 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Algorithms of Sampling-Frequency-Independent Layers for Non-integer Strides
Jun 19, 2023

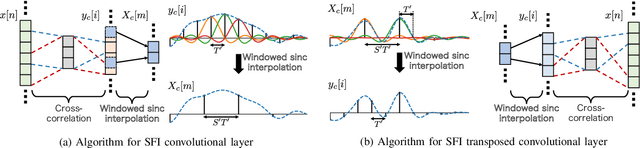
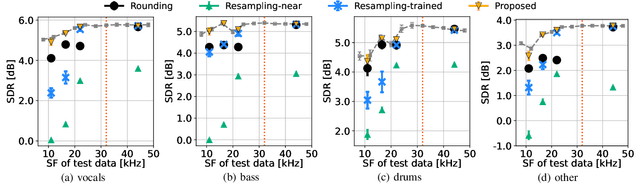

In this paper, we propose algorithms for handling non-integer strides in sampling-frequency-independent (SFI) convolutional and transposed convolutional layers. The SFI layers have been developed for handling various sampling frequencies (SFs) by a single neural network. They are replaceable with their non-SFI counterparts and can be introduced into various network architectures. However, they could not handle some specific configurations when combined with non-SFI layers. For example, an SFI extension of Conv-TasNet, a standard audio source separation model, cannot handle some pairs of trained and target SFs because the strides of the SFI layers become non-integers. This problem cannot be solved by simple rounding or signal resampling, resulting in the significant performance degradation. To overcome this problem, we propose algorithms for handling non-integer strides by using windowed sinc interpolation. The proposed algorithms realize the continuous-time representations of features using the interpolation and enable us to sample instants with the desired stride. Experimental results on music source separation showed that the proposed algorithms outperformed the rounding- and signal-resampling-based methods at SFs lower than the trained SF.
The pop song generator: designing an online course to teach collaborative, creative AI
Jun 15, 2023This article describes and evaluates a new online AI-creativity course. The course is based around three near-state-of-the-art AI models combined into a pop song generating system. A fine-tuned GPT-2 model writes lyrics, Music-VAE composes musical scores and instrumentation and Diffsinger synthesises a singing voice. We explain the decisions made in designing the course which is based on Piagetian, constructivist 'learning-by-doing'. We present details of the five-week course design with learning objectives, technical concepts, and creative and technical activities. We explain how we overcame technical challenges to build a complete pop song generator system, consisting of Python scripts, pre-trained models, and Javascript code that runs in a dockerised Linux container via a web-based IDE. A quantitative analysis of student activity provides evidence on engagement and a benchmark for future improvements. A qualitative analysis of a workshop with experts validated the overall course design, it suggested the need for a stronger creative brief and ethical and legal content.
CoverHunter: Cover Song Identification with Refined Attention and Alignments
Jun 15, 2023
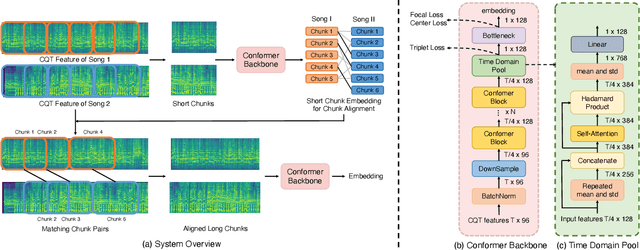
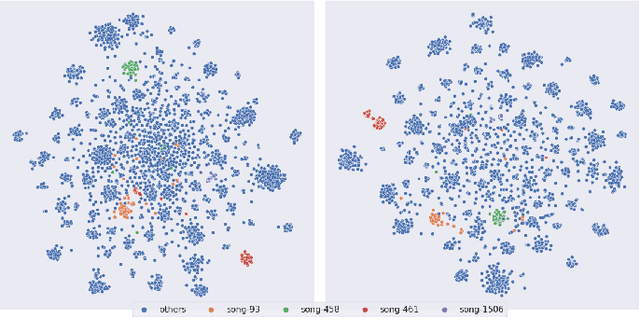
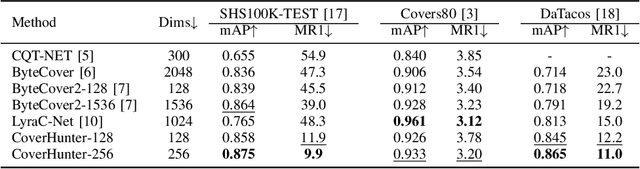
Abstract: Cover song identification (CSI) focuses on finding the same music with different versions in reference anchors given a query track. In this paper, we propose a novel system named CoverHunter that overcomes the shortcomings of existing detection schemes by exploring richer features with refined attention and alignments. CoverHunter contains three key modules: 1) A convolution-augmented transformer (i.e., Conformer) structure that captures both local and global feature interactions in contrast to previous methods mainly relying on convolutional neural networks; 2) An attention-based time pooling module that further exploits the attention in the time dimension; 3) A novel coarse-to-fine training scheme that first trains a network to roughly align the song chunks and then refines the network by training on the aligned chunks. At the same time, we also summarize some important training tricks used in our system that help achieve better results. Experiments on several standard CSI datasets show that our method significantly improves over state-of-the-art methods with an embedding size of 128 (2.3% on SHS100K-TEST and 17.7% on DaTacos).
