 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
A Study on Broadcast Networks for Music Genre Classification
Aug 25, 2022
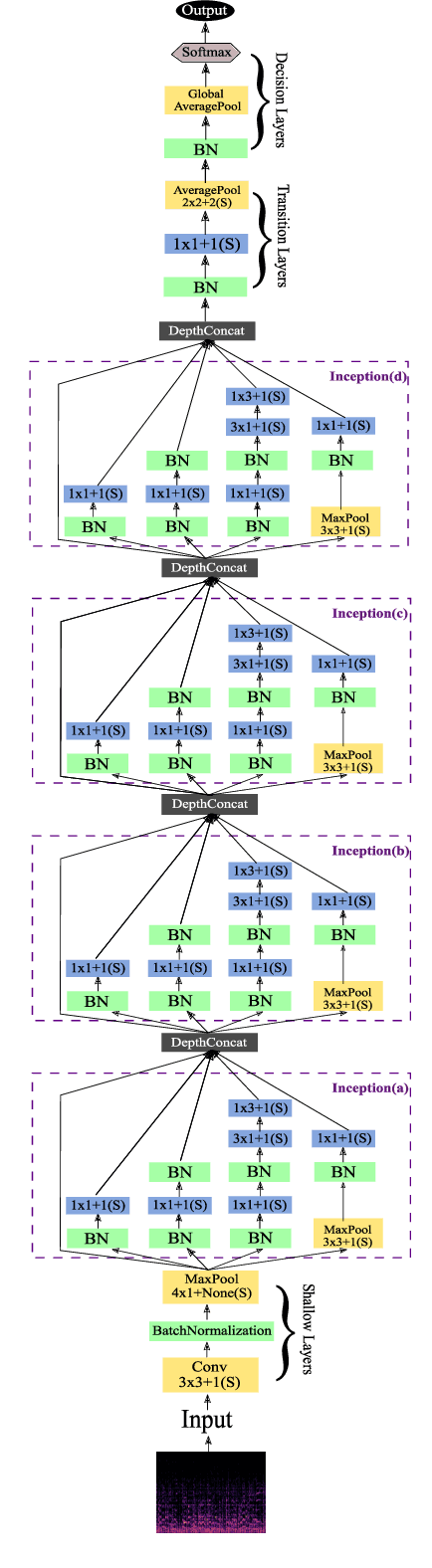
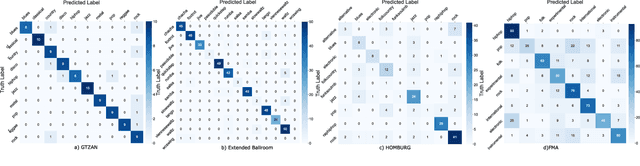
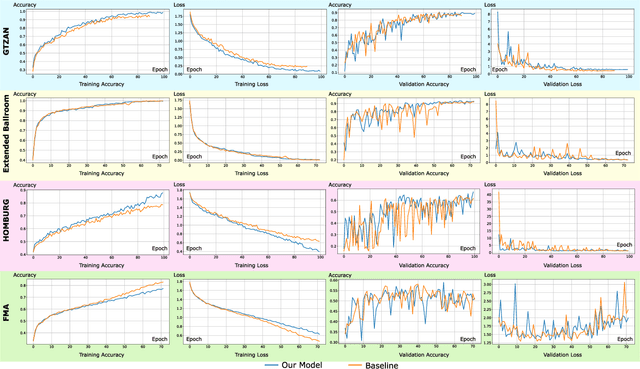
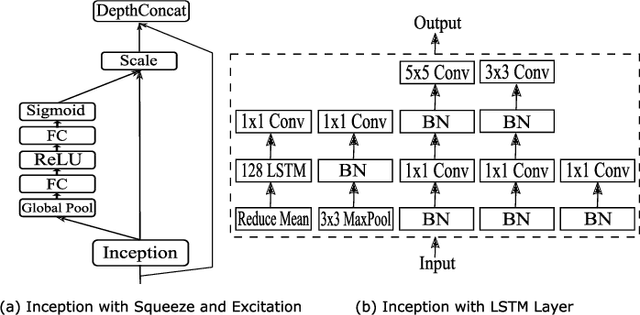
Due to the increased demand for music streaming/recommender services and the recent developments of music information retrieval frameworks, Music Genre Classification (MGC) has attracted the community's attention. However, convolutional-based approaches are known to lack the ability to efficiently encode and localize temporal features. In this paper, we study the broadcast-based neural networks aiming to improve the localization and generalizability under a small set of parameters (about 180k) and investigate twelve variants of broadcast networks discussing the effect of block configuration, pooling method, activation function, normalization mechanism, label smoothing, channel interdependency, LSTM block inclusion, and variants of inception schemes. Our computational experiments using relevant datasets such as GTZAN, Extended Ballroom, HOMBURG, and Free Music Archive (FMA) show state-of-the-art classification accuracies in Music Genre Classification. Our approach offers insights and the potential to enable compact and generalizable broadcast networks for music and audio classification.
