 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
jazznet: A Dataset of Fundamental Piano Patterns for Music Audio Machine Learning Research
Feb 17, 2023
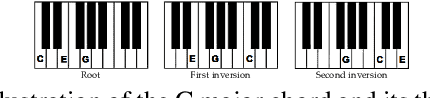
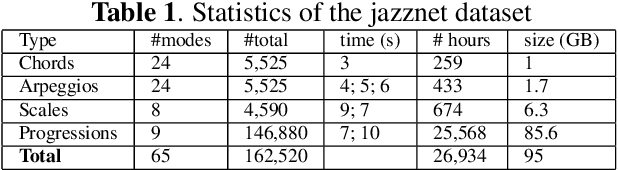
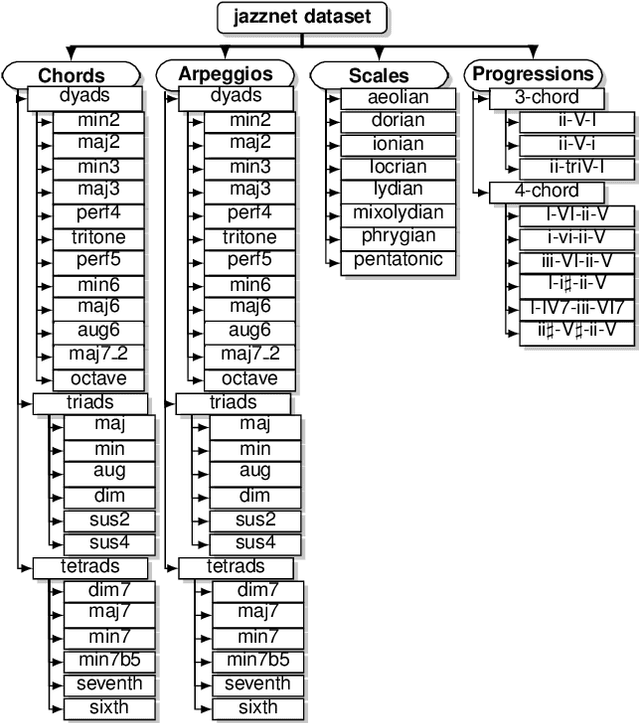

This paper introduces the jazznet Dataset, a dataset of fundamental jazz piano music patterns for developing machine learning (ML) algorithms in music information retrieval (MIR). The dataset contains 162520 labeled piano patterns, including chords, arpeggios, scales, and chord progressions with their inversions, resulting in more than 26k hours of audio and a total size of 95GB. The paper explains the dataset's composition, creation, and generation, and presents an open-source Pattern Generator using a method called Distance-Based Pattern Structures (DBPS), which allows researchers to easily generate new piano patterns simply by defining the distances between pitches within the musical patterns. We demonstrate that the dataset can help researchers benchmark new models for challenging MIR tasks, using a convolutional recurrent neural network (CRNN) and a deep convolutional neural network. The dataset and code are available via: https://github.com/tosiron/jazznet.
An Improved Metric of Informational Masking for Perceptual Audio Quality Measurement
Jul 13, 2023Perceptual audio quality measurement systems algorithmically analyze the output of audio processing systems to estimate possible perceived quality degradation using perceptual models of human audition. In this manner, they save the time and resources associated with the design and execution of listening tests (LTs). Models of disturbance audibility predicting peripheral auditory masking in quality measurement systems have considerably increased subjective quality prediction performance of signals processed by perceptual audio codecs. Additionally, cognitive effects have also been known to regulate perceived distortion severity by influencing their salience. However, the performance gains due to cognitive effect models in quality measurement systems were inconsistent so far, particularly for music signals. Firstly, this paper presents an improved model of informational masking (IM) -- an important cognitive effect in quality perception -- that considers disturbance information complexity around the masking threshold. Secondly, we incorporate the proposed IM metric into a quality measurement systems using a novel interaction analysis procedure between cognitive effects and distortion metrics. The procedure establishes interactions between cognitive effects and distortion metrics using LT data. The proposed IM metric is shown to outperform previously proposed IM metrics in a validation task against subjective quality scores from large and diverse LT databases. Particularly, the proposed system showed an increased quality prediction of music signals coded with bandwidth extension techniques, where other models frequently fail.
