 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Natural Language Supervision for General-Purpose Audio Representations
Sep 11, 2023
Audio-Language models jointly learn multimodal text and audio representations that enable Zero-Shot inference. Models rely on the encoders to create powerful representations of the input and generalize to multiple tasks ranging from sounds, music, and speech. Although models have achieved remarkable performance, there is still a performance gap with task-specific models. In this paper, we propose a Contrastive Language-Audio Pretraining model that is pretrained with a diverse collection of 4.6M audio-text pairs employing two innovative encoders for Zero-Shot inference. To learn audio representations, we trained an audio encoder on 22 audio tasks, instead of the standard training of sound event classification. To learn language representations, we trained an autoregressive decoder-only model instead of the standard encoder-only models. Then, the audio and language representations are brought into a joint multimodal space using Contrastive Learning. We used our encoders to improve the downstream performance by a margin. We extensively evaluated the generalization of our representations on 26 downstream tasks, the largest in the literature. Our model achieves state of the art results in several tasks leading the way towards general-purpose audio representations.
Byte Pair Encoding for Symbolic Music
Jan 27, 2023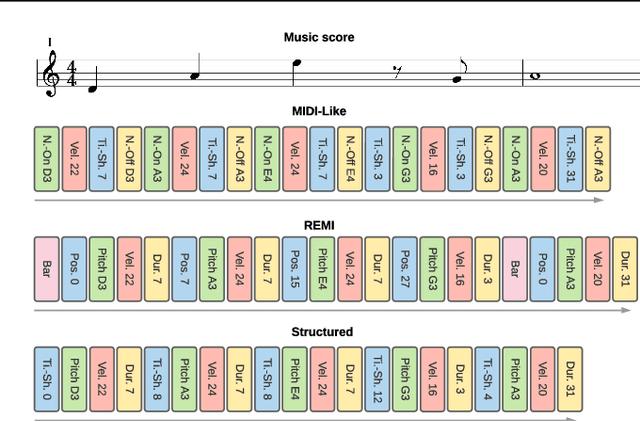
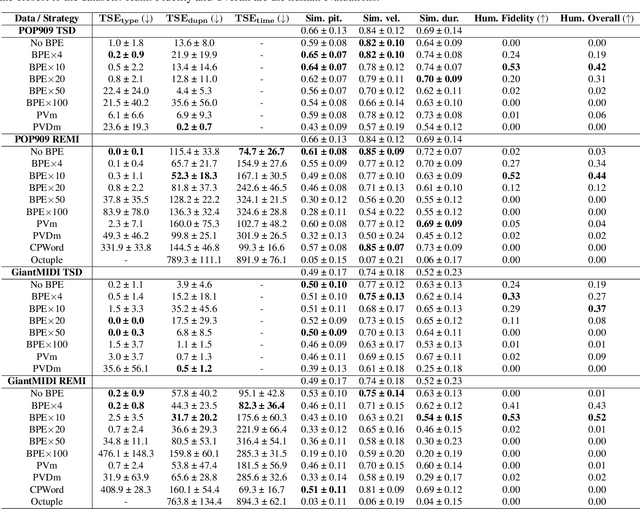
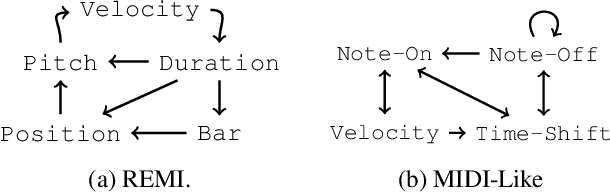
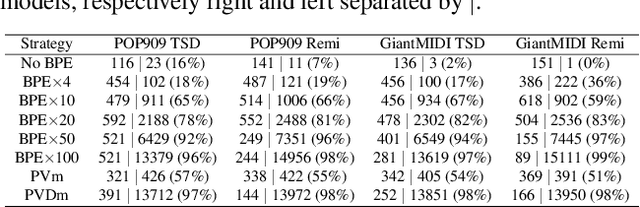
The symbolic music modality is nowadays mostly represented as discrete and used with sequential models such as Transformers, for deep learning tasks. Recent research put efforts on the tokenization, i.e. the conversion of data into sequences of integers intelligible to such models. This can be achieved by many ways as music can be composed of simultaneous tracks, of simultaneous notes with several attributes. Until now, the proposed tokenizations are based on small vocabularies describing the note attributes and time events, resulting in fairly long token sequences. In this paper, we show how Byte Pair Encoding (BPE) can improve the results of deep learning models while improving its performances. We experiment on music generation and composer classification, and study the impact of BPE on how models learn the embeddings, and show that it can help to increase their isotropy, i.e., the uniformity of the variance of their positions in the space.
