 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Sound of Story: Multi-modal Storytelling with Audio
Oct 30, 2023
Storytelling is multi-modal in the real world. When one tells a story, one may use all of the visualizations and sounds along with the story itself. However, prior studies on storytelling datasets and tasks have paid little attention to sound even though sound also conveys meaningful semantics of the story. Therefore, we propose to extend story understanding and telling areas by establishing a new component called "background sound" which is story context-based audio without any linguistic information. For this purpose, we introduce a new dataset, called "Sound of Story (SoS)", which has paired image and text sequences with corresponding sound or background music for a story. To the best of our knowledge, this is the largest well-curated dataset for storytelling with sound. Our SoS dataset consists of 27,354 stories with 19.6 images per story and 984 hours of speech-decoupled audio such as background music and other sounds. As benchmark tasks for storytelling with sound and the dataset, we propose retrieval tasks between modalities, and audio generation tasks from image-text sequences, introducing strong baselines for them. We believe the proposed dataset and tasks may shed light on the multi-modal understanding of storytelling in terms of sound. Downloading the dataset and baseline codes for each task will be released in the link: https://github.com/Sosdatasets/SoS_Dataset.
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Oct 20, 2023Hearing is arguably an essential ability of artificial intelligence (AI) agents in the physical world, which refers to the perception and understanding of general auditory information consisting of at least three types of sounds: speech, audio events, and music. In this paper, we propose SALMONN, a speech audio language music open neural network, built by integrating a pre-trained text-based large language model (LLM) with speech and audio encoders into a single multimodal model. SALMONN enables the LLM to directly process and understand general audio inputs and achieve competitive performances on a number of speech and audio tasks used in training, such as automatic speech recognition and translation, auditory-information-based question answering, emotion recognition, speaker verification, and music and audio captioning \textit{etc.} SALMONN also has a diverse set of emergent abilities unseen in the training, which includes but is not limited to speech translation to untrained languages, speech-based slot filling, spoken-query-based question answering, audio-based storytelling, and speech audio co-reasoning \textit{etc}. The presence of the cross-modal emergent abilities is studied, and a novel few-shot activation tuning approach is proposed to activate such abilities of SALMONN. To our knowledge, SALMONN is the first model of its type and can be regarded as a step towards AI with generic hearing abilities. An interactive demo of SALMONN is available at \texttt{\url{https://github.com/bytedance/SALMONN}}, and the training code and model checkpoints will be released upon acceptance.
Lil-Bevo: Explorations of Strategies for Training Language Models in More Humanlike Ways
Oct 26, 2023We present Lil-Bevo, our submission to the BabyLM Challenge. We pretrained our masked language models with three ingredients: an initial pretraining with music data, training on shorter sequences before training on longer ones, and masking specific tokens to target some of the BLiMP subtasks. Overall, our baseline models performed above chance, but far below the performance levels of larger LLMs trained on more data. We found that training on short sequences performed better than training on longer sequences.Pretraining on music may help performance marginally, but, if so, the effect seems small. Our targeted Masked Language Modeling augmentation did not seem to improve model performance in general, but did seem to help on some of the specific BLiMP tasks that we were targeting (e.g., Negative Polarity Items). Training performant LLMs on small amounts of data is a difficult but potentially informative task. While some of our techniques showed some promise, more work is needed to explore whether they can improve performance more than the modest gains here. Our code is available at https://github.com/venkatasg/Lil-Bevo and out models at https://huggingface.co/collections/venkatasg/babylm-653591cdb66f4bf68922873a
Everybody Compose: Deep Beats To Music
Jun 09, 2023

This project presents a deep learning approach to generate monophonic melodies based on input beats, allowing even amateurs to create their own music compositions. Three effective methods - LSTM with Full Attention, LSTM with Local Attention, and Transformer with Relative Position Representation - are proposed for this novel task, providing great variation, harmony, and structure in the generated music. This project allows anyone to compose their own music by tapping their keyboards or ``recoloring'' beat sequences from existing works.