RAWIW: RAW Image Watermarking Robust to ISP Pipeline
Jul 28, 2023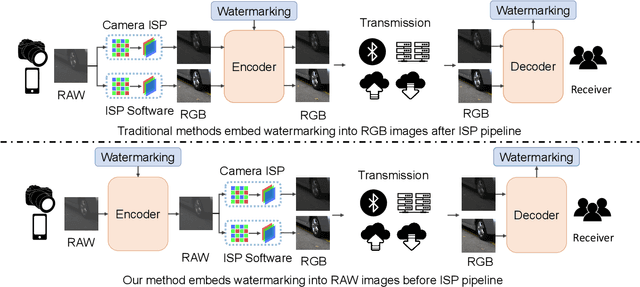
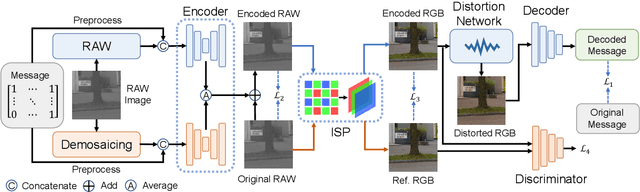


Invisible image watermarking is essential for image copyright protection. Compared to RGB images, RAW format images use a higher dynamic range to capture the radiometric characteristics of the camera sensor, providing greater flexibility in post-processing and retouching. Similar to the master recording in the music industry, RAW images are considered the original format for distribution and image production, thus requiring copyright protection. Existing watermarking methods typically target RGB images, leaving a gap for RAW images. To address this issue, we propose the first deep learning-based RAW Image Watermarking (RAWIW) framework for copyright protection. Unlike RGB image watermarking, our method achieves cross-domain copyright protection. We directly embed copyright information into RAW images, which can be later extracted from the corresponding RGB images generated by different post-processing methods. To achieve end-to-end training of the framework, we integrate a neural network that simulates the ISP pipeline to handle the RAW-to-RGB conversion process. To further validate the generalization of our framework to traditional ISP pipelines and its robustness to transmission distortion, we adopt a distortion network. This network simulates various types of noises introduced during the traditional ISP pipeline and transmission. Furthermore, we employ a three-stage training strategy to strike a balance between robustness and concealment of watermarking. Our extensive experiments demonstrate that RAWIW successfully achieves cross-domain copyright protection for RAW images while maintaining their visual quality and robustness to ISP pipeline distortions.
Contrastive Audio-Language Learning for Music
Aug 25, 2022

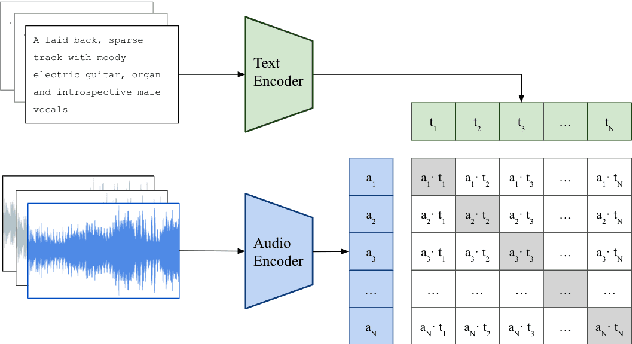
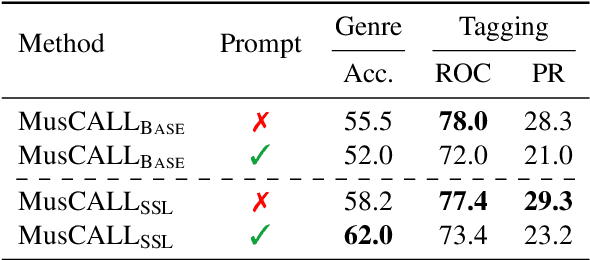
As one of the most intuitive interfaces known to humans, natural language has the potential to mediate many tasks that involve human-computer interaction, especially in application-focused fields like Music Information Retrieval. In this work, we explore cross-modal learning in an attempt to bridge audio and language in the music domain. To this end, we propose MusCALL, a framework for Music Contrastive Audio-Language Learning. Our approach consists of a dual-encoder architecture that learns the alignment between pairs of music audio and descriptive sentences, producing multimodal embeddings that can be used for text-to-audio and audio-to-text retrieval out-of-the-box. Thanks to this property, MusCALL can be transferred to virtually any task that can be cast as text-based retrieval. Our experiments show that our method performs significantly better than the baselines at retrieving audio that matches a textual description and, conversely, text that matches an audio query. We also demonstrate that the multimodal alignment capability of our model can be successfully extended to the zero-shot transfer scenario for genre classification and auto-tagging on two public datasets.
