 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Enhancing Expressiveness in Dance Generation via Integrating Frequency and Music Style Information
Mar 09, 2024
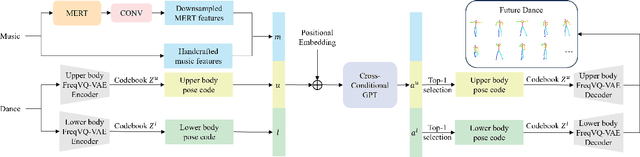
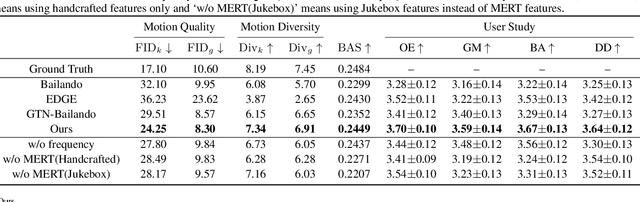
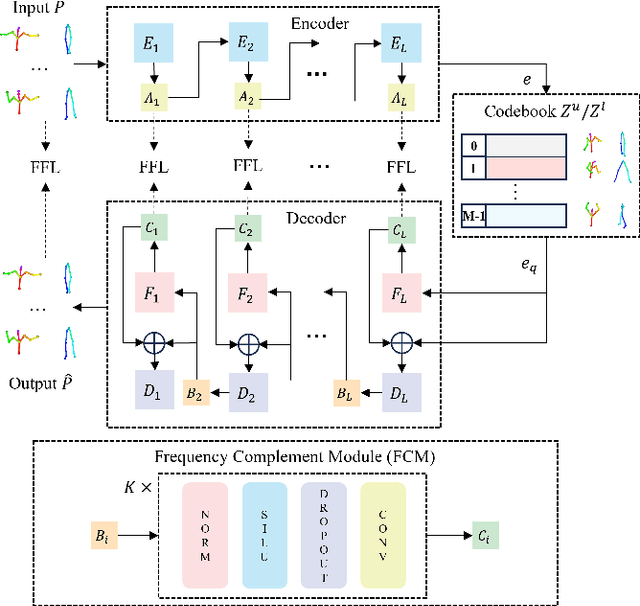

Dance generation, as a branch of human motion generation, has attracted increasing attention. Recently, a few works attempt to enhance dance expressiveness, which includes genre matching, beat alignment, and dance dynamics, from certain aspects. However, the enhancement is quite limited as they lack comprehensive consideration of the aforementioned three factors. In this paper, we propose ExpressiveBailando, a novel dance generation method designed to generate expressive dances, concurrently taking all three factors into account. Specifically, we mitigate the issue of speed homogenization by incorporating frequency information into VQ-VAE, thus improving dance dynamics. Additionally, we integrate music style information by extracting genre- and beat-related features with a pre-trained music model, hence achieving improvements in the other two factors. Extensive experimental results demonstrate that our proposed method can generate dances with high expressiveness and outperforms existing methods both qualitatively and quantitatively.
Measuring audio prompt adherence with distribution-based embedding distances
Apr 04, 2024An increasing number of generative music models can be conditioned on an audio prompt that serves as musical context for which the model is to create an accompaniment (often further specified using a text prompt). Evaluation of how well model outputs adhere to the audio prompt is often done in a model or problem specific manner, presumably because no generic evaluation method for audio prompt adherence has emerged. Such a method could be useful both in the development and training of new models, and to make performance comparable across models. In this paper we investigate whether commonly used distribution-based distances like Fr\'echet Audio Distance (FAD), can be used to measure audio prompt adherence. We propose a simple procedure based on a small number of constituents (an embedding model, a projection, an embedding distance, and a data fusion method), that we systematically assess using a baseline validation. In a follow-up experiment we test the sensitivity of the proposed audio adherence measure to pitch and time shift perturbations. The results show that the proposed measure is sensitive to such perturbations, even when the reference and candidate distributions are from different music collections. Although more experimentation is needed to answer unaddressed questions like the robustness of the measure to acoustic artifacts that do not affect the audio prompt adherence, the current results suggest that distribution-based embedding distances provide a viable way of measuring audio prompt adherence. An python/pytorch implementation of the proposed measure is publicly available as a github repository.
