 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Comparision Of Adversarial And Non-Adversarial LSTM Music Generative Models
Nov 01, 2022
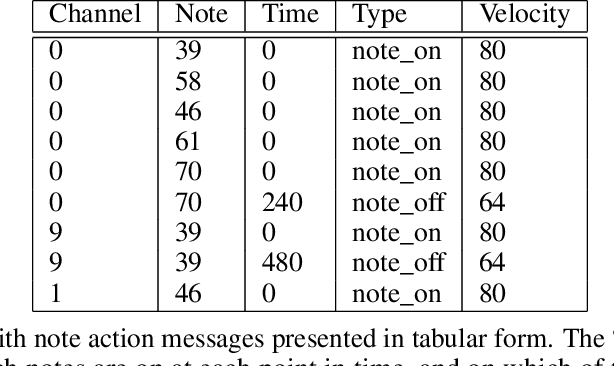
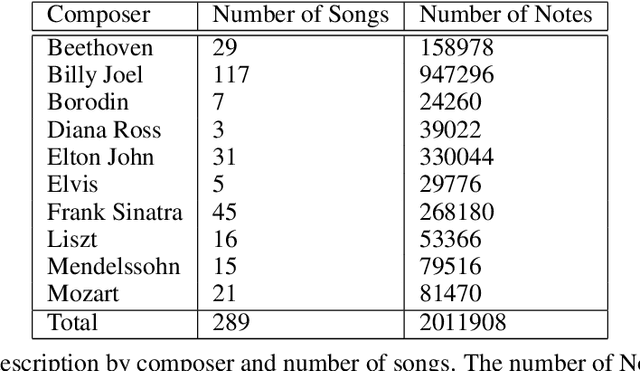
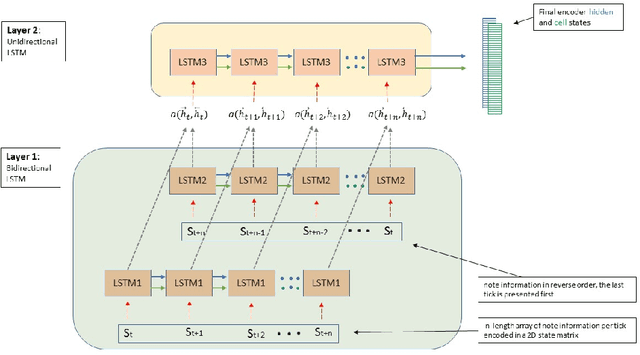
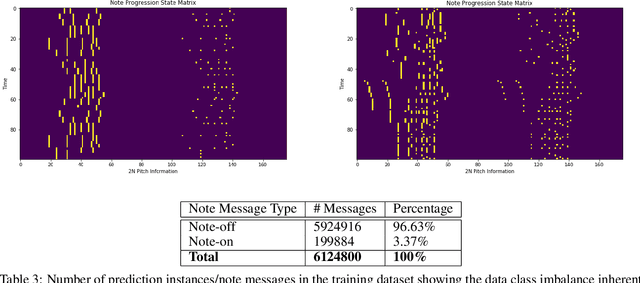
Algorithmic music composition is a way of composing musical pieces with minimal to no human intervention. While recurrent neural networks are traditionally applied to many sequence-to-sequence prediction tasks, including successful implementations of music composition, their standard supervised learning approach based on input-to-output mapping leads to a lack of note variety. These models can therefore be seen as potentially unsuitable for tasks such as music generation. Generative adversarial networks learn the generative distribution of data and lead to varied samples. This work implements and compares adversarial and non-adversarial training of recurrent neural network music composers on MIDI data. The resulting music samples are evaluated by human listeners, their preferences recorded. The evaluation indicates that adversarial training produces more aesthetically pleasing music.