HCLAS-X: Hierarchical and Cascaded Lyrics Alignment System Using Multimodal Cross-Correlation
Jul 10, 2023In this work, we address the challenge of lyrics alignment, which involves aligning the lyrics and vocal components of songs. This problem requires the alignment of two distinct modalities, namely text and audio. To overcome this challenge, we propose a model that is trained in a supervised manner, utilizing the cross-correlation matrix of latent representations between vocals and lyrics. Our system is designed in a hierarchical and cascaded manner. It predicts synced time first on a sentence-level and subsequently on a word-level. This design enables the system to process long sequences, as the cross-correlation uses quadratic memory with respect to sequence length. In our experiments, we demonstrate that our proposed system achieves a significant improvement in mean average error, showcasing its robustness in comparison to the previous state-of-the-art model. Additionally, we conduct a qualitative analysis of the system after successfully deploying it in several music streaming services.
WavJourney: Compositional Audio Creation with Large Language Models
Jul 26, 2023Large Language Models (LLMs) have shown great promise in integrating diverse expert models to tackle intricate language and vision tasks. Despite their significance in advancing the field of Artificial Intelligence Generated Content (AIGC), their potential in intelligent audio content creation remains unexplored. In this work, we tackle the problem of creating audio content with storylines encompassing speech, music, and sound effects, guided by text instructions. We present WavJourney, a system that leverages LLMs to connect various audio models for audio content generation. Given a text description of an auditory scene, WavJourney first prompts LLMs to generate a structured script dedicated to audio storytelling. The audio script incorporates diverse audio elements, organized based on their spatio-temporal relationships. As a conceptual representation of audio, the audio script provides an interactive and interpretable rationale for human engagement. Afterward, the audio script is fed into a script compiler, converting it into a computer program. Each line of the program calls a task-specific audio generation model or computational operation function (e.g., concatenate, mix). The computer program is then executed to obtain an explainable solution for audio generation. We demonstrate the practicality of WavJourney across diverse real-world scenarios, including science fiction, education, and radio play. The explainable and interactive design of WavJourney fosters human-machine co-creation in multi-round dialogues, enhancing creative control and adaptability in audio production. WavJourney audiolizes the human imagination, opening up new avenues for creativity in multimedia content creation.