Can a virtual conductor create its own interpretation of a music orchestra?
Apr 17, 2023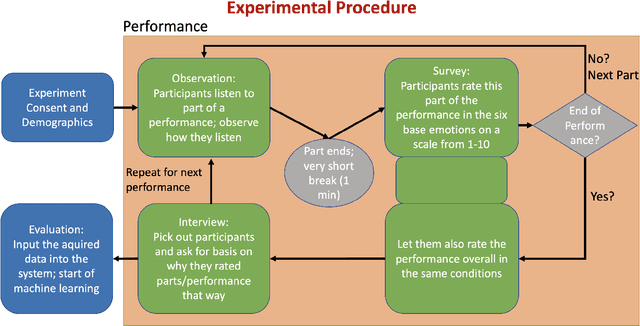
Having a computer do the work for you has become more and more common over time. But in the entertainment area, where a human is a creator, we want to avoid having too much influence on technology. On the other hand, inspiration is still important; we developed a virtual conductor that can generate an emotionally associated interpretation of known music work. This was done by surveying a set number of people to determine, which emotions were associated with a specific interpretation and instruments. As a result of machine learning this conductor was then able to achieve his goal. Unlike earlier studies of virtual conductors, which would replace the role of a human conductor, this new one is supposed to be an assisting tool for conductors. As a result, starting on a new interpretation will be easier because it streamlines research time and provides a technical perspective that can inspire new ideas. By using this technology as a supplement to human creativity, we can create richer, more nuanced interpretations of musical works.
From Discrete Tokens to High-Fidelity Audio Using Multi-Band Diffusion
Aug 02, 2023Deep generative models can generate high-fidelity audio conditioned on various types of representations (e.g., mel-spectrograms, Mel-frequency Cepstral Coefficients (MFCC)). Recently, such models have been used to synthesize audio waveforms conditioned on highly compressed representations. Although such methods produce impressive results, they are prone to generate audible artifacts when the conditioning is flawed or imperfect. An alternative modeling approach is to use diffusion models. However, these have mainly been used as speech vocoders (i.e., conditioned on mel-spectrograms) or generating relatively low sampling rate signals. In this work, we propose a high-fidelity multi-band diffusion-based framework that generates any type of audio modality (e.g., speech, music, environmental sounds) from low-bitrate discrete representations. At equal bit rate, the proposed approach outperforms state-of-the-art generative techniques in terms of perceptual quality. Training and, evaluation code, along with audio samples, are available on the facebookresearch/audiocraft Github page.
Comparision Of Adversarial And Non-Adversarial LSTM Music Generative Models
Nov 01, 2022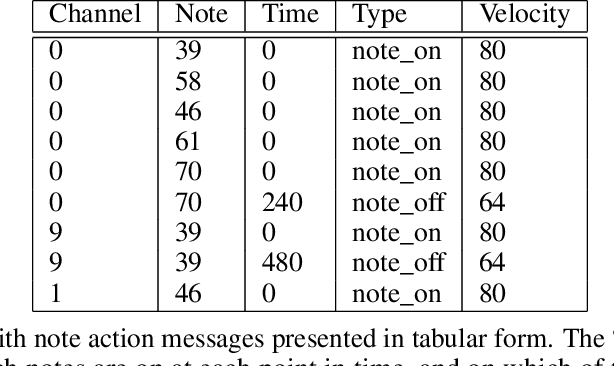
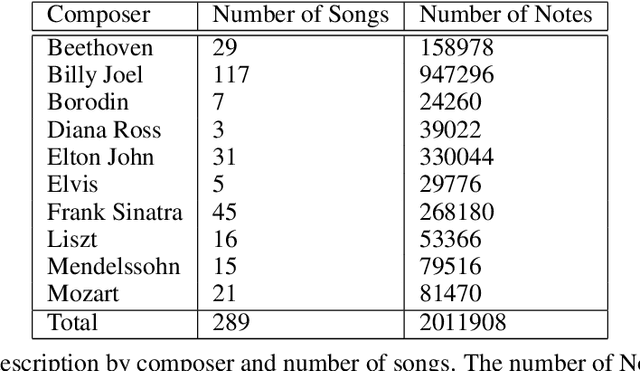
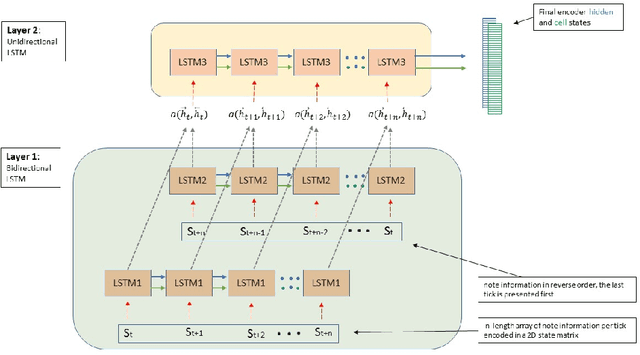
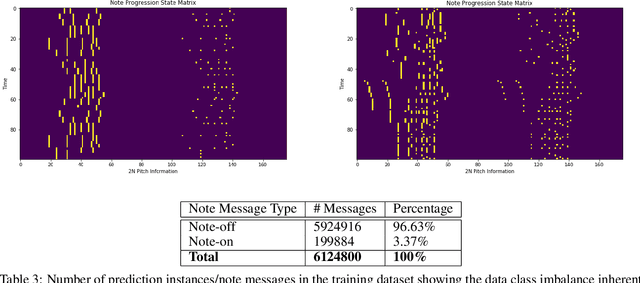