* Accepted MMSys '23
High-Fidelity Noise Reduction with Differentiable Signal Processing
Oct 17, 2023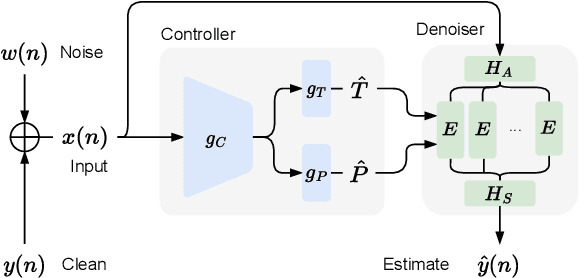
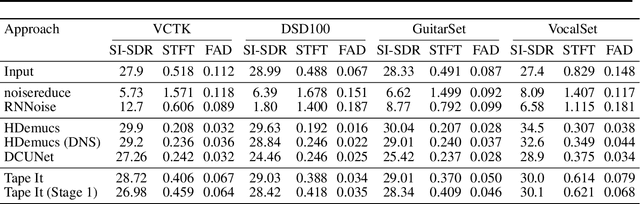
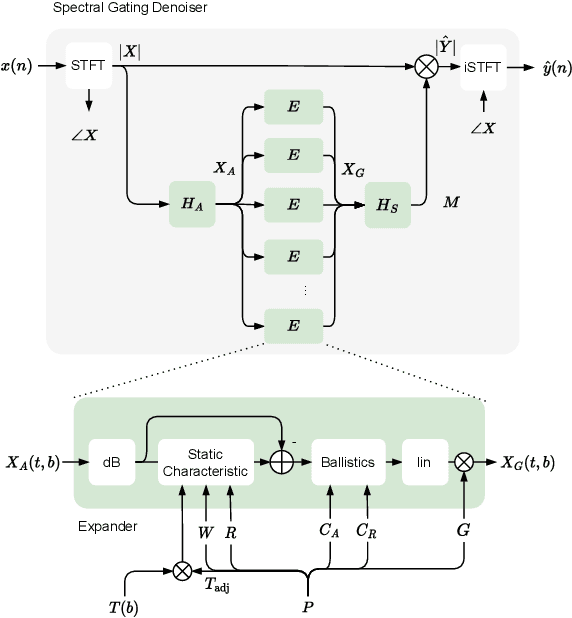

Noise reduction techniques based on deep learning have demonstrated impressive performance in enhancing the overall quality of recorded speech. While these approaches are highly performant, their application in audio engineering can be limited due to a number of factors. These include operation only on speech without support for music, lack of real-time capability, lack of interpretable control parameters, operation at lower sample rates, and a tendency to introduce artifacts. On the other hand, signal processing-based noise reduction algorithms offer fine-grained control and operation on a broad range of content, however, they often require manual operation to achieve the best results. To address the limitations of both approaches, in this work we introduce a method that leverages a signal processing-based denoiser that when combined with a neural network controller, enables fully automatic and high-fidelity noise reduction on both speech and music signals. We evaluate our proposed method with objective metrics and a perceptual listening test. Our evaluation reveals that speech enhancement models can be extended to music, however training the model to remove only stationary noise is critical. Furthermore, our proposed approach achieves performance on par with the deep learning models, while being significantly more efficient and introducing fewer artifacts in some cases. Listening examples are available online at https://tape.it/research/denoiser .
Joint Localization and Communication Enhancement in Uplink Integrated Sensing and Communications System with Clock Asynchronism
Oct 28, 2023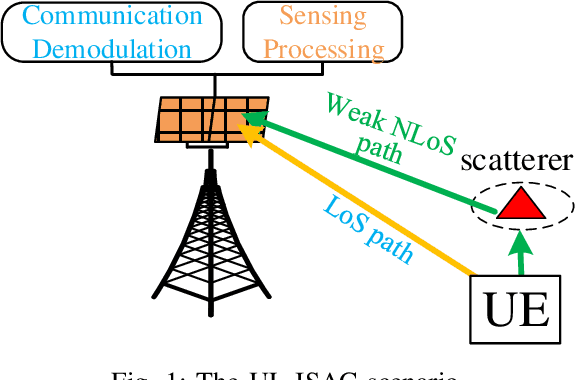
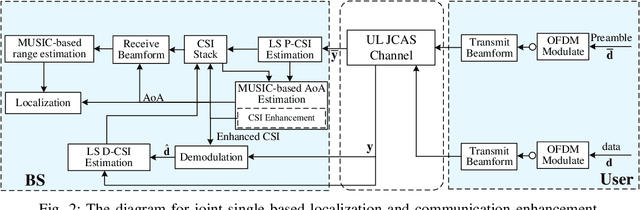
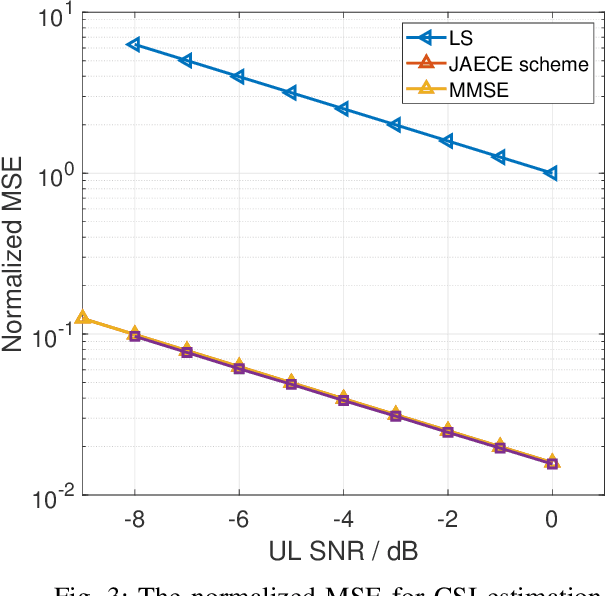
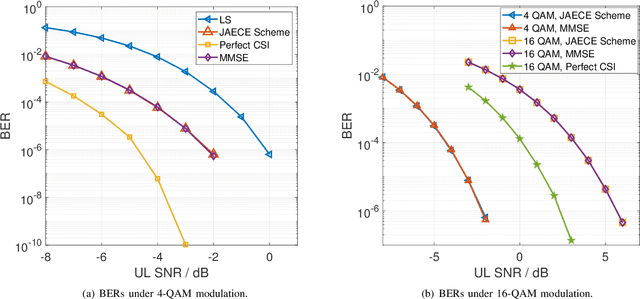
In this paper, we propose a joint single-base localization and communication enhancement scheme for the uplink (UL) integrated sensing and communications (ISAC) system with asynchronism, which can achieve accurate single-base localization of user equipment (UE) and significantly improve the communication reliability despite the existence of timing offset (TO) due to the clock asynchronism between UE and base station (BS). Our proposed scheme integrates the CSI enhancement into the multiple signal classification (MUSIC)-based AoA estimation and thus imposes no extra complexity on the ISAC system. We