 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Apr 02, 2024
Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods.
Music Style Transfer with Time-Varying Inversion of Diffusion Models
Feb 21, 2024With the development of diffusion models, text-guided image style transfer has demonstrated high-quality controllable synthesis results. However, the utilization of text for diverse music style transfer poses significant challenges, primarily due to the limited availability of matched audio-text datasets. Music, being an abstract and complex art form, exhibits variations and intricacies even within the same genre, thereby making accurate textual descriptions challenging. This paper presents a music style transfer approach that effectively captures musical attributes using minimal data. We introduce a novel time-varying textual inversion module to precisely capture mel-spectrogram features at different levels. During inference, we propose a bias-reduced stylization technique to obtain stable results. Experimental results demonstrate that our method can transfer the style of specific instruments, as well as incorporate natural sounds to compose melodies. Samples and source code are available at https://lsfhuihuiff.github.io/MusicTI/.
An Order-Complexity Aesthetic Assessment Model for Aesthetic-aware Music Recommendation
Feb 13, 2024Computational aesthetic evaluation has made remarkable contribution to visual art works, but its application to music is still rare. Currently, subjective evaluation is still the most effective form of evaluating artistic works. However, subjective evaluation of artistic works will consume a lot of human and material resources. The popular AI generated content (AIGC) tasks nowadays have flooded all industries, and music is no exception. While compared to music produced by humans, AI generated music still sounds mechanical, monotonous, and lacks aesthetic appeal. Due to the lack of music datasets with rating annotations, we have to choose traditional aesthetic equations to objectively measure the beauty of music. In order to improve the quality of AI music generation and further guide computer music production, synthesis, recommendation and other tasks, we use Birkhoff's aesthetic measure to design a aesthetic model, objectively measuring the aesthetic beauty of music, and form a recommendation list according to the aesthetic feeling of music. Experiments show that our objective aesthetic model and recommendation method are effective.
MUSIC: Accelerated Convergence for Distributed Optimization With Inexact and Exact Methods
Mar 05, 2024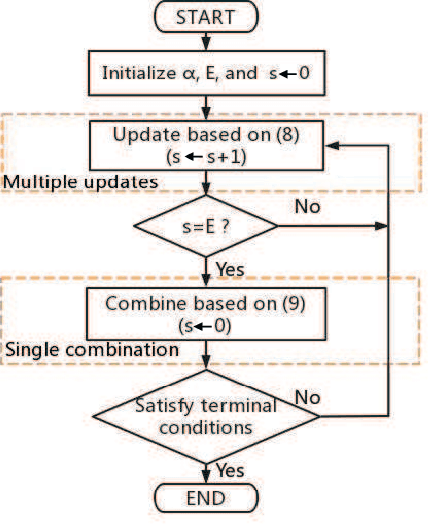
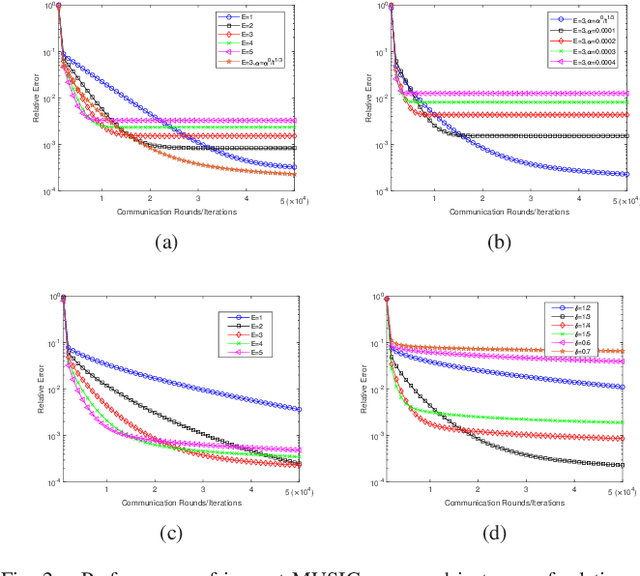
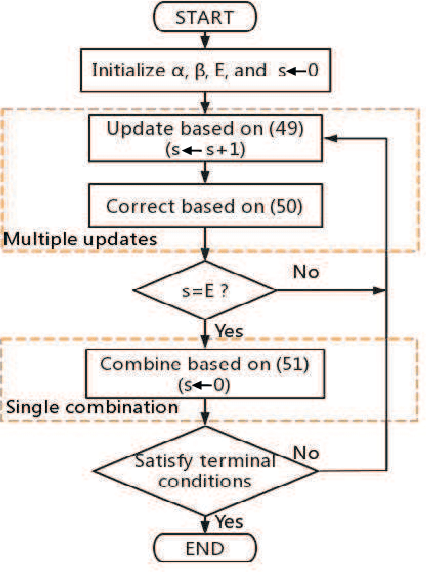
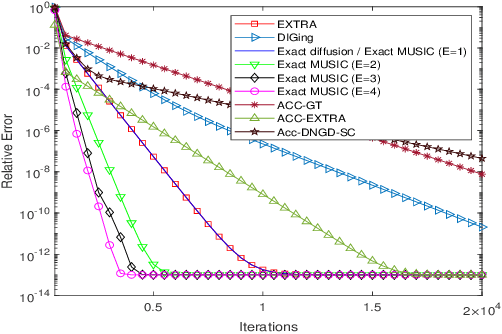
Gradient-type distributed optimization methods have blossomed into one of the most important tools for solving a minimization learning task over a networked agent system. However, only one gradient update per iteration is difficult to achieve a substantive acceleration of convergence. In this paper, we propose an accelerated framework named as MUSIC allowing each agent to perform multiple local updates and a single combination in each iteration. More importantly, we equip inexact and exact distributed optimization methods into this framework, thereby developing two new algorithms that exhibit accelerated linear convergence and high communication efficiency. Our rigorous convergence analysis reveals the sources of steady-state errors arising from inexact policies and offers effective solutions. Numerical results based on synthetic and real datasets demonstrate both our theoretical motivations and analysis, as well as performance advantages.
