 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
MuLan: A Joint Embedding of Music Audio and Natural Language
Aug 26, 2022
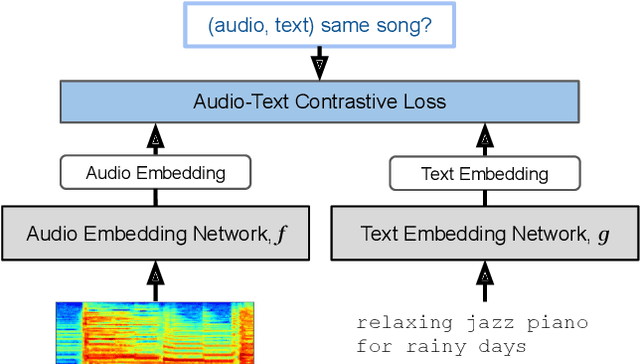


Music tagging and content-based retrieval systems have traditionally been constructed using pre-defined ontologies covering a rigid set of music attributes or text queries. This paper presents MuLan: a first attempt at a new generation of acoustic models that link music audio directly to unconstrained natural language music descriptions. MuLan takes the form of a two-tower, joint audio-text embedding model trained using 44 million music recordings (370K hours) and weakly-associated, free-form text annotations. Through its compatibility with a wide range of music genres and text styles (including conventional music tags), the resulting audio-text representation subsumes existing ontologies while graduating to true zero-shot functionalities. We demonstrate the versatility of the MuLan embeddings with a range of experiments including transfer learning, zero-shot music tagging, language understanding in the music domain, and cross-modal retrieval applications.
Inaudible Adversarial Perturbation: Manipulating the Recognition of User Speech in Real Tim
Aug 02, 2023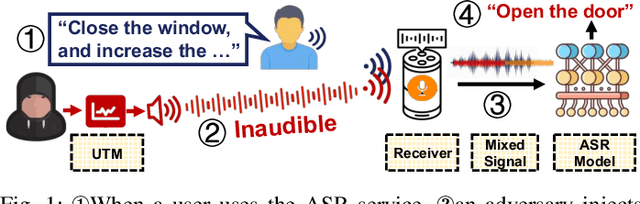
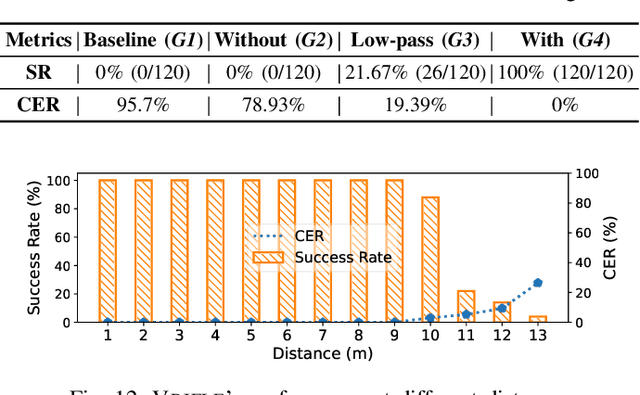
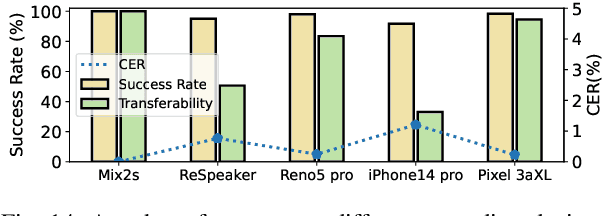
Automatic speech recognition (ASR) systems have been shown to be vulnerable to adversarial examples (AEs). Recent success all assumes that users will not notice or disrupt the attack process despite the existence of music/noise-like sounds and spontaneous responses from voice assistants. Nonetheless, in practical user-present scenarios, user awareness may nullify existing attack attempts that launch unexpected sounds or ASR usage. In this paper, we seek to bridge the gap in existing research and extend the attack to user-present scenarios. We propose VRIFLE, an inaudible adversarial perturbation (IAP) attack via ultrasound delivery that can manipulate ASRs as a user speaks. The inherent differences between audible sounds and ultrasounds make IAP delivery face unprecedented challenges such as distortion, noise, and instability. In this regard, we design a novel ultrasonic transformation model to enhance the crafted perturbation to be physically effective and even survive long-distance delivery. We further enable VRIFLE's robustness by adopting a series of augmentation on user and real-world variations during the generation process. In this way, VRIFLE features an effective real-time manipulation of the ASR output from different distances and under any speech of users, with an alter-and-mute strategy that suppresses the impact of user disruption. Our extensive experiments in both digital and physical worlds verify VRIFLE's effectiveness under various configurations, robustness against six kinds of defenses, and universality in a targeted manner. We also show that VRIFLE can be delivered with a portable attack device and even everyday-life loudspeakers.