Multi-modal Multi-view Clustering based on Non-negative Matrix Factorization
Aug 09, 2023
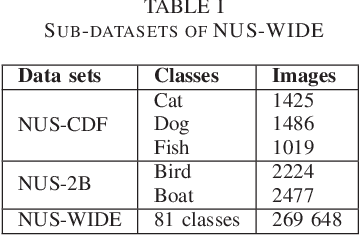
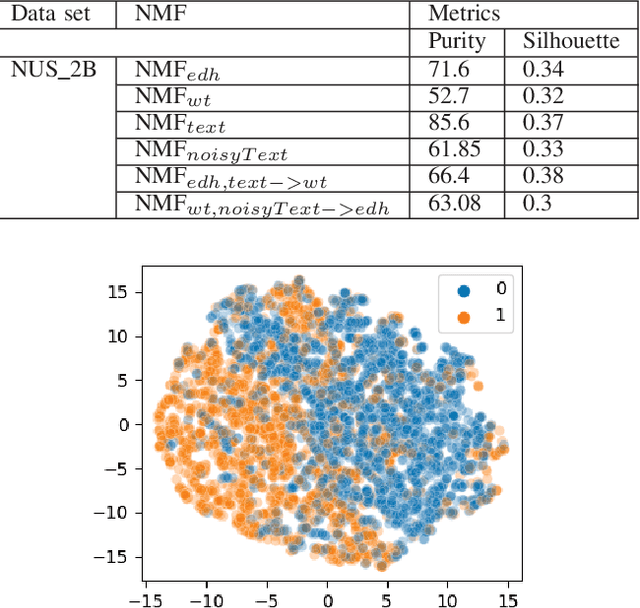

By combining related objects, unsupervised machine learning techniques aim to reveal the underlying patterns in a data set. Non-negative Matrix Factorization (NMF) is a data mining technique that splits data matrices by imposing restrictions on the elements' non-negativity into two matrices: one representing the data partitions and the other to represent the cluster prototypes of the data set. This method has attracted a lot of attention and is used in a wide range of applications, including text mining, clustering, language modeling, music transcription, and neuroscience (gene separation). The interpretation of the generated matrices is made simpler by the absence of negative values. In this article, we propose a study on multi-modal clustering algorithms and present a novel method called multi-modal multi-view non-negative matrix factorization, in which we analyze the collaboration of several local NMF models. The experimental results show the value of the proposed approach, which was evaluated using a variety of data sets, and the obtained results are very promising compared to state of art methods.
jazznet: A Dataset of Fundamental Piano Patterns for Music Audio Machine Learning Research
Feb 17, 2023
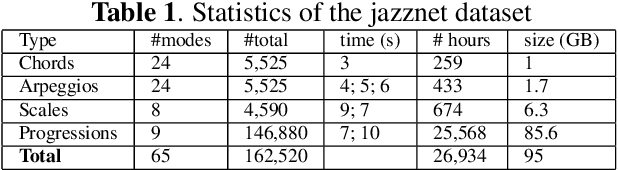
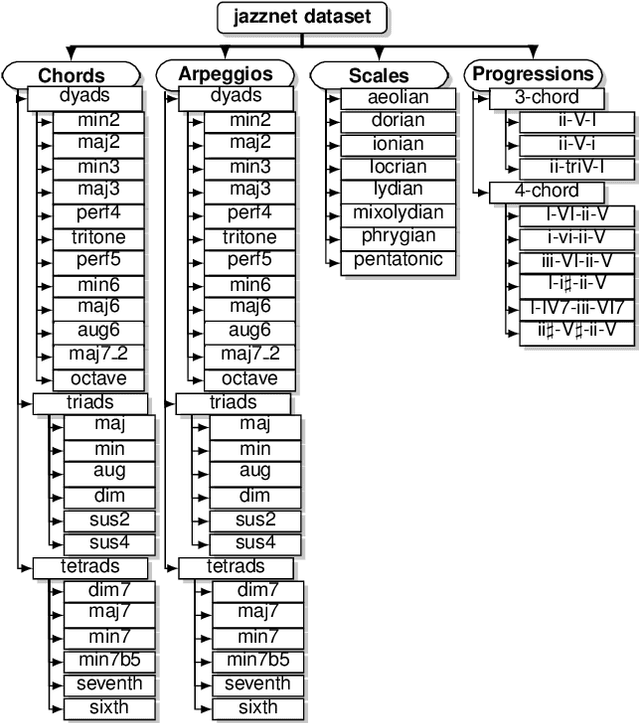

This paper introduces the jazznet Dataset, a dataset of fundamental jazz piano music patterns for developing machine learning (ML) algorithms in music information retrieval (MIR). The dataset contains 162520 labeled piano patterns, including chords, arpeggios, scales, and chord progressions with their inversions, resulting in more than 26k hours of audio and a total size of 95GB. The paper explains the dataset's composition, creation, and