 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Towards Proper Contrastive Self-supervised Learning Strategies For Music Audio Representation
Jul 10, 2022
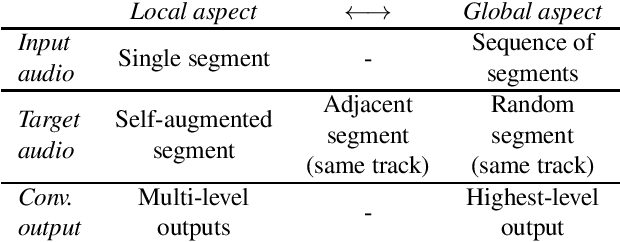

The common research goal of self-supervised learning is to extract a general representation which an arbitrary downstream task would benefit from. In this work, we investigate music audio representation learned from different contrastive self-supervised learning schemes and empirically evaluate the embedded vectors on various music information retrieval (MIR) tasks where different levels of the music perception are concerned. We analyze the results to discuss the proper direction of contrastive learning strategies for different MIR tasks. We show that these representations convey a comprehensive information about the auditory characteristics of music in general, although each of the self-supervision strategies has its own effectiveness in certain aspect of information.
Algorithms of Sampling-Frequency-Independent Layers for Non-integer Strides
Jun 19, 2023
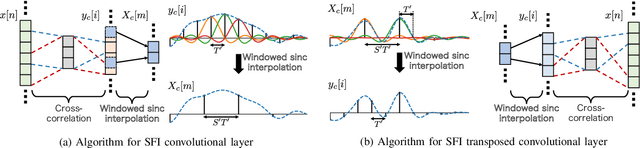
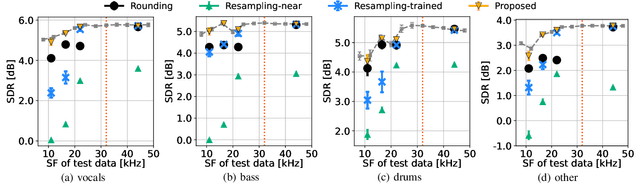

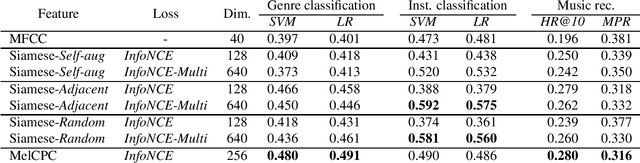
In this paper, we propose algorithms for handling non-integer strides in sampling-frequency-independent (SFI) convolutional and transposed convolutional layers. The SFI layers have been developed for handling various sampling frequencies (SFs) by a single neural network. They are replaceable with their non-SFI counterparts and can be introduced into various network architectures. However, they could not handle some specific configurations when combined with non-SFI layers. For example, an SFI extension of Conv-TasNet, a standard audio source separation model, cannot handle some pairs of trained and target SFs because the strides of the SFI layers become non-integers. This problem cannot be solved by simple rounding or signal resampling, resulting in the significant performance degradation. To overcome this problem, we propose algorithms for handling non-integer strides by using windowed sinc interpolation. The proposed algorithms realize the continuous-time representations of features using the interpolation and enable us to sample instants with the desired stride. Experimental results on music source separation showed that the proposed algorithms outperformed the rounding- and signal-resampling-based methods at SFs lower than the trained SF.
