 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Online Game Level Generation from Music
Jul 12, 2022
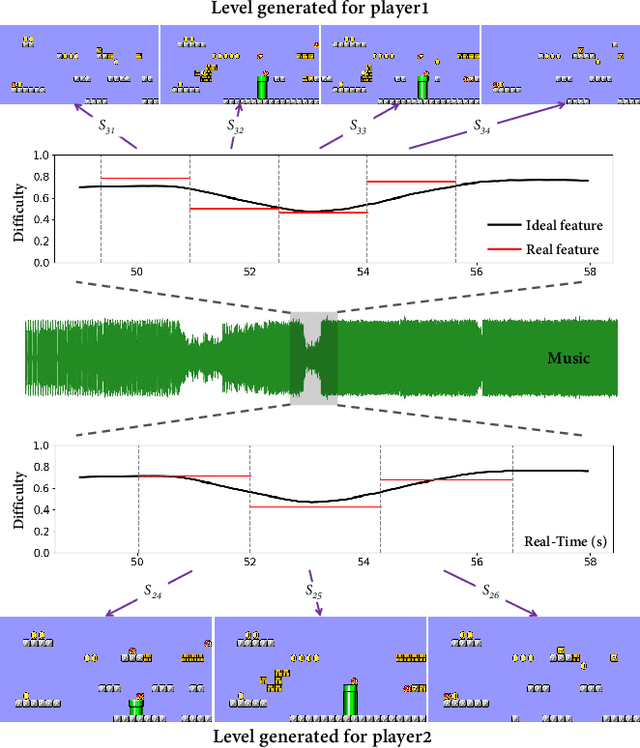
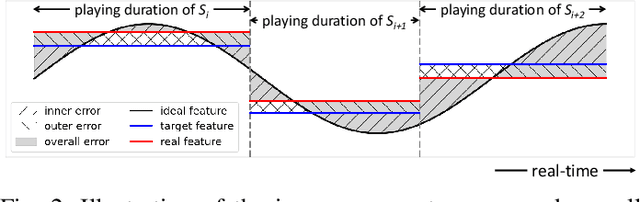
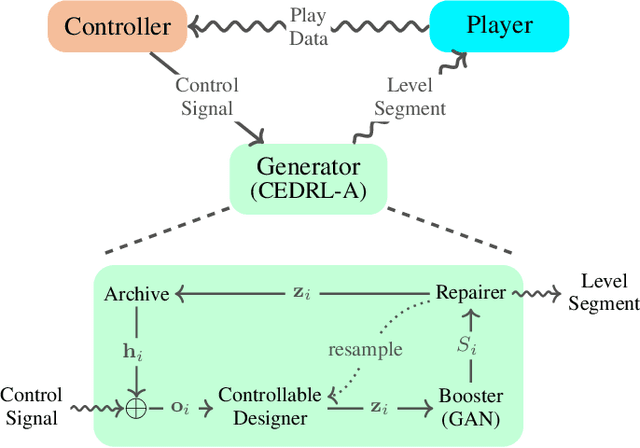
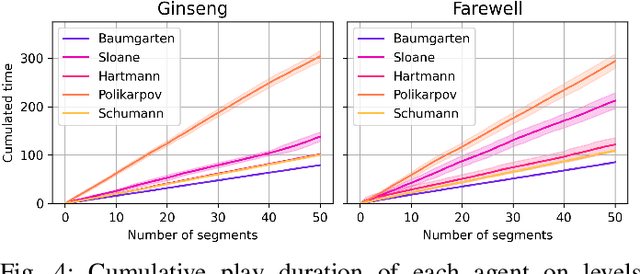
Game consists of multiple types of content, while the harmony of different content types play an essential role in game design. However, most works on procedural content generation consider only one type of content at a time. In this paper, we propose and formulate online level generation from music, in a way of matching a level feature to a music feature in real-time, while adapting to players' play speed. A generic framework named online player-adaptive procedural content generation via reinforcement learning, OPARL for short, is built upon the experience-driven reinforcement learning and controllable reinforcement learning, to enable online level generation from music. Furthermore, a novel control policy based on local search and k-nearest neighbours is proposed and integrated into OPARL to control the level generator considering the play data collected online. Results of simulation-based experiments show that our implementation of OPARL is competent to generate playable levels with difficulty degree matched to the ``energy'' dynamic of music for different artificial players in an online fashion.
