 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Optimizing multi-user sound communications in reverberating environments with acoustic reconfigurable metasurfaces
Aug 03, 2023
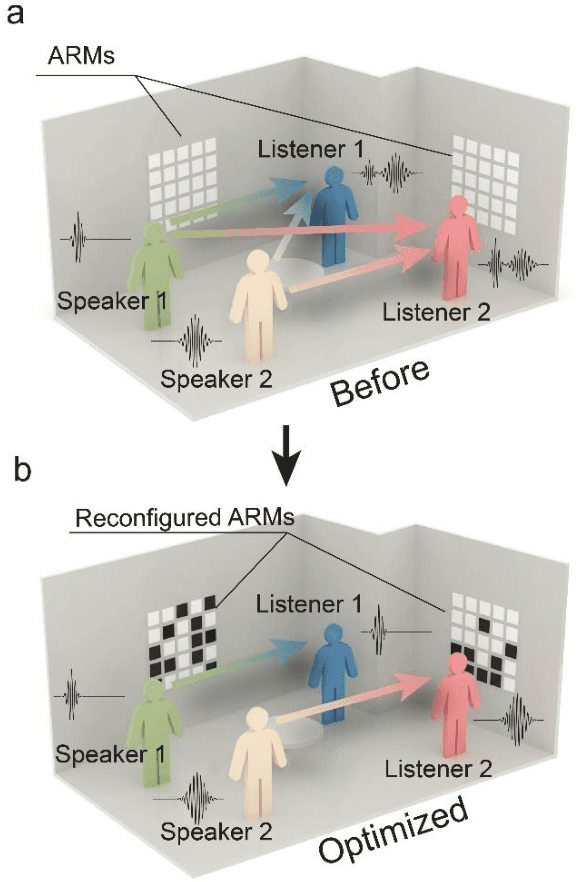
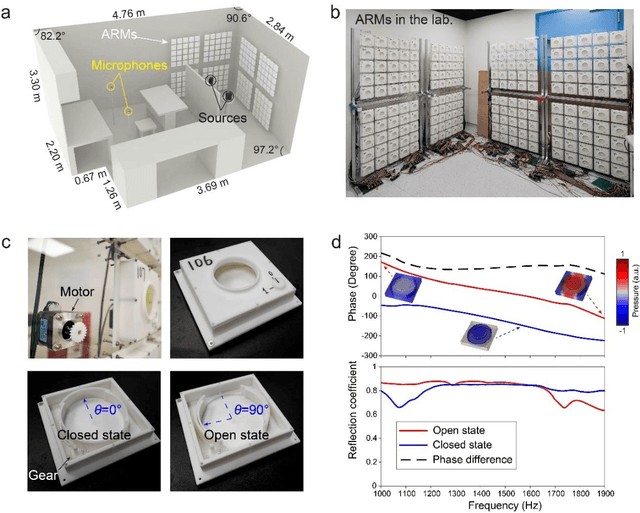
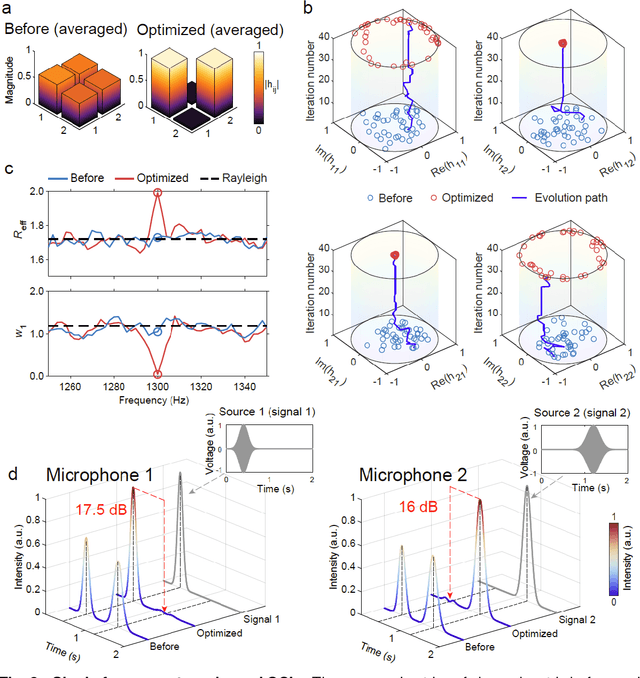
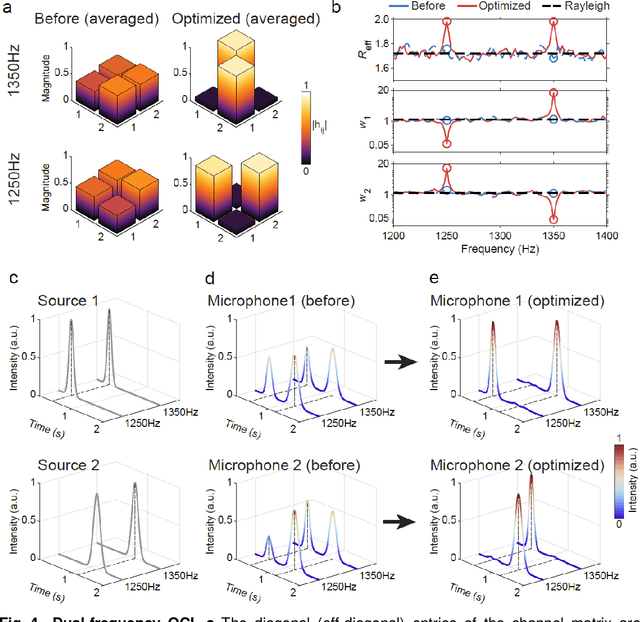
How do you ensure that, in a reverberant room, several people can speak simultaneously to several other people, making themselves perfectly understood and without any crosstalk between messages? In this work, we report a conceptual solution to this problem by developing an intelligent acoustic wall, which can be reconfigured electronically and is controlled by a learning algorithm that adapts to the geometry of the room and the positions of sources and receivers. To this end, a portion of the room boundaries is covered with a smart mirror made of a broadband acoustic reconfigurable metasurface (ARMs) designed to provide a two-state (0 or {\pi}) phase shift in the reflected waves by 200 independently tunable units. The whole phase pattern is optimized to maximize the Shannon capacity while minimizing crosstalk between the different sources and receivers. We demonstrate the control of multi-spectral sound fields covering a spectrum much larger than the coherence