 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Mood Classification of Bangla Songs Based on Lyrics
Jul 19, 2023
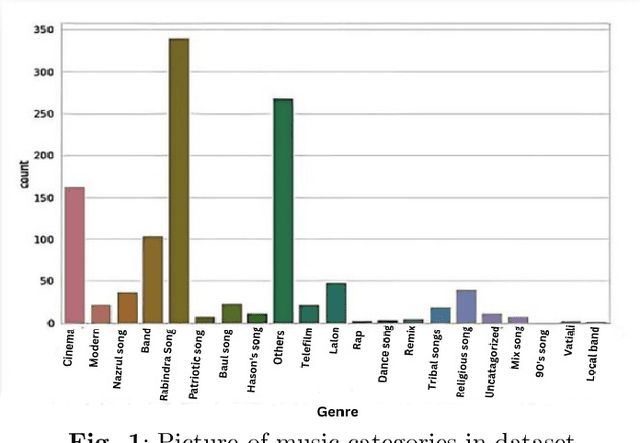
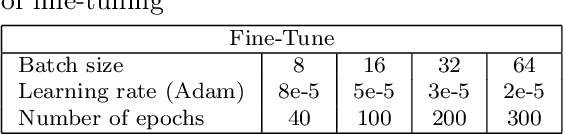
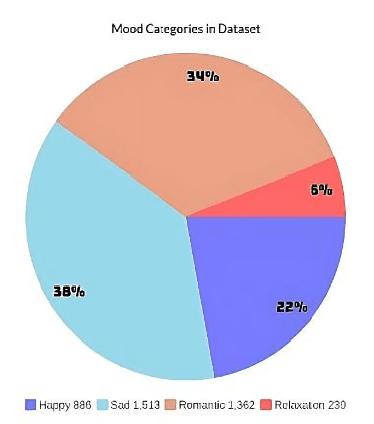
Music can evoke various emotions, and with the advancement of technology, it has become more accessible to people. Bangla music, which portrays different human emotions, lacks sufficient research. The authors of this article aim to analyze Bangla songs and classify their moods based on the lyrics. To achieve this, this research has compiled a dataset of 4000 Bangla song lyrics, genres, and used Natural Language Processing and the Bert Algorithm to analyze the data. Among the 4000 songs, 1513 songs are represented for the sad mood, 1362 for the romantic mood, 886 for happiness, and the rest 239 are classified as relaxation. By embedding the lyrics of the songs, the authors have classified the songs into four moods: Happy, Sad, Romantic, and Relaxed. This research is crucial as it enables a multi-class classification of songs' moods, making the music more relatable to people's emotions. The article presents the automated result of the four moods accurately derived from the song lyrics.
Byte Pair Encoding for Symbolic Music
Jan 27, 2023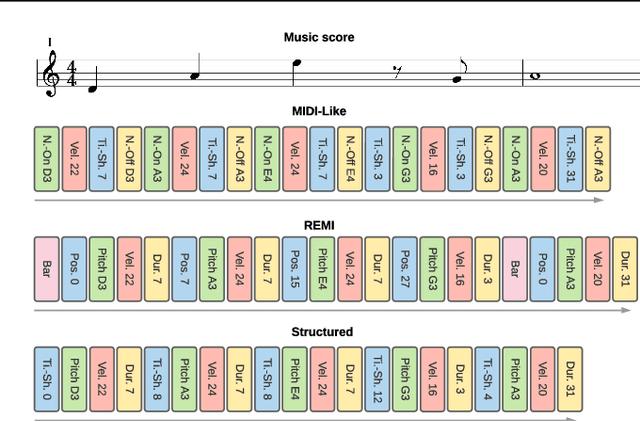
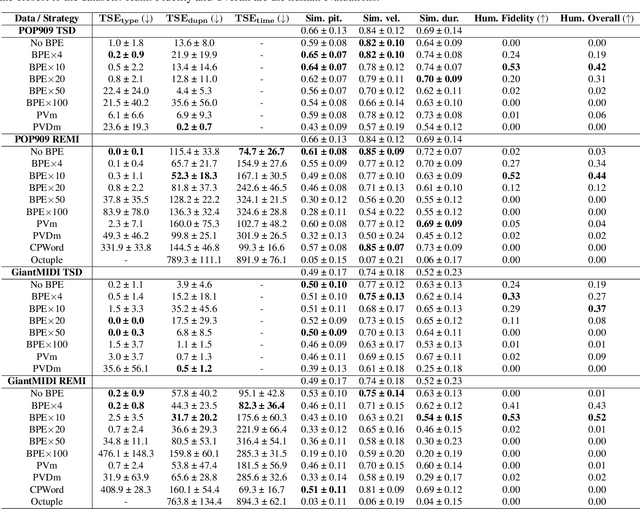
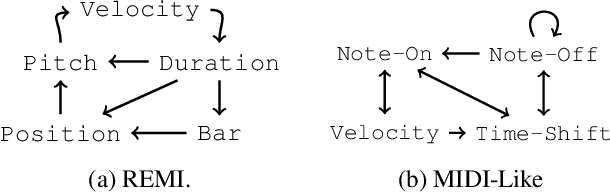
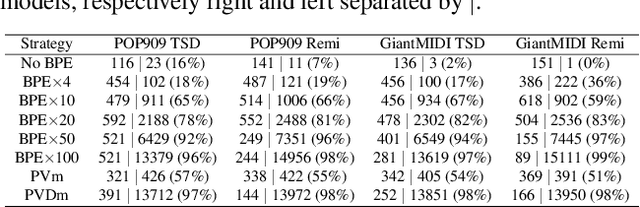
The symbolic music modality is nowadays mostly represented as discrete and used with sequential models such as Transformers, for deep learning tasks. Recent research put efforts on the tokenization, i.e. the conversion of data into sequences of integers intelligible to such models. This can be achieved by many ways as music can be composed of simultaneous tracks, of simultaneous notes with several attributes. Until now, the