Low-complexity hardware and algorithm for joint communication and sensing
Sep 13, 2023Joint Communication and Sensing (JCAS) is foreseen as one very distinctive feature of the emerging 6G systems providing, in addition to fast end reliable communication, the ability to obtain an accurate perception of the physical environment. In this paper, we propose a JCAS algorithm that exploits a novel beamforming architecture, which features a combination of wideband analog and narrowband digital beamforming. This allows accurate estimation of Time of Arrival (ToA), exploiting the large bandwidth and Angle of Arrival (AoA), exploiting the high-rank digital beamforming. In our proposal, we separately estimate the ToA and AoA. The association between ToA and AoA is solved by acquiring multiple non-coherent frames and adding up the signal from each frame such that a specific component is combined coherently before the AoA estimation. Consequently, this removes the need to use 2D and 3D joint estimation methods, thus significantly lowering complexity. The resolution performance of the method is compared with that of 2D MUltiple SIgnal Classification (2D-MUSIC) algorithm, using a fully-digital wideband beamforming architecture. The results show that the proposed method can achieve performance similar to a fully-digital high-bandwidth system, while requiring a fraction of the total aggregate sampling rate and having much lower complexity.
A Domain-Knowledge-Inspired Music Embedding Space and a Novel Attention Mechanism for Symbolic Music Modeling
Dec 02, 2022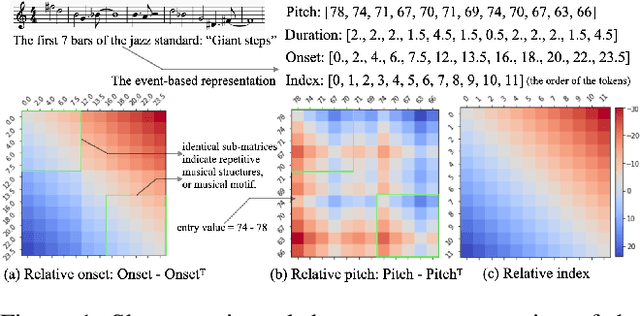
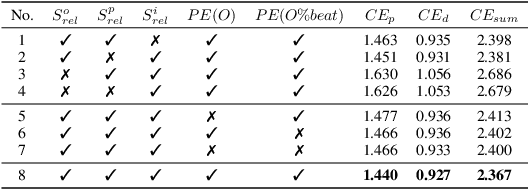
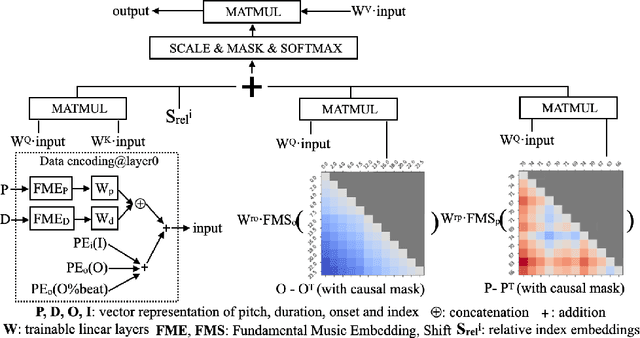
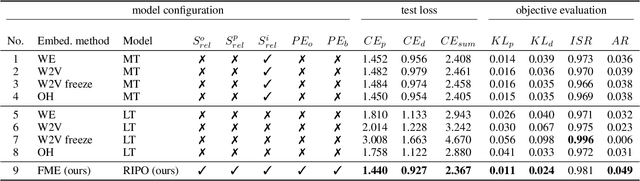
Following the success of the transformer architecture in the natural language domain, transformer-like architectures have been widely applied to the domain of symbolic music recently. Symbolic music and text, however, are two different modalities. Symbolic music contains multiple attributes, both absolute attributes (e.g., pitch) and relative attributes (e.g., pitch interval). These relative attributes shape human perception of musical motifs. These important relative attributes, however, are mostly ignored in existing symbolic music modeling methods with the main reason being the lack of a musically-meaningful embedding space where both the absolute and relative embeddings of the symbolic music tokens can be efficiently represented. In this paper, we propose the Fundamental Music Embedding (FME) for symbolic music based on a bias-adjusted sinusoidal encoding within which both the absolute and the relative attributes can be embedded and the fundamental musical properties (e.g., translational invariance) are explicitly preserved. Taking advantage of the proposed FME, we further propose a novel attention mechanism based on the relative index, pitch and onset embeddings (RIPO attention) such that the musical domain knowledge can be fully utilized for symbolic music modeling. Experiment results show that our proposed model: RIPO transformer which utilizes FME and RIPO attention outperforms the state-of-the-art transformers (i.e., music transformer, linear transformer) in a melody completion task. Moreover, using the RIPO transformer in a downstream music generation task, we notice that the notorious degeneration phenomenon no longer exists and the music generated by the RIPO transformer outperforms the music generated by state-of-the-art transformer models in both subjective and objective evaluations.
