 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Self-Supervised Pretraining on Paired Sequences of fMRI Data for Transfer Learning to Brain Decoding Tasks
May 15, 2023
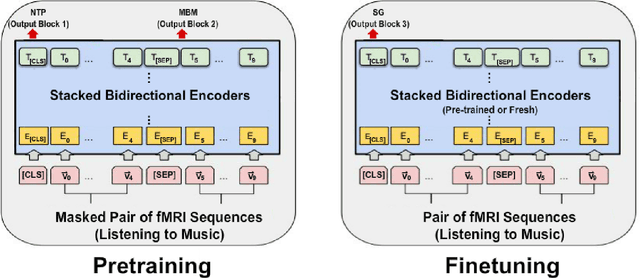
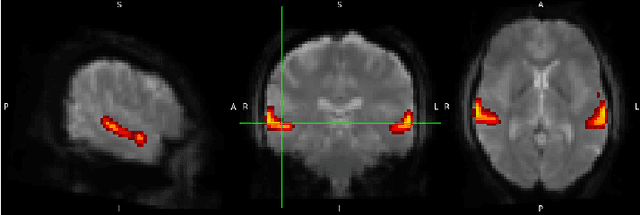

In this work we introduce a self-supervised pretraining framework for transformers on functional Magnetic Resonance Imaging (fMRI) data. First, we pretrain our architecture on two self-supervised tasks simultaneously to teach the model a general understanding of the temporal and spatial dynamics of human auditory cortex during music listening. Our pretraining results are the first to suggest a synergistic effect of multitask training on fMRI data. Second, we finetune the pretrained models and train additional fresh models on a supervised fMRI classification task. We observe significantly improved accuracy on held-out runs with the finetuned models, which demonstrates the ability of our pretraining tasks to facilitate transfer learning. This work contributes to the growing body of literature on transformer architectures for pretraining and transfer learning with fMRI data, and serves as a proof of concept for our pretraining tasks and multitask pretraining on fMRI data.
Scorpiano -- A System for Automatic Music Transcription for Monophonic Piano Music
Aug 24, 2021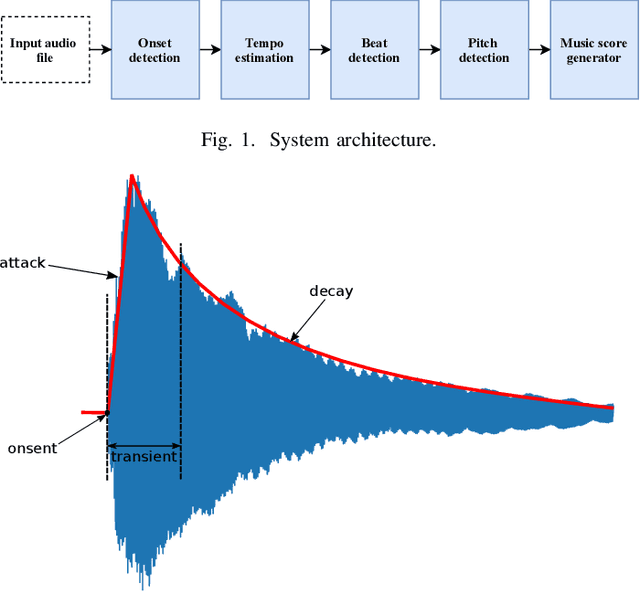
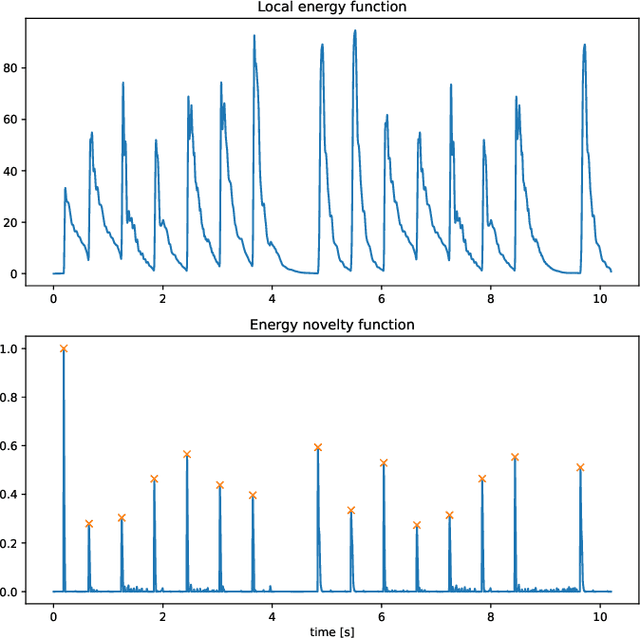
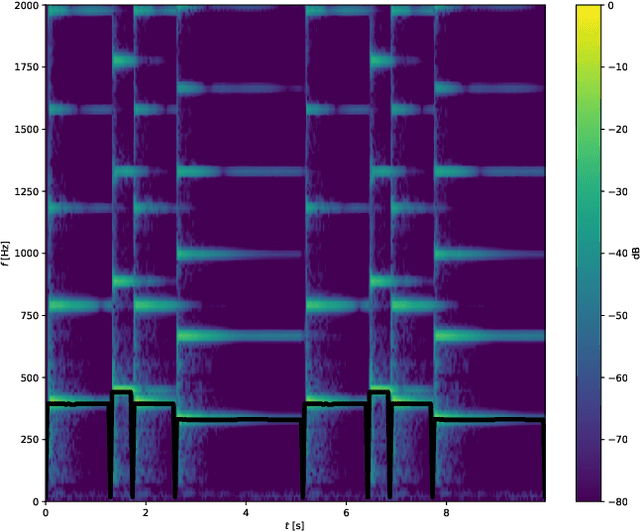

Music transcription is the process of transcribing music audio into music notation. It is a field in which the machines still cannot beat human performance. The main motivation for automatic music transcription is to make it possible for anyone playing a musical instrument, to be able to generate the music notes for a piece of music quickly and accurately. It does not matter if the person is a beginner and simply struggles to find the music score by searching, or an expert who heard a live jazz improvisation and would like to reproduce it without