proposed tokenizations are based on small vocabularies describing the note attributes and time events, resulting in fairly long token sequences. In this paper, we show how Byte Pair Encoding (BPE) can improve the results of deep learning models while improving its performances. We experiment on music generation and composer classification, and study the impact of BPE on how models learn the embeddings, and show that it can help to increase their isotropy, i.e., the uniformity of the variance of their positions in the space.
ComMU: Dataset for Combinatorial Music Generation
Nov 17, 2022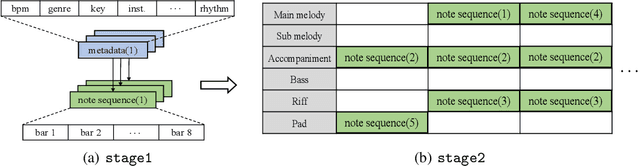
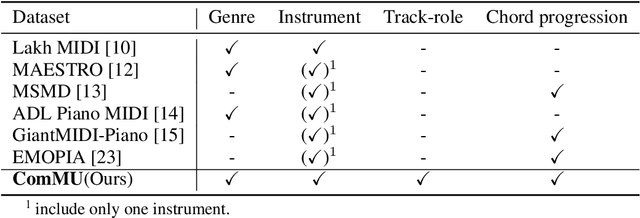


Commercial adoption of automatic music composition requires the capability of generating diverse and high-quality music suitable for the desired context (e.g., music for romantic movies, action games, restaurants, etc.). In this paper, we introduce combinatorial music generation, a new task to create varying background music based on given conditions. Combinatorial music generation creates short samples of music with rich musical metadata, and combines them to produce a complete music. In addition, we introduce ComMU, the first symbolic music dataset consisting of short music samples and their corresponding 12 musical metadata for combinatorial music generation. Notable properties of ComMU are that (1) dataset is manually constructed by professional composers with an objective guideline that induces regularity, and (2) it has 12 musical metadata that embraces composers' intentions. Our results show that we can generate diverse high-quality music only with metadata, and that our unique metadata such as track-role and extended chord quality improves the capacity of the automatic composition. We highly recommend watching our video before reading the paper (https://pozalabs.github.io/ComMU).