A Stakeholder-Centered View on Fairness in Music Recommender Systems
Sep 08, 2022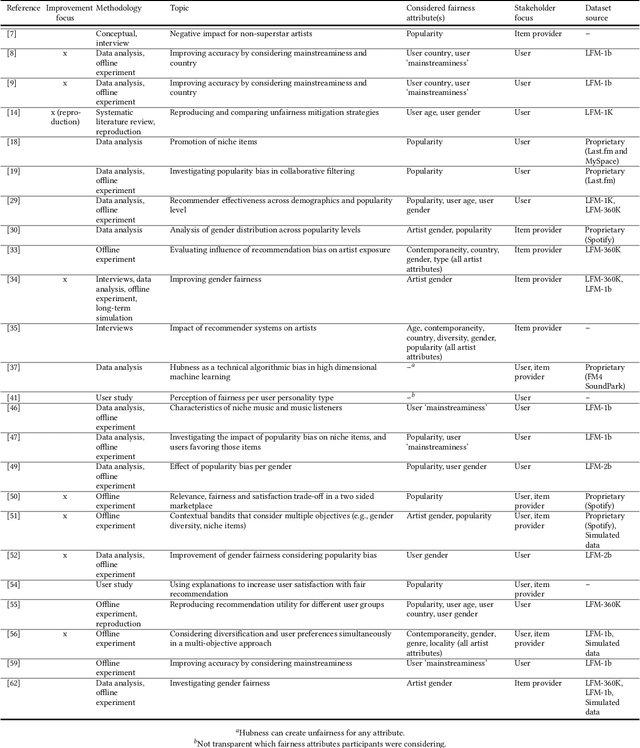
Our narrative literature review acknowledges that, although there is an increasing interest in recommender system fairness in general, the music domain has received relatively little attention in this regard. However, addressing fairness of music recommender systems (MRSs) is highly important because the performance of these systems considerably impacts both the users of music streaming platforms and the artists providing music to those platforms. The distinct needs that these stakeholder groups may have, and the different aspects of fairness that therefore should be considered, make for a challenging research field with ample opportunities for improvement. The review first outlines current literature on MRS fairness from the perspective of each stakeholder and the stakeholders combined, and then identifies promising directions for future research. The two open questions arising from the review are as follows: (i) In the MRS field, only limited data is publicly available to conduct fairness research; most datasets either originate from the same source or are proprietary (and, thus, not widely accessible). How can we address this limited data availability? (ii) Overall, the review shows that the large majority of works analyze the current situation of MRS fairness, whereas only few works propose approaches to improve it. How can we move forward to a focus on improving fairness aspects in these recommender systems? At FAccTRec '22, we emphasize the specifics of addressing RS fairness in the music domain.
