 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Music Rearrangement Using Hierarchical Segmentation
May 12, 2023
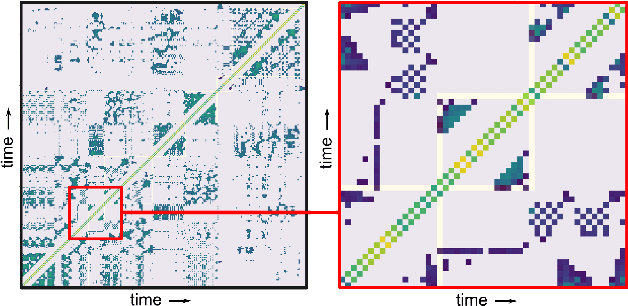
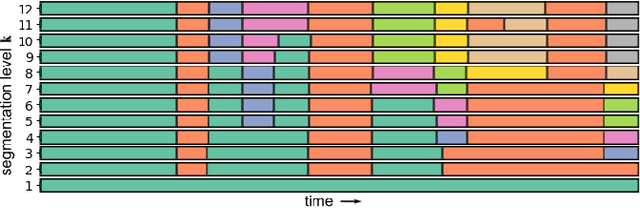
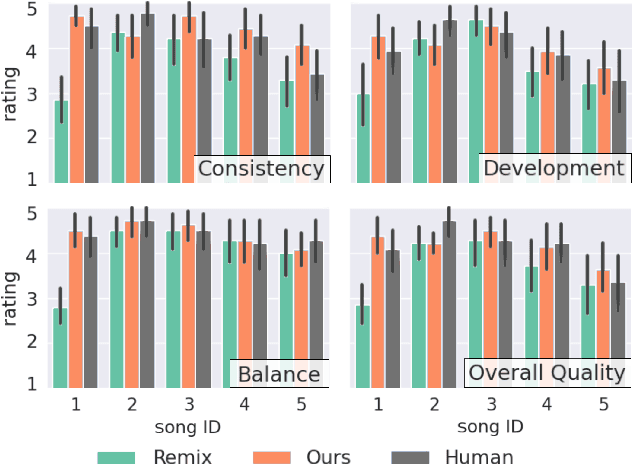
Music rearrangement involves reshuffling, deleting, and repeating sections of a music piece with the goal of producing a standalone version that has a different duration. It is a creative and time-consuming task commonly performed by an expert music engineer. In this paper, we propose a method for automatically rearranging music recordings that takes into account the hierarchical structure of the recording. Previous approaches focus solely on identifying cut-points in the audio that could result in smooth transitions. We instead utilize deep audio representations to hierarchically segment the piece and define a cut-point search subject to the boundaries and musical functions of the segments. We score suitable entry- and exit-point pairs based on their similarity and the segments they belong to, and define an optimal path search. Experimental results demonstrate the selected cut-points are most commonly imperceptible by listeners and result in more consistent musical development with less distracting repetitions.