On the Consistency of Average Embeddings for Item Recommendation
Aug 24, 2023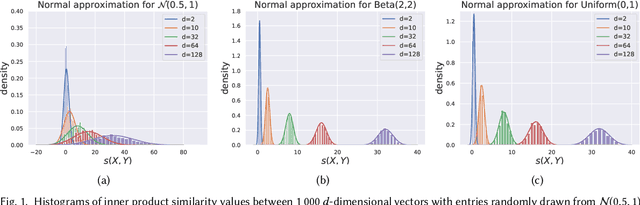
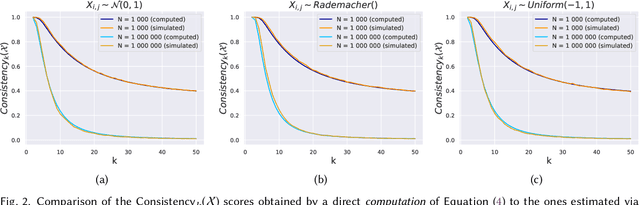
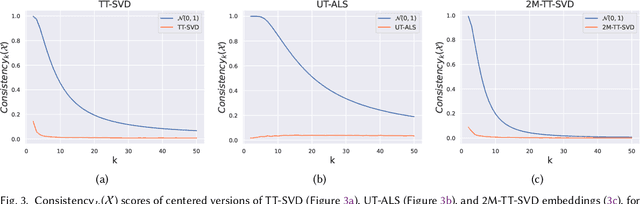
A prevalent practice in recommender systems consists of averaging item embeddings to represent users or higher-level concepts in the same embedding space. This paper investigates the relevance of such a practice. For this purpose, we propose an expected precision score, designed to measure the consistency of an average embedding relative to the items used for its construction. We subsequently analyze the mathematical expression of this score in a theoretical setting with specific assumptions, as well as its empirical behavior on real-world data from music streaming services. Our results emphasize that real-world averages are less consistent for recommendation, which paves the way for future research to better align real-world embeddings with assumptions from our theoretical setting.
A Domain-Knowledge-Inspired Music Embedding Space and a Novel Attention Mechanism for Symbolic Music Modeling
Dec 02, 2022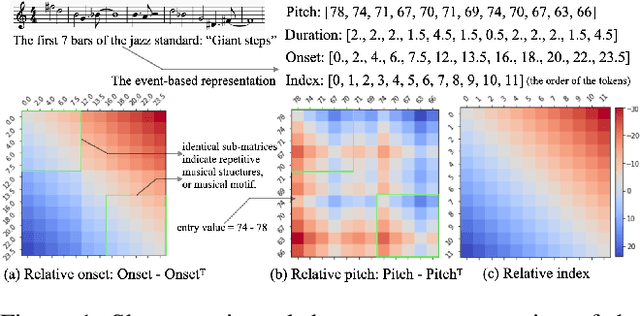
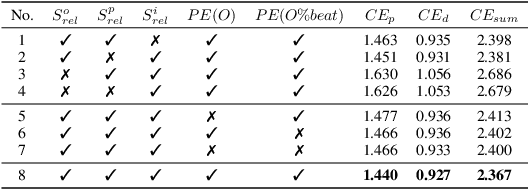
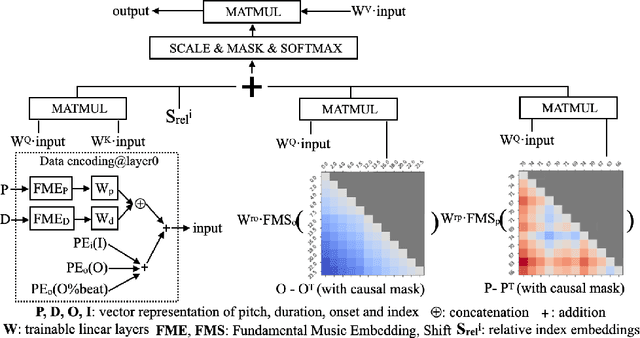
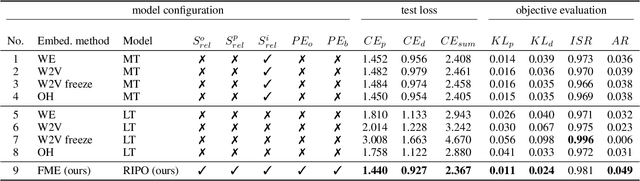
Following the success of the transformer architecture in the natural language domain, transformer-like architectures have been widely applied to the domain of symbolic music recently. Symbolic music and text, however, are two different modalities. Symbolic music contains multiple attributes, both absolute attributes (e.g., pitch) and relative attributes (e.g., pitch interval). These relative attributes shape human perception of musical motifs. These important relative attributes, however, are mostly ignored in existing symbolic music modeling methods with the main reason being the lack of a musically-meaningful embedding space where both the absolute and relative embeddings of the symbolic music tokens can be efficiently represented. In this paper, we propose the Fundamental Music Embedding (FME) for symbolic music based on a bias-adjusted sinusoidal encoding within which both the absolute and the relative attributes can be embedded and the fundamental musical properties (e.g., translational invariance) are explicitly preserved. Taking advantage of the proposed FME, we further propose a novel attention