* Abstract for FAcctRec 2022 at RecSys 2022, 1 table, main article published in Frontiers in Big Data
SongDriver: Real-time Music Accompaniment Generation without Logical Latency nor Exposure Bias
Sep 13, 2022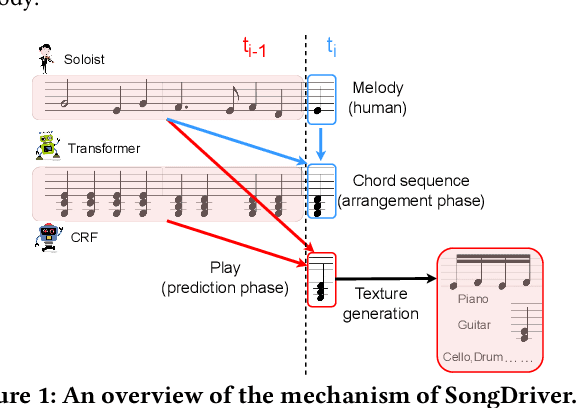
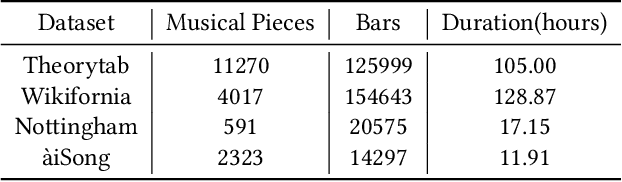
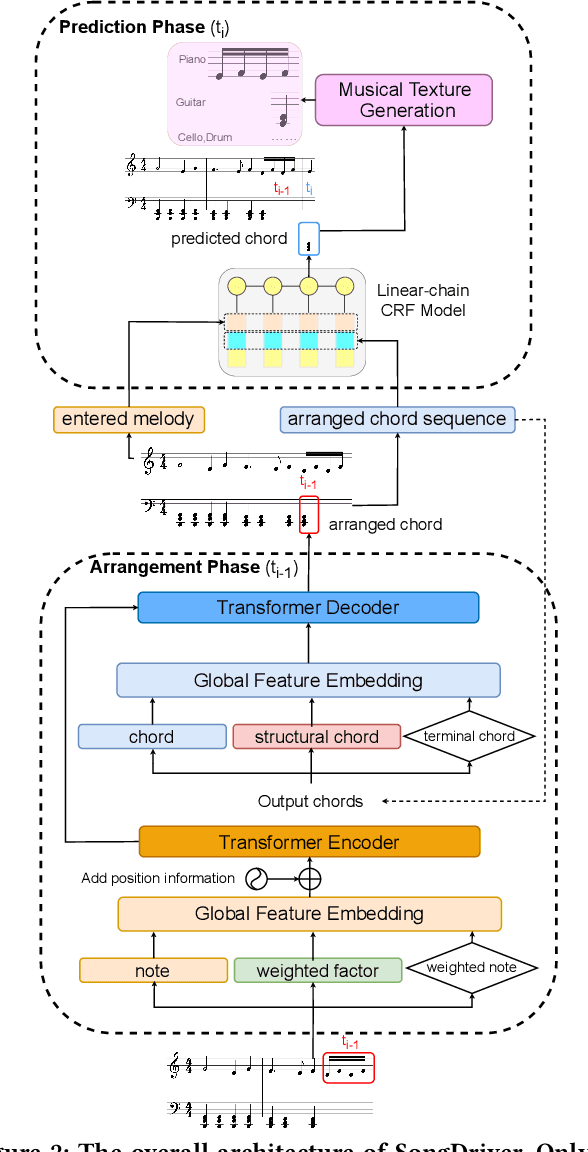
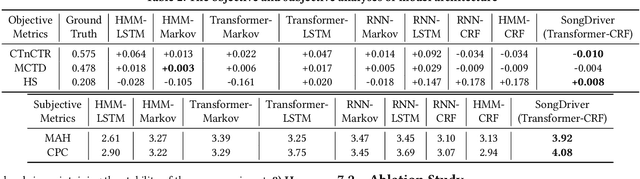
Real-time music accompaniment generation has a wide range of applications in the music industry, such as music education and live performances. However, automatic real-time music accompaniment generation is still understudied and often faces a trade-off between logical latency and exposure bias. In this paper, we propose SongDriver, a real-time music accompaniment generation system without logical latency nor exposure bias. Specifically, SongDriver divides one accompaniment generation task into two phases: 1) The arrangement phase, where a Transformer model first arranges chords for input melodies in real-time, and caches the chords for the next phase instead of playing them out. 2) The prediction phase, where a CRF model generates playable multi-track accompaniments for the coming melodies based on previously cached chords. With this two-phase strategy, SongDriver directly generates the accompaniment for the upcoming melody, achieving zero logical latency. Furthermore, when predicting chords for a timestep, SongDriver refers to the cached chords from the first phase rather than its previous predictions, which avoids the exposure bias problem. Since the input length is often constrained under real-time conditions, another potential problem is the loss of long-term sequential information. To make up for this disadvantage, we extract four musical features from a long-term music piece before the current time step as global information. In the experiment, we train SongDriver on some open-source datasets and an original \`aiSong Dataset built from Chinese-style modern pop music scores. The results show that SongDriver outperforms existing SOTA (state-of-the-art) models on both objective and subjective metrics, meanwhile significantly reducing the physical latency.