Whisper-AT: Noise-Robust Automatic Speech Recognizers are Also Strong General Audio Event Taggers
Jul 06, 2023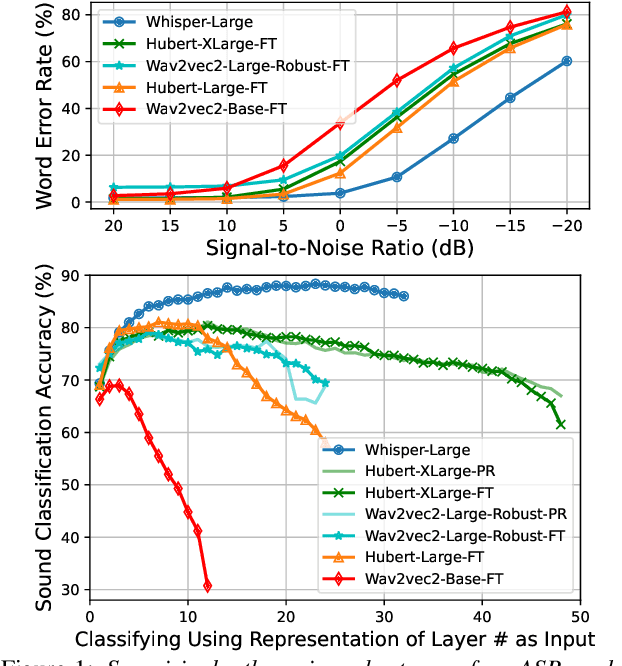
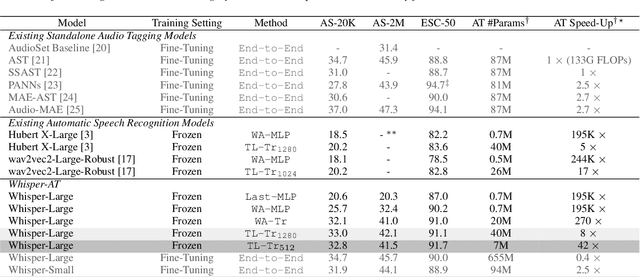
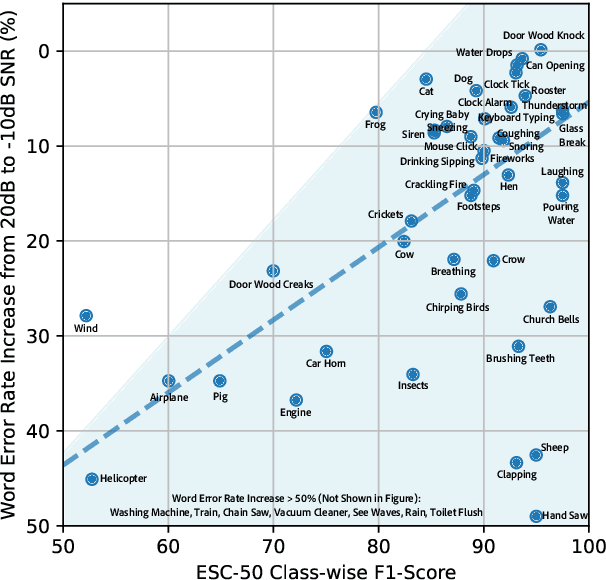
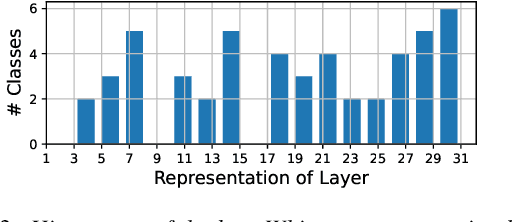
In this paper, we focus on Whisper, a recent automatic speech recognition model trained with a massive 680k hour labeled speech corpus recorded in diverse conditions. We first show an interesting finding that while Whisper is very robust against real-world background sounds (e.g., music), its audio representation is actually not noise-invariant, but is instead highly correlated to non-speech sounds, indicating that Whisper recognizes speech conditioned on the noise type. With this finding, we build a unified audio tagging and speech recognition model Whisper-AT by freezing the backbone of Whisper, and training a lightweight audio tagging model on top of it. With <1% extra computational cost, Whisper-AT can recognize audio events, in addition to spoken text, in a single forward pass.