CoverHunter: Cover Song Identification with Refined Attention and Alignments
Jun 15, 2023
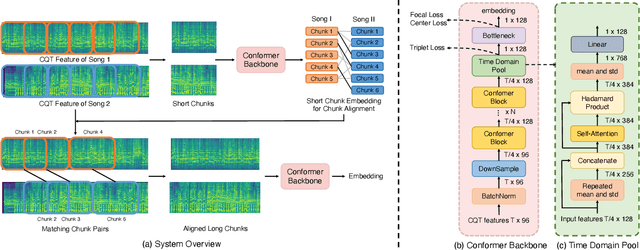
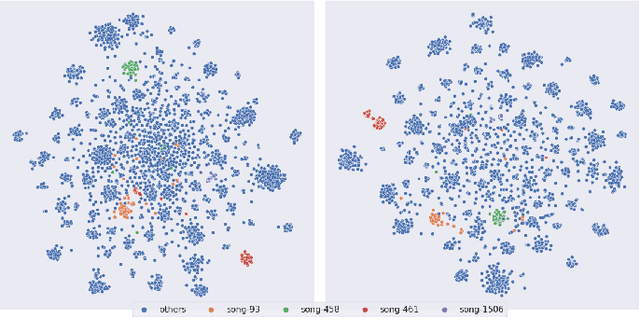
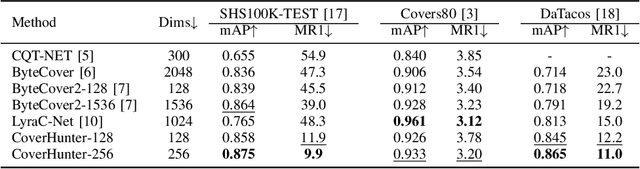
Abstract: Cover song identification (CSI) focuses on finding the same music with different versions in reference anchors given a query track. In this paper, we propose a novel system named CoverHunter that overcomes the shortcomings of existing detection schemes by exploring richer features with refined attention and alignments. CoverHunter contains three key modules: 1) A convolution-augmented transformer (i.e., Conformer) structure that captures both local and global feature interactions in contrast to previous methods mainly relying on convolutional neural networks; 2) An attention-based time pooling module that further exploits the attention in the time dimension; 3) A novel coarse-to-fine training scheme that first trains a network to roughly align the song chunks and then refines the network by training on the aligned chunks. At the same time, we also summarize some important training tricks used in our system that help achieve better results. Experiments on several standard CSI datasets show that our method significantly improves over state-of-the-art methods with an embedding size of 128 (2.3% on SHS100K-TEST and 17.7% on DaTacos).
The pop song generator: designing an online course to teach collaborative, creative AI
Jun 15, 2023This article describes and evaluates a new online AI-creativity course. The course is based around three near-state-of-the-art AI models combined into a pop song generating system. A fine-tuned GPT-2 model writes lyrics, Music-VAE composes musical scores and instrumentation and Diffsinger synthesises a singing voice. We explain the decisions made in designing the course which is based on Piagetian, constructivist 'learning-by-doing'. We present details of the five-week course design with learning objectives, technical concepts, and creative and technical activities. We explain how we overcame technical challenges to build a complete pop song generator system, consisting of Python scripts, pre-trained models, and Javascript code that runs in a dockerised Linux container via a web-based IDE. A quantitative analysis of student activity provides evidence on engagement and a benchmark for future improvements. A qualitative analysis of a workshop with experts validated the overall course design, it suggested the need for a stronger creative brief and ethical and legal content.