Video Background Music Generation with Controllable Music Transformer
Nov 16, 2021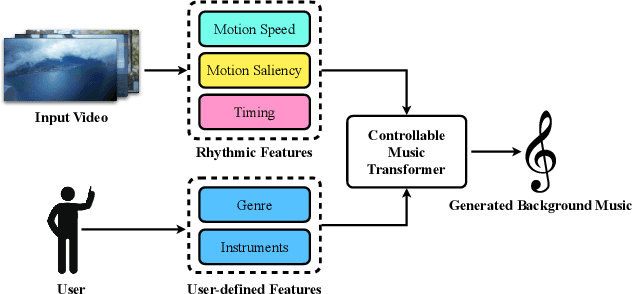
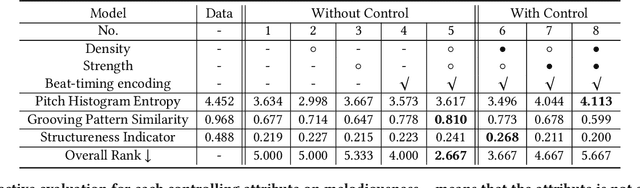
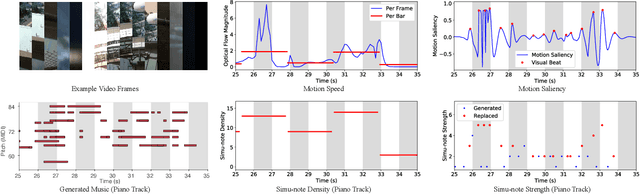
In this work, we address the task of video background music generation. Some previous works achieve effective music generation but are unable to generate melodious music tailored to a particular video, and none of them considers the video-music rhythmic consistency. To generate the background music that matches the given video, we first establish the rhythmic relations between video and background music. In particular, we connect timing, motion speed, and motion saliency from video with beat, simu-note density, and simu-note strength from music, respectively. We then propose CMT, a Controllable Music Transformer that enables local control of the aforementioned rhythmic features and global control of the music genre and instruments. Objective and subjective evaluations show that the generated background music has achieved satisfactory compatibility with the input videos, and at the same time, impressive music quality. Code and models are available at https://github.com/wzk1015/video-bgm-generation.