RAWIW: RAW Image Watermarking Robust to ISP Pipeline
Jul 28, 2023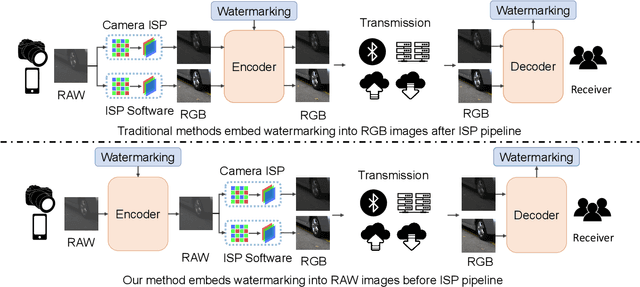
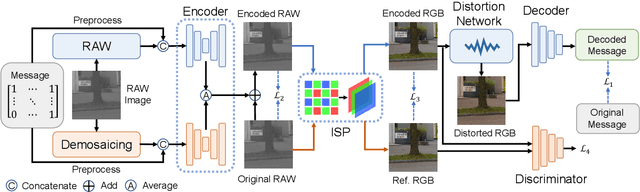


Invisible image watermarking is essential for image copyright protection. Compared to RGB images, RAW format images use a higher dynamic range to capture the radiometric characteristics of the camera sensor, providing greater flexibility in post-processing and retouching. Similar to the master recording in the music industry, RAW images are considered the original format for distribution and image production, thus requiring copyright protection. Existing watermarking methods typically target RGB images, leaving a gap for RAW images. To address this issue, we propose the first deep learning-based RAW Image Watermarking (RAWIW) framework for copyright protection. Unlike RGB image watermarking, our method achieves cross-domain copyright protection. We directly embed copyright information into RAW images, which can be later extracted from the corresponding RGB images generated by different post-processing methods. To achieve end-to-end training of the framework, we integrate a neural network that simulates the ISP pipeline to handle the RAW-to-RGB conversion process. To further validate the generalization of our framework to traditional ISP pipelines and its robustness to transmission distortion, we adopt a distortion network. This network simulates various types of noises introduced during the traditional ISP pipeline and transmission. Furthermore, we employ a three-stage training strategy to strike a balance between robustness and concealment of watermarking. Our extensive experiments demonstrate that RAWIW successfully achieves cross-domain copyright protection for RAW images while maintaining their visual quality and robustness to ISP pipeline distortions.
Generating coherent comic with rich story using ChatGPT and Stable Diffusion
May 19, 2023Past work demonstrated that using neural networks, we can extend unfinished music pieces while maintaining the music style of the musician. With recent advancements in large language models and diffusion models, we are now capable of generating comics with an interesting storyline while maintaining the art style of the artist. In this paper, we used ChatGPT to generate storylines and dialogue and then generated the comic using stable diffusion. We introduced a novel way to evaluate AI-generated stories, and we achieved SOTA performance on character fidelity and art style by fine-tuning stable diffusion using LoRA, ControlNet, etc.
Computing Melodic Templates in Oral Music Traditions
Sep 27, 2022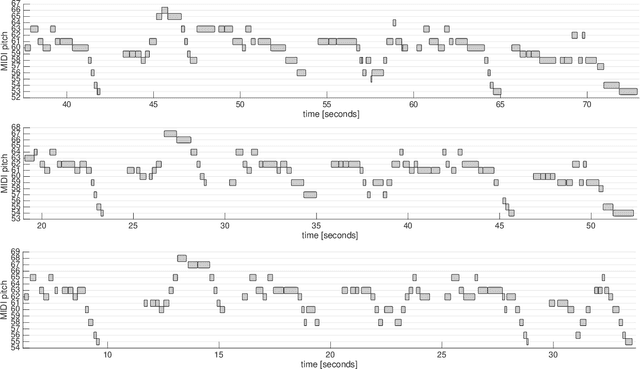

The term melodic template or skeleton refers to a basic melody which is subject to variation during a music performance. In many oral music tradition, these templates are implicitly passed throughout generations without ever being formalized in a score. In this work, we introduce a new geometric optimization problem, the spanning tube problem, to approximate a melodic template for a set of labeled performance transcriptions corresponding to an specific style in oral music traditions. Given a set of $n$ piecewise linear functions, we solve the problem of finding a continuous function, $f^*$, and a minimum value, $\varepsilon^*$, such that, the vertical segment of length $2\varepsilon^*$ centered at $(x,f^*(x))$ intersects at least $p$ functions ($p\leq n$). The method explored here also provide a novel tool for quantitatively assess the amount of melodic variation which occurs across performances.