Retrieval-Augmented Open-Vocabulary Object Detection
Apr 08, 2024Open-vocabulary object detection (OVD) has been studied with Vision-Language Models (VLMs) to detect novel objects beyond the pre-trained categories. Previous approaches improve the generalization ability to expand the knowledge of the detector, using 'positive' pseudo-labels with additional 'class' names, e.g., sock, iPod, and alligator. To extend the previous methods in two aspects, we propose Retrieval-Augmented Losses and visual Features (RALF). Our method retrieves related 'negative' classes and augments loss functions. Also, visual features are augmented with 'verbalized concepts' of classes, e.g., worn on the feet, handheld music player, and sharp teeth. Specifically, RALF consists of two modules: Retrieval Augmented Losses (RAL) and Retrieval-Augmented visual Features (RAF). RAL constitutes two losses reflecting the semantic similarity with negative vocabularies. In addition, RAF augments visual features with the verbalized concepts from a large language model (LLM). Our experiments demonstrate the effectiveness of RALF on COCO and LVIS benchmark datasets. We achieve improvement up to 3.4 box AP$_{50}^{\text{N}}$ on novel categories of the COCO dataset and 3.6 mask AP$_{\text{r}}$ gains on the LVIS dataset. Code is available at https://github.com/mlvlab/RALF .
MR-MT3: Memory Retaining Multi-Track Music Transcription to Mitigate Instrument Leakage
Mar 15, 2024
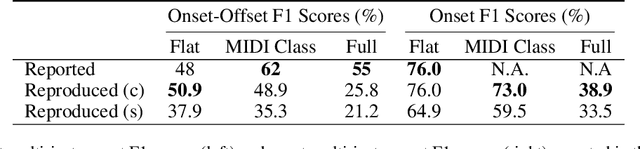
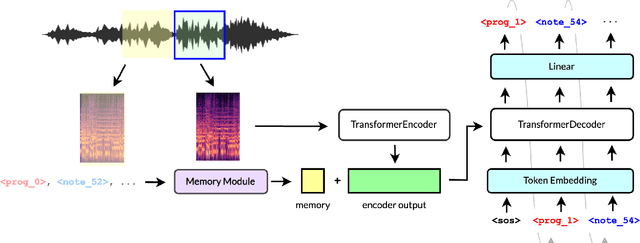
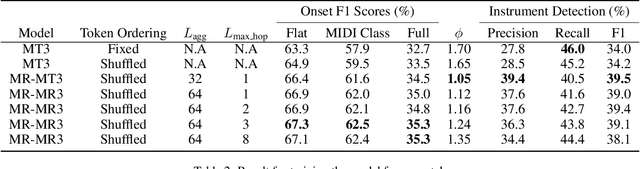
This paper presents enhancements to the MT3 model, a state-of-the-art (SOTA) token-based multi-instrument automatic music transcription (AMT) model. Despite SOTA performance, MT3 has the issue of instrument leakage, where transcriptions are fragmented across different instruments. To mitigate this, we propose MR-MT3, with enhancements including a memory retention mechanism, prior token sampling, and token shuffling are proposed. These methods are evaluated on the Slakh2100 dataset, demonstrating improved onset F1 scores and reduced instrument leakage. In addition to the conventional multi-instrument transcription F1 score, new metrics such as the instrument leakage ratio and the instrument detection F1 score are introduced for a more comprehensive assessment of transcription quality. The study also explores the issue of domain overfitting by evaluating MT3 on single-instrument monophonic datasets such as ComMU and NSynth. The findings, along with the source code, are shared to facilitate future work aimed at refining token-based multi-instrument AMT models.
Structure-informed Positional Encoding for Music Generation
Feb 20, 2024Music generated by deep learning methods often suffers from a lack of coherence and long-term organization. Yet, multi-scale hierarchical structure is a distinctive feature of music signals. To leverage this information, we propose a structure-informed positional encoding framework for music generation with Transformers. We design three variants in terms of absolute, relative and non-stationary positional information. We comprehensively test them on two symbolic music generation tasks: next-timestep prediction and accompaniment generation. As a comparison, we choose multiple baselines from the literature and demonstrate the merits of our methods using several musically-motivated evaluation metrics. In particular, our methods improve the melodic and structural consistency of the generated pieces.
Exploring the Design of Generative AI in Supporting Music-based Reminiscence for Older Adults
Mar 03, 2024
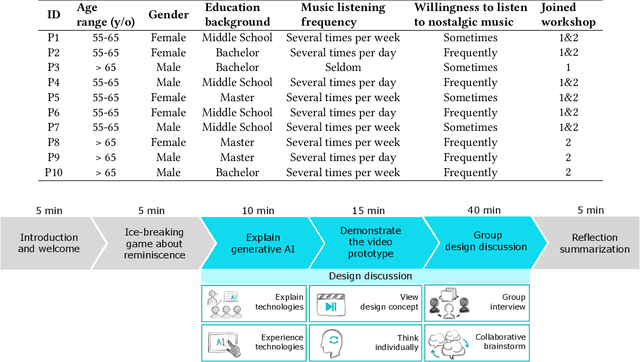


Music-based reminiscence has the potential to positively impact the psychological well-being of older adults. However, the aging process and physiological changes, such as memory decline and limited verbal communication, may impede the ability of older adults to recall their memories and life experiences. Given the advanced capabilities of generative artificial intelligence (AI) systems, such as generated conversations and images, and their potential to facilitate the reminiscing process, this study aims to explore the design of generative AI to support music-based reminiscence in older adults. This study follows a user-centered design approach incorporating various stages, including detailed interviews with two social workers and two design workshops (involving ten older adults). Our work contributes to an in-depth understanding of older adults' attitudes toward utilizing generative AI for supporting music-based reminiscence and identifies concrete design considerations for the future design of generative AI to enhance the reminiscence experience of older adults.