Multitrack Music Transcription with a Time-Frequency Perceiver
Jun 19, 2023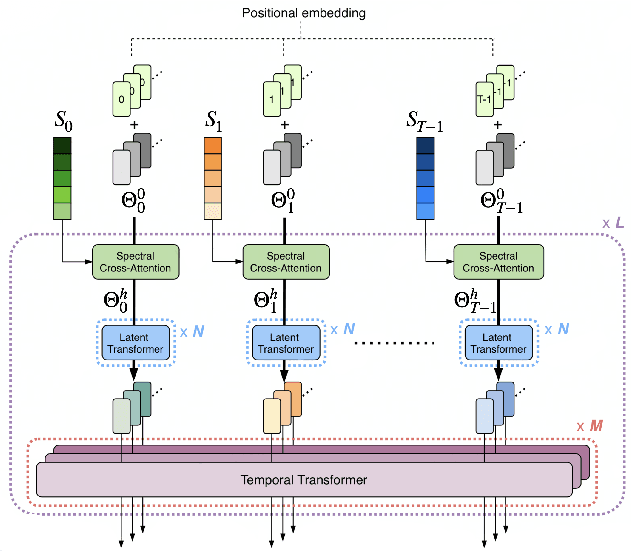
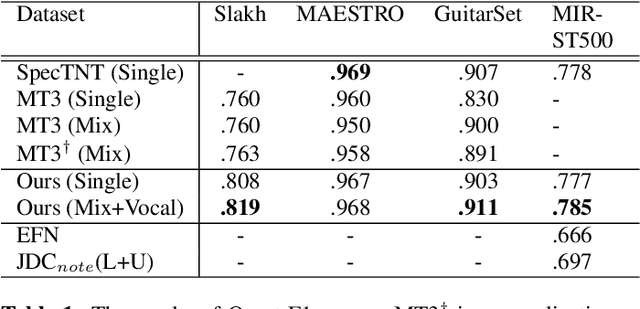

Multitrack music transcription aims to transcribe a music audio input into the musical notes of multiple instruments simultaneously. It is a very challenging task that typically requires a more complex model to achieve satisfactory result. In addition, prior works mostly focus on transcriptions of regular instruments, however, neglecting vocals, which are usually the most important signal source if present in a piece of music. In this paper, we propose a novel deep neural network architecture, Perceiver TF, to model the time-frequency representation of audio input for multitrack transcription. Perceiver TF augments the Perceiver architecture by introducing a hierarchical expansion with an additional Transformer layer to model temporal coherence. Accordingly, our model inherits the benefits of Perceiver that posses better scalability, allowing it to well handle transcriptions of many instruments in a single model. In experiments, we train a Perceiver TF to model 12 instrument classes as well as vocal in a multi-task learning manner. Our result demonstrates that the proposed system outperforms the state-of-the-art counterparts (e.g., MT3 and SpecTNT) on various public datasets.
On The Open Prompt Challenge In Conditional Audio Generation
Nov 01, 2023Text-to-audio generation (TTA) produces audio from a text description, learning from pairs of audio samples and hand-annotated text. However, commercializing audio generation is challenging as user-input prompts are often under-specified when compared to text descriptions used to train TTA models. In this work, we treat TTA models as a ``blackbox'' and address the user prompt challenge with two key insights: (1) User prompts are generally under-specified, leading to a large alignment gap between user prompts and training prompts. (2) There is a distribution of audio descriptions for which TTA models are better at generating higher quality audio, which we refer to as ``audionese''. To this end, we rewrite prompts with instruction-tuned models and propose utilizing text-audio alignment as feedback signals via margin ranking learning for audio improvements. On both objective and subjective human evaluations, we observed marked improvements in both text-audio alignment and music audio quality.
JAZZVAR: A Dataset of Variations found within Solo Piano Performances of Jazz Standards for Music Overpainting
Jul 18, 2023Jazz pianists often uniquely interpret jazz standards. Passages from these interpretations can be viewed as sections of variation. We manually extracted such variations from solo jazz piano performances. The JAZZVAR dataset is a collection of 502 pairs of Variation and Original MIDI segments. Each Variation in the dataset is accompanied by a corresponding Original segment containing the melody and chords from the original jazz standard. Our approach differs from many existing jazz datasets in the music information retrieval (MIR) community, which often focus on improvisation sections within jazz performances. In this paper, we outline the curation process for obtaining and sorting the repertoire, the pipeline for creating the Original and Variation pairs, and our analysis of the dataset. We also introduce a new generative music task, Music Overpainting, and present a baseline Transformer model trained on the JAZZVAR dataset for this task. Other potential applications of our dataset include expressive performance analysis and performer identification.