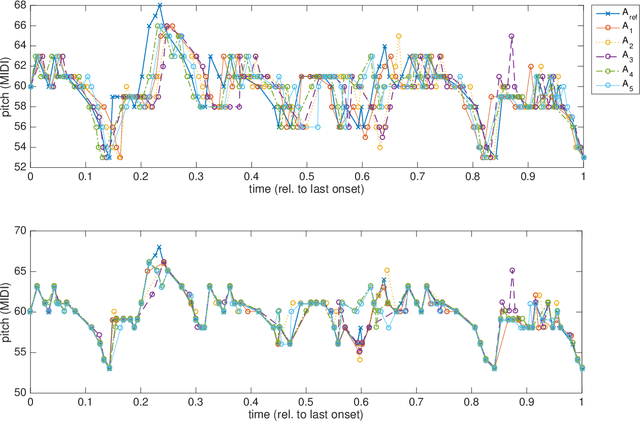
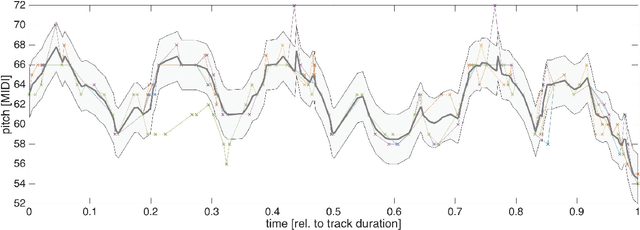
Improving Choral Music Separation through Expressive Synthesized Data from Sampled Instruments
Sep 07, 2022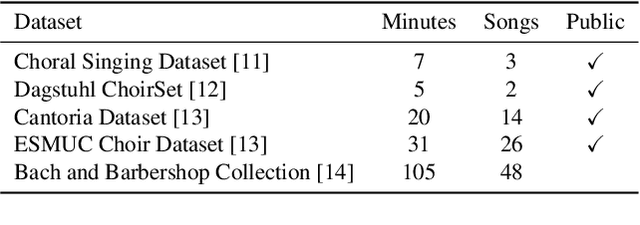
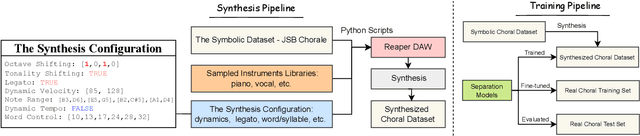
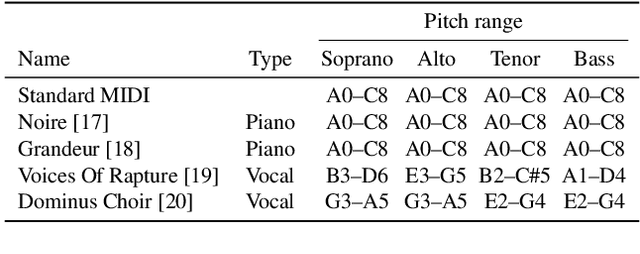

Choral music separation refers to the task of extracting tracks of voice parts (e.g., soprano, alto, tenor, and bass) from mixed audio. The lack of datasets has impeded research on this topic as previous work has only been able to train and evaluate models on a few minutes of choral music data due to copyright issues and dataset collection difficulties. In this paper, we investigate the use of synthesized training data for the source separation task on real choral music. We make three contributions: first, we provide an automated pipeline for synthesizing choral music data from sampled instrument plugins within controllable options for instrument expressiveness. This produces an 8.2-hour-long choral music dataset from the JSB Chorales Dataset and one can easily synthesize additional data. Second, we conduct an experiment to evaluate multiple separation models on available choral music separation datasets from previous work. To the best of our knowledge, this is the first experiment to comprehensively evaluate choral music separation. Third, experiments demonstrate that the synthesized choral data is of sufficient quality to improve the model's performance on real choral music datasets. This provides additional experimental statistics and data support for the choral music separation study.