Transfer Learning and Bias Correction with Pre-trained Audio Embeddings
Jul 20, 2023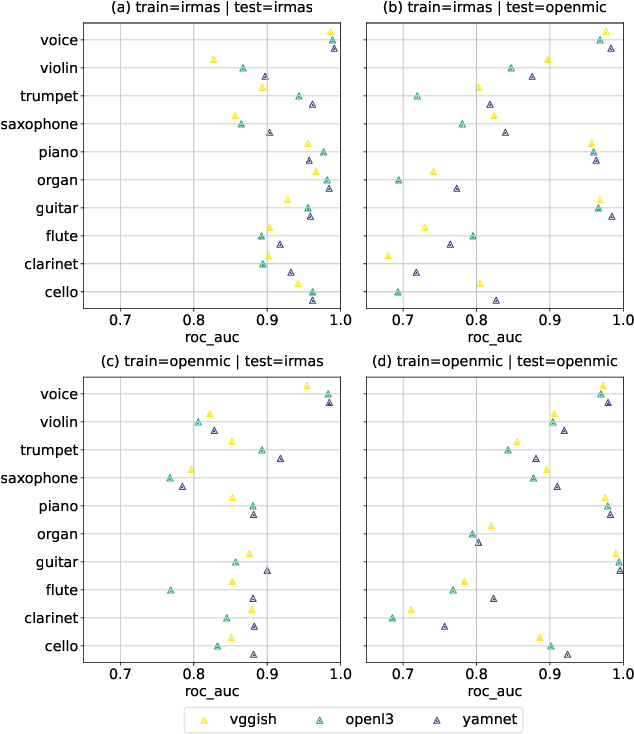
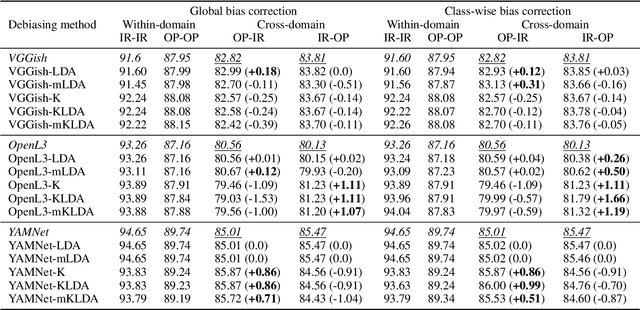
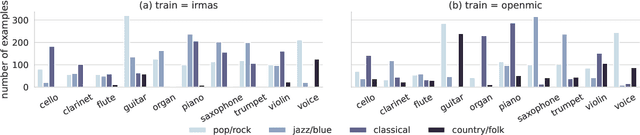
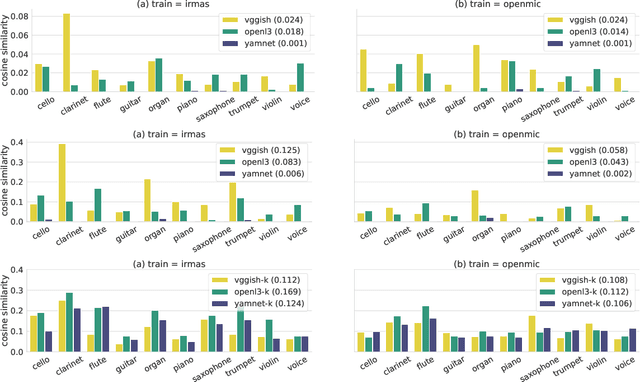
Deep neural network models have become the dominant approach to a large variety of tasks within music information retrieval (MIR). These models generally require large amounts of (annotated) training data to achieve high accuracy. Because not all applications in MIR have sufficient quantities of training data, it is becoming increasingly common to transfer models across domains. This approach allows representations derived for one task to be applied to another, and can result in high accuracy with less stringent training data requirements for the downstream task. However, the properties of pre-trained audio embeddings are not fully understood. Specifically, and unlike traditionally engineered features, the representations extracted from pre-trained deep networks may embed and propagate biases from the model's training regime. This work investigates the phenomenon of bias propagation in the context of pre-trained audio representations for the task of instrument recognition. We first demonstrate that three different pre-trained representations (VGGish, OpenL3, and YAMNet) exhibit comparable performance when constrained to a single dataset, but differ in their ability to generalize across datasets (OpenMIC and IRMAS). We then investigate dataset identity and genre distribution as potential sources of bias. Finally, we propose and evaluate post-processing countermeasures to mitigate the effects of bias, and improve generalization across datasets.