DeepSRGM -- Sequence Classification and Ranking in Indian Classical Music with Deep Learning
Feb 15, 2024A vital aspect of Indian Classical Music (ICM) is Raga, which serves as a melodic framework for compositions and improvisations alike. Raga Recognition is an important music information retrieval task in ICM as it can aid numerous downstream applications ranging from music recommendations to organizing huge music collections. In this work, we propose a deep learning based approach to Raga recognition. Our approach employs efficient pre possessing and learns temporal sequences in music data using Long Short Term Memory based Recurrent Neural Networks (LSTM-RNN). We train and test the network on smaller sequences sampled from the original audio while the final inference is performed on the audio as a whole. Our method achieves an accuracy of 88.1% and 97 % during inference on the Comp Music Carnatic dataset and its 10 Raga subset respectively making it the state-of-the-art for the Raga recognition task. Our approach also enables sequence ranking which aids us in retrieving melodic patterns from a given music data base that are closely related to the presented query sequence.
Large Motion Model for Unified Multi-Modal Motion Generation
Apr 01, 2024Human motion generation, a cornerstone technique in animation and video production, has widespread applications in various tasks like text-to-motion and music-to-dance. Previous works focus on developing specialist models tailored for each task without scalability. In this work, we present Large Motion Model (LMM), a motion-centric, multi-modal framework that unifies mainstream motion generation tasks into a generalist model. A unified motion model is appealing since it can leverage a wide range of motion data to achieve broad generalization beyond a single task. However, it is also challenging due to the heterogeneous nature of substantially different motion data and tasks. LMM tackles these challenges from three principled aspects: 1) Data: We consolidate datasets with different modalities, formats and tasks into a comprehensive yet unified motion generation dataset, MotionVerse, comprising 10 tasks, 16 datasets, a total of 320k sequences, and 100 million frames. 2) Architecture: We design an articulated attention mechanism ArtAttention that incorporates body part-aware modeling into Diffusion Transformer backbone. 3) Pre-Training: We propose a novel pre-training strategy for LMM, which employs variable frame rates and masking forms, to better exploit knowledge from diverse training data. Extensive experiments demonstrate that our generalist LMM achieves competitive performance across various standard motion generation tasks over state-of-the-art specialist models. Notably, LMM exhibits strong generalization capabilities and emerging properties across many unseen tasks. Additionally, our ablation studies reveal valuable insights about training and scaling up large motion models for future research.