Music Source Separation with Generative Flow
Apr 19, 2022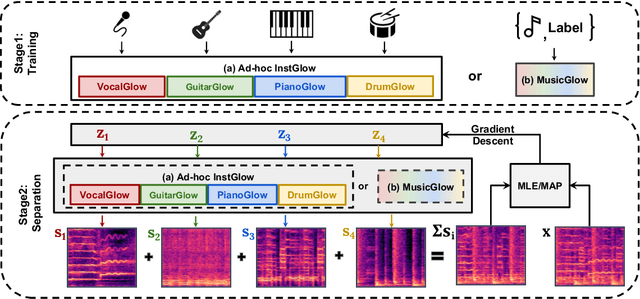
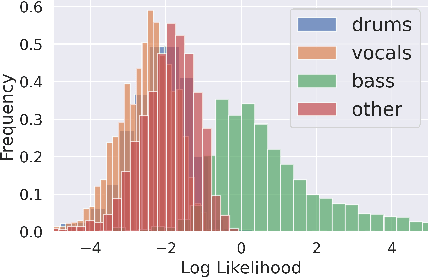
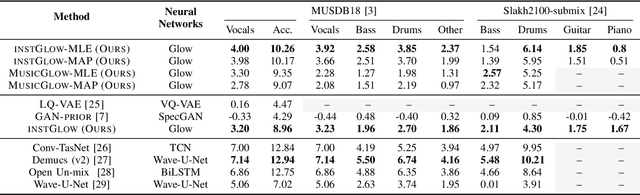
Music source separation with both paired mixed signals and source signals has obtained substantial progress over the years. However, this setting highly relies on large amounts of paired data. Source-only supervision decouples the process of learning a mapping from a mixture to particular sources into a two stage paradigm: source modeling and separation. Recent systems under source-only supervision either achieve good performance in synthetic toy experiments or limited performance in music separation task. In this paper, we leverage flow-based implicit generators to train music source priors and likelihood based objective to separate music mixtures. Experiments show that in singing voice and music separation tasks, our proposed systems achieve competitive results to one of the full supervision systems. We also demonstrate one variant of our proposed systems is capable of separating new source tracks effortlessly.
Large Language and Text-to-3D Models for Engineering Design Optimization
Jul 03, 2023
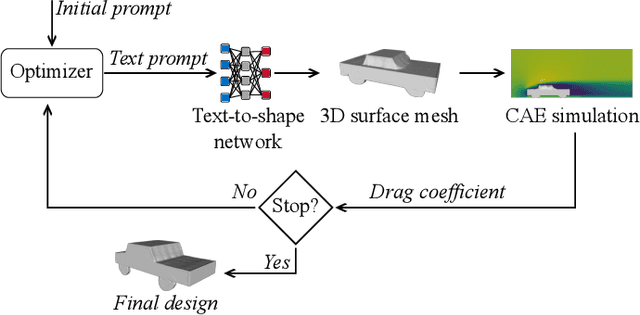
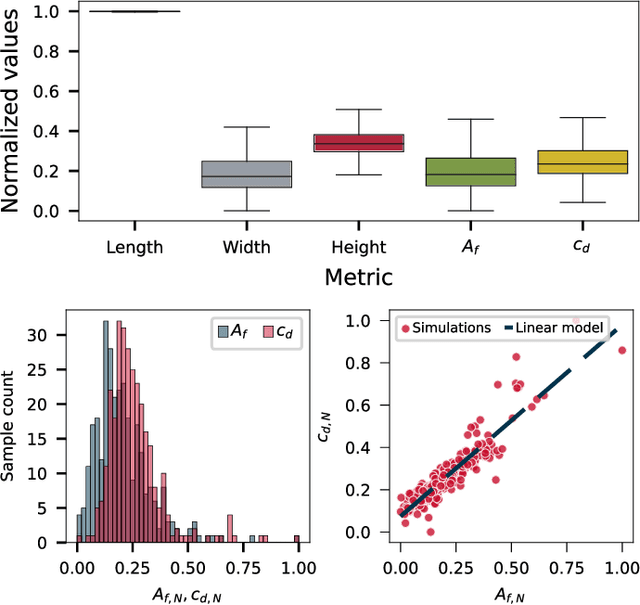

The current advances in generative AI for learning large neural network models with the capability to produce essays, images, music and even 3D assets from text prompts create opportunities for a manifold of disciplines. In the present paper, we