Shaping the Epochal Individuality and Generality: The Temporal Dynamics of Uncertainty and Prediction Error in Musical Improvisation
Oct 04, 2023Musical improvisation, much like spontaneous speech, reveals intricate facets of the improviser's state of mind and emotional character. However, the specific musical components that reveal such individuality remain largely unexplored. Within the framework of brain's statistical learning and predictive processing, this study examined the temporal dynamics of uncertainty and surprise (prediction error) in a piece of musical improvisation. This study employed the HBSL model to analyze a corpus of 456 Jazz improvisations, spanning 1905 to 2009, from 78 distinct Jazz musicians. The results indicated distinctive temporal patterns of surprise and uncertainty, especially in pitch and pitch-rhythm sequences, revealing era-specific features from the early 20th to the 21st centuries. Conversely, rhythm sequences exhibited a consistent degree of uncertainty across eras. Further, the acoustic properties remain unchanged across different periods. These findings highlight the importance of how temporal dynamics of surprise and uncertainty in improvisational music change over periods, profoundly influencing the distinctive methodologies artists adopt for improvisation in each era. Further, it is suggested that the development of improvisational music can be attributed to the brain's adaptive statistical learning mechanisms, which constantly refine internal models to mirror the cultural and emotional nuances of their respective epochs. This study unravels the evolutionary trajectory of improvisational music and highlights the nuanced shifts artists employ to resonate with the cultural and emotional landscapes of their times.
Towards personalised music-therapy; a neurocomputational modelling perspective
May 15, 2023

Music therapy has emerged recently as a successful intervention that improves patient's outcome in a large range of neurological and mood disorders without adverse effects. Brain networks are entrained to music in ways that can be explained both via top-down and bottom-up processes. In particular, the direct interaction of auditory with the motor and the reward system via a predictive framework explains the efficacy of music-based interventions in motor rehabilitation. In this manuscript, we provide a brief overview of current theories of music perception and processing. Subsequently, we summarise evidence of music-based interventions primarily in motor, emotional and cardiovascular regulation. We highlight opportunities to improve quality of life and reduce stress beyond the clinic environment and in healthy individuals. This relatively unexplored area requires an understanding of how we can personalise and automate music selection processes to fit individuals needs and tasks via feedback loops mediated by measurements of neuro-physiological responses.
MBTFNet: Multi-Band Temporal-Frequency Neural Network For Singing Voice Enhancement
Oct 06, 2023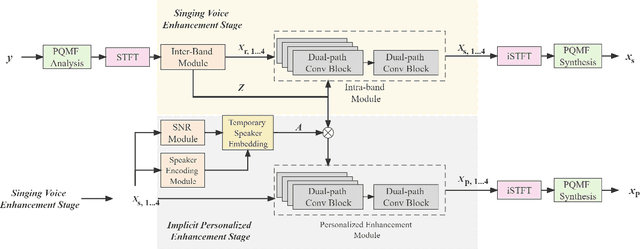
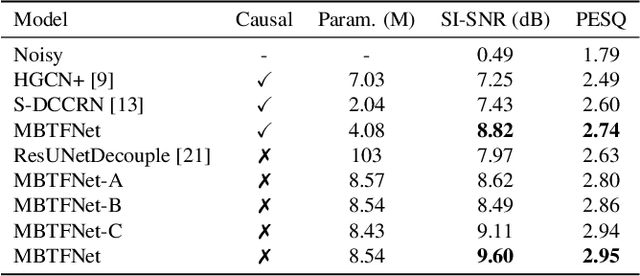
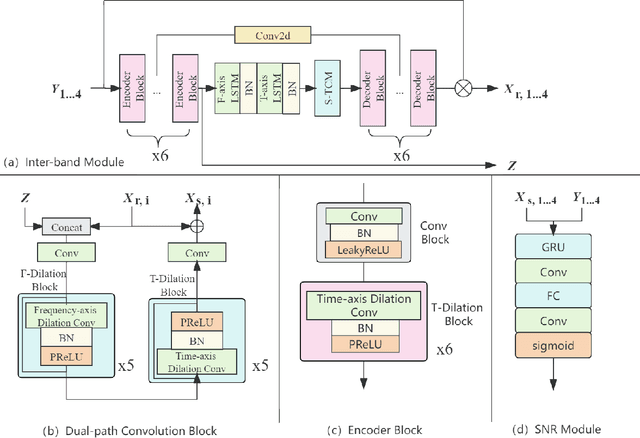
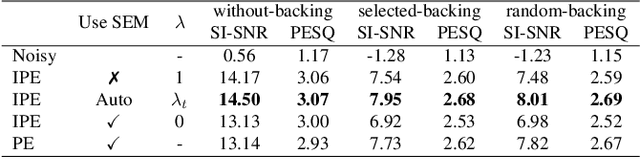
A typical neural speech enhancement (SE) approach mainly handles speech and noise mixtures, which is not optimal for singing voice enhancement scenarios. Music source separation (MSS) models treat vocals and various accompaniment components equally, which may reduce performance compared to the model that only considers vocal enhancement. In this paper, we propose a novel multi-band temporal-frequency neural network (MBTFNet) for singing voice enhancement, which particularly removes background music, noise and even backing vocals from singing recordings. MBTFNet combines inter and intra-band modeling for better processing of full-band signals. Dual-path modeling are introduced to expand the receptive field of the model. We propose an implicit personalized enhancement (IPE) stage based on signal-to-noise ratio (SNR) estimation, which further improves the performance of MBTFNet. Experiments show that our proposed model significantly outperforms several state-of-the-art SE and MSS models.