bandwidth of the room for diverse striking functionalities, including crosstalk-free acoustic communication, frequency-multiplexed communications, and multi-user communications. An experiment conducted with two music sources for two different people demonstrates a crosstalk-free simultaneous music playback. Our work opens new routes for the control of sound waves in complex media and for a new generation of acoustic devices.
Goniometers are a Powerful Acoustic Feature for Music Information Retrieval Tasks
Feb 02, 2023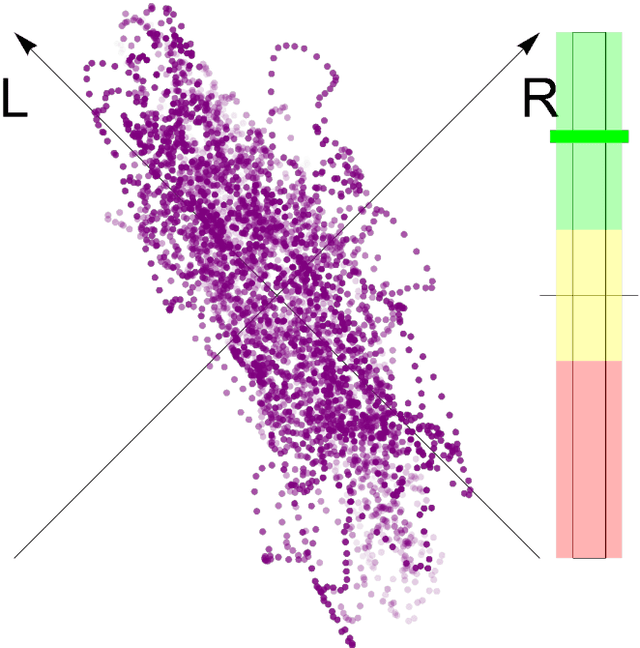
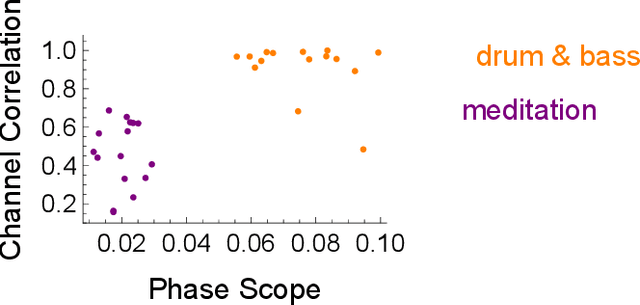
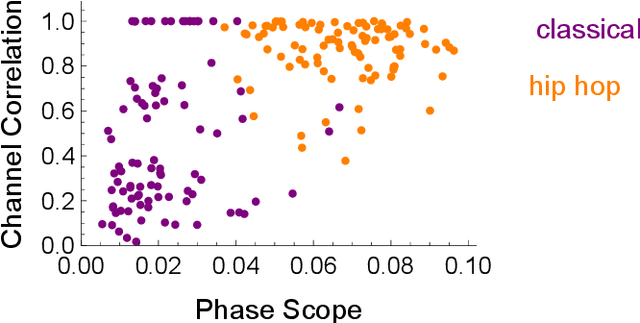
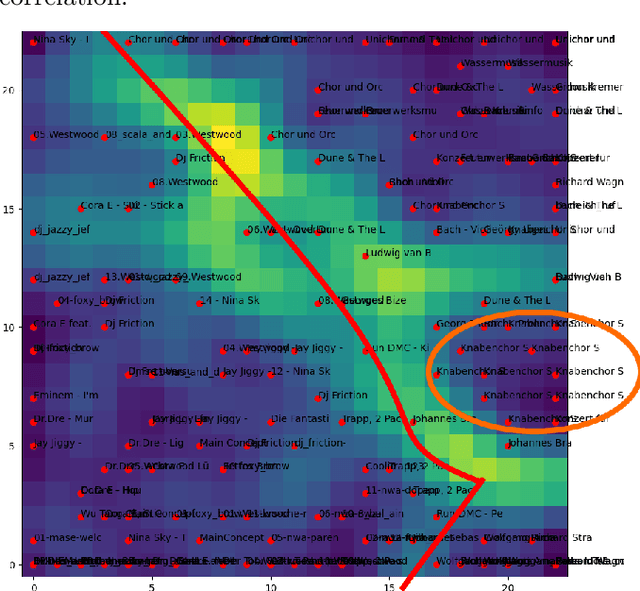
Goniometers, also known as Phase Scopes or Vector Scopes, are audio metering tools that help music producers and mixing engineers monitor spatial aspects of a music mix, such as the stereo panorama, the width of single sources, the amount and diffuseness of reverberation as well as phase cancellations that may occur on the sweet-spot and in a mono-mixdown. In addition, they implicitly inform about the dynamics of the sound. Self-organizing maps trained with a goniometer, are consulted to explore the usefulness of this acoustic feature for music information retrieval tasks. One can see that goniometers are able to classify different genres and cluster a single album. The advantage of goniometers is the causality: Music producers and mixing engineers consciously consult goniometers to reach their desired sound, which is not the case for other acoustic features, from Zero-Crossing Rate to Mel-Frequency Cepstral Coefficients.
Proceedings of the 2nd International Workshop on Reading Music Systems
Dec 01, 2022


The International Workshop on Reading Music Systems (WoRMS) is a workshop that tries to connect researchers who develop systems for reading music, such as in the field of Optical Music Recognition, with other researchers and practitioners that could benefit from such systems, like librarians or musicologists. The relevant topics of interest for the workshop include, but are not limited to: Music reading systems; Optical music recognition; Datasets and performance evaluation; Image processing on music scores; Writer identification; Authoring, editing, storing and presentation systems for music scores; Multi-modal systems; Novel input-methods for music to produce written music; Web-based Music Information Retrieval services; Applications and projects; Use-cases related to written music. These are the proceedings of the 2nd International Workshop on Reading Music Systems, held in Delft on the 2nd of November 2019.