A Recommender System for NFT Collectibles with Item Feature
Apr 03, 2024Recommender systems have been actively studied and applied in various domains to deal with information overload. Although there are numerous studies on recommender systems for movies, music, and e-commerce, comparatively less attention has been paid to the recommender system for NFTs despite the continuous growth of the NFT market. This paper presents a recommender system for NFTs that utilizes a variety of data sources, from NFT transaction records to external item features, to generate precise recommendations that cater to individual preferences. We develop a data-efficient graph-based recommender system to efficiently capture the complex relationship between each item and users and generate node(item) embeddings which incorporate both node feature information and graph structure. Furthermore, we exploit inputs beyond user-item interactions, such as image feature, text feature, and price feature. Numerical experiments verify the performance of the graph-based recommender system improves significantly after utilizing all types of item features as side information, thereby outperforming all other baselines.
Symbolic Music Generation with Non-Differentiable Rule Guided Diffusion
Feb 23, 2024We study the problem of symbolic music generation (e.g., generating piano rolls), with a technical focus on non-differentiable rule guidance. Musical rules are often expressed in symbolic form on note characteristics, such as note density or chord progression, many of which are non-differentiable which pose a challenge when using them for guided diffusion. We propose Stochastic Control Guidance (SCG), a novel guidance method that only requires forward evaluation of rule functions that can work with pre-trained diffusion models in a plug-and-play way, thus achieving training-free guidance for non-differentiable rules for the first time. Additionally, we introduce a latent diffusion architecture for symbolic music generation with high time resolution, which can be composed with SCG in a plug-and-play fashion. Compared to standard strong baselines in symbolic music generation, this framework demonstrates marked advancements in music quality and rule-based controllability, outperforming current state-of-the-art generators in a variety of settings. For detailed demonstrations, code and model checkpoints, please visit our project website: https://scg-rule-guided-music.github.io/.
Sheet Music Transformer: End-To-End Optical Music Recognition Beyond Monophonic Transcription
Feb 12, 2024State-of-the-art end-to-end Optical Music Recognition (OMR) has, to date, primarily been carried out using monophonic transcription techniques to handle complex score layouts, such as polyphony, often by resorting to simplifications or specific adaptations. Despite their efficacy, these approaches imply challenges related to scalability and limitations. This paper presents the Sheet Music Transformer, the first end-to-end OMR model designed to transcribe complex musical scores without relying solely on monophonic strategies. Our model employs a Transformer-based image-to-sequence framework that predicts score transcriptions in a standard digital music encoding format from input images. Our model has been tested on two polyphonic music datasets and has proven capable of handling these intricate music structures effectively. The experimental outcomes not only indicate the competence of the model, but also show that it is better than the state-of-the-art methods, thus contributing to advancements in end-to-end OMR transcription.
Against Filter Bubbles: Diversified Music Recommendation via Weighted Hypergraph Embedding Learning
Feb 26, 2024Recommender systems serve a dual purpose for users: sifting out inappropriate or mismatched information while accurately identifying items that align with their preferences. Numerous recommendation algorithms are designed to provide users with a personalized array of information tailored to their preferences. Nevertheless, excessive personalization can confine users within a "filter bubble". Consequently, achieving the right balance between accuracy and diversity in recommendations is a pressing concern. To address this challenge, exemplified by music recommendation, we introduce the Diversified Weighted Hypergraph music Recommendation algorithm (DWHRec). In the DWHRec algorithm, the initial connections between users and listened tracks are represented by a weighted hypergraph. Simultaneously, associations between artists, albums and tags with tracks are also appended to the hypergraph. To explore users' latent preferences, a hypergraph-based random walk embedding method is applied to the constructed hypergraph. In our investigation, accuracy is gauged by the alignment between the user and the track, whereas the array of recommended track types measures diversity. We rigorously compared DWHRec against seven state-of-the-art recommendation algorithms using two real-world music datasets. The experimental results validate DWHRec as a solution that adeptly harmonizes accuracy and diversity, delivering a more enriched musical experience. Beyond music recommendation, DWHRec can be extended to cater to other scenarios with similar data structures.