generation, and presents an open-source Pattern Generator using a method called Distance-Based Pattern Structures (DBPS), which allows researchers to easily generate new piano patterns simply by defining the distances between pitches within the musical patterns. We demonstrate that the dataset can help researchers benchmark new models for challenging MIR tasks, using a convolutional recurrent neural network (CRNN) and a deep convolutional neural network. The dataset and code are available via: https://github.com/tosiron/jazznet.
LoopBoxes -- Evaluation of a Collaborative Accessible Digital Musical Instrument
May 24, 2023
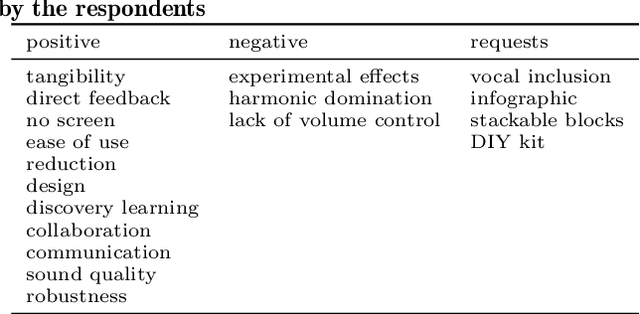
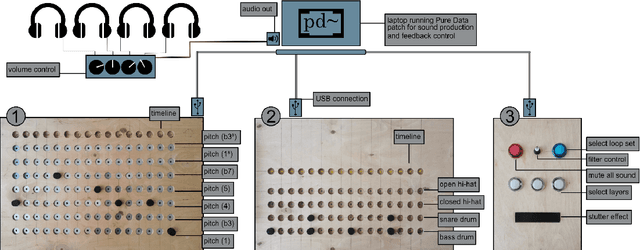
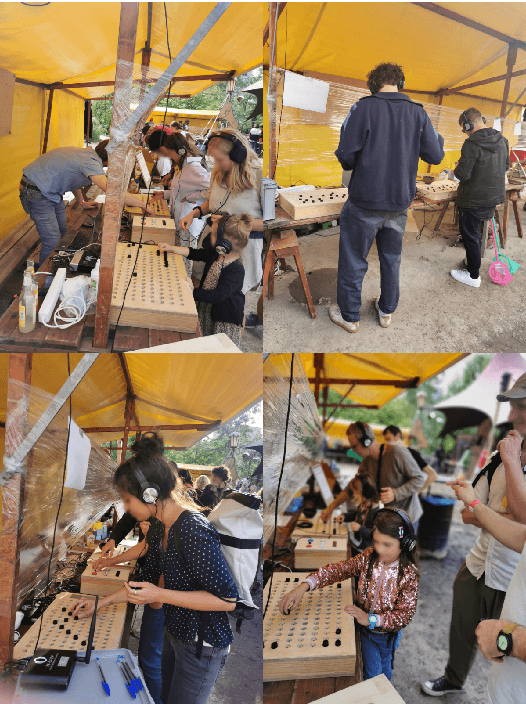
LoopBoxes is an accessible digital musical instrument designed to create an intuitive access to loop based music making for children with special educational needs (SEN). This paper describes the evaluation of the instrument in the form of a pilot study during a music festival in Berlin, Germany, as well as a case study with children and music teachers in a SEN school setting. We created a modular system composed of three modules that afford single user as well as collaborative music making. The pilot study was evaluated using informal observation and questionnaires (n = 39), and indicated that the instrument affords music making for people with and without prior musical knowledge across all age groups and fosters collaborative musical processes. The case study was based on observation and a qualitative interview. It confirmed that the instrument meets the needs of the school settings and indicated how future versions could expand access to all students, especially those experiencing complex disabilities. In addition, out-of-the-box functionality seems to be crucial for the long-term implementation of the instrument in a school setting.