losing time doing manual transcription. We propose Scorpiano -- a system that can automatically generate a music score for simple monophonic piano melody tracks using digital signal processing. The system integrates multiple digital audio processing methods: notes onset detection, tempo estimation, beat detection, pitch detection and finally generation of the music score. The system has proven to give good results for simple piano melodies, comparable to commercially available neural network based systems.
E-PANNs: Sound Recognition Using Efficient Pre-trained Audio Neural Networks
May 30, 2023

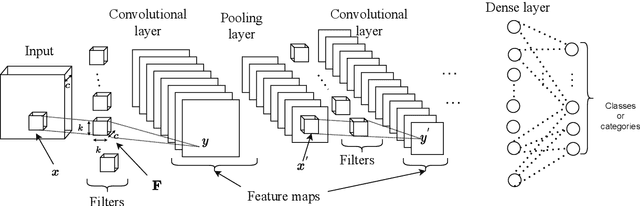
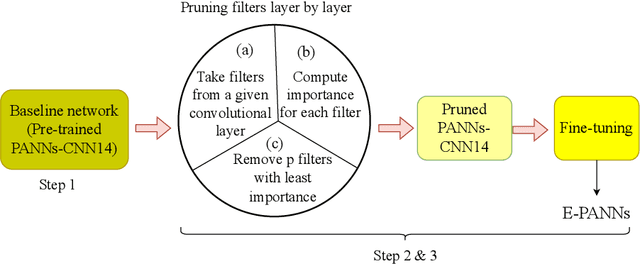
Sounds carry an abundance of information about activities and events in our everyday environment, such as traffic noise, road works, music, or people talking. Recent machine learning methods, such as convolutional neural networks (CNNs), have been shown to be able to automatically recognize sound activities, a task known as audio tagging. One such method, pre-trained audio neural networks (PANNs), provides a neural network which has been pre-trained on over 500 sound classes from the publicly available AudioSet dataset, and can be used as a baseline or starting point for other tasks. However, the existing PANNs model has a high computational complexity and large storage requirement. This could limit the potential for deploying PANNs on resource-constrained devices, such as on-the-edge sound sensors, and could lead to high energy consumption if many such devices were deployed. In this paper, we reduce the computational complexity and memory requirement of the PANNs model by taking a pruning approach to eliminate redundant parameters from the PANNs model. The resulting Efficient PANNs (E-PANNs) model, which requires 36\% less computations and 70\% less memory, also slightly improves the sound recognition (audio tagging) performance. The code for the E-PANNs model has been released under an open source license.