Tempo vs. Pitch: understanding self-supervised tempo estimation
Apr 14, 2023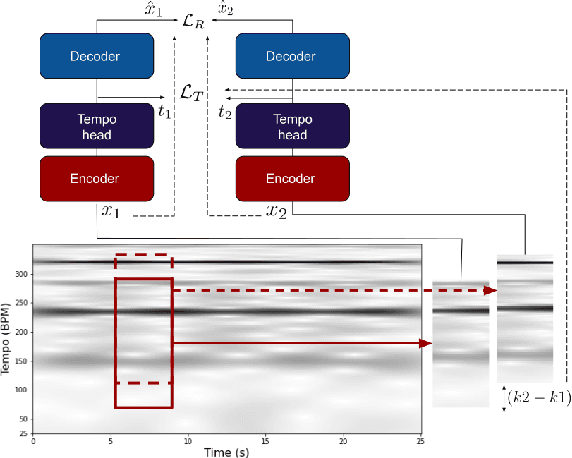
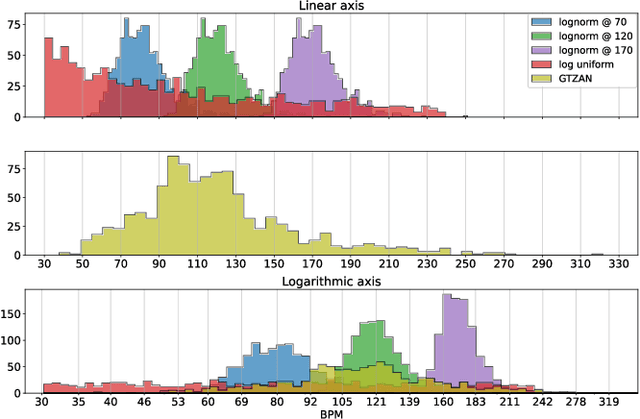
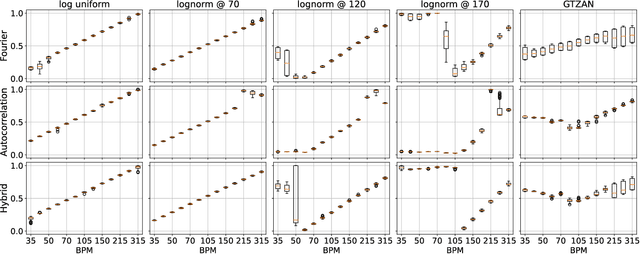
Self-supervision methods learn representations by solving pretext tasks that do not require human-generated labels, alleviating the need for time-consuming annotations. These methods have been applied in computer vision, natural language processing, environmental sound analysis, and recently in music information retrieval, e.g. for pitch estimation. Particularly in the context of music, there are few insights about the fragility of these models regarding different distributions of data, and how they could be mitigated. In this paper, we explore these questions by dissecting a self-supervised model for pitch estimation adapted for tempo estimation via rigorous experimentation with synthetic data. Specifically, we study the relationship between the input representation and data distribution for self-supervised tempo estimation.
Large Language and Text-to-3D Models for Engineering Design Optimization
Jul 03, 2023
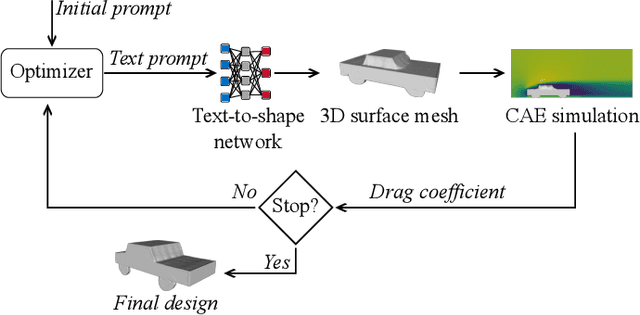
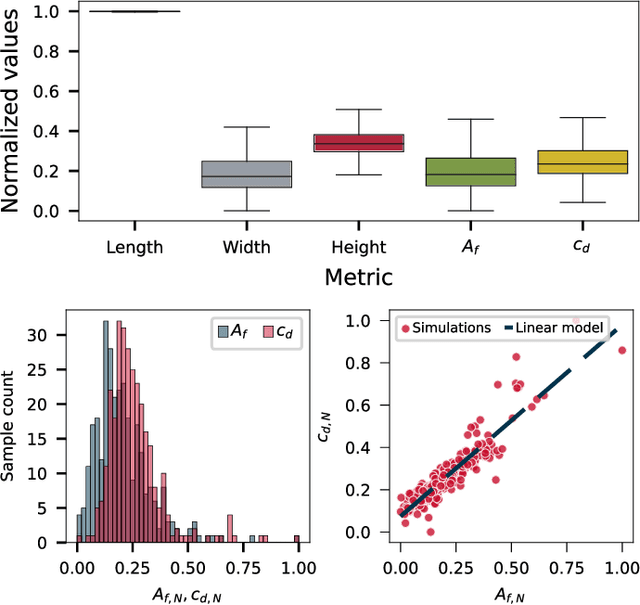

The current advances in generative AI for learning large neural network models with the capability to produce essays, images, music and even 3D assets from text prompts create opportunities for a manifold of disciplines. In the present paper, we study the potential of deep text-to-3D models in the engineering domain, with focus on the chances and challenges when integrating and interacting with 3D assets in computational simulation-based design optimization. In contrast to traditional design optimization of 3D geometries that often searches for the optimum designs using numerical representations, such as B-Spline surface or deformation parameters in vehicle aerodynamic optimization, natural language challenges the optimization framework by requiring a different interpretation of variation operators while at the same time may ease and motivate the human user