mechanism based on the relative index, pitch and onset embeddings (RIPO attention) such that the musical domain knowledge can be fully utilized for symbolic music modeling. Experiment results show that our proposed model: RIPO transformer which utilizes FME and RIPO attention outperforms the state-of-the-art transformers (i.e., music transformer, linear transformer) in a melody completion task. Moreover, using the RIPO transformer in a downstream music generation task, we notice that the notorious degeneration phenomenon no longer exists and the music generated by the RIPO transformer outperforms the music generated by state-of-the-art transformer models in both subjective and objective evaluations.
Dance with You: The Diversity Controllable Dancer Generation via Diffusion Models
Aug 23, 2023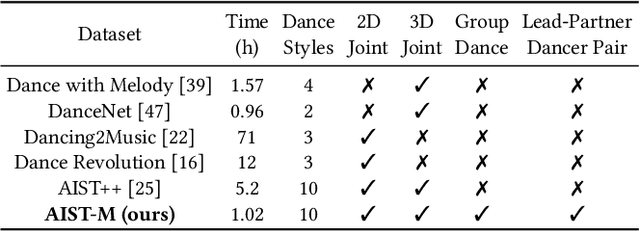
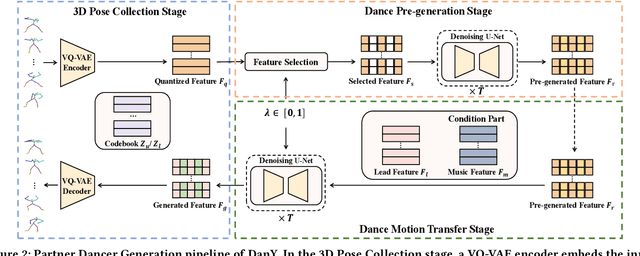
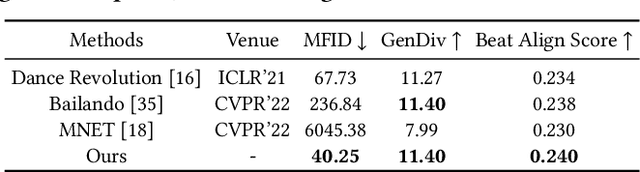
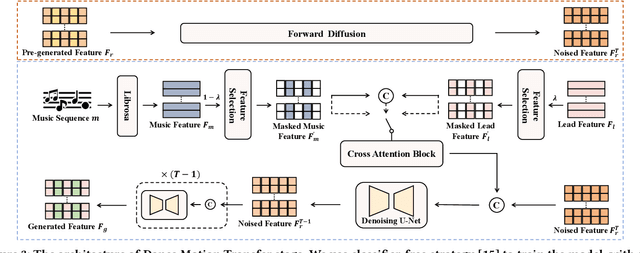
Recently, digital humans for interpersonal interaction in virtual environments have gained significant attention. In this paper, we introduce a novel multi-dancer synthesis task called partner dancer generation, which involves synthesizing virtual human dancers capable of performing dance with users. The task aims to control the pose diversity between the lead dancer and the partner dancer. The core of this task is to ensure the controllable diversity of the generated partner dancer while maintaining temporal coordination with the lead dancer. This scenario varies from earlier research in generating dance motions driven by music, as our emphasis is on automatically designing partner dancer postures according to pre-defined diversity, the pose of lead dancer, as well as the accompanying tunes. To achieve this objective, we propose a three-stage framework called Dance-with-You (DanY). Initially, we employ a 3D Pose Collection stage to collect a wide range of basic dance poses as references for motion generation. Then, we introduce a hyper-parameter that coordinates the similarity between dancers by masking poses to prevent the generation of sequences that are over-diverse or consistent. To avoid the rigidity of movements, we design a Dance Pre-generated stage to pre-generate these masked poses instead of filling them with zeros. After that, a Dance Motion Transfer stage is adopted with leader sequences