 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Collaborative Song Dataset (CoSoD): An annotated dataset of multi-artist collaborations in popular music
Jul 10, 2023
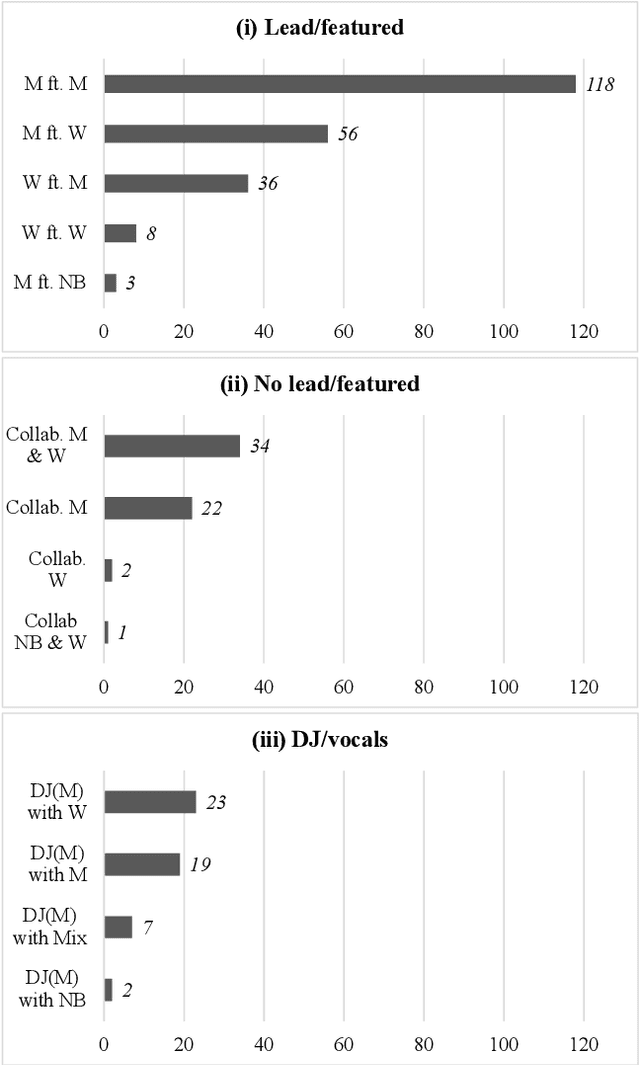
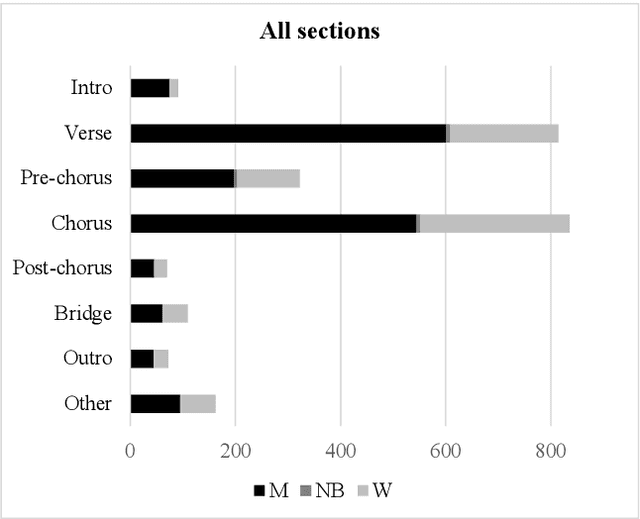
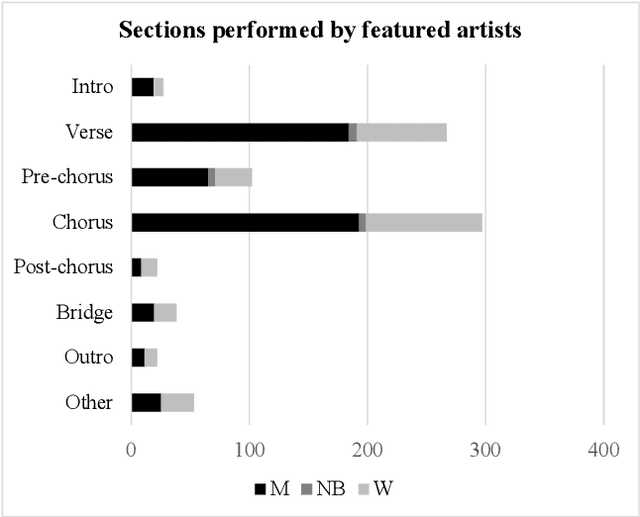
The Collaborative Song Dataset (CoSoD) is a corpus of 331 multi-artist collaborations from the 2010-2019 Billboard "Hot 100" year-end charts. The corpus is annotated with formal sections, aspects of vocal production (including reverberation, layering, panning, and gender of the performers), and relevant metadata. CoSoD complements other popular music datasets by focusing exclusively on musical collaborations between independent acts. In addition to facilitating the study of song form and vocal production, CoSoD allows for the in-depth study of gender as it relates to various timbral, pitch, and formal parameters in musical collaborations. In this paper, we detail the contents of the dataset and outline the annotation process. We also present an experiment using CoSoD that examines how the use of reverberation, layering, and panning are related to the gender of the artist. In this experiment, we find that men's voices are on average treated with less reverberation and occupy a more narrow position in the stereo mix than women's voices.