study the potential of deep text-to-3D models in the engineering domain, with focus on the chances and challenges when integrating and interacting with 3D assets in computational simulation-based design optimization. In contrast to traditional design optimization of 3D geometries that often searches for the optimum designs using numerical representations, such as B-Spline surface or deformation parameters in vehicle aerodynamic optimization, natural language challenges the optimization framework by requiring a different interpretation of variation operators while at the same time may ease and motivate the human user interaction. Here, we propose and realize a fully automated evolutionary design optimization framework using Shap-E, a recently published text-to-3D asset network by OpenAI, in the context of aerodynamic vehicle optimization. For representing text prompts in the evolutionary optimization, we evaluate (a) a bag-of-words approach based on prompt templates and Wordnet samples, and (b) a tokenisation approach based on prompt templates and the byte pair encoding method from GPT4. Our main findings from the optimizations indicate that, first, it is important to ensure that the designs generated from prompts are within the object class of application, i.e. diverse and novel designs need to be realistic, and, second, that more research is required to develop methods where the strength of text prompt variations and the resulting variations of the 3D designs share causal relations to some degree to improve the optimization.
Automatic Transcription of Drum Strokes in Carnatic Music
Nov 28, 2022
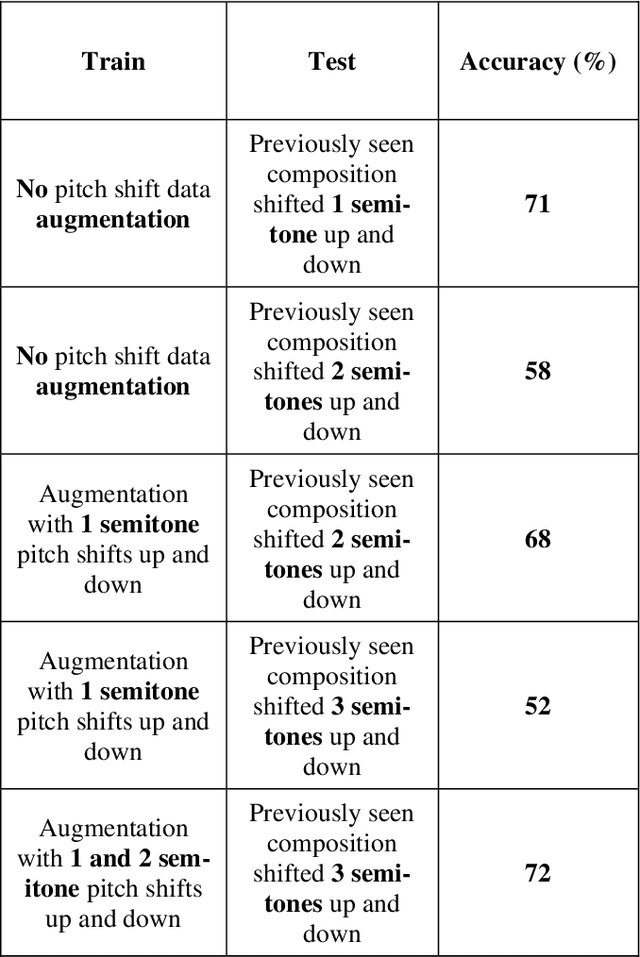
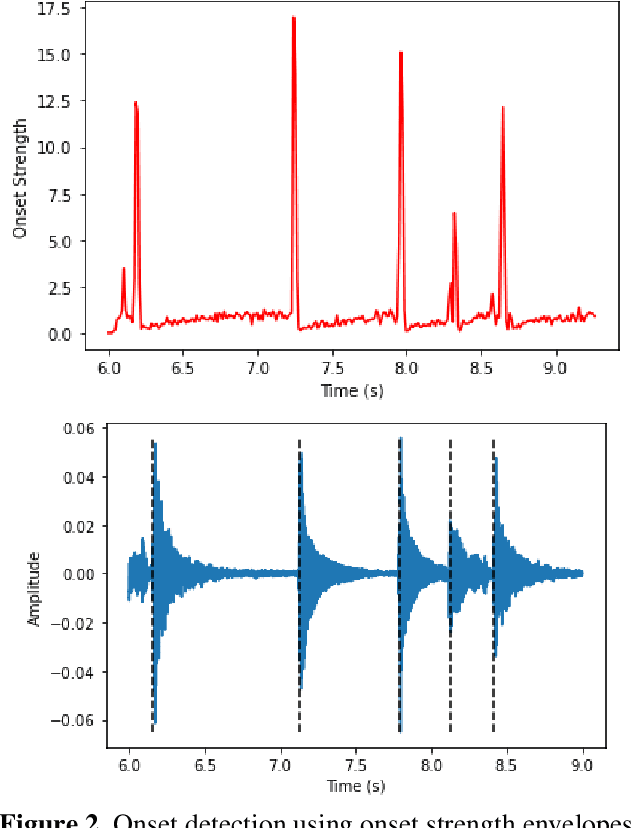
The mridangam is a double-headed percussion instrument that plays a key role in Carnatic music concerts. This paper presents a novel automatic transcription algorithm to classify the strokes played on the mridangam. Onset detection is first performed to segment the audio signal into individual strokes, and feature vectors consisting of the DFT magnitude spectrum of the segmented signal are generated. A multi-layer feedforward neural network is trained using the feature vectors as inputs and the manual transcriptions as targets. Since the mridangam is a tonal instrument tuned to a given tonic, tonic invariance is an important feature of the classifier. Tonic invariance is achieved by augmenting the dataset with pitch-shifted copies of the audio. This algorithm consistently yields over 83% accuracy on a held-out test dataset.
An adaptive music generation architecture for games based on the deep learning Transformer mode
Jul 04, 2022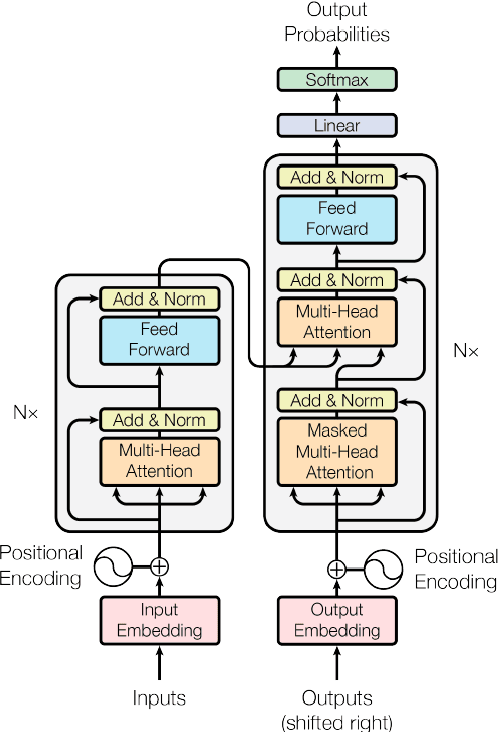
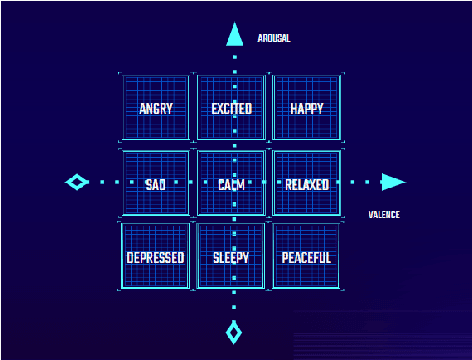
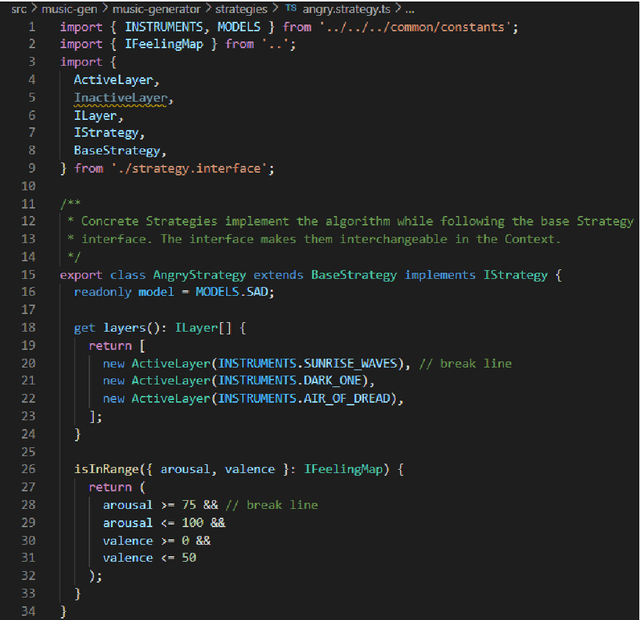
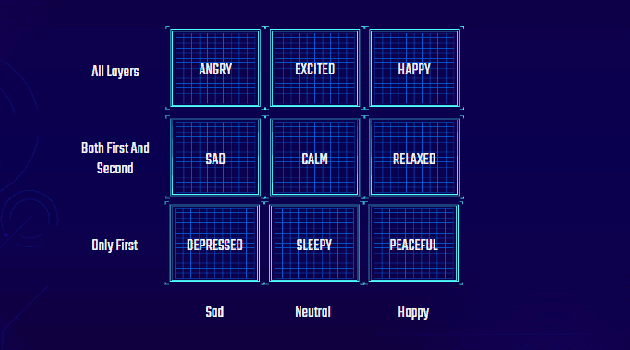