Algorithmic music composition is a way of composing musical pieces with minimal to no human intervention. While recurrent neural networks are traditionally applied to many sequence-to-sequence prediction tasks, including successful implementations of music composition, their standard supervised learning approach based on input-to-output mapping leads to a lack of note variety. These models can therefore be seen as potentially unsuitable for tasks such as music generation. Generative adversarial networks learn the generative distribution of data and lead to varied samples. This work implements and compares adversarial and non-adversarial training of recurrent neural network music composers on MIDI data. The resulting music samples are evaluated by human listeners, their preferences recorded. The evaluation indicates that adversarial training produces more aesthetically pleasing music.
Controllable Lyrics-to-Melody Generation
Jun 05, 2023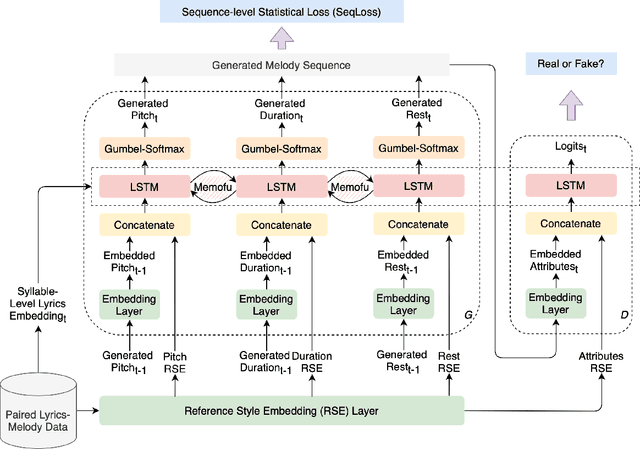
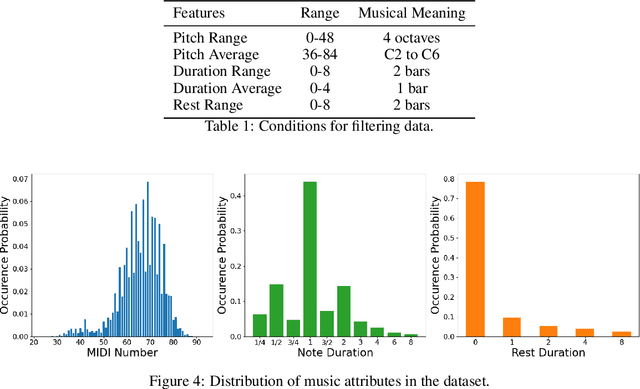

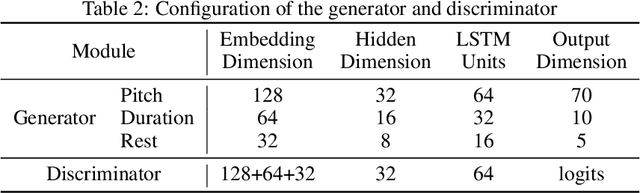
Lyrics-to-melody generation is an interesting and challenging topic in AI music research field. Due to the difficulty of learning the correlations between lyrics and melody, previous methods suffer from low generation quality and lack of controllability. Controllability of generative models enables human interaction with models to generate desired contents, which is especially important in music generation tasks towards human-centered AI that can facilitate musicians in creative activities. To address these issues, we propose a controllable lyrics-to-melody generation network, ConL2M, which is able to generate realistic melodies from lyrics in user-desired musical style. Our work contains three main novelties: 1) To model the dependencies of music attributes cross multiple sequences, inter-branch memory fusion (Memofu) is proposed to enable information flow between multi-branch stacked LSTM architecture; 2) Reference style embedding (RSE) is proposed to improve the quality of generation as well as control the musical style of generated melodies; 3) Sequence-level statistical loss (SeqLoss) is proposed to help the model learn sequence-level features of melodies given lyrics. Verified by evaluation metrics for music quality and controllability, initial study of controllable lyrics-to-melody generation shows better generation quality and the feasibility of interacting with users to generate the melodies in desired musical styles when given lyrics.
Emotion-Conditioned Melody Harmonization with Hierarchical Variational Autoencoder