PitchNet: A Fully Convolutional Neural Network for Pitch Estimation
Aug 14, 2023In the domain of music and sound processing, pitch extraction plays a pivotal role. This research introduces "PitchNet", a convolutional neural network tailored for pitch extraction from the human singing voice, including acapella performances. Integrating autocorrelation with deep learning techniques, PitchNet aims to optimize the accuracy of pitch detection. Evaluation across datasets comprising synthetic sounds, opera recordings, and time-stretched vowels demonstrates its efficacy. This work paves the way for enhanced pitch extraction in both music and voice settings.
The Role of Communication and Reference Songs in the Mixing Process: Insights from Professional Mix Engineers
Sep 08, 2023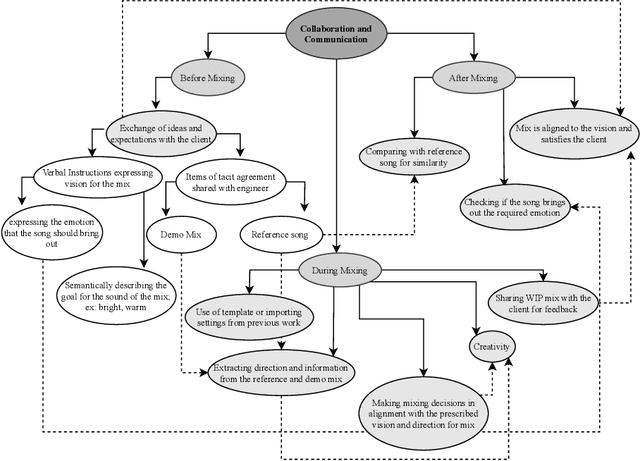
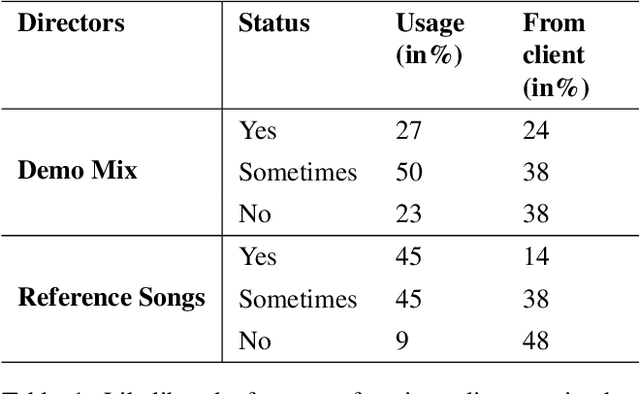
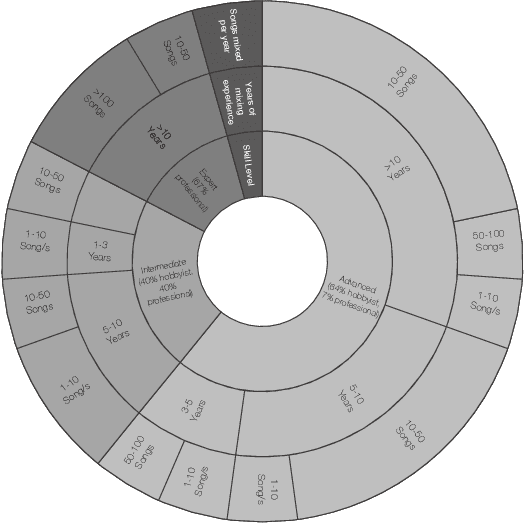
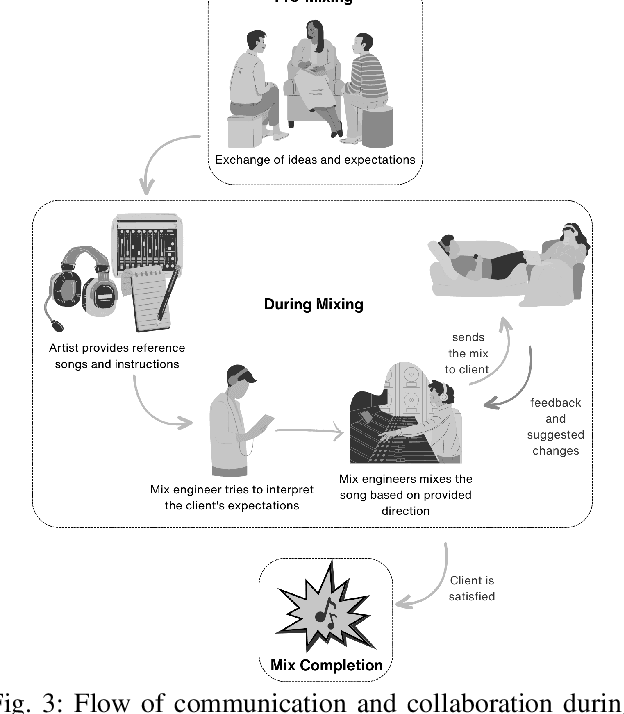
Effective music mixing requires technical and creative finesse, but clear communication with the client is crucial. The mixing engineer must grasp the client's expectations, and preferences, and collaborate to achieve the desired sound. The tacit agreement for the desired sound of the mix is often established using guides like reference songs and demo mixes exchanged between the artist and the engineer and sometimes verbalised using semantic terms. This paper presents the findings of a two-phased exploratory study aimed at understanding how professional mixing engineers interact with clients and use their feedback to guide the mixing process. For phase one, semi-structured interviews were conducted with five mixing engineers with the aim of gathering insights about their communication strategies, creative processes, and decision-making criteria. Based on the inferences from these interviews, an online questionnaire was designed and administered to a larger group of 22 mixing engineers during the second phase. The results of this study shed light on the importance of collaboration, empathy, and intention in the mixing process, and can inform the development of smart multi-track mixing systems that better support these practices. By highlighting the significance of these findings, this paper contributes to the growing body of research on the collaborative nature of music production and provides actionable recommendations for the design and implementation of innovative mixing tools.