Explainability in Music Recommender Systems
Jan 25, 2022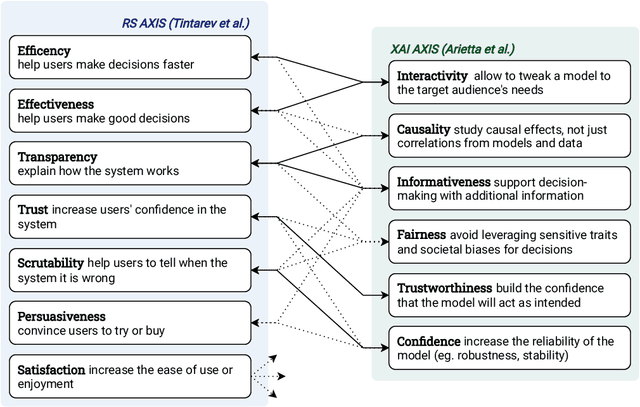
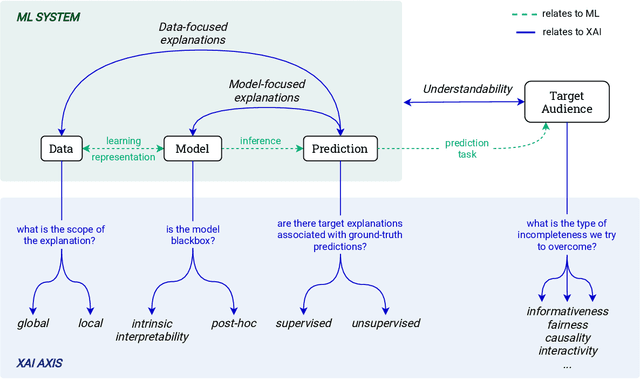
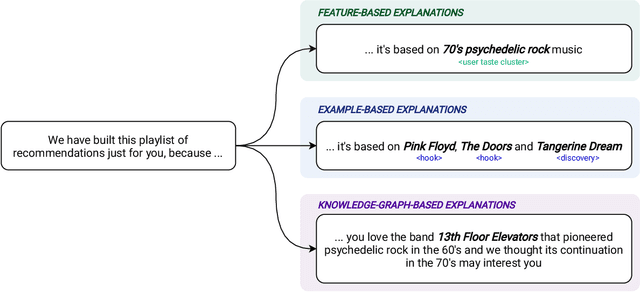
The most common way to listen to recorded music nowadays is via streaming platforms which provide access to tens of millions of tracks. To assist users in effectively browsing these large catalogs, the integration of Music Recommender Systems (MRSs) has become essential. Current real-world MRSs are often quite complex and optimized for recommendation accuracy. They combine several building blocks based on collaborative filtering and content-based recommendation. This complexity can hinder the ability to explain recommendations to end users, which is particularly important for recommendations perceived as unexpected or inappropriate. While pure recommendation performance often correlates with user satisfaction, explainability has a positive impact on other factors such as trust and forgiveness, which are ultimately essential to maintain user loyalty. In this article, we discuss how explainability can be addressed in the context of MRSs. We provide perspectives on how explainability could improve music recommendation algorithms and enhance user experience. First, we review common dimensions and goals of recommenders' explainability and in general of eXplainable Artificial Intelligence (XAI), and elaborate on the extent to which these apply -- or need to be adapted -- to the specific characteristics of music consumption and recommendation. Then, we show how explainability components can be integrated within a MRS and in what form explanations can be provided. Since the evaluation of explanation quality is decoupled from pure accuracy-based evaluation criteria, we also discuss requirements and strategies for evaluating explanations of music recommendations. Finally, we describe the current challenges for introducing explainability within a large-scale industrial music recommender system and provide research perspectives.