Taming Diffusion Models for Music-driven Conducting Motion Generation
Jun 15, 2023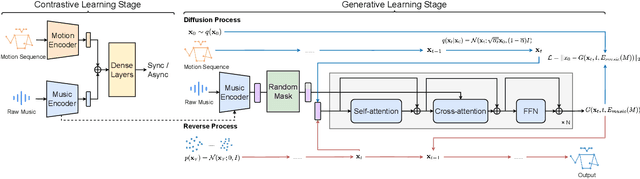

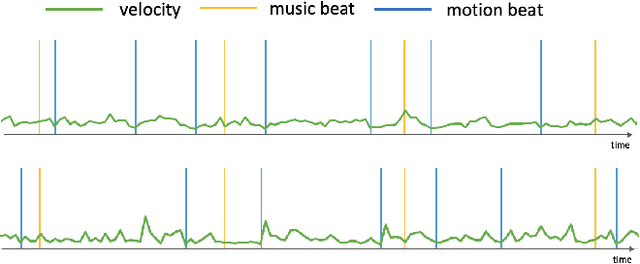
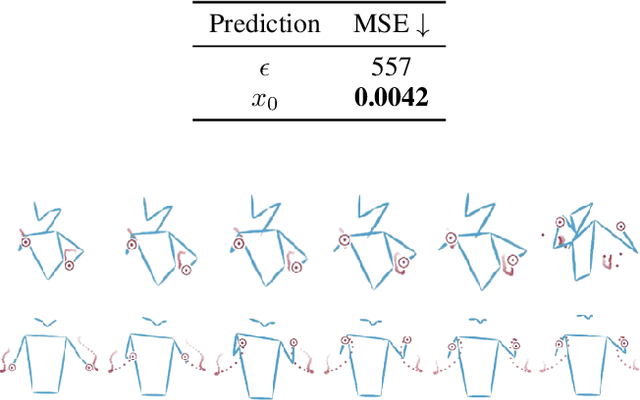
Generating the motion of orchestral conductors from a given piece of symphony music is a challenging task since it requires a model to learn semantic music features and capture the underlying distribution of real conducting motion. Prior works have applied Generative Adversarial Networks (GAN) to this task, but the promising diffusion model, which recently showed its advantages in terms of both training stability and output quality, has not been exploited in this context. This paper presents Diffusion-Conductor, a novel DDIM-based approach for music-driven conducting motion generation, which integrates the diffusion model to a two-stage learning framework. We further propose a random masking strategy to improve the feature robustness, and use a pair of geometric loss functions to impose additional regularizations and increase motion diversity. We also design several novel metrics, including Frechet Gesture Distance (FGD) and Beat Consistency Score (BC) for a more comprehensive evaluation of the generated motion. Experimental results demonstrate the advantages of our model.