TM2D: Bimodality Driven 3D Dance Generation via Music-Text Integration
Apr 05, 2023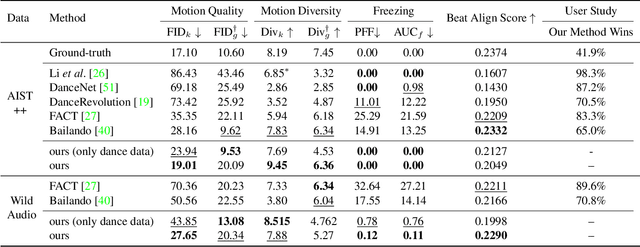
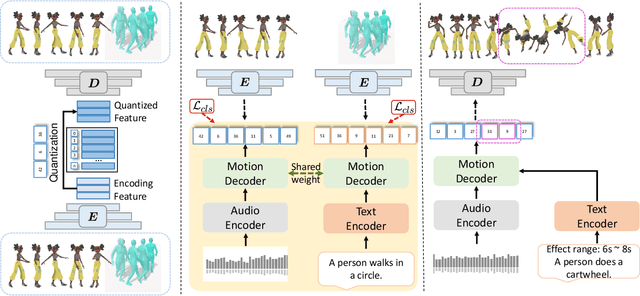
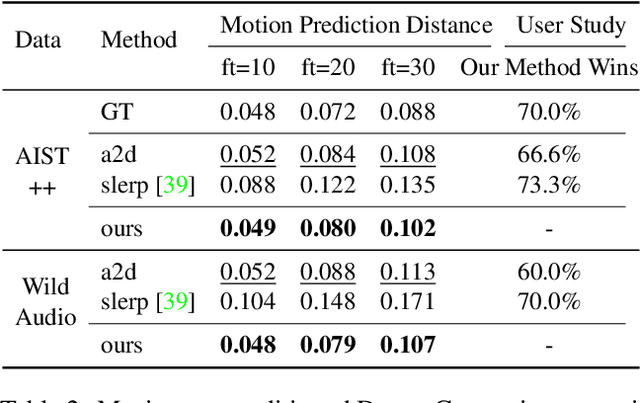
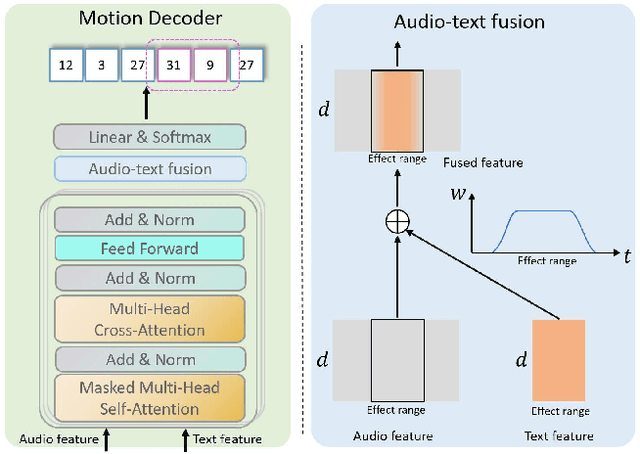
We propose a novel task for generating 3D dance movements that simultaneously incorporate both text and music modalities. Unlike existing works that generate dance movements using a single modality such as music, our goal is to produce richer dance movements guided by the instructive information provided by the text. However, the lack of paired motion data with both music and text modalities limits the ability to generate dance movements that integrate both. To alleviate this challenge, we propose to utilize a 3D human motion VQ-VAE to project the motions of the two datasets into a latent space consisting of quantized vectors, which effectively mix the motion tokens from the two datasets with different distributions for training. Additionally, we propose a cross-modal transformer to integrate text instructions into motion generation architecture for generating 3D dance movements without degrading the performance of music-conditioned dance generation. To better evaluate the quality of the generated motion, we introduce two novel metrics, namely Motion Prediction Distance (MPD) and Freezing Score, to measure the coherence and freezing percentage of the generated motion. Extensive experiments show that our approach can generate realistic and coherent dance movements conditioned on both text and music while maintaining comparable performance with the two single modalities. Code will be available at: https://garfield-kh.github.io/TM2D/.
