methods Using Data Augmentation
Dec 31, 2021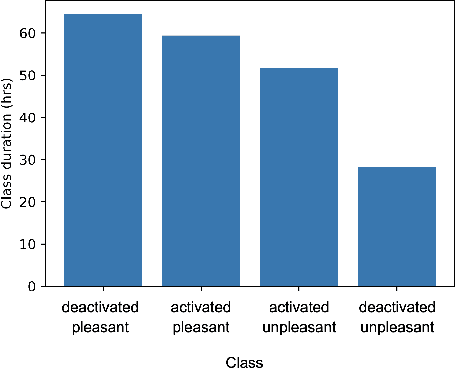
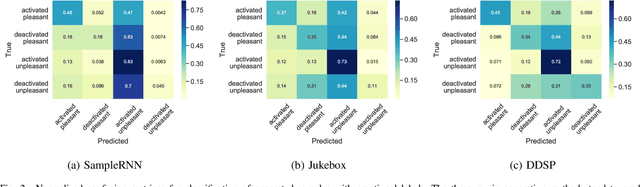
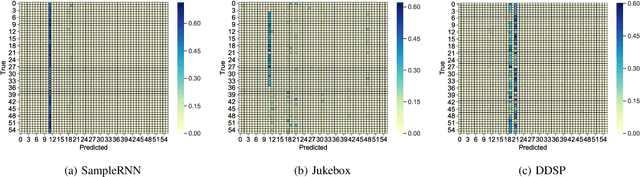
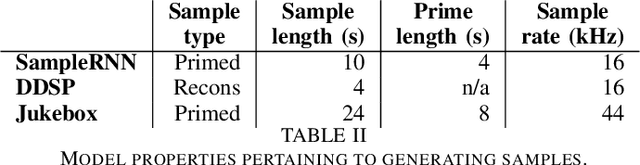
Despite advances in deep algorithmic music generation, evaluation of generated samples often relies on human evaluation, which is subjective and costly. We focus on designing a homogeneous, objective framework for evaluating samples of algorithmically generated music. Any engineered measures to evaluate generated music typically attempt to define the samples' musicality, but do not capture qualities of music such as theme or mood. We do not seek to assess the musical merit of generated music, but instead explore whether generated samples contain meaningful information pertaining to emotion or mood/theme. We achieve this by measuring the change in predictive performance of a music mood/theme classifier after augmenting its training data with generated samples. We analyse music samples generated by three models -- SampleRNN, Jukebox, and DDSP -- and employ a homogeneous framework across all methods to allow for objective comparison. This is the first attempt at augmenting a music genre classification dataset with conditionally generated music. We investigate the classification performance improvement using deep music generation and the ability of the generators to make emotional music by using an additional, emotion annotation of the dataset. Finally, we use a classifier trained on real data to evaluate the label validity of class-conditionally generated samples.
Emergency Response Person Localization and Vital Sign Estimation Using a Semi-Autonomous Robot Mounted SFCW Radar
May 25, 2023
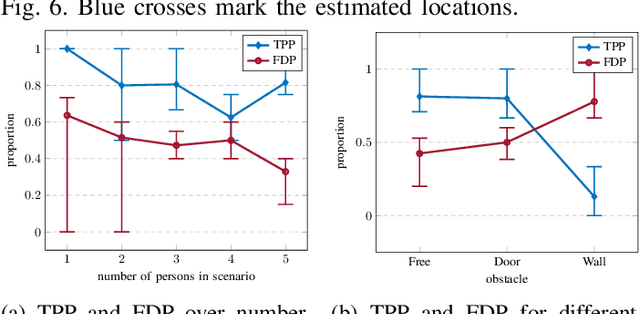
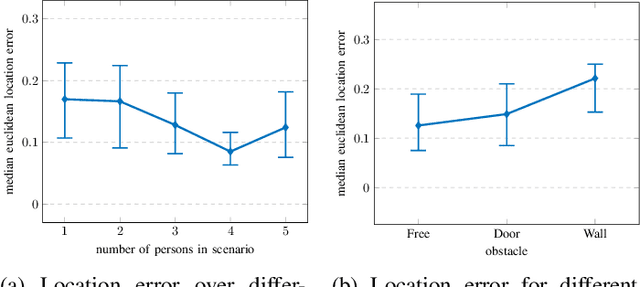
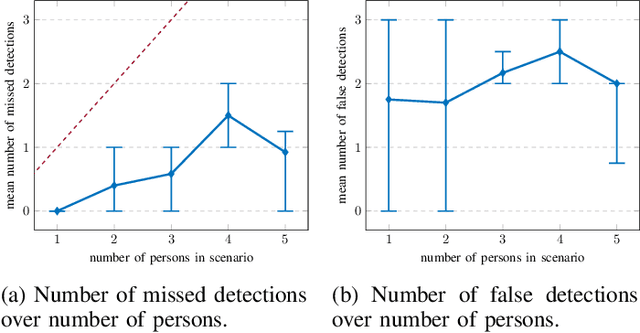
The large number and scale of natural and man-made disasters have led to an urgent demand for technologies that enhance the safety and efficiency of search and rescue teams. Semi-autonomous rescue robots are beneficial, especially when searching inaccessible terrains, or dangerous environments, such as collapsed infrastructures. For search and rescue missions in degraded visual conditions or non-line of sight scenarios, radar-based approaches may contribute to acquire valuable, and otherwise unavailable information. This article presents a complete signal processing chain for radar-based multi-person detection, 2D-MUSIC localization and breathing frequency estimation. The proposed method shows promising results on a challenging emergency response dataset that we collected using a semi-autonomous robot equipped with a commercially available through-wall radar system. The dataset is composed of 62 scenarios of various difficulty levels with up to five persons captured in different postures, angles and ranges including wooden and stone obstacles that block the radar line of sight. Ground truth data for reference locations, respiration, electrocardiogram, and acceleration signals are included. The full emergency response benchmark data set as well as all codes to reproduce our results, are publicly available at https://doi.org/10.21227/4bzd-jm32.