SSM-Net: feature learning for Music Structure Analysis using a Self-Similarity-Matrix based loss
Nov 15, 2022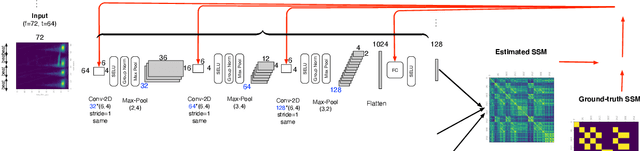
In this paper, we propose a new paradigm to learn audio features for Music Structure Analysis (MSA). We train a deep encoder to learn features such that the Self-Similarity-Matrix (SSM) resulting from those approximates a ground-truth SSM. This is done by minimizing a loss between both SSMs. Since this loss is differentiable w.r.t. its input features we can train the encoder in a straightforward way. We successfully demonstrate the use of this training paradigm using the Area Under the Curve ROC (AUC) on the RWC-Pop dataset.
Target-Aware Spatio-Temporal Reasoning via Answering Questions in Dynamics Audio-Visual Scenarios
May 21, 2023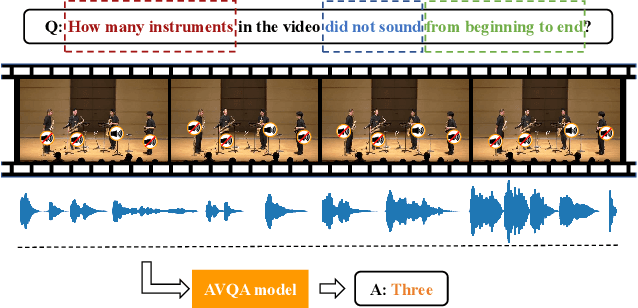

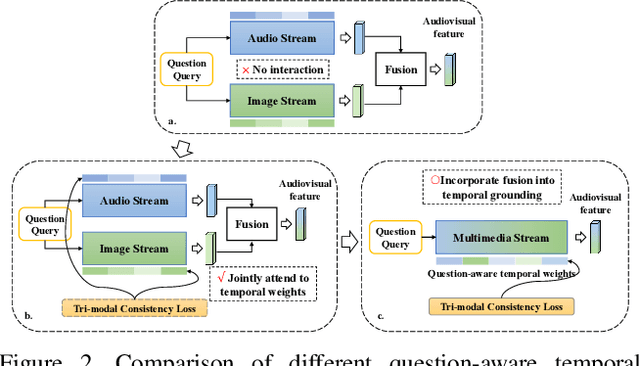

Audio-visual question answering (AVQA) is a challenging task that requires multistep spatio-temporal reasoning over multimodal contexts. To achieve scene understanding ability similar to humans, the AVQA task presents specific challenges, including effectively fusing audio and visual information and capturing question-relevant audio-visual features while maintaining temporal synchronization. This paper proposes a Target-aware Joint Spatio-Temporal Grounding Network for AVQA to address these challenges. The proposed approach has two main components: the Target-aware Spatial Grounding module, the Tri-modal consistency loss and corresponding Joint audio-visual temporal grounding module. The Target-aware module enables the model to focus on audio-visual cues relevant to the inquiry subject by exploiting the explicit semantics of text modality. The Tri-modal consistency loss facilitates the interaction between audio and video during question-aware temporal grounding and incorporates fusion within a simpler single-stream architecture. Experimental results on the MUSIC-AVQA dataset demonstrate the effectiveness and superiority of the proposed method over existing state-of-the-art methods. Our code will be availiable soon.