JEPOO: Highly Accurate Joint Estimation of Pitch, Onset and Offset for Music Information Retrieval
Jun 02, 2023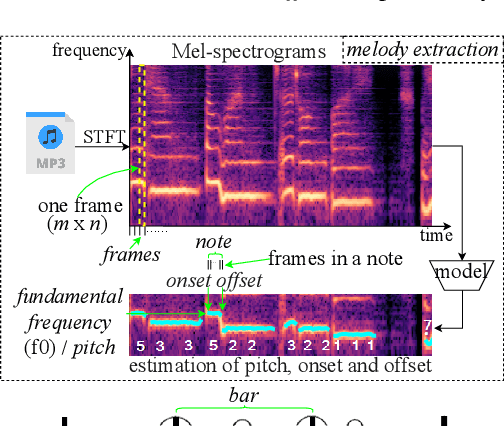
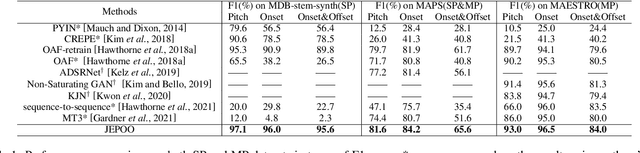
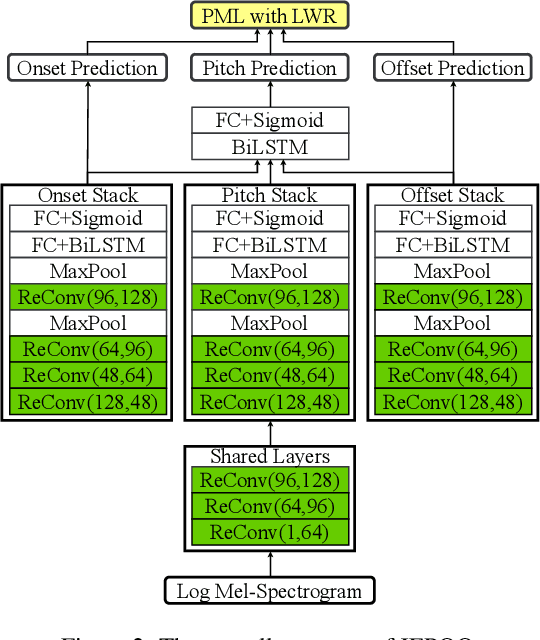
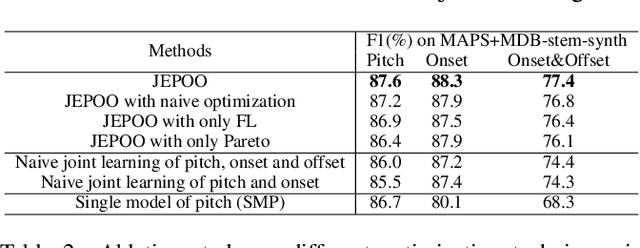
Melody extraction is a core task in music information retrieval, and the estimation of pitch, onset and offset are key sub-tasks in melody extraction. Existing methods have limited accuracy, and work for only one type of data, either single-pitch or multipitch. In this paper, we propose a highly accurate method for joint estimation of pitch, onset and offset, named JEPOO. We address the challenges of joint learning optimization and handling both single-pitch and multi-pitch data through novel model design and a new optimization technique named Pareto modulated loss with loss weight regularization. This is the first method that can accurately handle both single-pitch and multi-pitch music data, and even a mix of them. A comprehensive experimental study on a wide range of real datasets shows that JEPOO outperforms state-ofthe-art methods by up to 10.6%, 8.3% and 10.3% for the prediction of Pitch, Onset and Offset, respectively, and JEPOO is robust for various types of data and instruments. The ablation study shows the effectiveness of each component of JEPOO.
DiffuseRoll: Multi-track multi-category music generation based on diffusion model
Mar 14, 2023Recent advancements in generative models have shown remarkable progress in music generation. However, most existing methods focus on generating monophonic or homophonic music, while the generation of polyphonic and multi-track music with rich attributes is still a challenging task. In this paper, we propose a novel approach for multi-track, multi-attribute symphonic music generation using the diffusion model. Specifically, we generate piano-roll representations with a diffusion model and map them to MIDI format for output. To capture rich attribute information, we introduce a color coding scheme to encode note sequences into color and position information that represents pitch,velocity, and instrument. This scheme enables a seamless mapping between discrete music sequences and continuous images. We also propose a post-processing method to optimize the generated scores for better performance. Experimental results show that our method outperforms state-of-the-art methods in terms of polyphonic music generation with rich attribute information compared to the figure methods.