Proceedings of the 3rd International Workshop on Reading Music Systems
Dec 01, 2022The International Workshop on Reading Music Systems (WoRMS) is a workshop that tries to connect researchers who develop systems for reading music, such as in the field of Optical Music Recognition, with other researchers and practitioners that could benefit from such systems, like librarians or musicologists. The relevant topics of interest for the workshop include, but are not limited to: Music reading systems; Optical music recognition; Datasets and performance evaluation; Image processing on music scores; Writer identification; Authoring, editing, storing and presentation systems for music scores; Multi-modal systems; Novel input-methods for music to produce written music; Web-based Music Information Retrieval services; Applications and projects; Use-cases related to written music. These are the proceedings of the 3rd International Workshop on Reading Music Systems, held in Alicante on the 23rd of July 2021.
SSVMR: Saliency-based Self-training for Video-Music Retrieval
Feb 18, 2023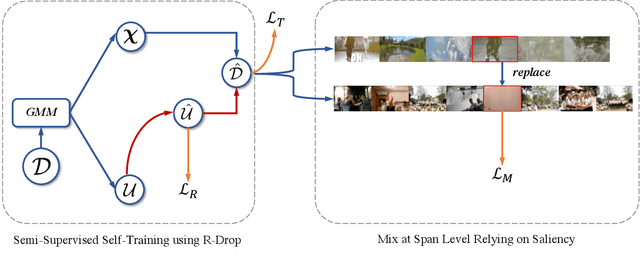
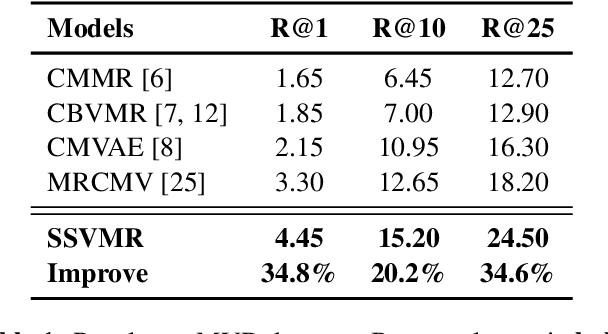
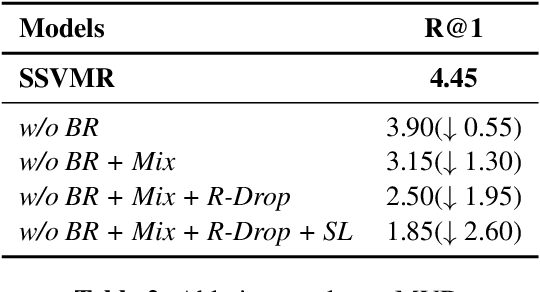

With the rise of short videos, the demand for selecting appropriate background music (BGM) for a video has increased significantly, video-music retrieval (VMR) task gradually draws much attention by research community. As other cross-modal learning tasks, existing VMR approaches usually attempt to measure the similarity between the video and music in the feature space. However, they (1) neglect the inevitable label noise; (2) neglect to enhance the ability to capture critical video clips. In this paper, we propose a novel saliency-based self-training framework, which is termed SSVMR. Specifically, we first explore to fully make use of the information containing in the training dataset by applying a semi-supervised method to suppress the adverse impact of label noise problem, where a self-training approach is adopted. In addition, we propose to capture the saliency of the video by mixing two videos at span level and preserving the locality of the two original videos. Inspired by back translation in NLP, we also conduct back retrieval to obtain more training data. Experimental results on MVD dataset show that our SSVMR achieves the state-of-the-art performance by a large margin, obtaining a relative improvement of 34.8% over the previous best model in terms of R@1.