further exploit a MUSIC-based range estimation method and prove that it can suppress the time-varying TO-related phase terms. Exploiting the AoA and range estimation of UE, we can estimate the location of UE. Finally, we propose a joint CSI and data signals-based localization scheme that can coherently exploit the data and the CSI signals to improve the AoA and range estimation, which further enhances the single-base localization of UE. The extensive simulation results show that the enhanced CSI can achieve equivalent bit error rate performance to the minimum mean square error (MMSE) CSI estimator. The proposed joint CSI and data signals-based localization scheme can achieve decimeter-level localization accuracy despite the existing clock asynchronism and improve the localization mean square error (MSE) by about 8 dB compared with the maximum likelihood (ML)-based benchmark method.
Simultaneous Measurement of Multiple Acoustic Attributes Using Structured Periodic Test Signals Including Music and Other Sound Materials
Sep 06, 2023We introduce a general framework for measuring acoustic properties such as liner time-invariant (LTI) response, signal-dependent time-invariant (SDTI) component, and random and time-varying (RTV) component simultaneously using structured periodic test signals. The framework also enables music pieces and other sound materials as test signals by "safeguarding" them by adding slight deterministic "noise." Measurement using swept-sin, MLS (Maxim Length Sequence), and their variants are special cases of the proposed framework. We implemented interactive and real-time measuring tools based on this framework and made them open-source. Furthermore, we applied this framework to assess pitch extractors objectively.
Of Spiky SVDs and Music Recommendation
Jun 30, 2023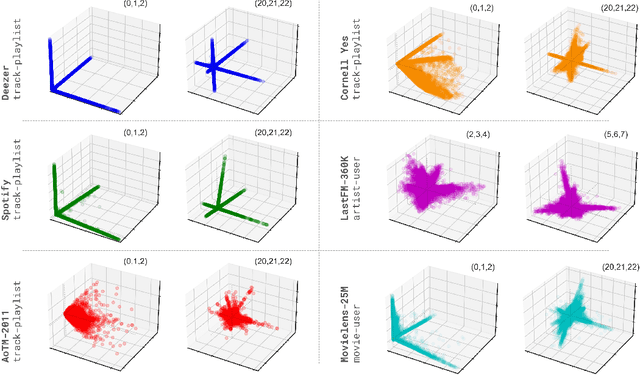

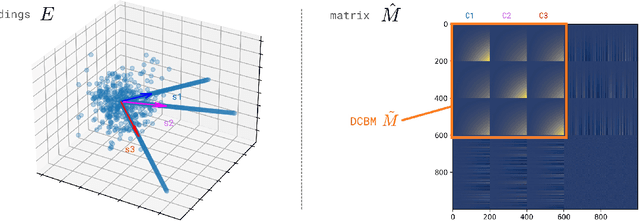

The truncated singular value decomposition is a widely used methodology in music recommendation for direct similar-item retrieval or embedding musical items for downstream tasks. This paper investigates a curious effect that we show naturally occurring on many recommendation datasets: spiking formations in the embedding space. We first propose a metric to quantify this spiking organization's strength, then mathematically prove its origin tied to underlying communities of items of varying internal popularity. With this new-found theoretical understanding, we finally open the topic with an industrial use case of estimating how music embeddings' top-k similar items will change over time under the addition of data.