From Words to Music: A Study of Subword Tokenization Techniques in Symbolic Music Generation
Apr 25, 2023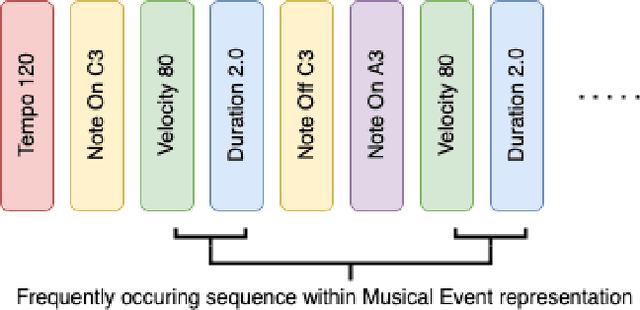

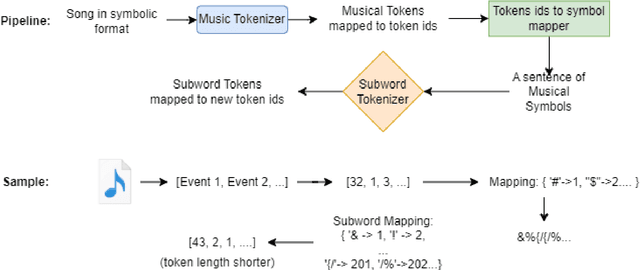
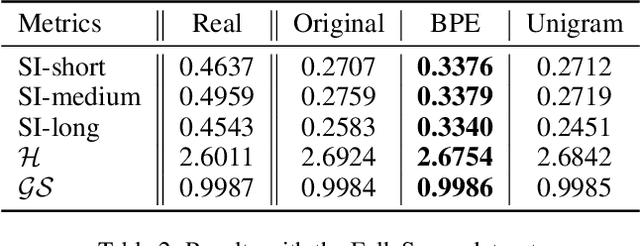
Subword tokenization has been widely successful in text-based natural language processing (NLP) tasks with Transformer-based models. As Transformer models become increasingly popular in symbolic music-related studies, it is imperative to investigate the efficacy of subword tokenization in the symbolic music domain. In this paper, we explore subword tokenization techniques, such as byte-pair encoding (BPE), in symbolic music generation and its impact on the overall structure of generated songs. Our experiments are based on three types of MIDI datasets: single track-melody only, multi-track with a single instrument, and multi-track and multi-instrument. We apply subword tokenization on post-musical tokenization schemes and find that it enables the generation of longer songs at the same time and improves the overall structure of the generated music in terms of objective metrics like structure indicator (SI), Pitch Class Entropy, etc. We also compare two subword tokenization methods, BPE and Unigram, and observe that both methods lead to consistent improvements. Our study suggests that subword tokenization is a promising technique for symbolic music generation and may have broader implications for music composition, particularly in cases involving complex data such as multi-track songs.
D-Band 2D MIMO FMCW Radar System Design for Indoor Wireless Sensing
Oct 05, 2023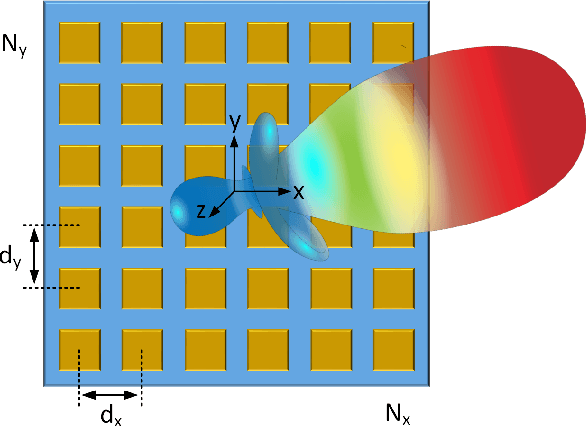
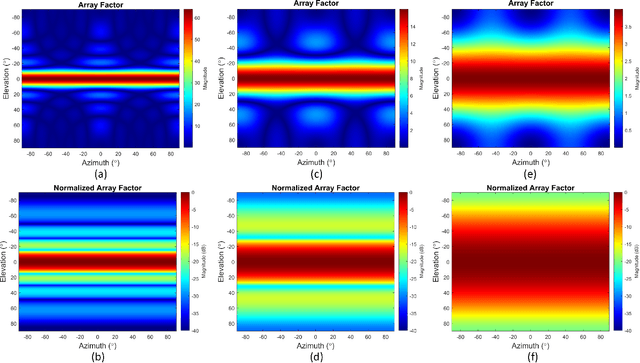