Jun 08, 2023Existing melody harmonization models have made great progress in improving the quality of generated harmonies, but most of them ignored the emotions beneath the music. Meanwhile, the variability of harmonies generated by previous methods is insufficient. To solve these problems, we propose a novel LSTM-based Hierarchical Variational Auto-Encoder (LHVAE) to investigate the influence of emotional conditions on melody harmonization, while improving the quality of generated harmonies and capturing the abundant variability of chord progressions. Specifically, LHVAE incorporates latent variables and emotional conditions at different levels (piece- and bar-level) to model the global and local music properties. Additionally, we introduce an attention-based melody context vector at each step to better learn the correspondence between melodies and harmonies. Experimental results of the objective evaluation show that our proposed model outperforms other LSTM-based models. Through subjective evaluation, we conclude that only altering the chords hardly changes the overall emotion of the music. The qualitative analysis demonstrates the ability of our model to generate variable harmonies.
SDMuse: Stochastic Differential Music Editing and Generation via Hybrid Representation
Nov 02, 2022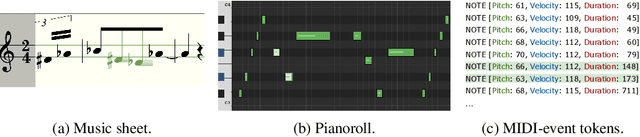

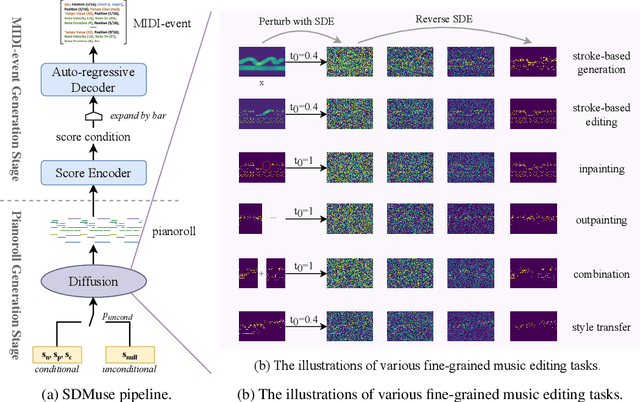

While deep generative models have empowered music generation, it remains a challenging and under-explored problem to edit an existing musical piece at fine granularity. In this paper, we propose SDMuse, a unified Stochastic Differential Music editing and generation framework, which can not only compose a whole musical piece from scratch, but also modify existing musical pieces in many ways, such as combination, continuation, inpainting, and style transferring. The proposed SDMuse follows a two-stage pipeline to achieve music generation and editing on top of a hybrid representation including pianoroll and MIDI-event. In particular, SDMuse first generates/edits pianoroll by iteratively denoising through a stochastic differential equation (SDE) based on a diffusion model generative prior, and then refines the generated pianoroll and predicts MIDI-event tokens auto-regressively. We evaluate the generated music of our method on ailabs1k7 pop music dataset in terms of quality and controllability on various music editing and generation tasks. Experimental results demonstrate the effectiveness of our proposed stochastic differential music editing and generation process, as well as the hybrid representations.