This paper presents an architecture for generating music for video games based on the Transformer deep learning model. The system generates music in various layers, following the standard layering strategy currently used by composers designing video game music. The music is adaptive to the psychological context of the player, according to the arousal-valence model. Our motivation is to customize music according to the player's tastes, who can select his preferred style of music through a set of training examples of music. We discuss current limitations and prospects for the future, such as collaborative and interactive control of the musical components.
ConchShell: A Generative Adversarial Networks that Turns Pictures into Piano Music
Oct 11, 2022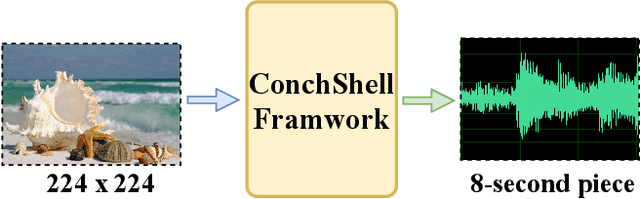

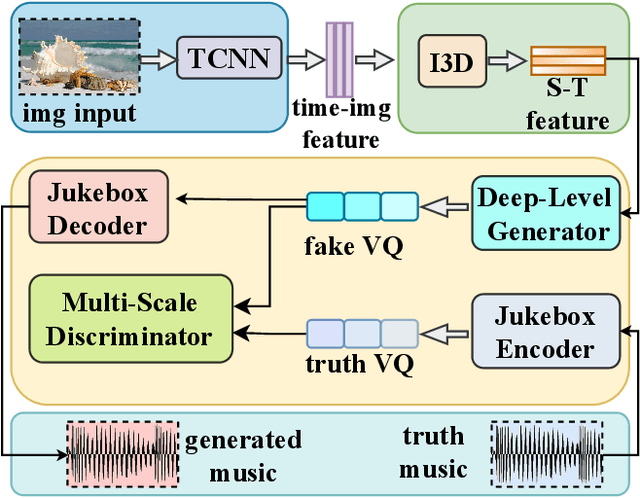
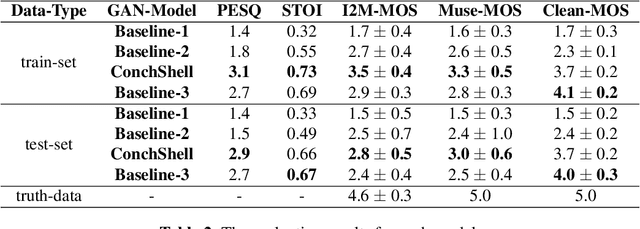
We present ConchShell, a multi-modal generative adversarial framework that takes pictures as input to the network and generates piano music samples that match the picture context. Inspired by I3D, we introduce a novel image feature representation method: time-convolutional neural network (TCNN), which is used to forge features for images in the temporal dimension. Although our image data consists of only six categories, our proposed framework will be innovative and commercially meaningful. The project will provide technical ideas for work such as 3D game voice overs, short-video soundtracks, and real-time generation of metaverse background music.We have also released a new dataset, the Beach-Ocean-Piano Dataset (BOPD) 1, which contains more than 3,000 images and more than 1,500 piano pieces. This dataset will support multimodal image-to-music research.