MATT: A Multiple-instance Attention Mechanism for Long-tail Music Genre Classification
Sep 09, 2022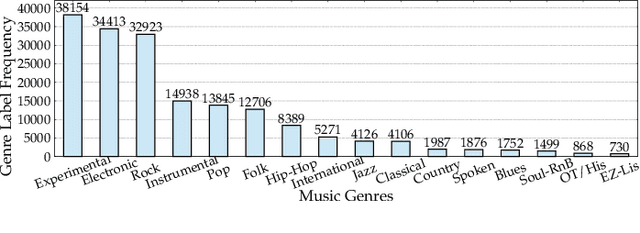
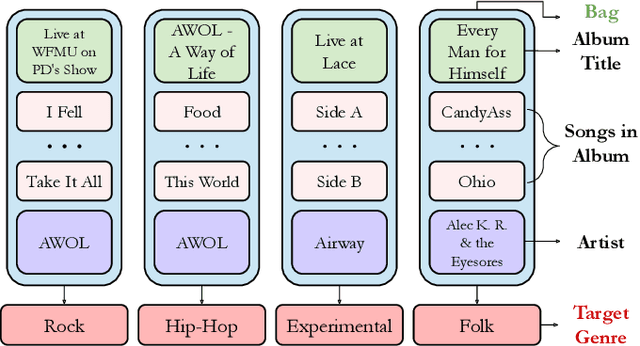
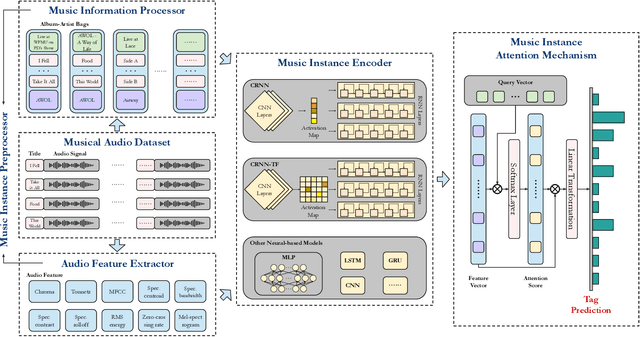
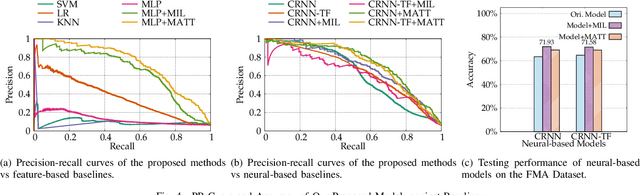
Imbalanced music genre classification is a crucial task in the Music Information Retrieval (MIR) field for identifying the long-tail, data-poor genre based on the related music audio segments, which is very prevalent in real-world scenarios. Most of the existing models are designed for class-balanced music datasets, resulting in poor performance in accuracy and generalization when identifying the music genres at the tail of the distribution. Inspired by the success of introducing Multi-instance Learning (MIL) in various classification tasks, we propose a novel mechanism named Multi-instance Attention (MATT) to boost the performance for identifying tail classes. Specifically, we first construct the bag-level datasets by generating the album-artist pair bags. Second, we leverage neural networks to encode the music audio segments. Finally, under the guidance of a multi-instance attention mechanism, the neural network-based models could select the most informative genre to match the given music segment. Comprehensive experimental results on a large-scale music genre benchmark dataset with long-tail distribution demonstrate MATT significantly outperforms other state-of-the-art baselines.
Sound Design Strategies for Latent Audio Space Explorations Using Deep Learning Architectures