Frequency Estimation Using Complex-Valued Shifted Window Transformer
Sep 17, 2023Estimating closely spaced frequency components of a signal is a fundamental problem in statistical signal processing. In this letter, we introduce 1-D real-valued and complex-valued shifted window (Swin) transformers, referred to as SwinFreq and CVSwinFreq, respectively, for line-spectra frequency estimation on 1-D complex-valued signals. Whereas 2-D Swin transformer-based models have gained traction for optical image super-resolution, we introduce for the first time a complex-valued Swin module designed to leverage the complex-valued nature of signals for a wide array of applications. The proposed approach overcomes the limitations of the classical algorithms such as the periodogram, MUSIC, and OMP in addition to state-of-the-art deep learning approach cResFreq. SwinFreq and CVSwinFreq boast superior performance at low signal-to-noise ratio SNR and improved resolution capability while requiring fewer model parameters than cResFreq, thus deeming it more suitable for edge and mobile applications. We find that the real-valued Swin-Freq outperforms its complex-valued counterpart CVSwinFreq for several tasks while touting a smaller model size. Finally, we apply the proposed techniques for radar range profile super-resolution using real data. The results from both synthetic and real experimentation validate the numerical and empirical superiority of SwinFreq and CVSwinFreq to the state-of-the-art deep learning-based techniques and traditional frequency estimation algorithms. The code and models are publicly available at https://github.com/josiahwsmith10/spectral-super-resolution-swin.
Quid Manumit -- Freeing the Qubit for Art
Sep 04, 2023This paper describes how to `Free the Qubit' for art, by creating standalone quantum musical effects and instruments. Previously released quantum simulator code for an ARM-based Raspberry Pi Pico embedded microcontroller is utilised here, and several examples are built demonstrating different methods of utilising embedded resources: The first is a Quantum MIDI processor that generates additional notes for accompaniment and unique quantum generated instruments based on the input notes, decoded and passed through a quantum circuit in an embedded simulator. The second is a Quantum Distortion module that changes an instrument's raw sound according to a quantum circuit, which is presented in two forms; a self-contained Quantum Stylophone, and an effect module plugin called 'QubitCrusher' for the Korg Nu:Tekt NTS-1. This paper also discusses future work and directions for quantum instruments, and provides all examples as open source. This is, to the author's knowledge, the first example of embedded Quantum Simulators for Instruments of Music (another QSIM).
Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion
Jan 30, 2023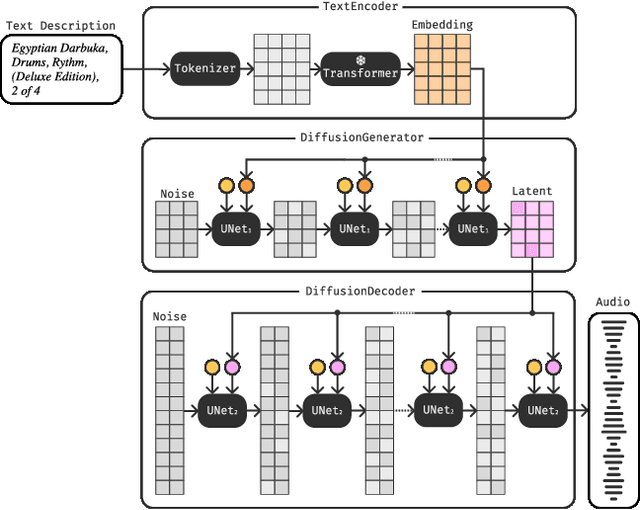
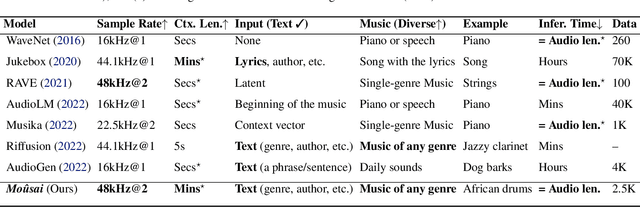
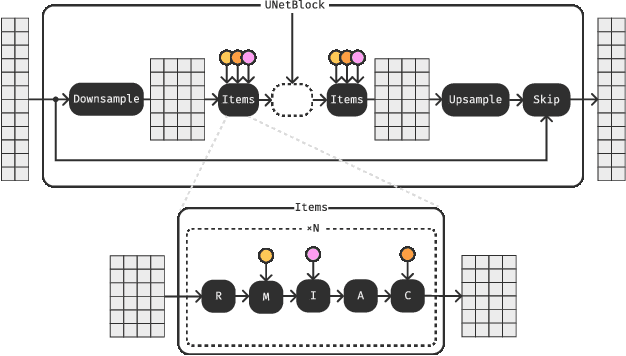

The recent surge in popularity of diffusion models for image generation has brought new attention to the potential of these models in other areas of media synthesis. One area that has yet to be fully explored is the application of diffusion models to music generation. Music generation requires to handle multiple aspects, including the temporal dimension, long-term structure, multiple layers of overlapping sounds, and nuances that only trained listeners can detect. In our work, we investigate the potential of diffusion models for text-conditional music generation. We develop a cascading latent diffusion approach that can generate multiple minutes of high-quality stereo music at 48kHz from textual descriptions. For each model, we make an effort to maintain reasonable inference speed, targeting real-time on a single consumer GPU. In addition to trained models, we provide a collection of open-source libraries with the hope of facilitating future work in the field. We open-source the following: Music samples for this paper: https://bit.ly/anonymous-mousai; all music samples for all models: https://bit.ly/audio-diffusion; and codes: https://github.com/archinetai/audio-diffusion-pytorch
Music-to-Text Synaesthesia: Generating Descriptive Text from Music Recordings
Oct 02, 2022
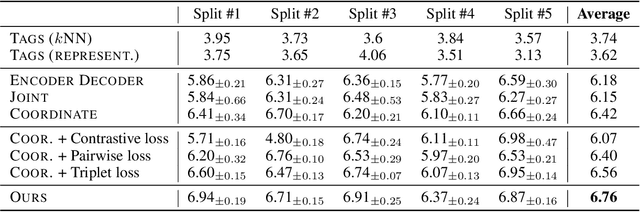
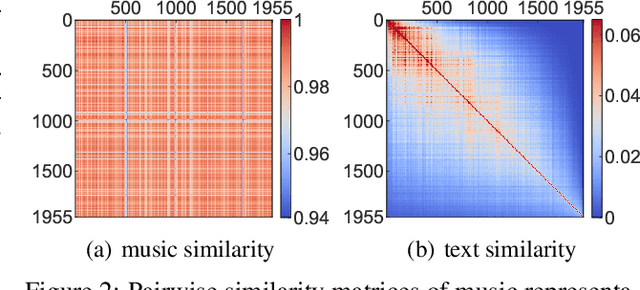

In this paper, we consider a novel research problem, music-to-text synaesthesia. Different from the classical music tagging problem that classifies a music recording into pre-defined categories, the music-to-text synaesthesia aims to generate descriptive texts from music recordings for further understanding. Although this is a new and interesting application to the machine learning community, to our best knowledge, the existing music-related datasets do not contain the semantic descriptions on music recordings and cannot serve the music-to-text synaesthesia task. In light of this, we collect a new dataset that contains 1,955 aligned pairs of classical music recordings and text descriptions. Based on this, we build a computational model to generate sentences that can describe the content of the music recording. To tackle the highly non-discriminative classical music, we design a group topology-preservation loss in our computational model, which considers more samples as a group reference and preserves the relative topology among different samples. Extensive experimental results qualitatively and quantitatively demonstrate the effectiveness of our proposed model over five heuristics or pre-trained competitive methods and their variants on our collected dataset.