Can a virtual conductor create its own interpretation of a music orchestra?
Apr 17, 2023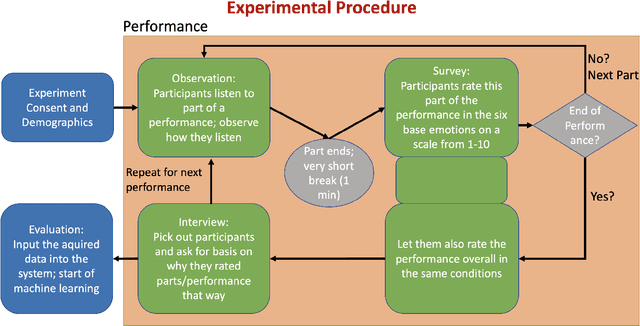
Having a computer do the work for you has become more and more common over time. But in the entertainment area, where a human is a creator, we want to avoid having too much influence on technology. On the other hand, inspiration is still important; we developed a virtual conductor that can generate an emotionally associated interpretation of known music work. This was done by surveying a set number of people to determine, which emotions were associated with a specific interpretation and instruments. As a result of machine learning this conductor was then able to achieve his goal. Unlike earlier studies of virtual conductors, which would replace the role of a human conductor, this new one is supposed to be an assisting tool for conductors. As a result, starting on a new interpretation will be easier because it streamlines research time and provides a technical perspective that can inspire new ideas. By using this technology as a supplement to human creativity, we can create richer, more nuanced interpretations of musical works.
SDMuse: Stochastic Differential Music Editing and Generation via Hybrid Representation
Nov 02, 2022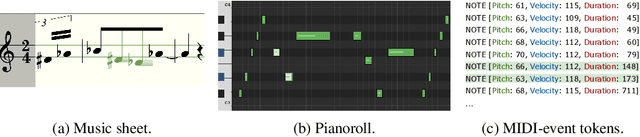

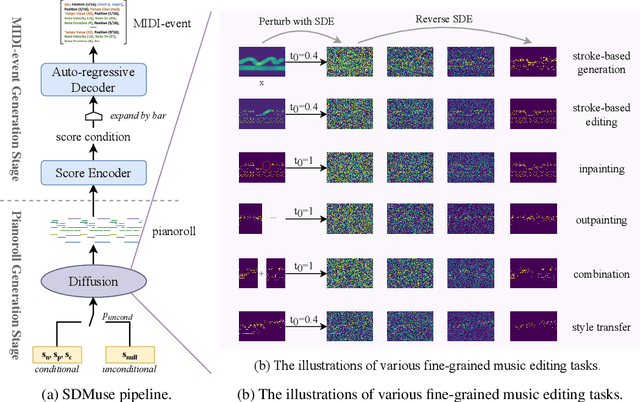

While deep generative models have empowered music generation, it remains a challenging and under-explored problem to edit an existing musical piece at fine granularity. In this paper, we propose SDMuse, a unified Stochastic Differential Music editing and generation framework, which can not only compose a whole musical piece from scratch, but also modify existing musical pieces in many ways, such as combination, continuation, inpainting, and style transferring. The proposed SDMuse follows a two-stage pipeline to achieve music generation and editing on top of a hybrid representation including pianoroll and MIDI-event. In particular, SDMuse first generates/edits pianoroll by iteratively denoising through a stochastic differential equation (SDE) based on a diffusion model generative prior, and then refines the generated pianoroll and predicts MIDI-event tokens auto-regressively. We evaluate the generated music of our method on ailabs1k7 pop music dataset in terms of quality and controllability on various music editing and generation tasks. Experimental results demonstrate the effectiveness of our proposed stochastic differential music editing and generation process, as well as the hybrid representations.