May 24, 2023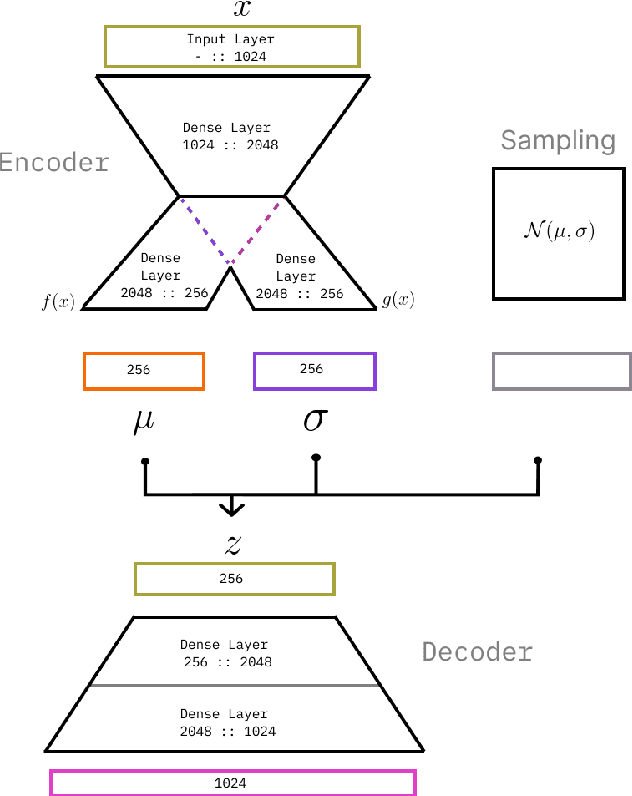
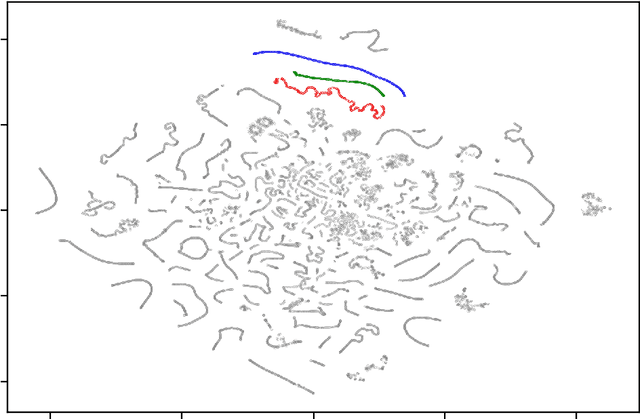

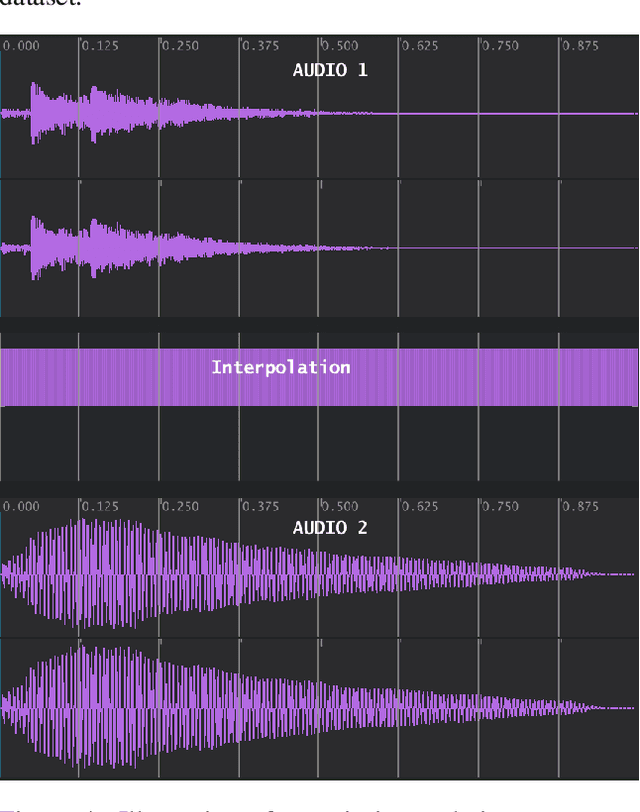
The research in Deep Learning applications in sound and music computing have gathered an interest in the recent years; however, there is still a missing link between these new technologies and on how they can be incorporated into real-world artistic practices. In this work, we explore a well-known Deep Learning architecture called Variational Autoencoders (VAEs). These architectures have been used in many areas for generating latent spaces where data points are organized so that similar data points locate closer to each other. Previously, VAEs have been used for generating latent timbre spaces or latent spaces of symbolic music excepts. Applying VAE to audio features of timbre requires a vocoder to transform the timbre generated by the network to an audio signal, which is computationally expensive. In this work, we apply VAEs to raw audio data directly while bypassing audio feature extraction. This approach allows the practitioners to use any audio recording while giving flexibility and control over the aesthetics through dataset curation. The lower computation time in audio signal generation allows the raw audio approach to be incorporated into real-time applications. In this work, we propose three strategies to explore latent spaces of audio and timbre for sound design applications. By doing so, our aim is to initiate a conversation on artistic approaches and strategies to utilize latent audio spaces in sound and music practices.