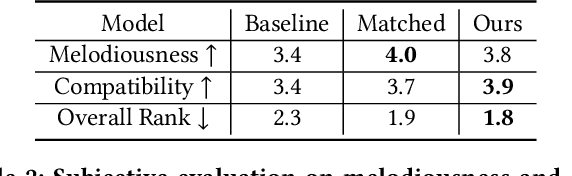
Automatic music mixing with deep learning and out-of-domain data
Aug 24, 2022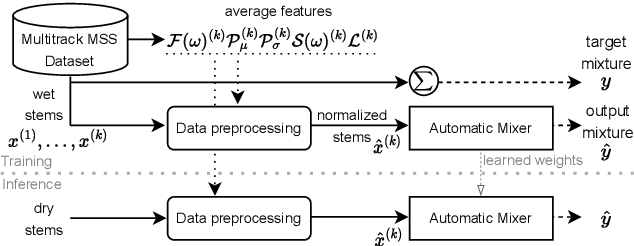
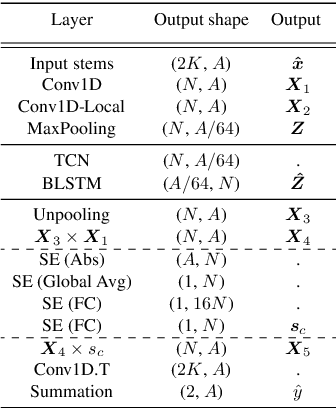

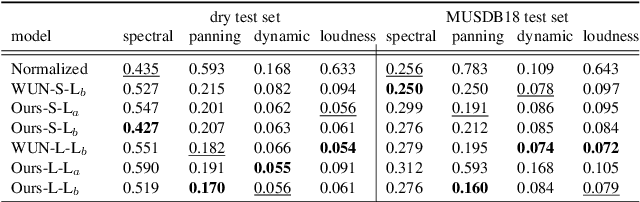
Music mixing traditionally involves recording instruments in the form of clean, individual tracks and blending them into a final mixture using audio effects and expert knowledge (e.g., a mixing engineer). The automation of music production tasks has become an emerging field in recent years, where rule-based methods and machine learning approaches have been explored. Nevertheless, the lack of dry or clean instrument recordings limits the performance of such models, which is still far from professional human-made mixes. We explore whether we can use out-of-domain data such as wet or processed multitrack music recordings and repurpose it to train supervised deep learning models that can bridge the current gap in automatic mixing quality. To achieve this we propose a novel data preprocessing method that allows the models to perform automatic music mixing. We also redesigned a listening test method for evaluating music mixing systems. We validate our results through such subjective tests using highly experienced mixing engineers as participants.
Metamathematics of Algorithmic Composition
May 24, 2023This essay recounts my personal journey towards a deeper understanding of the mathematical foundations of algorithmic music composition. I do not spend much time on specific mathematical algorithms used by composers; rather, I focus on general issues such as fundamental limits and possibilities, by analogy with metalogic, metamathematics, and computability theory. I discuss implications from these foundations for the future of algorithmic composition.
Debiased Cross-modal Matching for Content-based Micro-video Background Music Recommendation
Aug 07, 2022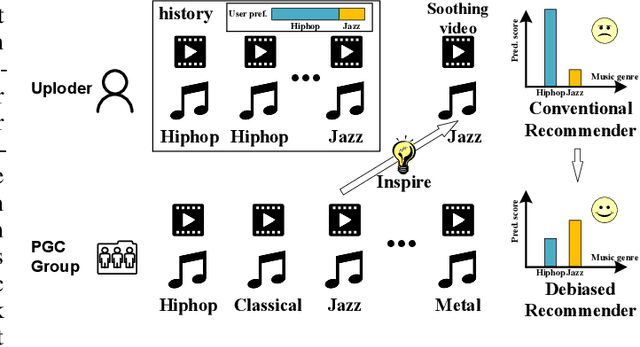
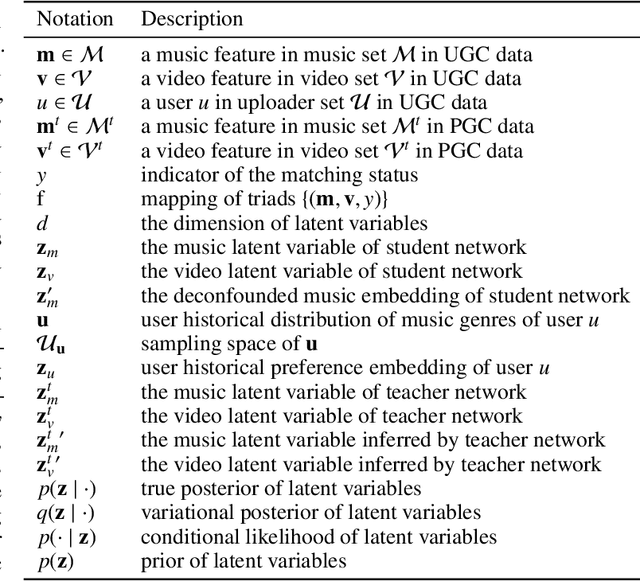