Mood Classification of Bangla Songs Based on Lyrics
Jul 19, 2023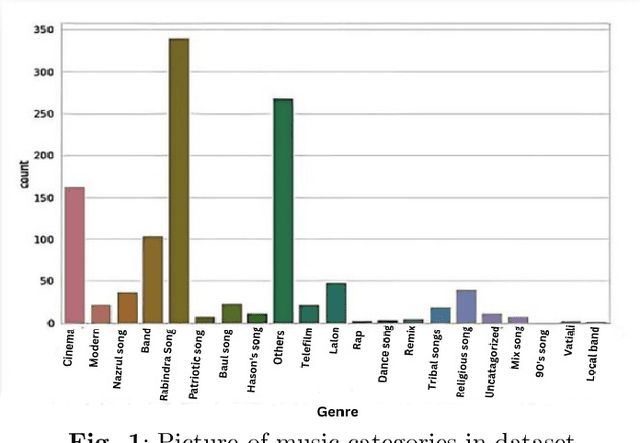
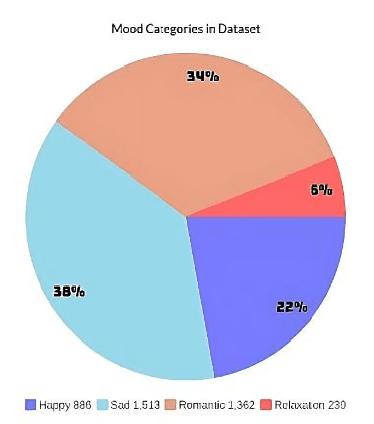
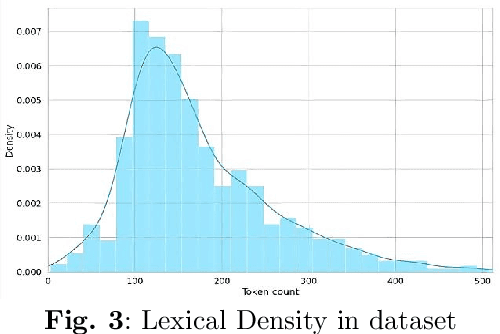
Music can evoke various emotions, and with the advancement of technology, it has become more accessible to people. Bangla music, which portrays different human emotions, lacks sufficient research. The authors of this article aim to analyze Bangla songs and classify their moods based on the lyrics. To achieve this, this research has compiled a dataset of 4000 Bangla song lyrics, genres, and used Natural Language Processing and the Bert Algorithm to analyze the data. Among the 4000 songs, 1513 songs are represented for the sad mood, 1362 for the romantic mood, 886 for happiness, and the rest 239 are classified as relaxation. By embedding the lyrics of the songs, the authors have classified the songs into four moods: Happy, Sad, Romantic, and Relaxed. This research is crucial as it enables a multi-class classification of songs' moods, making the music more relatable to people's emotions. The article presents the automated result of the four moods accurately derived from the song lyrics.