A Shift In Artistic Practices through Artificial Intelligence
Jun 13, 2023
The explosion of content generated by Artificial Intelligence models has initiated a cultural shift in arts, music, and media, where roles are changing, values are shifting, and conventions are challenged. The readily available, vast dataset of the internet has created an environment for AI models to be trained on any content on the web. With AI models shared openly, and used by many, globally, how does this new paradigm shift challenge the status quo in artistic practices? What kind of changes will AI technology bring into music, arts, and new media?
An Improved Metric of Informational Masking for Perceptual Audio Quality Measurement
Jul 13, 2023Perceptual audio quality measurement systems algorithmically analyze the output of audio processing systems to estimate possible perceived quality degradation using perceptual models of human audition. In this manner, they save the time and resources associated with the design and execution of listening tests (LTs). Models of disturbance audibility predicting peripheral auditory masking in quality measurement systems have considerably increased subjective quality prediction performance of signals processed by perceptual audio codecs. Additionally, cognitive effects have also been known to regulate perceived distortion severity by influencing their salience. However, the performance gains due to cognitive effect models in quality measurement systems were inconsistent so far, particularly for music signals. Firstly, this paper presents an improved model of informational masking (IM) -- an important cognitive effect in quality perception -- that considers disturbance information complexity around the masking threshold. Secondly, we incorporate the proposed IM metric into a quality measurement systems using a novel interaction analysis procedure between cognitive effects and distortion metrics. The procedure establishes interactions between cognitive effects and distortion metrics using LT data. The proposed IM metric is shown to outperform previously proposed IM metrics in a validation task against subjective quality scores from large and diverse LT databases. Particularly, the proposed system showed an increased quality prediction of music signals coded with bandwidth extension techniques, where other models frequently fail.
Controllable Lyrics-to-Melody Generation
Jun 05, 2023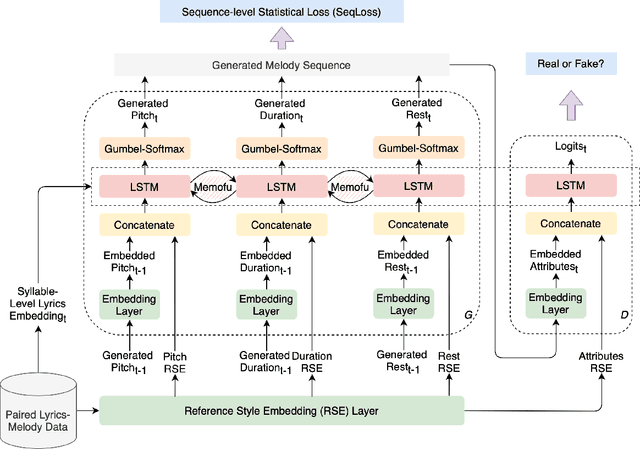
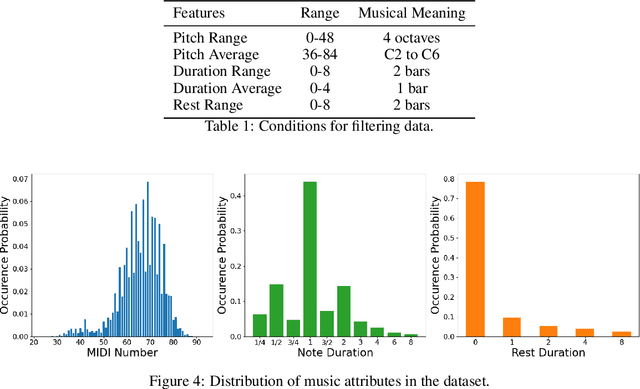

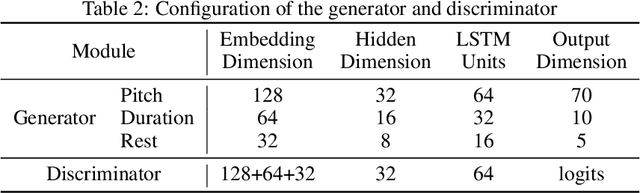