DAVIS: High-Quality Audio-Visual Separation with Generative Diffusion Models
Jul 31, 2023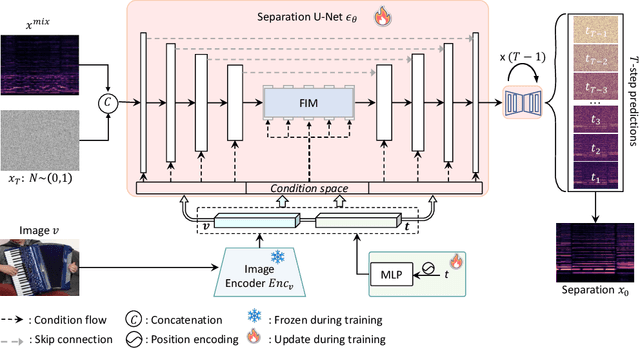
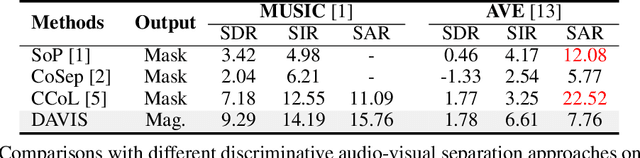
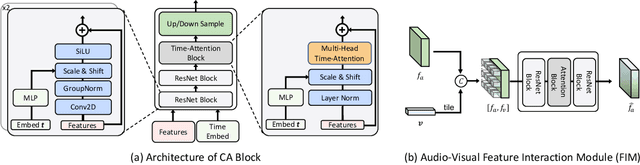
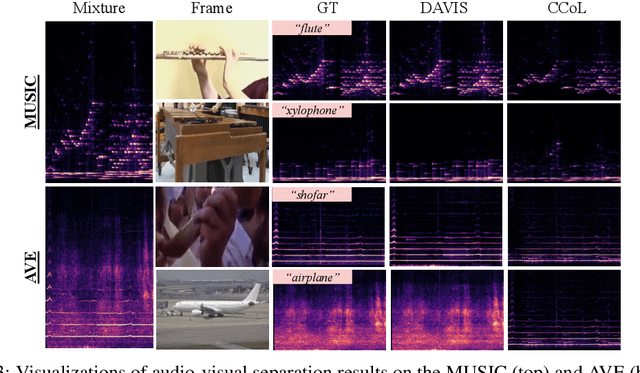
We propose DAVIS, a Diffusion model-based Audio-VIusal Separation framework that solves the audio-visual sound source separation task through a generative manner. While existing discriminative methods that perform mask regression have made remarkable progress in this field, they face limitations in capturing the complex data distribution required for high-quality separation of sounds from diverse categories. In contrast, DAVIS leverages a generative diffusion model and a Separation U-Net to synthesize separated magnitudes starting from Gaussian noises, conditioned on both the audio mixture and the visual footage. With its generative objective, DAVIS is better suited to achieving the goal of high-quality sound separation across diverse categories. We compare DAVIS to existing state-of-the-art discriminative audio-visual separation methods on the domain-specific MUSIC dataset and the open-domain AVE dataset, and results show that DAVIS outperforms other methods in separation quality, demonstrating the advantages of our framework for tackling the audio-visual source separation task.