Scream Detection in Heavy Metal Music
May 11, 2022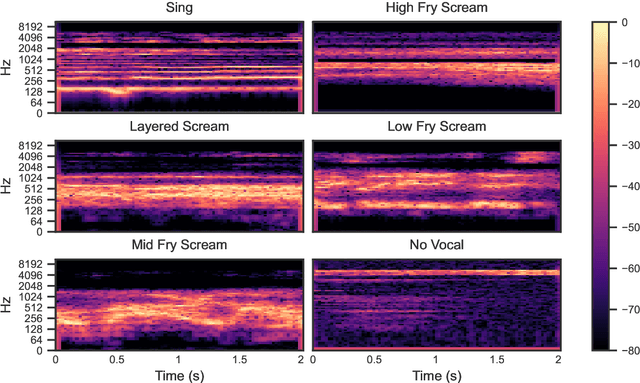
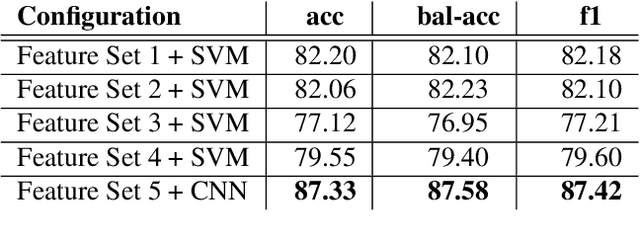
Harsh vocal effects such as screams or growls are far more common in heavy metal vocals than the traditionally sung vocal. This paper explores the problem of detection and classification of extreme vocal techniques in heavy metal music, specifically the identification of different scream techniques. We investigate the suitability of various feature representations, including cepstral, spectral, and temporal features as input representations for classification. The main contributions of this work are (i) a manually annotated dataset comprised of over 280 minutes of heavy metal songs of various genres with a statistical analysis of occurrences of different extreme vocal techniques in heavy metal music, and (ii) a systematic study of different input feature representations for the classification of heavy metal vocals
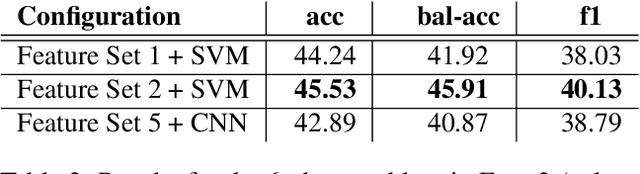
Genre-conditioned Acoustic Models for Automatic Lyrics Transcription of Polyphonic Music
Apr 07, 2022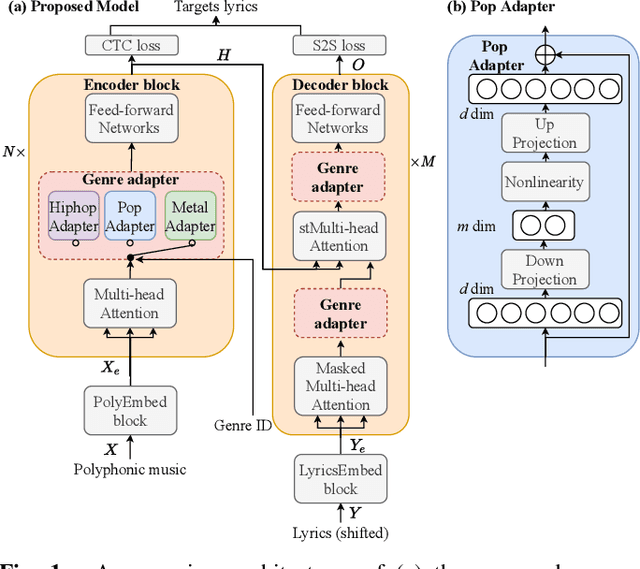
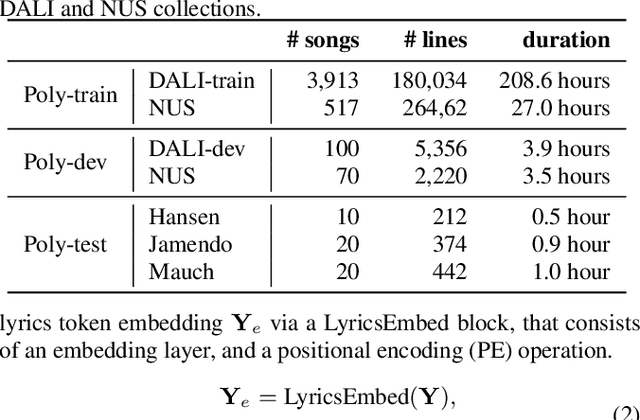
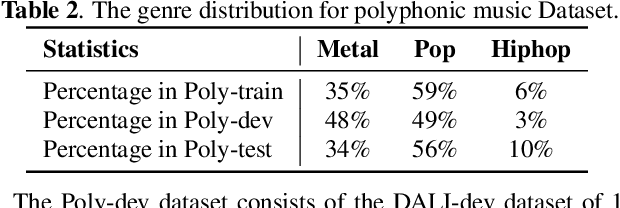
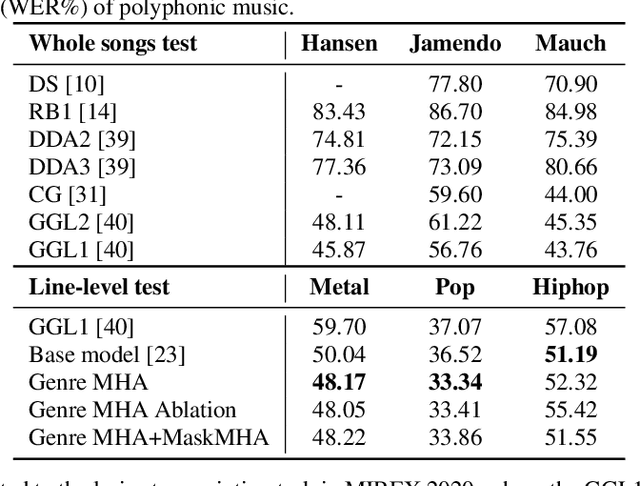
Lyrics transcription of polyphonic music is challenging not only because the singing vocals are corrupted by the background music, but also because the background music and the singing style vary across music genres, such as pop, metal, and hip hop, which affects lyrics intelligibility of the song in different ways. In this work, we propose to transcribe the lyrics of polyphonic music using a novel genre-conditioned network. The proposed network adopts pre-trained model parameters, and incorporates