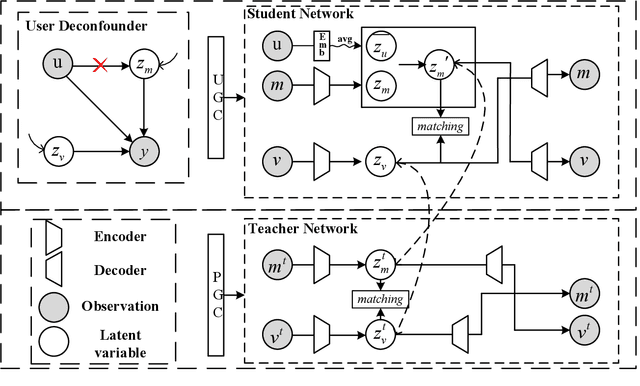

Micro-video background music recommendation is a complicated task where the matching degree between videos and uploader-selected background music is a major issue. However, the selection of the user-generated content (UGC) is biased caused by knowledge limitations and historical preferences among music of each uploader. In this paper, we propose a Debiased Cross-Modal (DebCM) matching model to alleviate the influence of such selection bias. Specifically, we design a teacher-student network to utilize the matching of segments of music videos, which is professional-generated content (PGC) with specialized music-matching techniques, to better alleviate the bias caused by insufficient knowledge of users. The PGC data is captured by a teacher network to guide the matching of uploader-selected UGC data of the student network by KL-based knowledge transfer. In addition, uploaders' personal preferences of music genres are identified as confounders that spuriously correlate music embeddings and background music selections, resulting in the learned recommender system to over-recommend music from the majority groups. To resolve such confounders in the UGC data of the student network, backdoor adjustment is utilized to deconfound the spurious correlation between music embeddings and prediction scores. We further utilize Monte Carlo (MC) estimator with batch-level average as the approximations to avoid integrating the entire confounder space calculated by the adjustment. Extensive experiments on the TT-150k-genre dataset demonstrate the effectiveness of the proposed method towards the selection bias. The code is publicly available on: \url{https://github.com/jing-1/DebCM}.
Multi-scale temporal-frequency attention for music source separation
Sep 02, 2022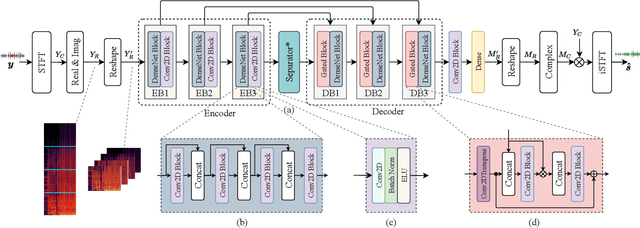
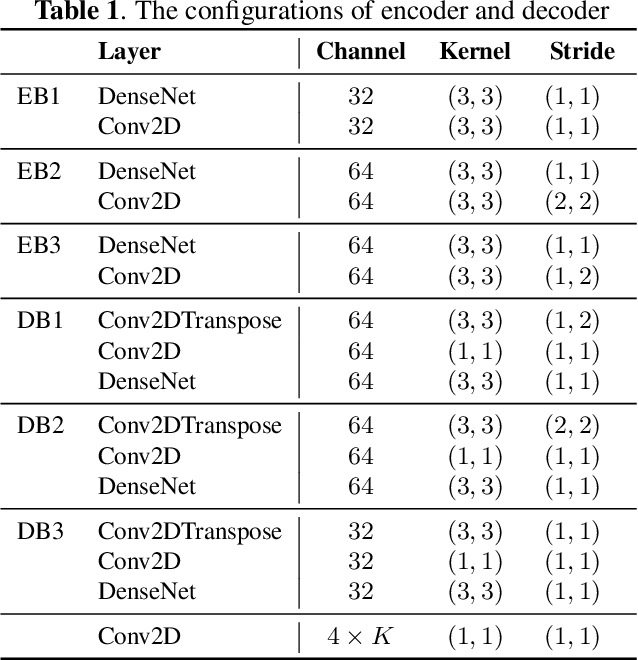
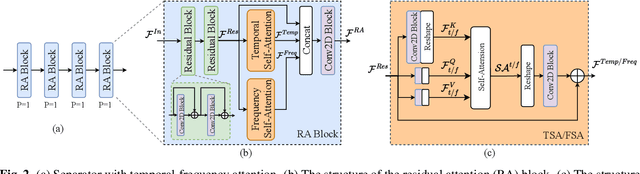
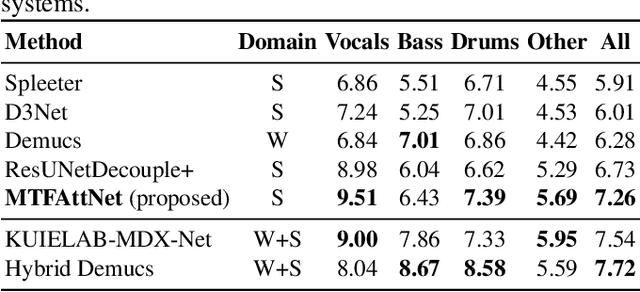