Tollywood Emotions: Annotation of Valence-Arousal in Telugu Song Lyrics
Mar 16, 2023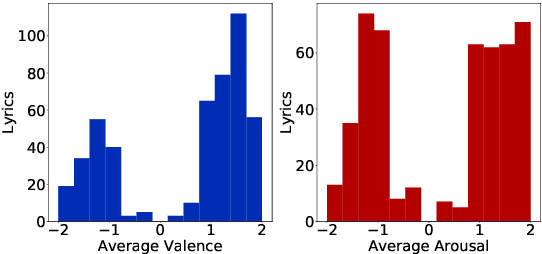
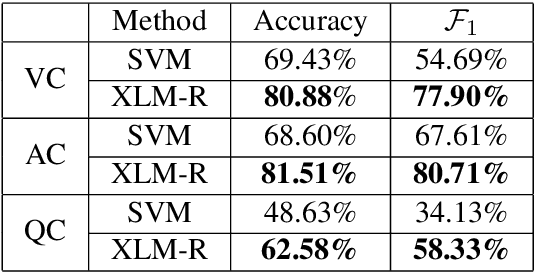
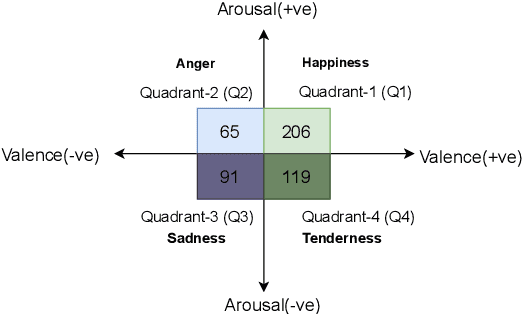
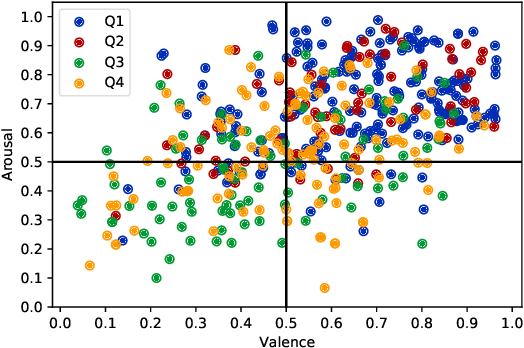
Emotion recognition from a given music track has heavily relied on acoustic features, social tags, and metadata but is seldom focused on lyrics. There are no datasets of Indian language songs that contain both valence and arousal manual ratings of lyrics. We present a new manually annotated dataset of Telugu songs' lyrics collected from Spotify with valence and arousal annotated on a discrete scale. A fairly high inter-annotator agreement was observed for both valence and arousal. Subsequently, we create two music emotion recognition models by using two classification techniques to identify valence, arousal and respective emotion quadrant from lyrics. Support vector machine (SVM) with term frequency-inverse document frequency (TF-IDF) features and fine-tuning the pre-trained XLMRoBERTa (XLM-R) model were used for valence, arousal and quadrant classification tasks. Fine-tuned XLMRoBERTa performs better than the SVM by improving macro-averaged F1-scores of 54.69%, 67.61%, 34.13% to 77.90%, 80.71% and 58.33% for valence, arousal and quadrant classifications, respectively, on 10-fold cross-validation. In addition, we compare our lyrics annotations with Spotify's annotations of valence and energy (same as arousal), which are based on entire music tracks. The implications of our findings are discussed. Finally, we make the dataset publicly available with lyrics, annotations and Spotify IDs.