interaction. Here, we propose and realize a fully automated evolutionary design optimization framework using Shap-E, a recently published text-to-3D asset network by OpenAI, in the context of aerodynamic vehicle optimization. For representing text prompts in the evolutionary optimization, we evaluate (a) a bag-of-words approach based on prompt templates and Wordnet samples, and (b) a tokenisation approach based on prompt templates and the byte pair encoding method from GPT4. Our main findings from the optimizations indicate that, first, it is important to ensure that the designs generated from prompts are within the object class of application, i.e. diverse and novel designs need to be realistic, and, second, that more research is required to develop methods where the strength of text prompt variations and the resulting variations of the 3D designs share causal relations to some degree to improve the optimization.
Dance Generation by Sound Symbolic Words
Jun 06, 2023

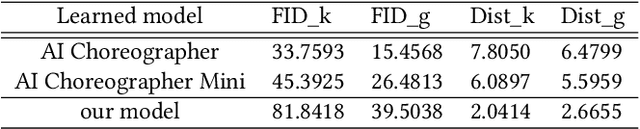
This study introduces a novel approach to generate dance motions using onomatopoeia as input, with the aim of enhancing creativity and diversity in dance generation. Unlike text and music, onomatopoeia conveys rhythm and meaning through abstract word expressions without constraints on expression and without need for specialized knowledge. We adapt the AI Choreographer framework and employ the Sakamoto system, a feature extraction method for onomatopoeia focusing on phonemes and syllables. Additionally, we present a new dataset of 40 onomatopoeia-dance motion pairs collected through a user survey. Our results demonstrate that the proposed method enables more intuitive dance generation and can create dance motions using sound-symbolic words from a variety of languages, including those without onomatopoeia. This highlights the potential for diverse dance creation across different languages and cultures, accessible to a wider audience. Qualitative samples from our model can be found at: https://sites.google.com/view/onomatopoeia-dance/home/.