Sparks of Large Audio Models: A Survey and Outlook
Sep 03, 2023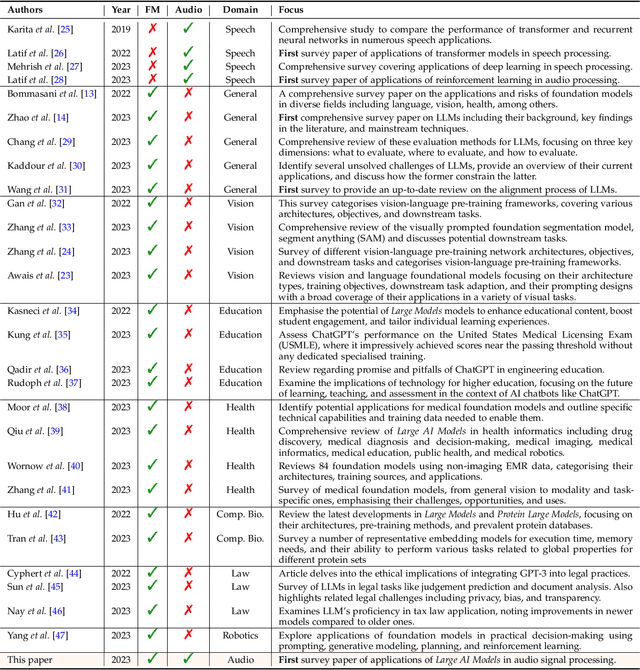

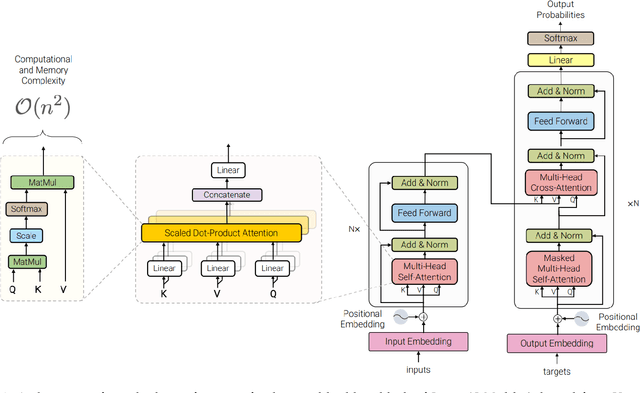
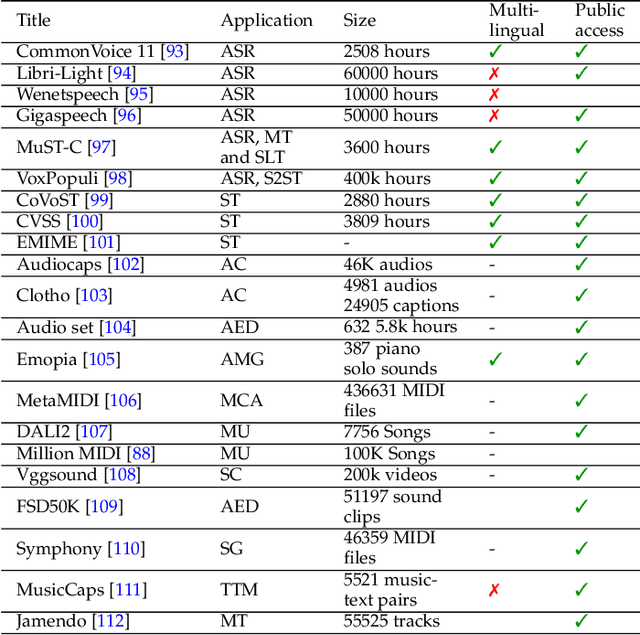
This survey paper provides a comprehensive overview of the recent advancements and challenges in applying large language models to the field of audio signal processing. Audio processing, with its diverse signal representations and a wide range of sources--from human voices to musical instruments and environmental sounds--poses challenges distinct from those found in traditional Natural Language Processing scenarios. Nevertheless, \textit{Large Audio Models}, epitomized by transformer-based architectures, have shown marked efficacy in this sphere. By leveraging massive amount of data, these models have demonstrated prowess in a variety of audio tasks, spanning from Automatic Speech Recognition and Text-To-Speech to Music Generation, among others. Notably, recently these Foundational Audio Models, like SeamlessM4T, have started showing abilities to act as universal translators, supporting multiple speech tasks for up to 100 languages without any reliance on separate task-specific systems. This paper presents an in-depth analysis of state-of-the-art methodologies regarding \textit{Foundational Large Audio Models}, their performance benchmarks, and their applicability to real-world scenarios. We also highlight current limitations and provide insights into potential future research directions in the realm of \textit{Large Audio Models} with the intent to spark further discussion, thereby fostering innovation in the next generation of audio-processing systems. Furthermore, to cope with the rapid development in this area, we will consistently update the relevant repository with relevant recent articles and their open-source implementations at https://github.com/EmulationAI/awesome-large-audio-models.