and music, in which a multi-conditional sampling formula is rewritten to transfer the pre-generated poses into a sequence with a partner style. In practice, to address the lack of multi-person datasets, we introduce AIST-M, a new dataset for partner dancer generation, which is publicly availiable. Comprehensive evaluations on our AIST-M dataset demonstrate that the proposed DanY can synthesize satisfactory partner dancer results with controllable diversity.
Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion
Jan 30, 2023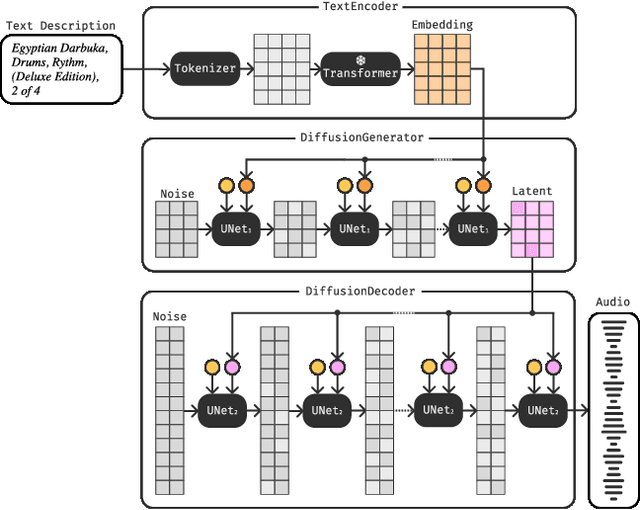
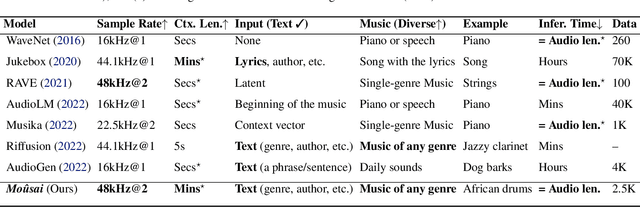
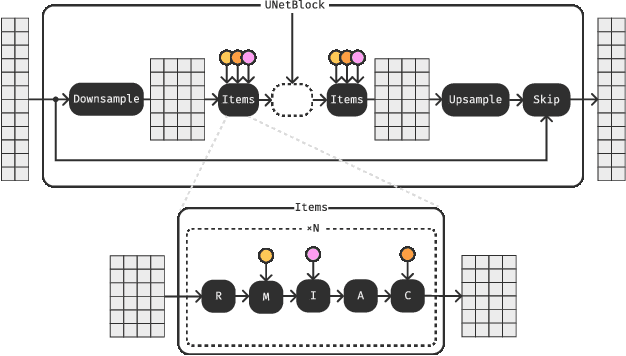

The recent surge in popularity of diffusion models for image generation has brought new attention to the potential of these models in other areas of media synthesis. One area that has yet to be fully explored is the application of diffusion models to music generation. Music generation requires to handle multiple aspects, including the temporal dimension, long-term structure, multiple layers of overlapping sounds, and nuances that only trained listeners can detect. In our work, we investigate the potential of diffusion models for text-conditional music generation. We develop a cascading latent diffusion approach that can generate multiple minutes of high-quality stereo music at 48kHz from textual descriptions. For each model, we make an effort to maintain reasonable inference speed, targeting real-time on a single consumer GPU. In addition to trained models, we provide a collection of open-source libraries with the hope of facilitating future work in the field. We open-source the following: Music samples for this paper: https://bit.ly/anonymous-mousai; all music samples for all models: https://bit.ly/audio-diffusion; and codes: https://github.com/archinetai/audio-diffusion-pytorch
Real-time auralization for performers on virtual stages
Sep 06, 2023This article presents an interactive system for stage acoustics experimentation including considerations for hearing one's own and others' instruments. The quality of real-time auralization systems for psychophysical experiments on music performance depends on the system's calibration and latency, among other factors (e.g. visuals, simulation methods, haptics, etc). The presented system focuses on the acoustic considerations for laboratory implementations. The calibration