Time-Frequency-Space Transmit Design and Signal Processing with Dynamic Subarray for Terahertz Integrated Sensing and Communication
Jul 10, 2023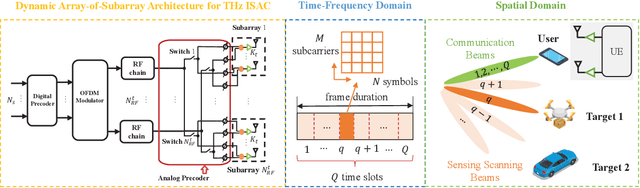
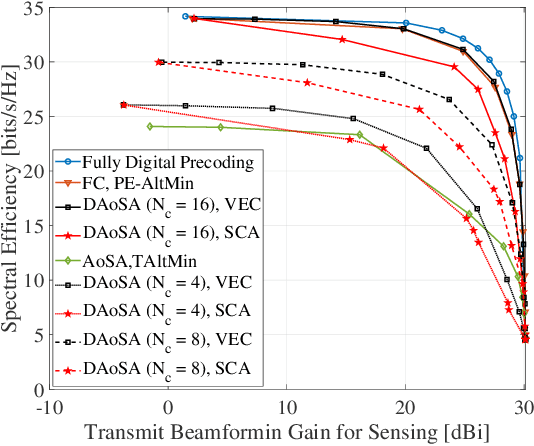
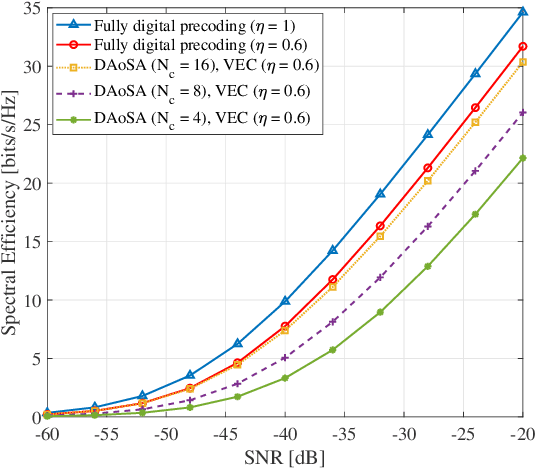
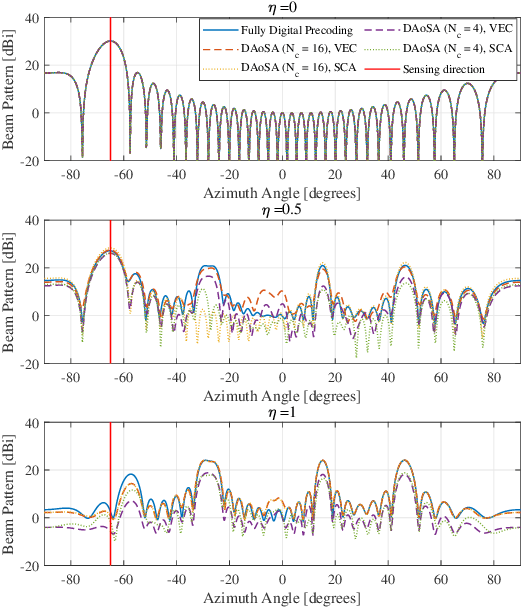
Terahertz (THz) integrated sensing and communication (ISAC) enables simultaneous data transmission with Terabit-per-second (Tbps) rate and millimeter-level accurate sensing. To realize such a blueprint, ultra-massive antenna arrays with directional beamforming are used to compensate for severe path loss in the THz band. In this paper, the time-frequency-space transmit design is investigated for THz ISAC to generate time-varying scanning sensing beams and stable communication beams. Specifically, with the dynamic array-of-subarray (DAoSA) hybrid beamforming architecture and multi-carrier modulation, two ISAC hybrid precoding algorithms are proposed, namely, a vectorization (VEC) based algorithm that outperforms existing ISAC hybrid precoding methods and a low-complexity sensing codebook assisted (SCA) approach. Meanwhile, coupled with the transmit design, parameter estimation algorithms are proposed to realize high-accuracy sensing, including a wideband DAoSA MUSIC (W-DAoSA-MUSIC) method for angle estimation and a sum-DFT-GSS (S-DFT-GSS) approach for range and velocity estimation. Numerical results indicate that the proposed algorithms can realize centi-degree-level angle estimation accuracy and millimeter-level range estimation accuracy, which are one or two orders of magnitudes better than the methods in the millimeter-wave band. In addition, to overcome the cyclic prefix limitation and Doppler effects in the THz band, an inter-symbol interference- and inter-carrier interference-tackled sensing algorithm is developed to refine sensing capabilities for THz ISAC.