Proceedings of the 4th International Workshop on Reading Music Systems
Nov 23, 2022The International Workshop on Reading Music Systems (WoRMS) is a workshop that tries to connect researchers who develop systems for reading music, such as in the field of Optical Music Recognition, with other researchers and practitioners that could benefit from such systems, like librarians or musicologists. The relevant topics of interest for the workshop include, but are not limited to: Music reading systems; Optical music recognition; Datasets and performance evaluation; Image processing on music scores; Writer identification; Authoring, editing, storing and presentation systems for music scores; Multi-modal systems; Novel input-methods for music to produce written music; Web-based Music Information Retrieval services; Applications and projects; Use-cases related to written music. These are the proceedings of the 4th International Workshop on Reading Music Systems, held online on Nov. 18th 2022.
Multi-Genre Music Transformer -- Composing Full Length Musical Piece
Jan 06, 2023

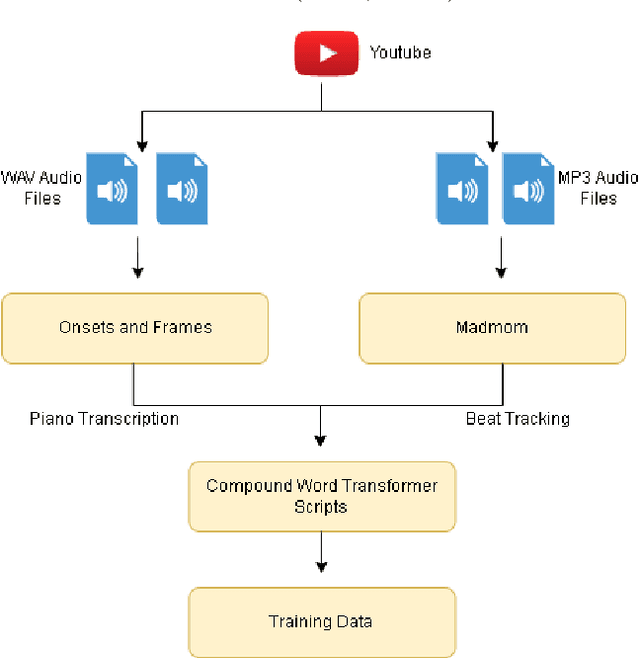
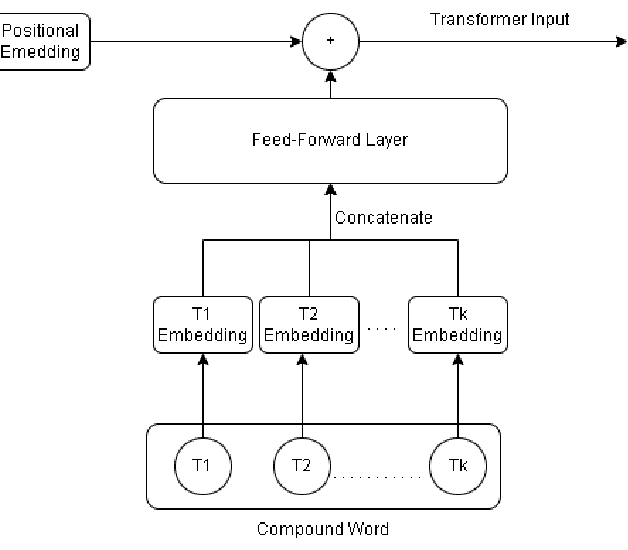
In the task of generating music, the art factor plays a big role and is a great challenge for AI. Previous work involving adversarial training to produce new music pieces and modeling the compatibility of variety in music (beats, tempo, musical stems) demonstrated great examples of learning this task. Though this was limited to generating mashups or learning features from tempo and key distributions to produce similar patterns. Compound Word Transformer was able to represent music generation task as a sequence generation challenge involving musical events defined by compound words. These musical events give a more accurate description of notes progression, chord change, harmony and the art factor. The objective of the project is to implement a Multi-Genre Transformer which learns to produce music pieces through more adaptive learning process involving more challenging task where genres or form of the composition is also considered. We built a multi-genre compound word dataset, implemented a linear transformer which was trained on this dataset. We call this Multi-Genre Transformer, which was able to generate full length new musical pieces which is diverse and comparable to original tracks. The model trains 2-5 times faster than other models discussed.