EmotionBox: a music-element-driven emotional music generation system using Recurrent Neural Network
Dec 16, 2021
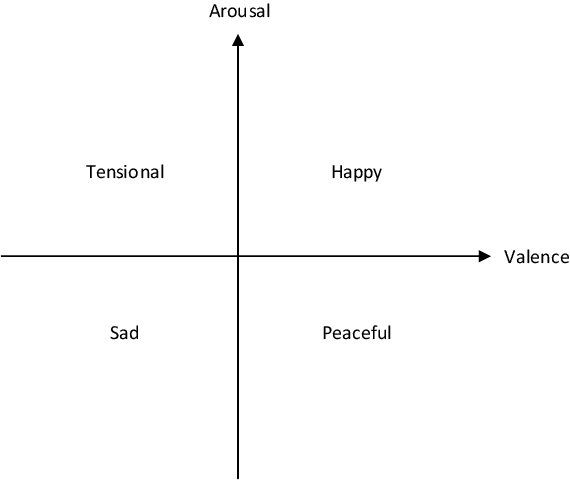
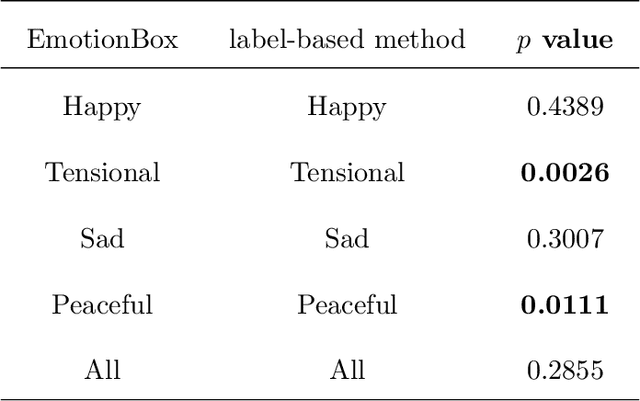
With the development of deep neural networks, automatic music composition has made great progress. Although emotional music can evoke listeners' different emotions and it is important for artistic expression, only few researches have focused on generating emotional music. This paper presents EmotionBox -an music-element-driven emotional music generator that is capable of composing music given a specific emotion, where this model does not require a music dataset labeled with emotions. Instead, pitch histogram and note density are extracted as features that represent mode and tempo respectively to control music emotions. The subjective listening tests show that the Emotionbox has a more competitive and balanced performance in arousing a specified emotion than the emotion-label-based method.
"More Than Words": Linking Music Preferences and Moral Values Through Lyrics
Sep 02, 2022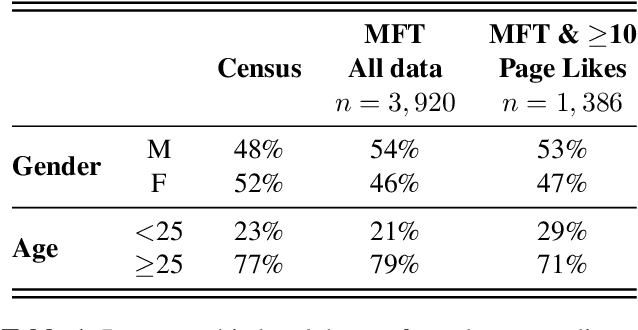
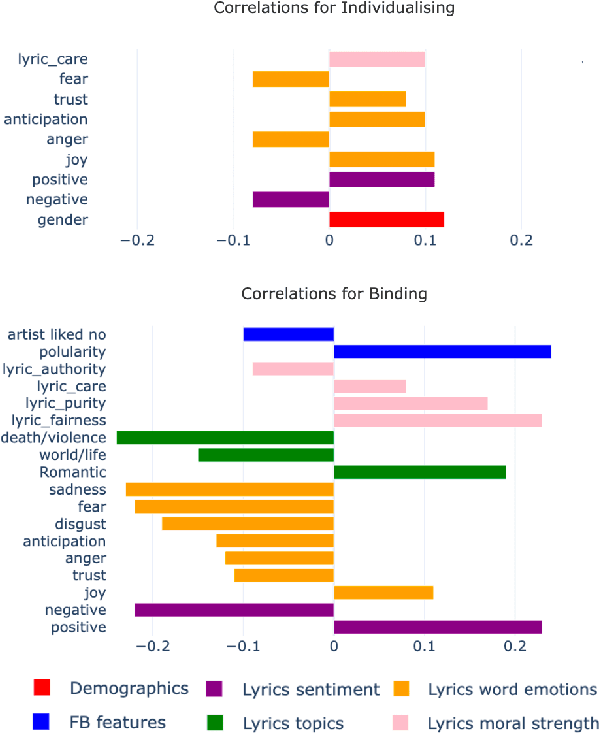
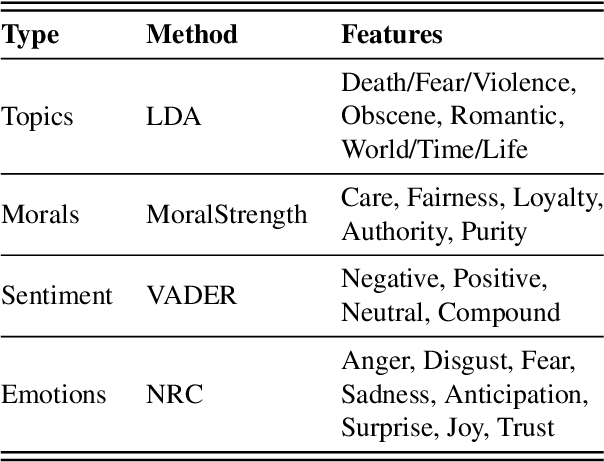
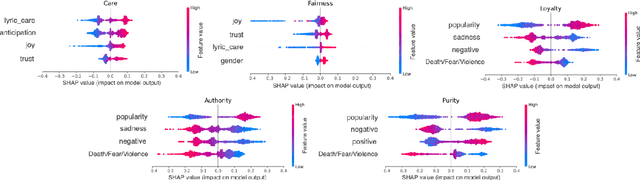
This study explores the association between music preferences and moral values by applying text analysis techniques to lyrics. Harvesting data from a Facebook-hosted application, we align psychometric scores of 1,386 users to lyrics from the top 5 songs of their preferred music artists as emerged from Facebook Page Likes. We