the genre adapters between layers to capture different genre peculiarities for lyrics-genre pairs, thereby only requiring lightweight genre-specific parameters for training. Our experiments show that the proposed genre-conditioned network outperforms the existing lyrics transcription systems.
Cadence Detection in Symbolic Classical Music using Graph Neural Networks
Aug 31, 2022

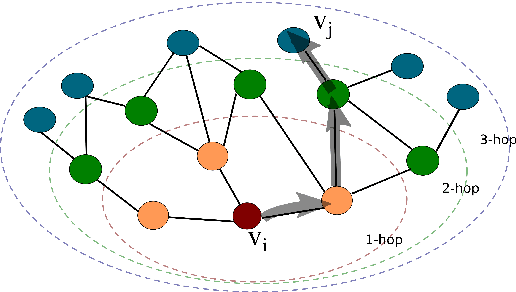
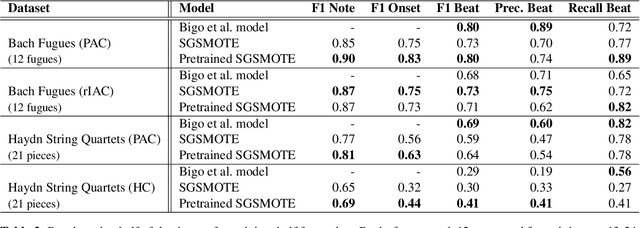
Cadences are complex structures that have been driving music from the beginning of contrapuntal polyphony until today. Detecting such structures is vital for numerous MIR tasks such as musicological analysis, key detection, or music segmentation. However, automatic cadence detection remains challenging mainly because it involves a combination of high-level musical elements like harmony, voice leading, and rhythm. In this work, we present a graph representation of symbolic scores as an intermediate means to solve the cadence detection task. We approach cadence detection as an imbalanced node classification problem using a Graph Convolutional Network. We obtain results that are roughly on par with the state of the art, and we present a model capable of making predictions at multiple levels of granularity, from individual notes to beats, thanks to the fine-grained, note-by-note representation. Moreover, our experiments suggest that graph convolution can learn non-local features that assist in cadence detection, freeing us from the need of having to devise specialized features that encode non-local context. We argue that this general approach to modeling musical scores and classification tasks has a number of potential advantages, beyond the specific recognition task presented here.