In recent years, deep neural networks (DNNs) based approaches have achieved the start-of-the-art performance for music source separation (MSS). Although previous methods have addressed the large receptive field modeling using various methods, the temporal and frequency correlations of the music spectrogram with repeated patterns have not been explicitly explored for the MSS task. In this paper, a temporal-frequency attention module is proposed to model the spectrogram correlations along both temporal and frequency dimensions. Moreover, a multi-scale attention is proposed to effectively capture the correlations for music signal. The experimental results on MUSDB18 dataset show that the proposed method outperforms the existing state-of-the-art systems with 9.51 dB signal-to-distortion ratio (SDR) on separating the vocal stems, which is the primary practical application of MSS.
Psychologically-Inspired Music Recommendation System
May 06, 2022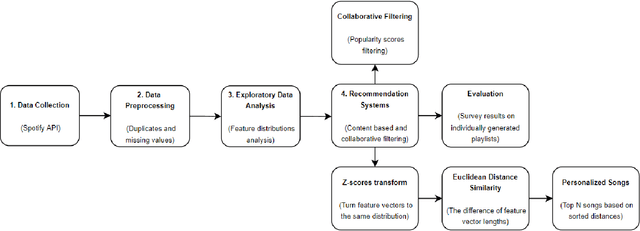
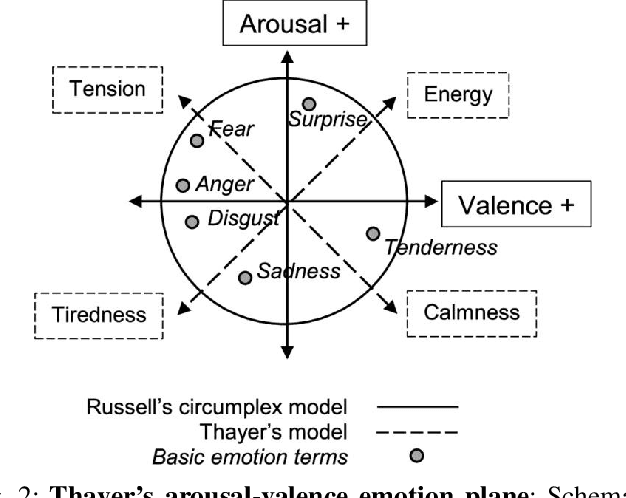

In the last few years, automated recommendation systems have been a major focus in the music field, where companies such as Spotify, Amazon, and Apple are competing in the ability to generate the most personalized music suggestions for their users. One of the challenges developers still fail to tackle is taking into account the psychological and emotional aspects of the music. Our goal is to find a way to integrate users' personal traits and their current emotional state into a single music recommendation system with both collaborative and content-based filtering. We seek to relate the personality and the current emotional state of the listener to the audio features in order to build an emotion-aware MRS. We compare the results both quantitatively and qualitatively to the output of the traditional MRS based on the Spotify API data to understand if our advancements make a significant impact on the quality of music recommendations.