is implemented as a set of filters accounting for the microphone-instrument distances and the directivity factors, as well as the transducers' frequency responses. Moreover, sources of errors are characterized using both state-of-the-art information and derivations from the mathematical definition of the calibration filter. In order to compensate for hardware latency without cropping parts of the simulated impulse responses, the virtual direct sound of musicians hearing themselves is skipped from the simulation and addressed by letting the actual direct sound reach the listener through open headphones. The required latency compensation of the interactive part (i.e. hearing others) meets the minimum distance requirement between musicians, which is 2 m for the implemented system. Finally, a proof of concept is provided that includes objective and subjective experiments, which give support to the feasibility of the proposed setup.
Music-to-Text Synaesthesia: Generating Descriptive Text from Music Recordings
Oct 02, 2022
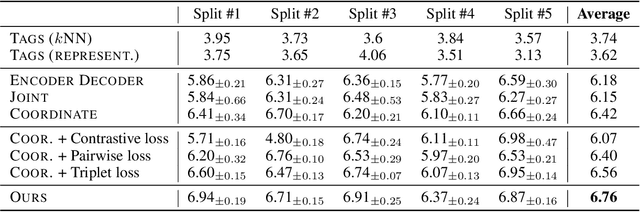
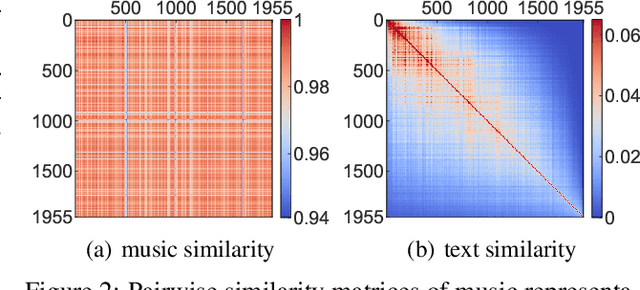

In this paper, we consider a novel research problem, music-to-text synaesthesia. Different from the classical music tagging problem that classifies a music recording into pre-defined categories, the music-to-text synaesthesia aims to generate descriptive texts from music recordings for further understanding. Although this is a new and interesting application to the machine learning community, to our best knowledge, the existing music-related datasets do not contain the semantic descriptions on music recordings and cannot serve the music-to-text synaesthesia task. In light of this, we collect a new dataset that contains 1,955 aligned pairs of classical music recordings and text descriptions. Based on this, we build a computational model to generate sentences that can describe the content of the music recording. To tackle the highly non-discriminative classical music, we design a group topology-preservation loss in our computational model, which considers more samples as a group reference and preserves the relative topology among different samples. Extensive experimental results qualitatively and quantitatively demonstrate the effectiveness of our proposed model over five heuristics or pre-trained competitive methods and their variants on our collected dataset.