Lyrics-to-melody generation is an interesting and challenging topic in AI music research field. Due to the difficulty of learning the correlations between lyrics and melody, previous methods suffer from low generation quality and lack of controllability. Controllability of generative models enables human interaction with models to generate desired contents, which is especially important in music generation tasks towards human-centered AI that can facilitate musicians in creative activities. To address these issues, we propose a controllable lyrics-to-melody generation network, ConL2M, which is able to generate realistic melodies from lyrics in user-desired musical style. Our work contains three main novelties: 1) To model the dependencies of music attributes cross multiple sequences, inter-branch memory fusion (Memofu) is proposed to enable information flow between multi-branch stacked LSTM architecture; 2) Reference style embedding (RSE) is proposed to improve the quality of generation as well as control the musical style of generated melodies; 3) Sequence-level statistical loss (SeqLoss) is proposed to help the model learn sequence-level features of melodies given lyrics. Verified by evaluation metrics for music quality and controllability, initial study of controllable lyrics-to-melody generation shows better generation quality and the feasibility of interacting with users to generate the melodies in desired musical styles when given lyrics.
Musika! Fast Infinite Waveform Music Generation
Aug 18, 2022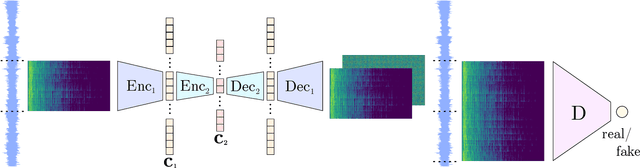
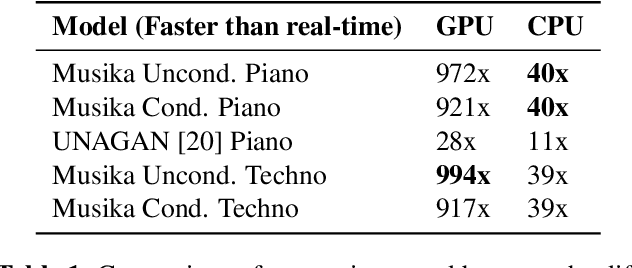
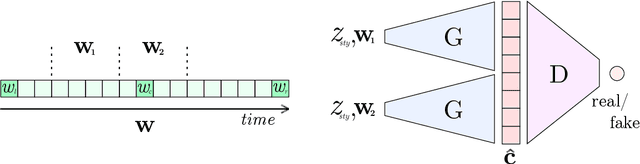

Fast and user-controllable music generation could enable novel ways of composing or performing music. However, state-of-the-art music generation systems require large amounts of data and computational resources for training, and are slow at inference. This makes them impractical for real-time interactive use. In this work, we introduce Musika, a music generation system that can be trained on hundreds of hours of music using a single consumer GPU, and that allows for much faster than real-time generation of music of arbitrary length on a consumer CPU. We achieve this by first learning a compact invertible representation of spectrogram magnitudes and phases with adversarial autoencoders, then training a Generative Adversarial Network (GAN) on this representation for a particular music domain. A latent coordinate system enables generating arbitrarily long sequences of excerpts in parallel, while a global context vector allows the music to remain stylistically coherent through time. We perform quantitative evaluations to assess the quality of the generated samples and showcase options for user control in piano and techno music generation. We release the source code and pretrained autoencoder weights at github.com/marcoppasini/musika, such that a GAN can be trained on a new music domain with a single GPU in a matter of hours.