Contrastive Learning for Cross-modal Artist Retrieval
Aug 12, 2023Music retrieval and recommendation applications often rely on content features encoded as embeddings, which provide vector representations of items in a music dataset. Numerous complementary embeddings can be derived from processing items originally represented in several modalities, e.g., audio signals, user interaction data, or editorial data. However, data of any given modality might not be available for all items in any music dataset. In this work, we propose a method based on contrastive learning to combine embeddings from multiple modalities and explore the impact of the presence or absence of embeddings from diverse modalities in an artist similarity task. Experiments on two datasets suggest that our contrastive method outperforms single-modality embeddings and baseline algorithms for combining modalities, both in terms of artist retrieval accuracy and coverage. Improvements with respect to other methods are particularly significant for less popular query artists. We demonstrate our method successfully combines complementary information from diverse modalities, and is more robust to missing modality data (i.e., it better handles the retrieval of artists with different modality embeddings than the query artist's).
MusicLM: Generating Music From Text
Jan 26, 2023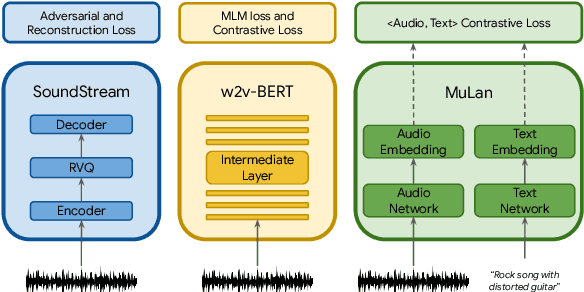
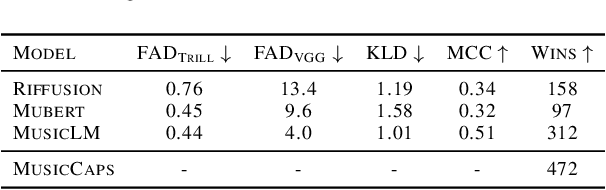
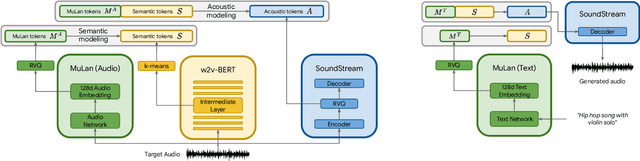
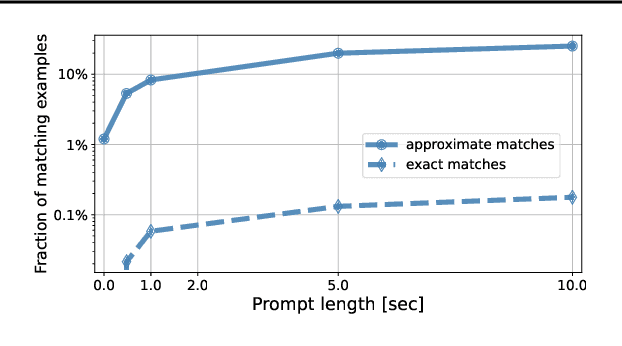
We introduce MusicLM, a model generating high-fidelity music from text descriptions such as "a calming violin melody backed by a distorted guitar riff". MusicLM casts the process of conditional music generation as a hierarchical sequence-to-sequence modeling task, and it generates music at 24 kHz that remains consistent over several minutes. Our experiments show that MusicLM outperforms previous systems both in audio quality and adherence to the text description. Moreover, we demonstrate that MusicLM can be conditioned on both text and a melody in that it can transform whistled and hummed melodies according to the style described in a text caption. To support future research, we publicly release MusicCaps, a dataset composed of 5.5k music-text pairs, with rich text descriptions provided by human experts.