Symbolic Music Loop Generation with Neural Discrete Representations
Aug 11, 2022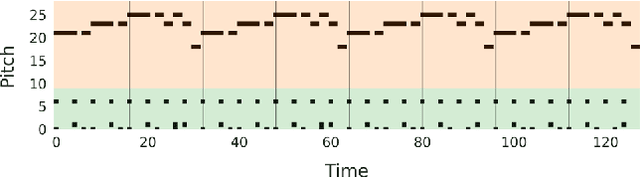

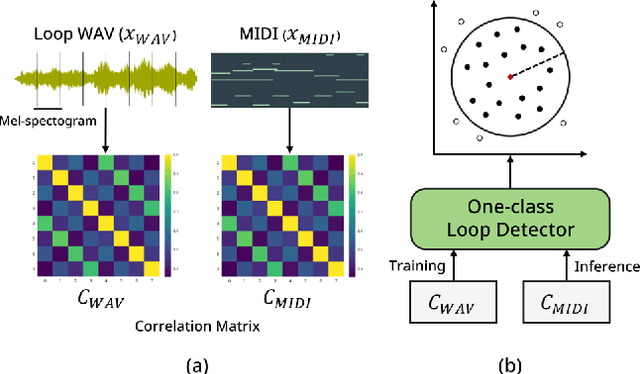
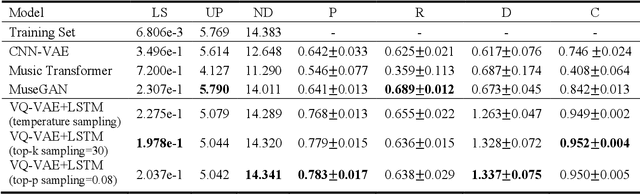
Since most of music has repetitive structures from motifs to phrases, repeating musical ideas can be a basic operation for music composition. The basic block that we focus on is conceptualized as loops which are essential ingredients of music. Furthermore, meaningful note patterns can be formed in a finite space, so it is sufficient to represent them with combinations of discrete symbols as done in other domains. In this work, we propose symbolic music loop generation via learning discrete representations. We first extract loops from MIDI datasets using a loop detector and then learn an autoregressive model trained by discrete latent codes of the extracted loops. We show that our model outperforms well-known music generative models in terms of both fidelity and diversity, evaluating on random space. Our code and supplementary materials are available at https://github.com/sjhan91/Loop_VQVAE_Official.
Discovery Dynamics: Leveraging Repeated Exposure for User and Music Characterization
Oct 28, 2022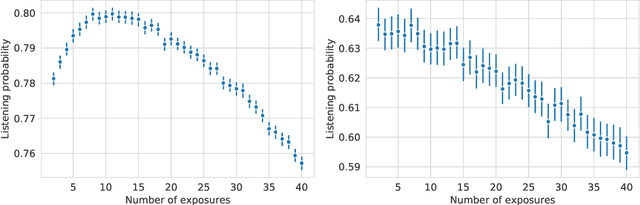
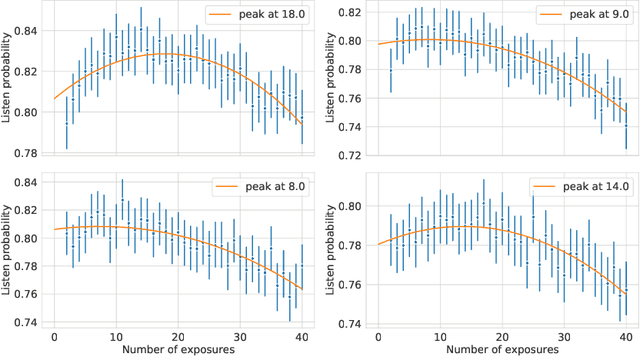
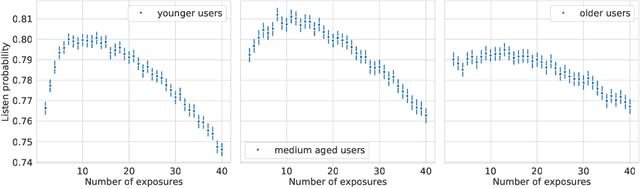
Repetition in music consumption is a common phenomenon. It is notably more frequent when compared to the consumption of other media, such as books and movies. In this paper, we show that one particularly interesting repetitive behavior arises when users are consuming new items. Users' interest tends to rise with the first repetitions and attains a peak after which interest will decrease with subsequent exposures, resulting in an inverted-U shape. This behavior, which has been extensively studied in psychology, is called the mere exposure effect. In this paper, we show how a number of factors, both content and user-based, well documented in the literature on the mere exposure effect, modulate the magnitude of the effect. Due to the vast availability of data of users discovering new songs everyday in music streaming platforms, these findings enable new ways to characterize both the music, users and their relationships. Ultimately, it opens up the possibility of developing new recommender systems paradigms based on these characterizations.