Emergency Response Person Localization and Vital Sign Estimation Using a Semi-Autonomous Robot Mounted SFCW Radar
May 25, 2023
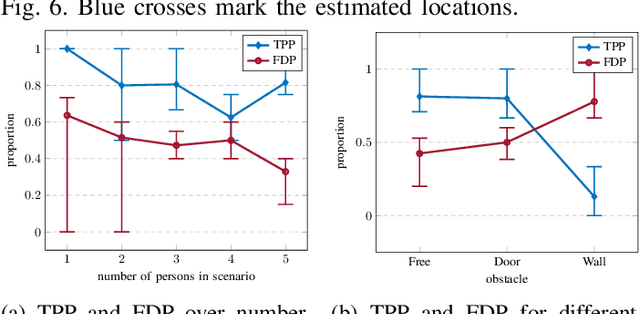
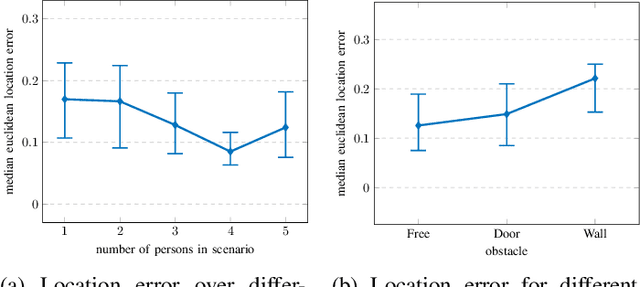
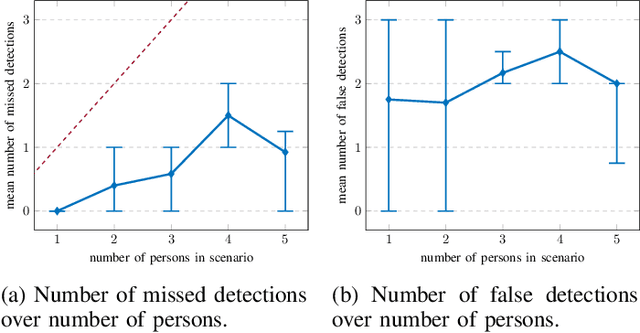
The large number and scale of natural and man-made disasters have led to an urgent demand for technologies that enhance the safety and efficiency of search and rescue teams. Semi-autonomous rescue robots are beneficial, especially when searching inaccessible terrains, or dangerous environments, such as collapsed infrastructures. For search and rescue missions in degraded visual conditions or non-line of sight scenarios, radar-based approaches may contribute to acquire valuable, and otherwise unavailable information. This article presents a complete signal processing chain for radar-based multi-person detection, 2D-MUSIC localization and breathing frequency estimation. The proposed method shows promising results on a challenging emergency response dataset that we collected using a semi-autonomous robot equipped with a commercially available through-wall radar system. The dataset is composed of 62 scenarios of various difficulty levels with up to five persons captured in different postures, angles and ranges including wooden and stone obstacles that block the radar line of sight. Ground truth data for reference locations, respiration, electrocardiogram, and acceleration signals are included. The full emergency response benchmark data set as well as all codes to reproduce our results, are publicly available at https://doi.org/10.21227/4bzd-jm32.