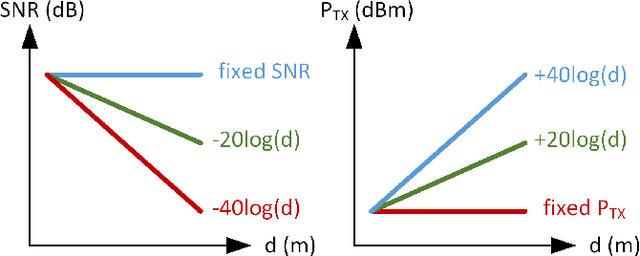
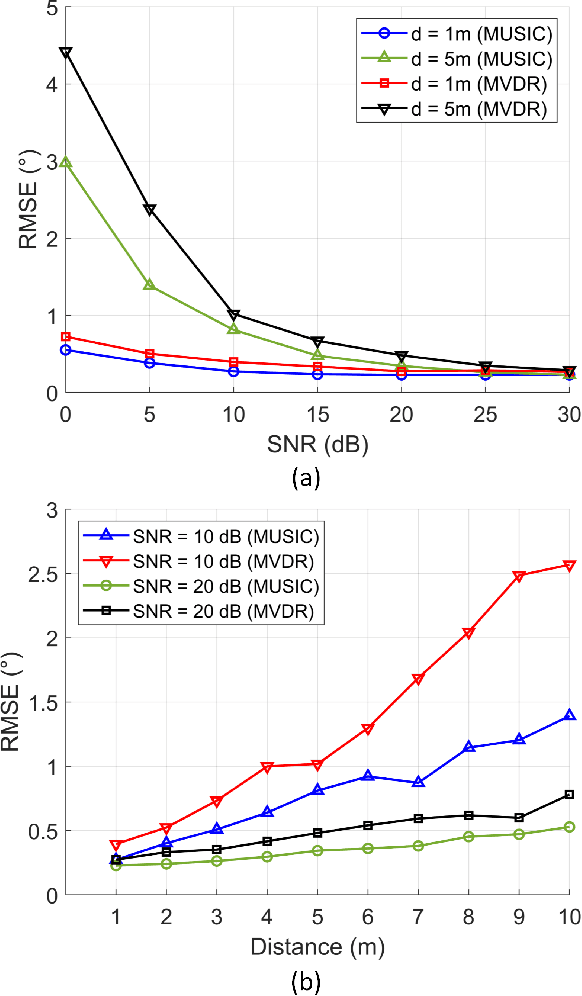
In this article, we present system design of D-band multi-input multi-output (MIMO) frequency-modulated continuous-wave (FMCW) radar for indoor wireless sensing. A uniform rectangular array (URA) of radar elements is used for 2D direction-of-arrival (DOA) estimation. The DOA estimation accuracy of the MIMO radar array in the presence of noise is evaluated using the multiple-signal classification (MUSIC) and the minimum variance distortionless response (MVDR) algorithms. We investigate different scaling scenarios for the radar receiver (RX) SNR and the transmitter (TX) output power with the target distance. The DOA estimation algorithm providing the highest accuracy and shortest simulation time is shown to depend on the size of the radar array. Specifically, for a 64-element array, the MUSIC achieves lower root-mean-square error (RMSE) compared to the MVDR across 1--10\,m indoor distances and 0--30\,dB SNR (e.g., $\rm 0.8^{\circ}$/$\rm 0.3^{\circ}$ versus $\rm 1.0^{\circ}$/$\rm 0.5^{\circ}$ at 10/20\,dB SNR and 5\,m distance) and 0.5x simulation time. For a 16-element array, the two algorithms provide comparable performance, while for a 4-element array, the MVDR outperforms the MUSIC by a large margin (e.g., $\rm 8.3^{\circ}$/$\rm 3.8^{\circ}$ versus $\rm 62.2^{\circ}$/$\rm 48.8^{\circ}$ at 10/20\,dB SNR and 5\,m distance) and 0.8x simulation time. Furthermore, the TX output power requirement of the radar array is investigated in free-space and through-wall wireless sensing scenarios, and is benchmarked by the state-of-the-art D-band on-chip radars.