Why People Skip Music? On Predicting Music Skips using Deep Reinforcement Learning
Jan 10, 2023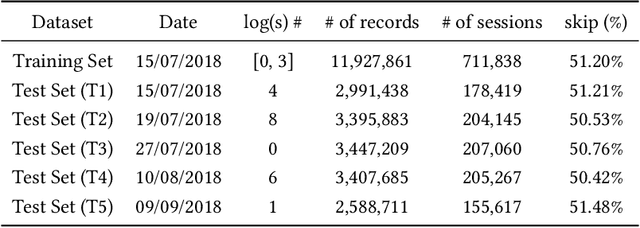
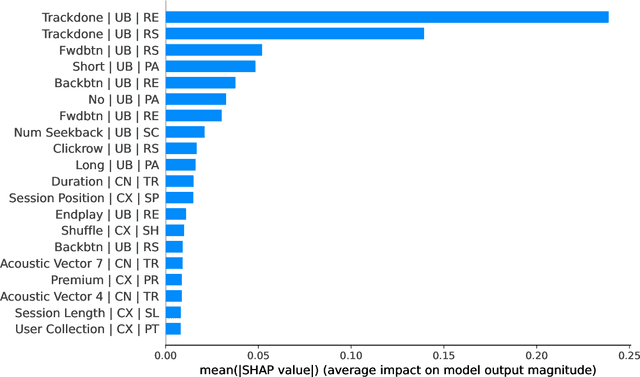
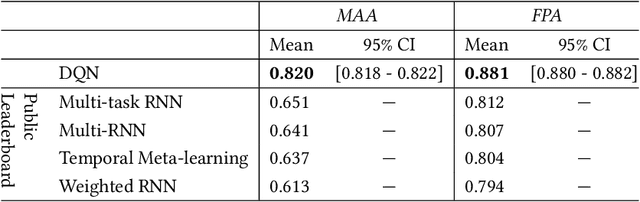
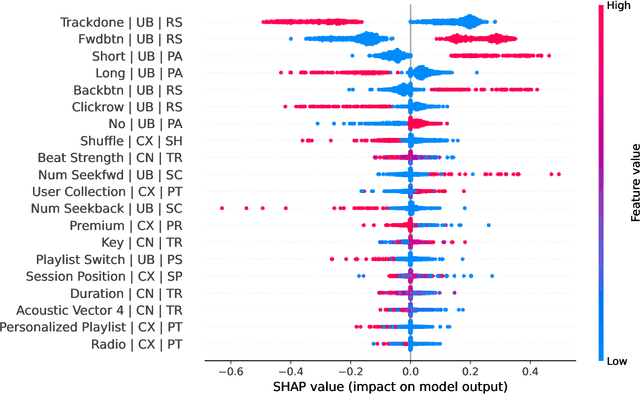
Music recommender systems are an integral part of our daily life. Recent research has seen a significant effort around black-box recommender based approaches such as Deep Reinforcement Learning (DRL). These advances have led, together with the increasing concerns around users' data collection and privacy, to a strong interest in building responsible recommender systems. A key element of a successful music recommender system is modelling how users interact with streamed content. By first understanding these interactions, insights can be drawn to enable the construction of more transparent and responsible systems. An example of these interactions is skipping behaviour, a signal that can measure users' satisfaction, dissatisfaction, or lack of interest. In this paper, we study the utility of users' historical data for the task of sequentially predicting users' skipping behaviour. To this end, we adapt DRL for this classification task, followed by a post-hoc explainability (SHAP) and ablation analysis of the input state representation. Experimental results from a real-world music streaming dataset (Spotify) demonstrate the effectiveness of our approach in this task by outperforming state-of-the-art models. A comprehensive analysis of our approach and of users' historical data reveals a temporal data leakage problem in the dataset. Our findings indicate that, overall, users' behaviour features are the most discriminative in how our proposed DRL model predicts music skips. Content and contextual features have a lesser effect. This suggests that a limited amount of user data should be collected and leveraged to predict skipping behaviour.