Tempo vs. Pitch: understanding self-supervised tempo estimation
Apr 14, 2023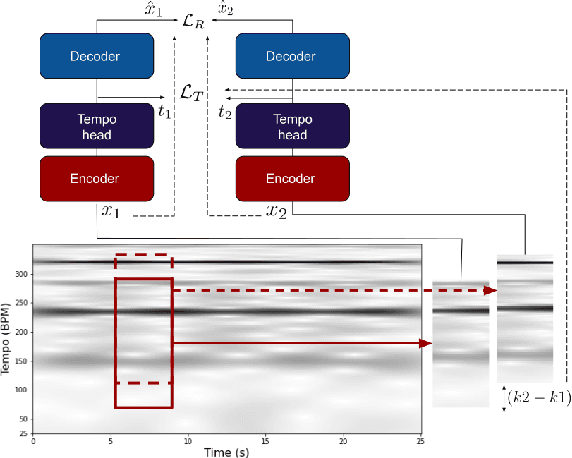
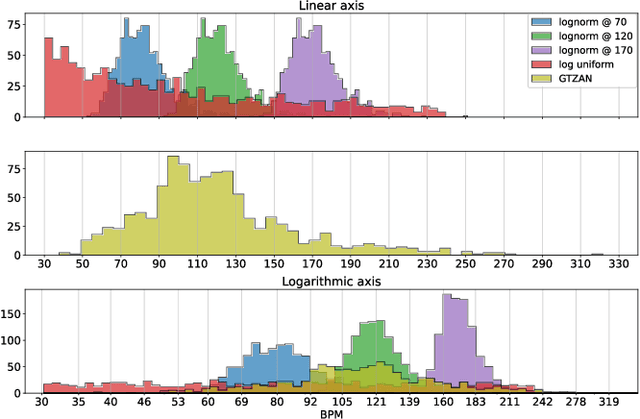
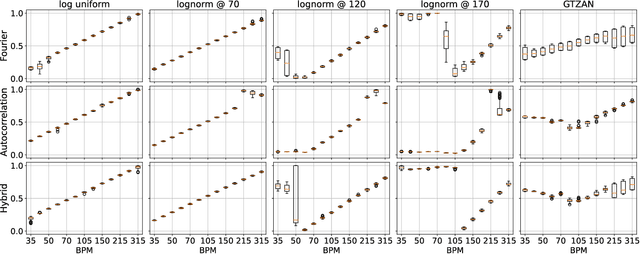
Self-supervision methods learn representations by solving pretext tasks that do not require human-generated labels, alleviating the need for time-consuming annotations. These methods have been applied in computer vision, natural language processing, environmental sound analysis, and recently in music information retrieval, e.g. for pitch estimation. Particularly in the context of music, there are few insights about the fragility of these models regarding different distributions of data, and how they could be mitigated. In this paper, we explore these questions by dissecting a self-supervised model for pitch estimation adapted for tempo estimation via rigorous experimentation with synthetic data. Specifically, we study the relationship between the input representation and data distribution for self-supervised tempo estimation.
A User-Centered Investigation of Personal Music Tours
Aug 16, 2022
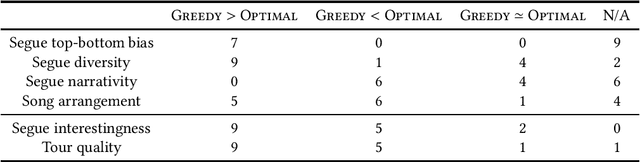
Streaming services use recommender systems to surface the right music to users. Playlists are a popular way to present music in a list-like fashion, ie as a plain list of songs. An alternative are tours, where the songs alternate segues, which explain the connections between consecutive songs. Tours address the user need of seeking background information about songs, and are found to be superior to playlists, given the right user context. In this work, we provide, for the first time, a user-centered evaluation of two tour-generation algorithms (Greedy and Optimal) using semi-structured interviews. We assess the algorithms, we discuss attributes of the tours that the algorithms produce, we identify which attributes are desirable and which are not, and we enumerate several possible improvements to the algorithms, along with practical suggestions on how to implement the improvements. Our main findings are that Greedy generates more likeable tours than Optimal, and that three important attributes of tours are segue diversity, song arrangement and song familiarity. More generally, we provide insights into how to present music to users, which could inform the design of user-centered recommender systems.