In-depth analysis of music structure as a self-organized network
Mar 21, 2023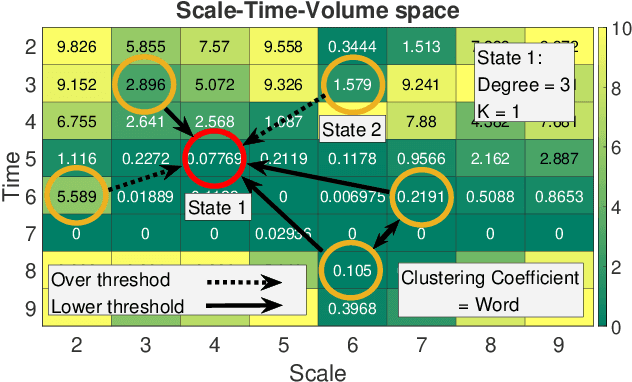
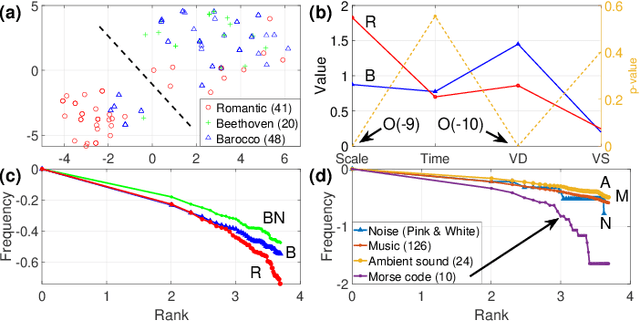
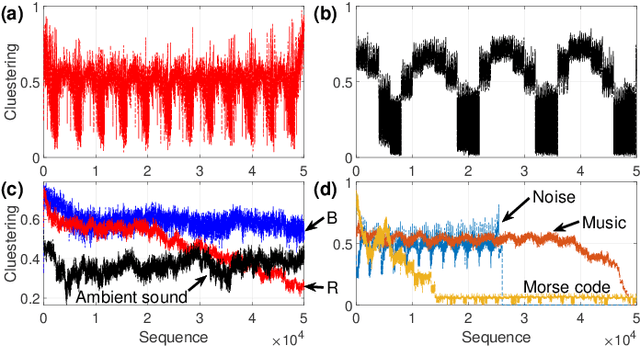
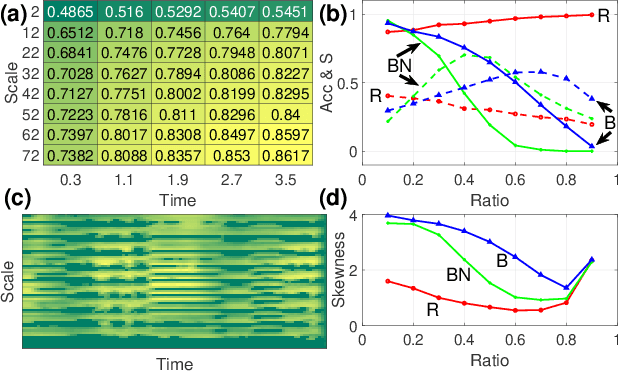
Words in a natural language not only transmit information but also evolve with the development of civilization and human migration. The same is true for music. To understand the complex structure behind the music, we introduced an algorithm called the Essential Element Network (EEN) to encode the audio into text. The network is obtained by calculating the correlations between scales, time, and volume. Optimizing EEN to generate Zipfs law for the frequency and rank of the clustering coefficient enables us to generate and regard the semantic relationships as words. We map these encoded words into the scale-temporal space, which helps us organize systematically the syntax in the deep structure of music. Our algorithm provides precise descriptions of the complex network behind the music, as opposed to the black-box nature of other deep learning approaches. As a result, the experience and properties accumulated through these processes can offer not only a new approach to the applications of Natural Language Processing (NLP) but also an easier and more objective way to analyze the evolution and development of music.