Music Interpretation Analysis. A Multimodal Approach To Score-Informed Resynthesis of Piano Recordings
May 02, 2022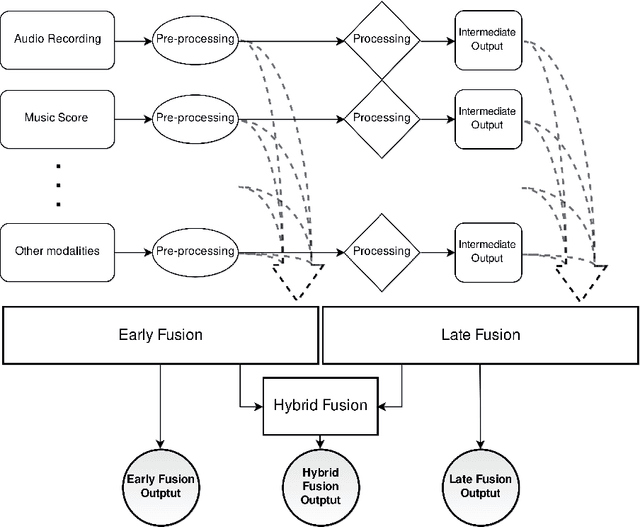
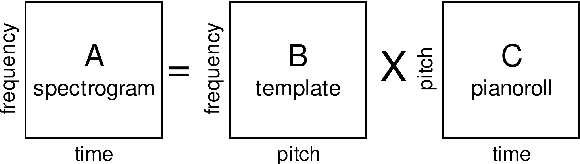
This Thesis discusses the development of technologies for the automatic resynthesis of music recordings using digital synthesizers. First, the main issue is identified in the understanding of how Music Information Processing (MIP) methods can take into consideration the influence of the acoustic context on the music performance. For this, a novel conceptual and mathematical framework named "Music Interpretation Analysis" (MIA) is presented. In the proposed framework, a distinction is made between the "performance" - the physical action of playing - and the "interpretation" - the action that the performer wishes to achieve. Second, the Thesis describes further works aiming at the democratization of music production tools via automatic resynthesis: 1) it elaborates software and file formats for historical music archiving and multimodal machine-learning datasets; 2) it explores and extends MIP technologies; 3) it presents the mathematical foundations of the MIA framework and shows preliminary evaluations to demonstrate the effectiveness of the approach
Partitura: A Python Package for Symbolic Music Processing
Jun 02, 2022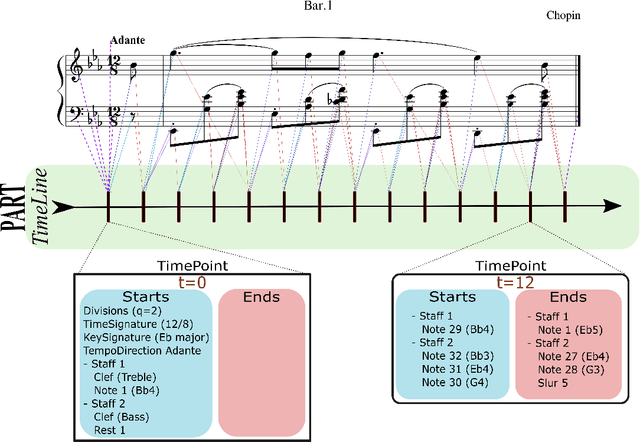

Partitura is a lightweight Python package for handling symbolic musical information. It provides easy access to features commonly used in music information retrieval tasks, like note arrays (lists of timed pitched events) and 2D piano roll matrices, as well as other score elements such as time and key signatures, performance directives, and repeat structures. Partitura can load musical scores (in MEI, MusicXML, Kern, and MIDI formats), MIDI performances, and score-to-performance alignments. The package includes some tools for music analysis, such as automatic pitch spelling, key signature identification, and voice separation. Partitura is an open-source project and is available at https://github.com/CPJKU/partitura/.