extract a set of lyrical features related to each song's overarching narrative, moral valence, sentiment, and emotion. A machine learning framework was designed to exploit regression approaches and evaluate the predictive power of lyrical features for inferring moral values. Results suggest that lyrics from top songs of artists people like inform their morality. Virtues of hierarchy and tradition achieve higher prediction scores ($.20 \leq r \leq .30$) than values of empathy and equality ($.08 \leq r \leq .11$), while basic demographic variables only account for a small part in the models' explainability. This shows the importance of music listening behaviours, as assessed via lyrical preferences, alone in capturing moral values. We discuss the technological and musicological implications and possible future improvements.
Pure Data and INScore: Animated notation for new music
Aug 09, 2022
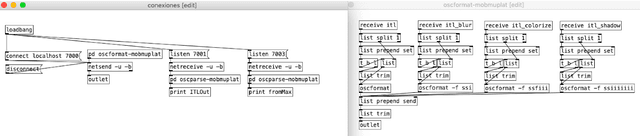

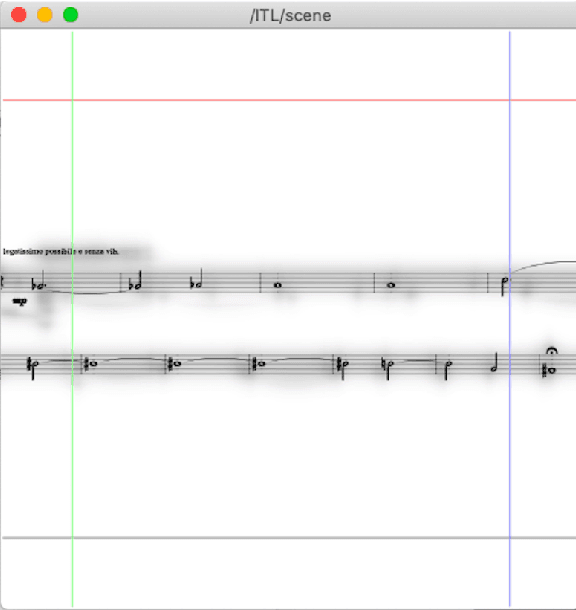
New music is made with computers, taking advantage of its graphics displays rather than its audio algorithms. Pure Data can be used to compose them. This essay will show a case study that uses Pure Data, in connection with INScore, for making a new type of score that uses animated notation or dynamic musicography for making music with performers. This sample was made by the author of the text, and it will show a number of notation possibilities that can be done using the combination of software. This will be accompanied by a simple prediction of what a musician could perform with it.