* Camera Ready for Proceedings of the 23rd International Society for Music Information Retrieval Conference, ISMIR 2022
Music Recommendation System based on Emotion, Age and Ethnicity
Dec 09, 2022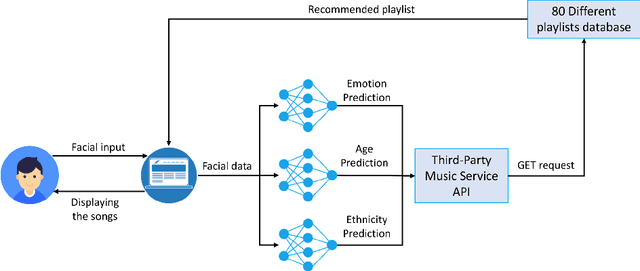
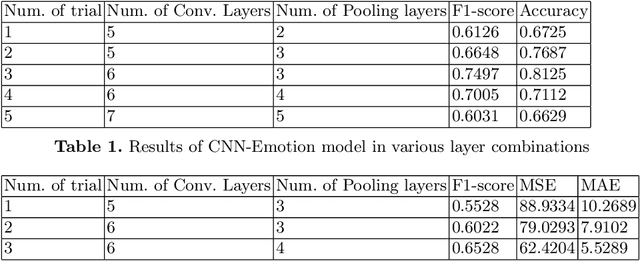


A Music Recommendation System based on Emotion, Age, and Ethnicity is developed in this study, using FER-2013 and ``Age, Gender, and Ethnicity (Face Data) CSV'' datasets. The CNN architecture, which is extensively used for this kind of purpose has been applied to the training of the models. After adding several appropriate layers to the training end of the project, in total, 3 separate models are trained in the Deep Learning side of the project: Emotion, Ethnicity, and Age. After the training step of these models, they are used as classifiers on the web application side. The snapshot of the user taken through the interface is sent to the models to predict their mood, age, and ethnic origin. According to these classifiers, various kinds of playlists pulled from Spotify API are proposed to the user in order to establish a functional and user-friendly atmosphere for the music selection. Afterward, the user can choose the playlist they want and listen to it by following the given link.
Supervised and Unsupervised Learning of Audio Representations for Music Understanding
Oct 07, 2022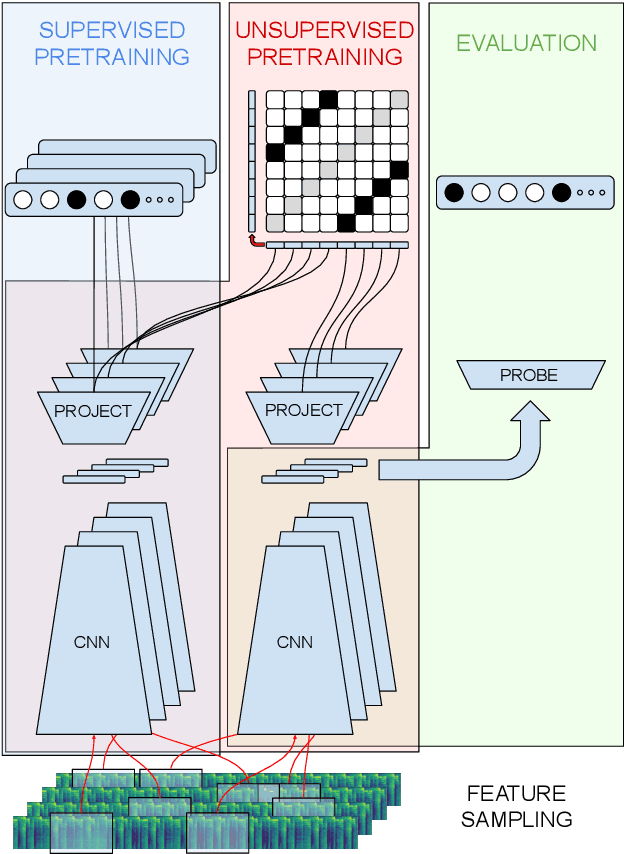
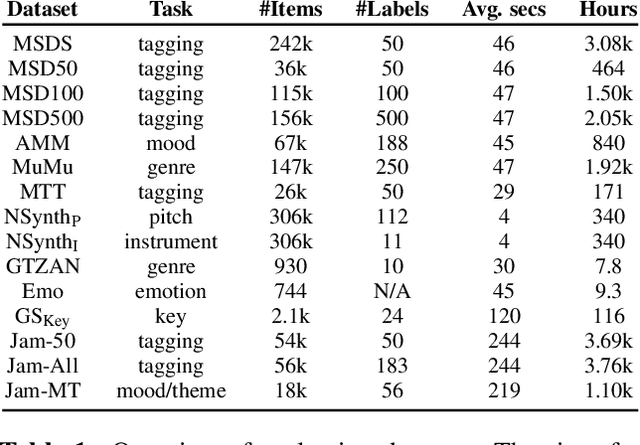
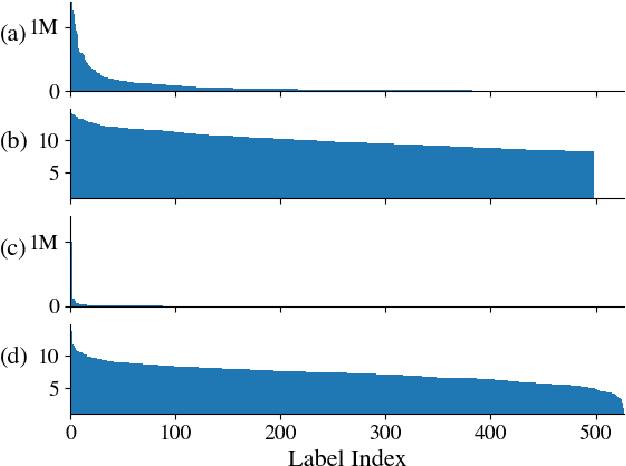
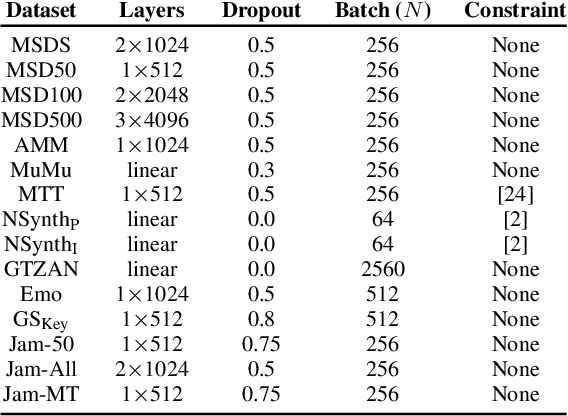
In this work, we provide a broad comparative analysis of strategies for pre-training audio understanding models for several tasks in the music domain, including labelling of genre, era, origin, mood, instrumentation, key, pitch, vocal characteristics, tempo and sonority. Specifically, we explore how the domain of pre-training datasets (music or generic audio) and the pre-training methodology (supervised or unsupervised) affects the adequacy of the resulting audio embeddings for downstream tasks. We show that models trained via supervised learning on large-scale expert-annotated music datasets achieve state-of-the-art performance in a wide range of music labelling tasks, each with novel content and vocabularies. This can be done in an efficient manner with models containing less than 100 million parameters that require no fine-tuning or reparameterization for downstream tasks, making this approach practical for industry-scale