Why People Skip Music? On Predicting Music Skips using Deep Reinforcement Learning
Jan 10, 2023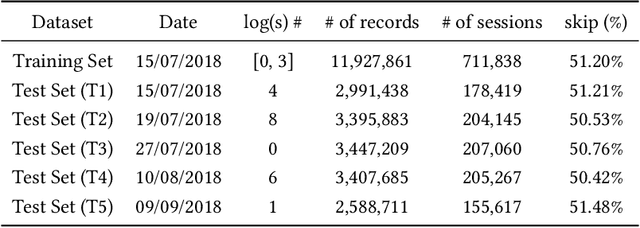
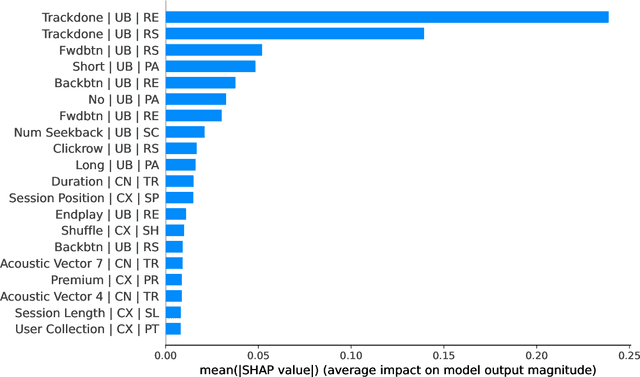
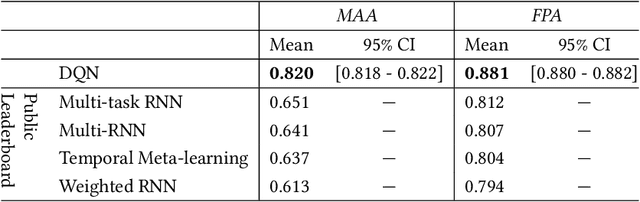
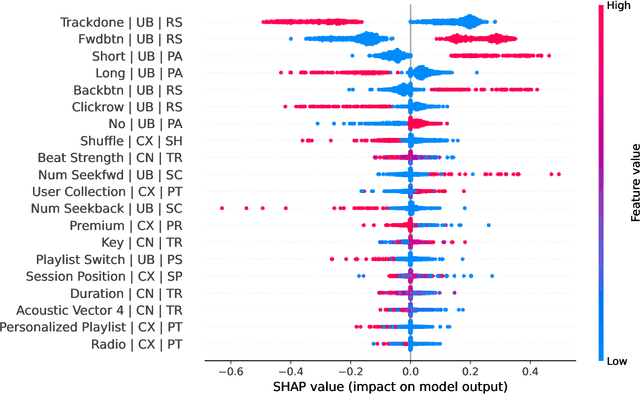
Music recommender systems are an integral part of our daily life. Recent research has seen a significant effort around black-box recommender based approaches such as Deep Reinforcement Learning (DRL). These advances have led, together with the increasing concerns around users' data collection and privacy, to a strong interest in building responsible recommender systems. A key element of a successful music recommender system is modelling how users interact with streamed content. By first understanding these interactions, insights can be drawn to enable the construction of more transparent and responsible systems. An example of these interactions is skipping behaviour, a signal that can measure users' satisfaction, dissatisfaction, or lack of interest. In this paper, we study the utility of users' historical data for the task of sequentially predicting users' skipping behaviour. To this end, we adapt DRL for this classification task, followed by a post-hoc explainability (SHAP) and ablation analysis of the input state representation. Experimental results from a real-world music streaming dataset (Spotify) demonstrate the effectiveness of our approach in this task by outperforming state-of-the-art models. A comprehensive analysis of our approach and of users' historical data reveals a temporal data leakage problem in the dataset. Our findings indicate that, overall, users' behaviour features are the most discriminative in how our proposed DRL model predicts music skips. Content and contextual features have a lesser effect. This suggests that a limited amount of user data should be collected and leveraged to predict skipping behaviour.