Learning Music Representations with wav2vec 2.0
Oct 27, 2022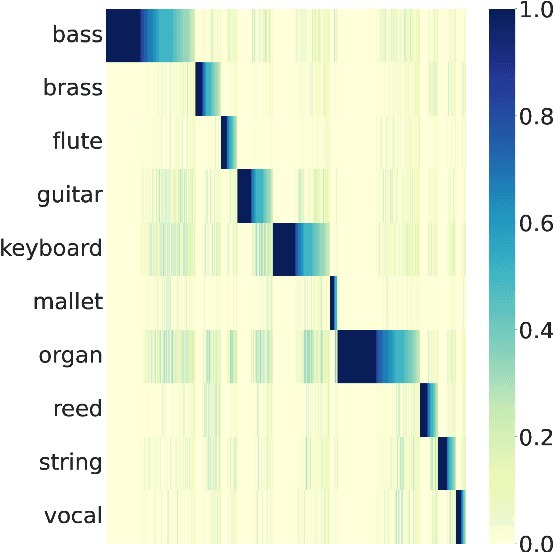
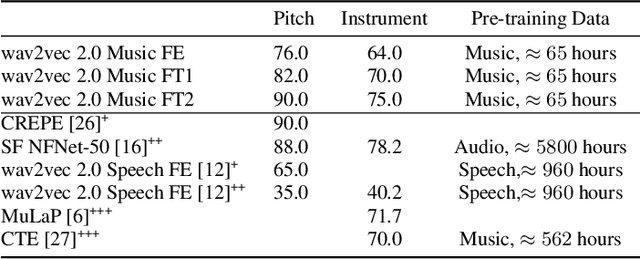
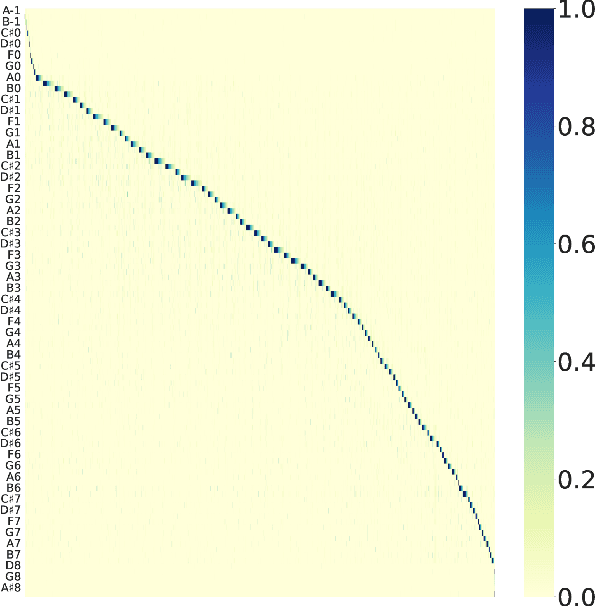
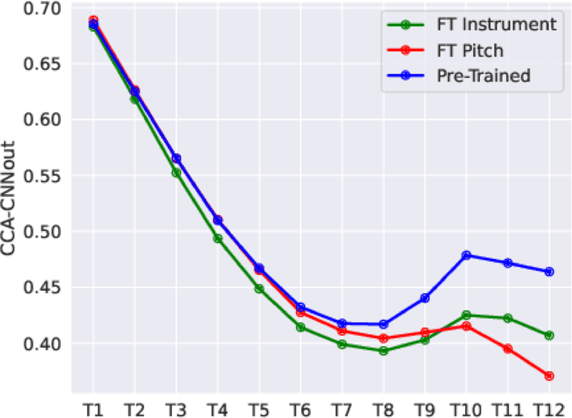
Learning music representations that are general-purpose offers the flexibility to finetune several downstream tasks using smaller datasets. The wav2vec 2.0 speech representation model showed promising results in many downstream speech tasks, but has been less effective when adapted to music. In this paper, we evaluate whether pre-training wav2vec 2.0 directly on music data can be a better solution instead of finetuning the speech model. We illustrate that when pre-training on music data, the discrete latent representations are able to encode the semantic meaning of musical concepts such as pitch and instrument. Our results show that finetuning wav2vec 2.0 pre-trained on music data allows us to achieve promising results on music classification tasks that are competitive with prior work on audio representations. In addition, the results are superior to the pre-trained model on speech embeddings, demonstrating that wav2vec 2.0 pre-trained on music data can be a promising music representation model.