MuChin: A Chinese Colloquial Description Benchmark for Evaluating Language Models in the Field of Music
Feb 15, 2024The rapidly evolving multimodal Large Language Models (LLMs) urgently require new benchmarks to uniformly evaluate their performance on understanding and textually describing music. However, due to semantic gaps between Music Information Retrieval (MIR) algorithms and human understanding, discrepancies between professionals and the public, and low precision of annotations, existing music description datasets cannot serve as benchmarks. To this end, we present MuChin, the first open-source music description benchmark in Chinese colloquial language, designed to evaluate the performance of multimodal LLMs in understanding and describing music. We established the Caichong Music Annotation Platform (CaiMAP) that employs an innovative multi-person, multi-stage assurance method, and recruited both amateurs and professionals to ensure the precision of annotations and alignment with popular semantics. Utilizing this method, we built a dataset with multi-dimensional, high-precision music annotations, the Caichong Music Dataset (CaiMD), and carefully selected 1,000 high-quality entries to serve as the test set for MuChin. Based on MuChin, we analyzed the discrepancies between professionals and amateurs in terms of music description, and empirically demonstrated the effectiveness of annotated data for fine-tuning LLMs. Ultimately, we employed MuChin to evaluate existing music understanding models on their ability to provide colloquial descriptions of music. All data related to the benchmark and the code for scoring have been open-sourced.
Arrange, Inpaint, and Refine: Steerable Long-term Music Audio Generation and Editing via Content-based Controls
Feb 14, 2024Controllable music generation plays a vital role in human-AI music co-creation. While Large Language Models (LLMs) have shown promise in generating high-quality music, their focus on autoregressive generation limits their utility in music editing tasks. To bridge this gap, we introduce a novel Parameter-Efficient Fine-Tuning (PEFT) method. This approach enables autoregressive language models to seamlessly address music inpainting tasks. Additionally, our PEFT method integrates frame-level content-based controls, facilitating track-conditioned music refinement and score-conditioned music arrangement. We apply this method to fine-tune MusicGen, a leading autoregressive music generation model. Our experiments demonstrate promising results across multiple music editing tasks, offering more flexible controls for future AI-driven music editing tools. A demo page\footnote{\url{https://kikyo-16.github.io/AIR/}.} showcasing our work and source codes\footnote{\url{https://github.com/Kikyo-16/airgen}.} are available online.
Reinforcement Learning Jazz Improvisation: When Music Meets Game Theory