audio catalogs. Within the class of unsupervised learning strategies, we show that the domain of the training dataset can significantly impact the performance of representations learned by the model. We find that restricting the domain of the pre-training dataset to music allows for training with smaller batch sizes while achieving state-of-the-art in unsupervised learning -- and in some cases, supervised learning -- for music understanding. We also corroborate that, while achieving state-of-the-art performance on many tasks, supervised learning can cause models to specialize to the supervised information provided, somewhat compromising a model's generality.
WavJourney: Compositional Audio Creation with Large Language Models
Jul 26, 2023Large Language Models (LLMs) have shown great promise in integrating diverse expert models to tackle intricate language and vision tasks. Despite their significance in advancing the field of Artificial Intelligence Generated Content (AIGC), their potential in intelligent audio content creation remains unexplored. In this work, we tackle the problem of creating audio content with storylines encompassing speech, music, and sound effects, guided by text instructions. We present WavJourney, a system that leverages LLMs to connect various audio models for audio content generation. Given a text description of an auditory scene, WavJourney first prompts LLMs to generate a structured script dedicated to audio storytelling. The audio script incorporates diverse audio elements, organized based on their spatio-temporal relationships. As a conceptual representation of audio, the audio script provides an interactive and interpretable rationale for human engagement. Afterward, the audio script is fed into a script compiler, converting it into a computer program. Each line of the program calls a task-specific audio generation model or computational operation function (e.g., concatenate, mix). The computer program is then executed to obtain an explainable solution for audio generation. We demonstrate the practicality of WavJourney across diverse real-world scenarios, including science fiction, education, and radio play. The explainable and interactive design of WavJourney fosters human-machine co-creation in multi-round dialogues, enhancing creative control and adaptability in audio production. WavJourney audiolizes the human imagination, opening up new avenues for creativity in multimedia content creation.