Exploring XAI for the Arts: Explaining Latent Space in Generative Music
Aug 10, 2023
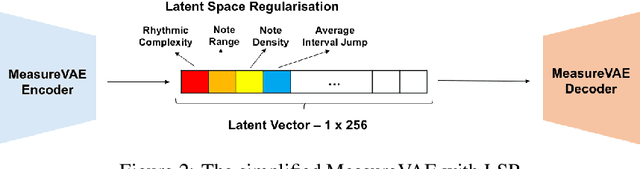
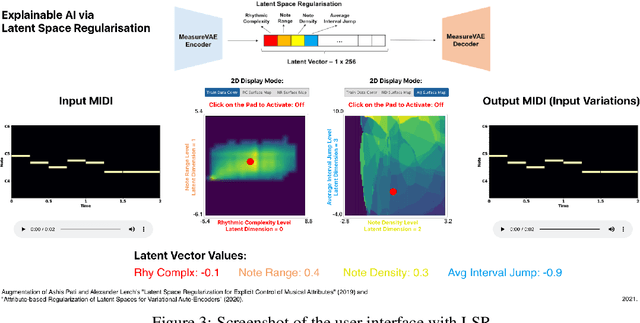

Explainable AI has the potential to support more interactive and fluid co-creative AI systems which can creatively collaborate with people. To do this, creative AI models need to be amenable to debugging by offering eXplainable AI (XAI) features which are inspectable, understandable, and modifiable. However, currently there is very little XAI for the arts. In this work, we demonstrate how a latent variable model for music generation can be made more explainable; specifically we extend MeasureVAE which generates measures of music. We increase the explainability of the model by: i) using latent space regularisation to force some specific dimensions of the latent space to map to meaningful musical attributes, ii) providing a user interface feedback loop to allow people to adjust dimensions of the latent space and observe the results of these changes in real-time, iii) providing a visualisation of the musical attributes in the latent space to help people understand and predict the effect of changes to latent space dimensions. We suggest that in doing so we bridge the gap between the latent space and the generated musical outcomes in a meaningful way which makes the model and its outputs more explainable and more debuggable.
Progressive distillation diffusion for raw music generation
Jul 20, 2023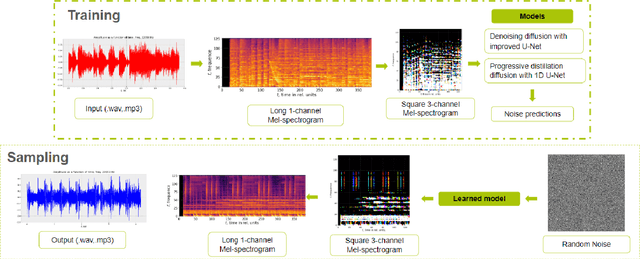
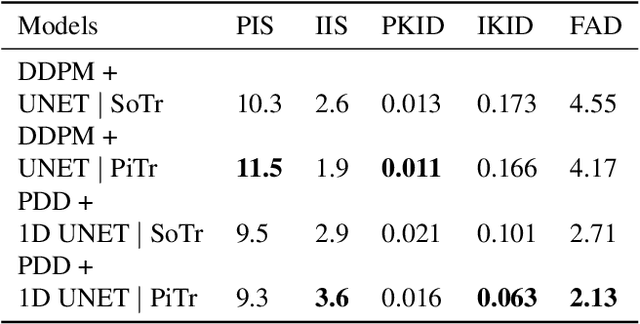
This paper aims to apply a new deep learning approach to the task of generating raw audio files. It is based on diffusion models, a recent type of deep generative model. This new type of method has recently shown outstanding results with image generation. A lot of focus has been given to those models by the computer vision community. On the other hand, really few have been given for other types of applications such as music generation in waveform domain. In this paper the model for unconditional generating applied to music is implemented: Progressive distillation diffusion with 1D U-Net. Then, a comparison of different parameters of diffusion and their value in a full result is presented. One big advantage of the methods implemented through this work is the fact that the model is able to deal with progressing audio processing and generating , using transformation from 1-channel 128 x 384 to 3-channel 128 x 128 mel-spectrograms and looped generation. The empirical comparisons are realized across different self-collected datasets.