Feb 25, 2024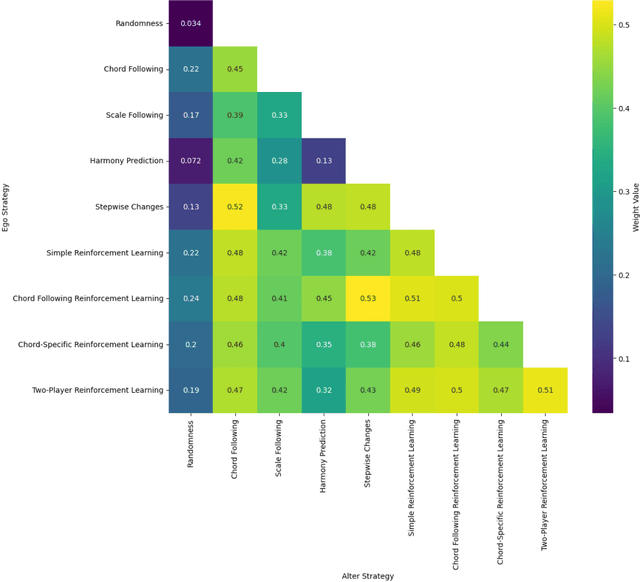
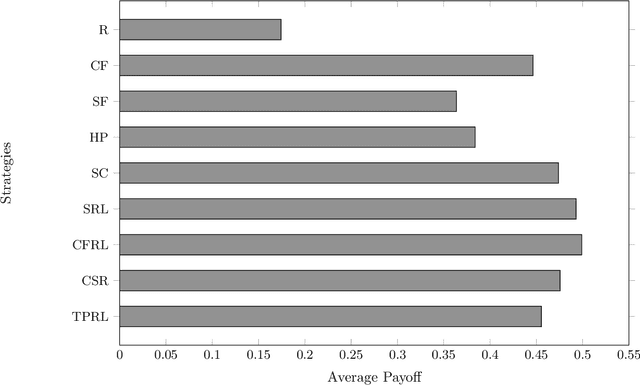
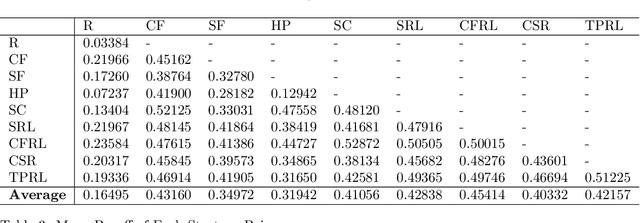
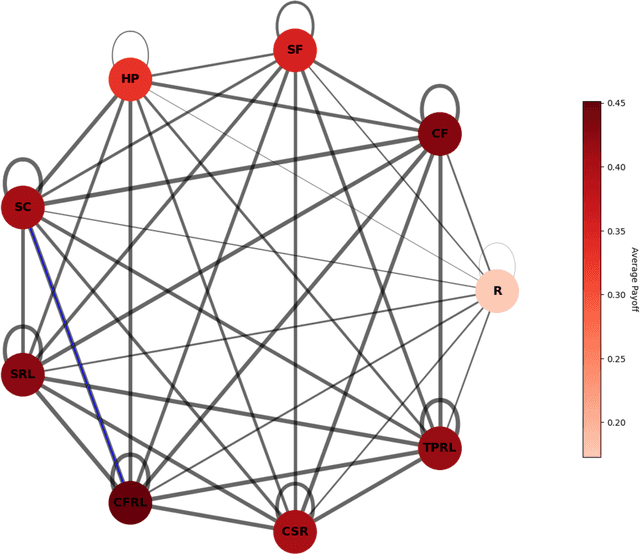
Live performances of music are always charming, with the unpredictability of improvisation due to the dynamic between musicians and interactions with the audience. Jazz improvisation is a particularly noteworthy example for further investigation from a theoretical perspective. Here, we introduce a novel mathematical game theory model for jazz improvisation, providing a framework for studying music theory and improvisational methodologies. We use computational modeling, mainly reinforcement learning, to explore diverse stochastic improvisational strategies and their paired performance on improvisation. We find that the most effective strategy pair is a strategy that reacts to the most recent payoff (Stepwise Changes) with a reinforcement learning strategy limited to notes in the given chord (Chord-Following Reinforcement Learning). Conversely, a strategy that reacts to the partner's last note and attempts to harmonize with it (Harmony Prediction) strategy pair yields the lowest non-control payoff and highest standard deviation, indicating that picking notes based on immediate reactions to the partner player can yield inconsistent outcomes. On average, the Chord-Following Reinforcement Learning strategy demonstrates the highest mean payoff, while Harmony Prediction exhibits the lowest. Our work lays the foundation for promising applications beyond jazz: including the use of artificial intelligence (AI) models to extract data from audio clips to refine musical reward systems, and training machine learning (ML) models on existing jazz solos to further refine strategies within the game.
Structuring Concept Space with the Musical Circle of Fifths by Utilizing Music Grammar Based Activations
Feb 22, 2024In this paper, we explore the intriguing similarities between the structure of a discrete neural network, such as a spiking network, and the composition of a piano piece. While both involve nodes or notes that are activated sequentially or in parallel, the latter benefits from the rich body of music theory to guide meaningful combinations. We propose a novel approach that leverages musical grammar to regulate activations in a spiking neural network, allowing for the representation of symbols as attractors. By applying rules for chord progressions from music theory, we demonstrate how certain activations naturally follow others, akin to the concept of attraction. Furthermore, we introduce the concept of modulating keys to navigate different basins of attraction within the network. Ultimately, we show that the map of concepts in our model is structured by the musical circle of fifths, highlighting the potential for leveraging music theory principles in deep learning algorithms.