Exploiting Negative Preference in Content-based Music Recommendation with Contrastive Learning
Jul 28, 2022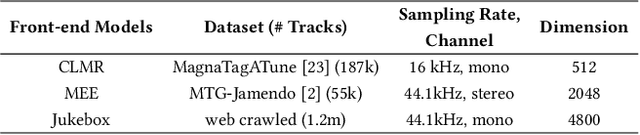
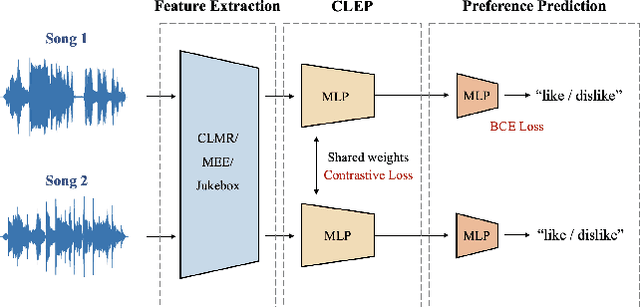
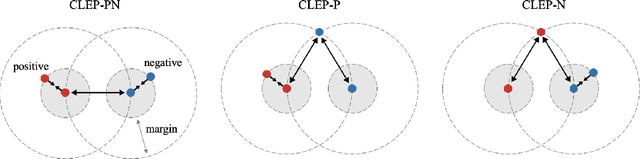
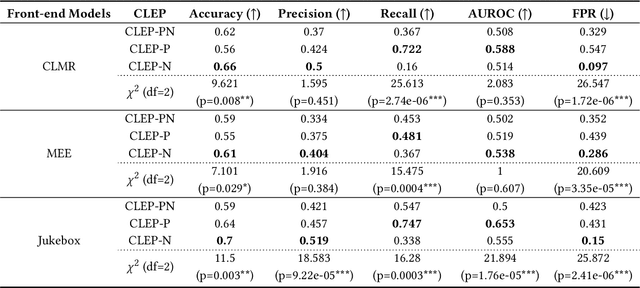
Advanced music recommendation systems are being introduced along with the development of machine learning. However, it is essential to design a music recommendation system that can increase user satisfaction by understanding users' music tastes, not by the complexity of models. Although several studies related to music recommendation systems exploiting negative preferences have shown performance improvements, there was a lack of explanation on how they led to better recommendations. In this work, we analyze the role of negative preference in users' music tastes by comparing music recommendation models with contrastive learning exploiting preference (CLEP) but with three different training strategies - exploiting preferences of both positive and negative (CLEP-PN), positive only (CLEP-P), and negative only (CLEP-N). We evaluate the effectiveness of the negative preference by validating each system with a small amount of personalized data obtained via survey and further illuminate the possibility of exploiting negative preference in music recommendations. Our experimental results show that CLEP-N outperforms the other two in accuracy and false positive rate. Furthermore, the proposed training strategies produced a consistent tendency regardless of different types of front-end musical feature extractors, proving the stability of the proposed method.