Msanii: High Fidelity Music Synthesis on a Shoestring Budget
Jan 16, 2023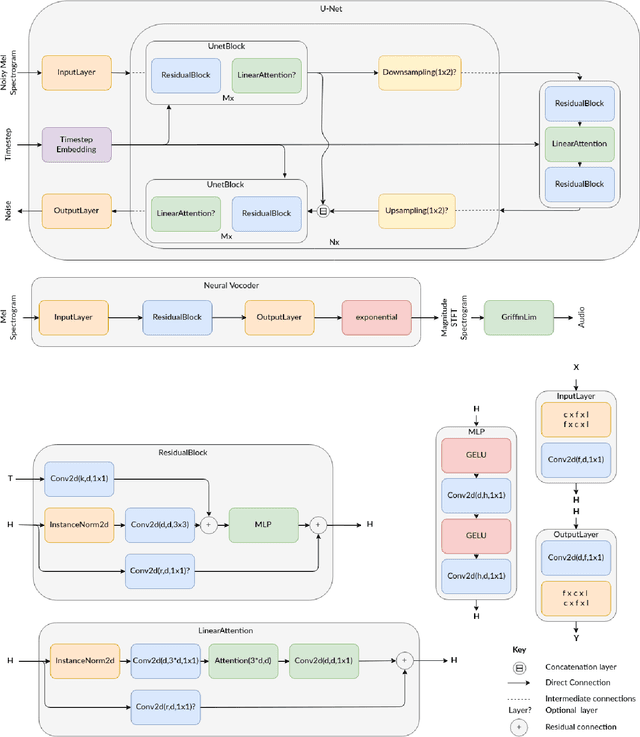
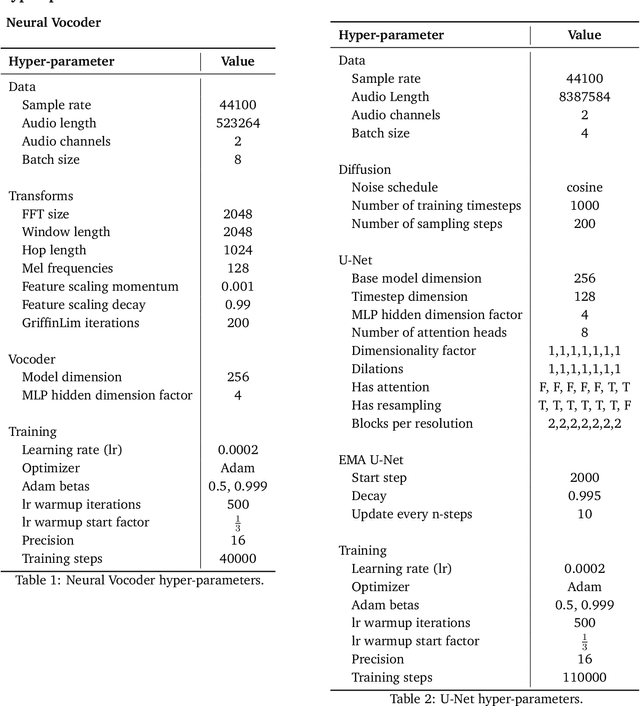
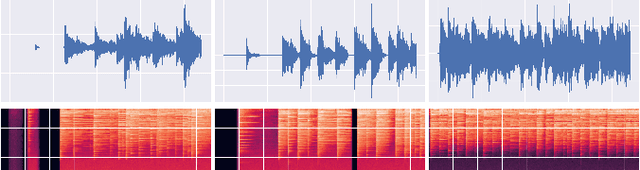

In this paper, we present Msanii, a novel diffusion-based model for synthesizing long-context, high-fidelity music efficiently. Our model combines the expressiveness of mel spectrograms, the generative capabilities of diffusion models, and the vocoding capabilities of neural vocoders. We demonstrate the effectiveness of Msanii by synthesizing tens of seconds (190 seconds) of stereo music at high sample rates (44.1 kHz) without the use of concatenative synthesis, cascading architectures, or compression techniques. To the best of our knowledge, this is the first work to successfully employ a diffusion-based model for synthesizing such long music samples at high sample rates. Our demo can be found https://kinyugo.github.io/msanii-demo and our code https://github.com/Kinyugo/msanii .