Ripple Knowledge Graph Convolutional Networks For Recommendation Systems
May 02, 2023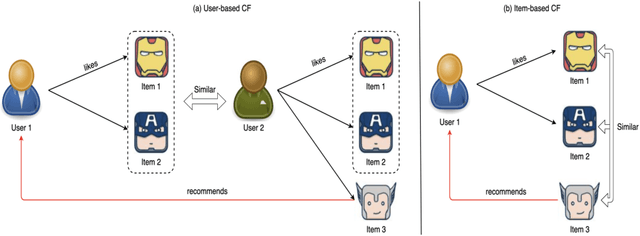

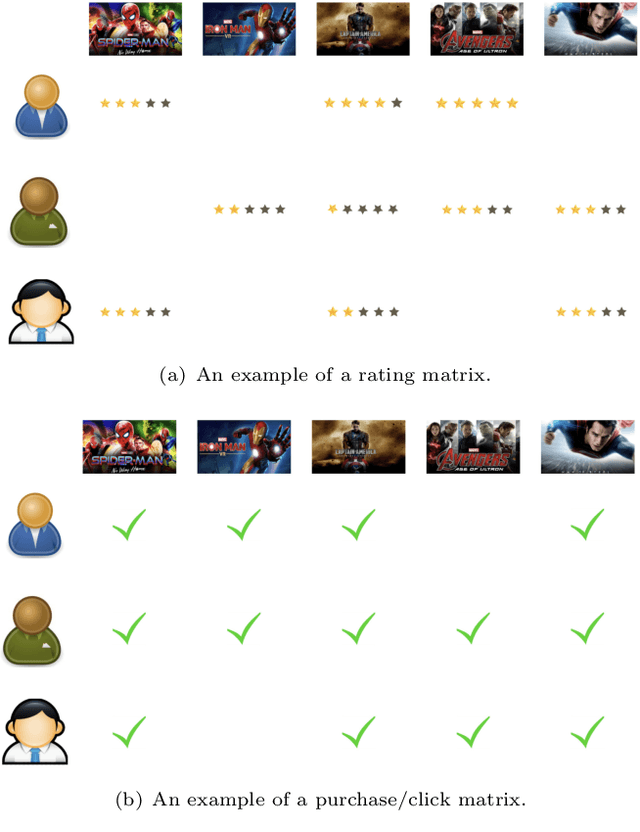
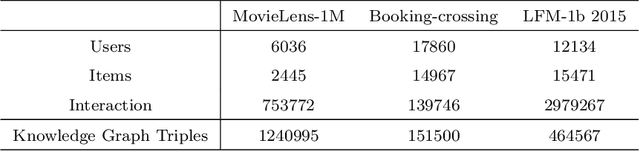
Using knowledge graphs to assist deep learning models in making recommendation decisions has recently been proven to effectively improve the model's interpretability and accuracy. This paper introduces an end-to-end deep learning model, named RKGCN, which dynamically analyses each user's preferences and makes a recommendation of suitable items. It combines knowledge graphs on both the item side and user side to enrich their representations to maximize the utilization of the abundant information in knowledge graphs. RKGCN is able to offer more personalized and relevant recommendations in three different scenarios. The experimental results show the superior effectiveness of our model over 5 baseline models on three real-world datasets including movies, books, and music.
Improving Recommendation Systems with User Personality Inferred from Product Reviews
Mar 21, 2023


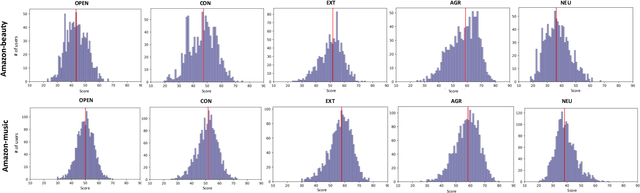
Personality is a psychological factor that reflects people's preferences, which in turn influences their decision-making. We hypothesize that accurate modeling of users' personalities improves recommendation systems' performance. However, acquiring such personality profiles is both sensitive and expensive. We address this problem by introducing a novel method to automatically extract personality profiles from public product review text. We then design and assess three context-aware recommendation architectures that leverage the profiles to test our hypothesis. Experiments on our two newly contributed personality datasets -- Amazon-beauty and Amazon-music -- validate our hypothesis, showing performance boosts of 3--28%.Our analysis uncovers that varying personality types contribute differently to recommendation performance: open and extroverted personalities are most helpful in music recommendation, while a conscientious personality is most helpful in beauty product recommendation.